LLM 系列 (十一):长上下文:大模型如何读懂更长的信息
过去我们使用大模型时,常常会遇到一个很直观的限制:输入太长,模型放不下。一篇几十页的论文、一份完整的技术文档、一个代码仓库、一次持续很久的多轮对话,都可能超过模型能够处理的上下文窗口。
随着模型上下文长度从早期常见的 4K token,扩展到今天的 1M token 级别(例如 Gemini 1.5 Pro,以及后续部分 Claude / GPT / Gemini 系列模型),LLM 的使用方式也开始发生变化。它不再只是回答一个短问题,而是可以阅读完整资料、分析复杂代码、理解长期对话,甚至支撑 Agent 执行长程任务。
但长上下文并不只是“把窗口调大”。上下文越长,Attention 计算越重,KV Cache 越占显存,模型也越容易忽略中间信息,或者被大量无关内容干扰。真正的长上下文能力,不只是能放下更多 token,而是能在更长、更复杂的信息中找到关键内容,建立远距离关系,并以可承受的成本完成推理。
长上下文为什么重要
长上下文的重要性,不只是“能输入更多内容”,而是它改变了 LLM 能处理的问题类型。在短上下文阶段,模型更像一个问答工具:用户提出一个问题,模型基于当前 prompt 给出回答。它适合解释概念、生成短文本、写一段代码,但很难真正处理完整资料、长期对话和复杂任务过程。当上下文窗口变长后,模型可以看到更完整的信息,应用形态也随之变化:从“基于一句话回答问题”,走向“基于一组资料完成任务”。
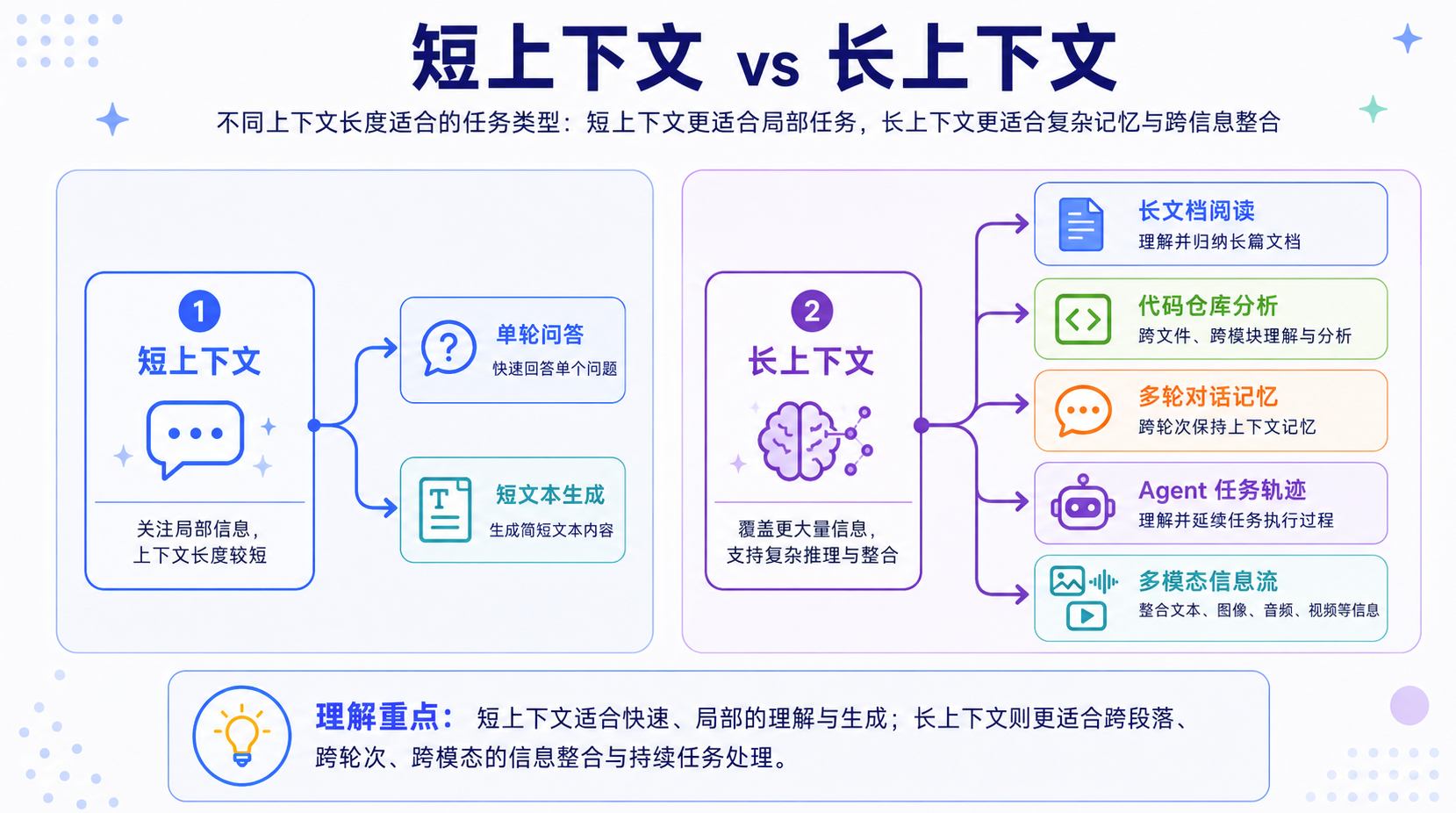
典型变化包括:
- 长文档问答:短上下文通常只能放摘要或片段,而长上下文可以让模型阅读完整论文、合同、报告,再基于完整材料回答问题。
- 代码仓库分析:短上下文往往只能看单个文件,而长上下文可以把多个文件、模块关系、调用链和配置一起放进来,帮助模型理解工程结构。
- 多轮对话记忆:短上下文容易丢失早期历史,而长上下文可以保留更长的用户意图、约束条件和任务状态,让对话更连续。
- Agent 任务执行:Agent 在执行任务时会产生计划、工具调用结果、中间状态和错误修正记录。长上下文可以帮助模型维持完整任务轨迹。
- 多模态信息处理:图像、音频、视频都会被转换成大量 token。长上下文让模型有机会处理更完整的信息流,而不是只看局部片段。
从模型角度看,语言模型的输入可以简化为:
1 | context = [token_1, token_2, ..., token_n] |
这里的 context 就是模型当前能看到的上下文,n 表示上下文中的 token 数量。
当 n 只有几千时,模型主要处理的是一个问题、一段材料、一次短任务;当 n 扩展到几十万甚至百万级时,模型面对的就不再是“短文本生成”,而是完整资料理解和复杂信息组织。
但这也带来一个新的要求:模型不仅要“看见”更多 token,还要知道哪些 token 重要,哪些可以忽略,哪些信息需要跨很远的位置建立关系。
所以,长上下文不是一个单独功能,而是模型结构、训练数据、推理系统和评估方式共同升级后的结果。它让 LLM 从“会回答问题”,进一步走向“能处理复杂信息任务”。
长上下文难在哪里
长上下文真正困难的地方,不是把 max context length 这个参数调大,而是当序列变长后,模型和系统都会同时承受更大的压力。可以把它拆成四类问题,如下图所示:
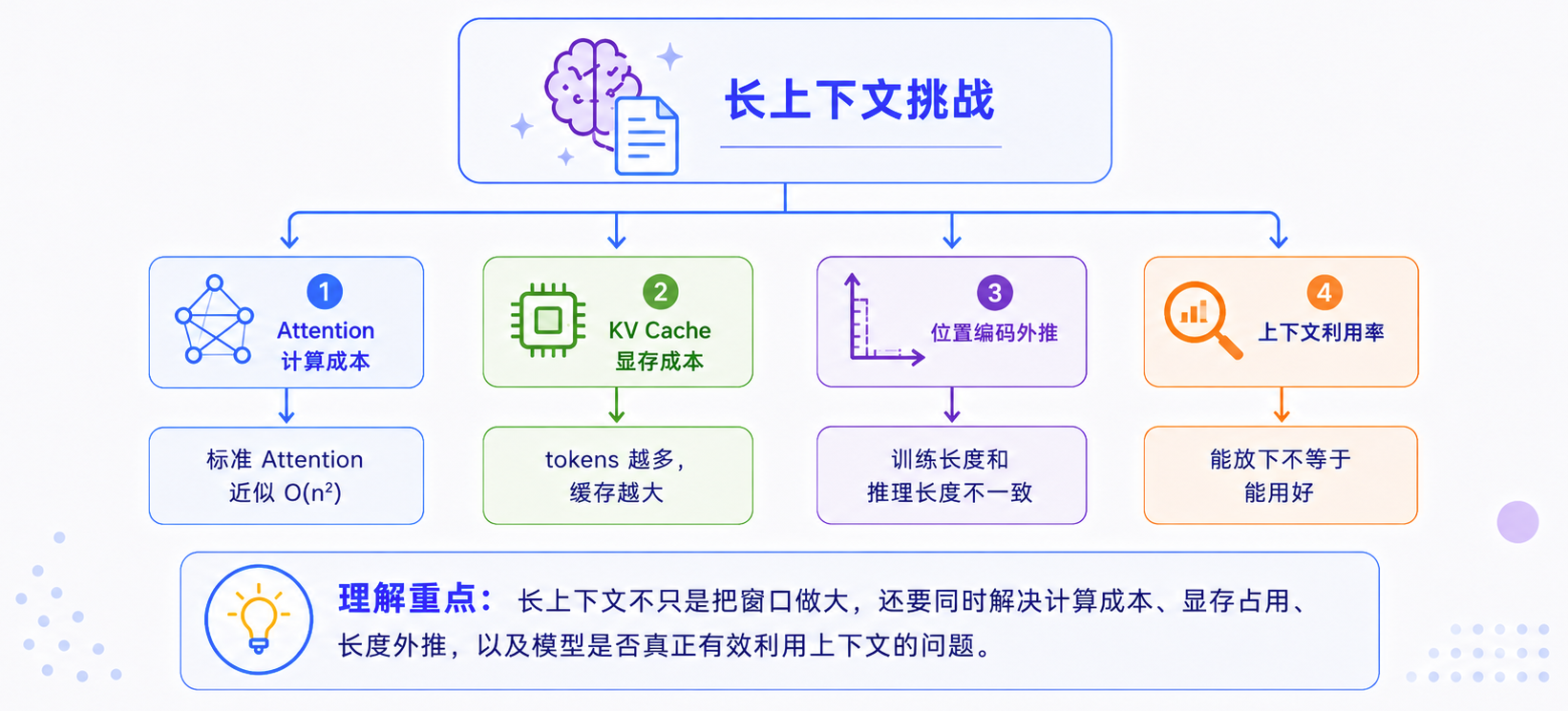
Attention 计算成本会快速上升
Transformer 的 Self-Attention 会让序列中的 token 彼此建立关系。对于长度为 n 的序列,标准 Attention 需要计算一个近似 n × n 的注意力矩阵,所以复杂度大致是:Attention 复杂度 ≈ O(n²)。这意味着上下文长度不是线性变贵,而是会快速放大计算压力。举个直观例子(这里是举例说明,实际模型可能通过稀疏注意力、分块、滑动窗口等方式避免完整计算所有关系):
- 4K 上下文:Attention 关系数量大约是
4K × 4K,约 1.6 千万。 - 32K 上下文:Attention 关系数量大约是
32K × 32K,约 10 亿。 - 128K 上下文:Attention 关系数量大约是
128K × 128K,约 160 亿。 - 1M 上下文:Attention 关系数量大约达到万亿级别。
所以,当上下文长度扩大 10 倍时,Attention 计算可能接近扩大 100 倍。FlashAttention 可以显著减少 IO 开销和显存访问成本,让 Attention 算得更快、更省,但它并不会从理论上消除标准全量 Attention 的二次复杂度。
KV Cache 会成为显存瓶颈
推理阶段还有一个很关键的成本:KV Cache。模型在生成新 token 时,需要参考历史上下文。为了避免每一步都重新计算历史 token 的 Key 和 Value,推理系统会把它们缓存起来,后续 decode 时直接复用。
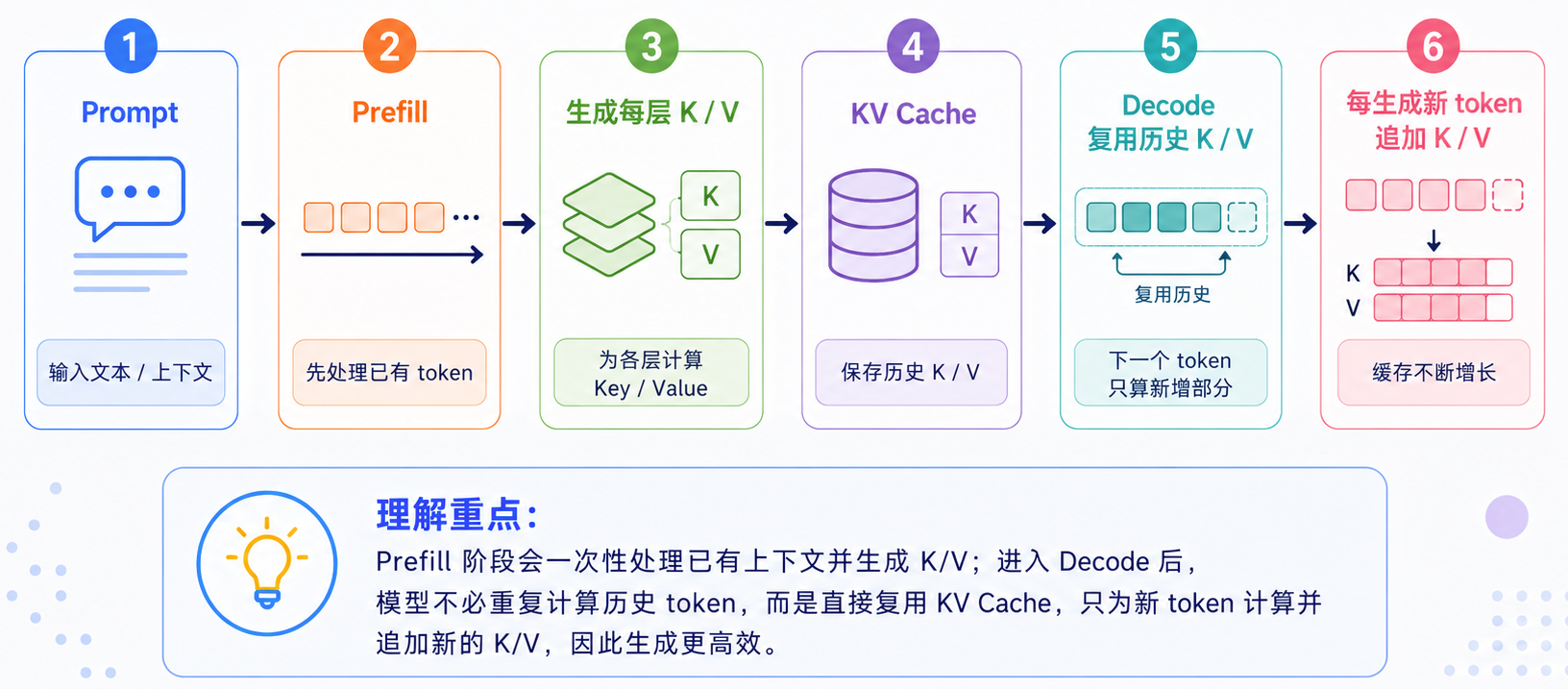
KV Cache 可以粗略估算为:KV Cache ≈ 2 × layers × tokens × kv_heads × head_dim × bytes × batch_size。其中:
2表示 Key 和 Value;layers表示模型层数;tokens表示上下文长度;kv_heads和head_dim表示 KV 的注意力头数量和维度;bytes表示每个数值占用的字节数;batch_size表示并发请求数量。
这个公式说明:上下文越长,KV Cache 越大;并发越高,KV Cache 还会继续叠加。对于长上下文推理,瓶颈经常不是模型权重,而是缓存历史上下文所需的显存。
位置编码会遇到外推问题
模型不只要看到 token,还要知道 token 的位置。否则,下面两句话在模型眼里就很难区分:
- 张三打了李四;
- 李四打了张三;
现代 LLM 通常会使用位置编码来表达顺序关系,其中 RoPE 是非常常见的一种方案。问题在于:模型训练时见过的上下文长度通常是有限的。如果模型主要在 4K 或 8K 长度上训练,但推理时直接扩展到 128K,模型就会遇到位置外推问题:
- 训练时只见过较短位置;
- 推理时需要理解远超训练范围的位置。
如果处理不好,模型可能在长距离关系上变差。例如:
- 对靠后的内容理解变弱;
- 对远距离引用关系判断不稳;
- 前半段回答正常,后半段质量下降;
- 长文档中的章节顺序、依赖关系出现混乱。
所以,长上下文不仅是“放得下”,还要求模型在很远的位置上仍然保持稳定的位置感。
上下文利用率并不会自动提升
这是长上下文里最容易被忽略的问题:窗口变大,不代表模型真的会用好全部内容。即使一个模型支持 100K、1M token,它也可能没有稳定利用这些信息。常见问题包括:
- 中间信息被忽略:模型更关注开头和结尾,对中间内容不敏感;
- 关键信息找不到:答案明明在上下文里,但模型没有定位到;
- 相似信息互相干扰:长文档里存在多个相近概念或重复段落,模型可能混淆来源;
- 局部正确,全局错误:模型能理解某个片段,但无法把多个片段组合成正确结论;
- 约束记忆不稳定:前文已经给出的格式要求、业务规则或用户偏好,在后文生成时被遗忘。
因此,长上下文能力真正要解决的是一条完整链路:放得下 -> 找得到 -> 看得全 -> 推得对 -> 答得稳。其中“放得下”只是第一步。真正困难的是在长序列里保持稳定的信息检索、关系建模和推理能力。
长上下文的核心技术方案
长上下文不是一个单点优化,而是一组技术组合。它既涉及模型结构,也涉及训练数据、推理系统和应用架构。如果简单拆开看,长上下文主要依赖五类能力:
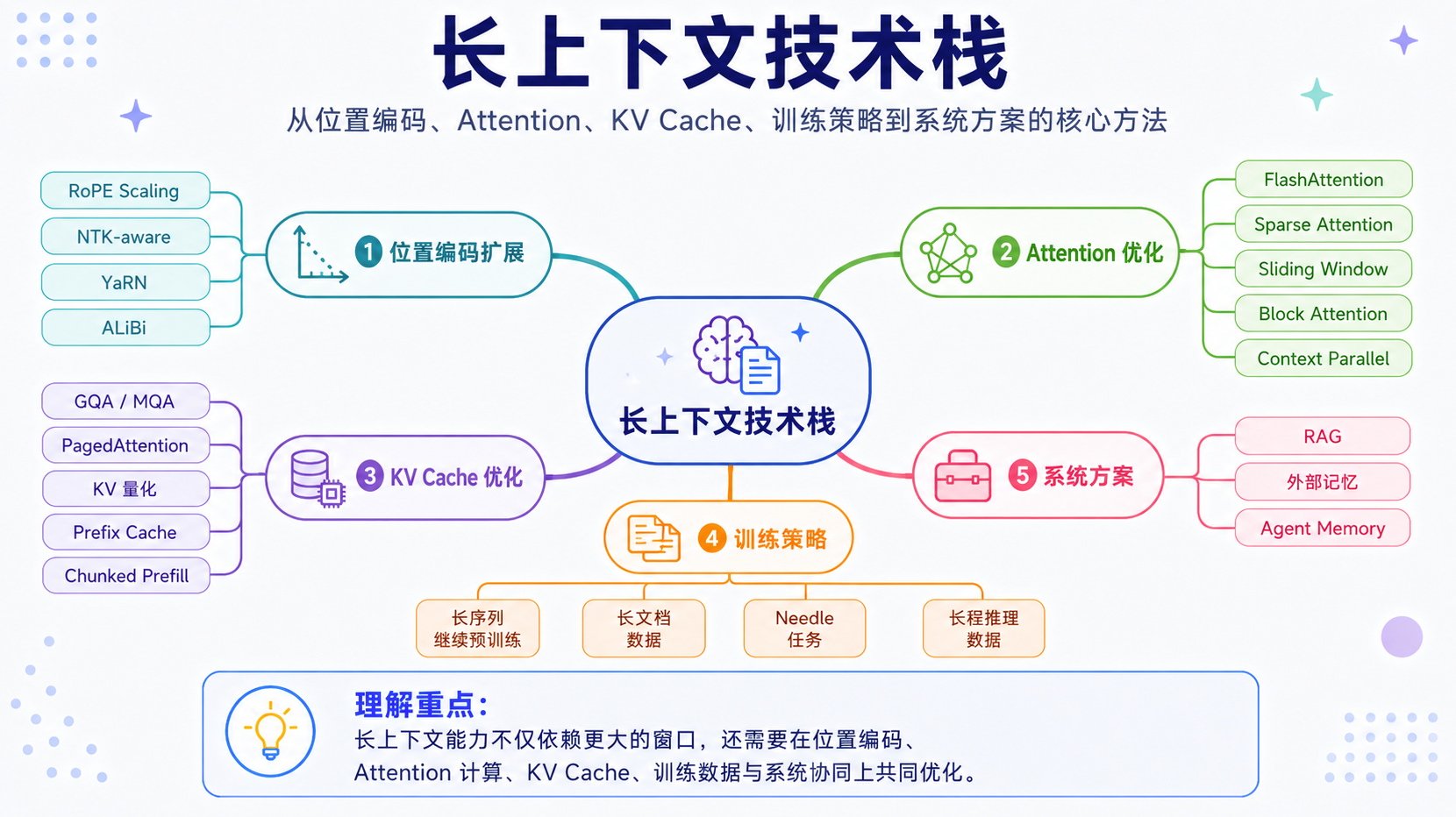
位置编码扩展:让模型理解更远的位置
模型不仅要看到 token,还要知道 token 在哪里。位置编码解决的就是顺序和距离问题。很多现代 LLM 使用 RoPE,也就是 Rotary Position Embedding。RoPE 能把位置信息融入 Attention 的 Query 和 Key 中,让模型更好地理解相对位置关系。
但问题在于:模型训练时见过的上下文长度通常是有限的。如果模型主要在 4K、8K 或 32K 长度上训练,推理时直接拉到 128K、1M,模型不一定能自然适应。所以,长上下文首先需要解决位置外推问题:
- 训练时见过较短位置;
- 推理时需要理解更远位置;
常见方法包括:
- RoPE Scaling:通过调整 RoPE 的频率尺度,把原本较短的位置空间拉伸到更长范围,让模型能处理更长序列。
- NTK-aware Scaling:在 RoPE Scaling 的基础上更精细地调整频率分布,让模型在长距离位置上更稳定。
- YaRN:通过更平滑的位置插值和外推方式,降低上下文扩展后的质量退化。
- ALiBi:不直接使用传统位置 embedding,而是在 Attention score 中加入和距离相关的 bias,让模型天然感知距离。
这些方法的核心目标是一致的:让模型在更远的位置上仍然保持稳定的位置感。如果位置编码处理不好,模型即使能接收很长输入,也可能无法稳定理解远距离关系。
Attention 优化:降低长序列计算压力
长上下文第二个核心问题,是 Attention 太贵。标准 Self-Attention 会计算 token 之间的两两关系,复杂度近似是 O(n²)。当上下文从 4K 扩展到 128K、1M 时,全量 Attention 的计算和显存压力都会急剧上升。因此,长上下文模型通常需要 Attention 层面的优化。常见方向包括:
- FlashAttention:它不改变 Attention 的数学形式,而是优化计算过程中的显存读写和 IO 开销。可以理解为:同样做全量 Attention,但算得更快、更省显存。
- Sparse Attention:不再让每个 token 都关注所有 token,而是只关注一部分重要位置,从而减少计算量。
- Sliding Window Attention:每个 token 主要关注附近窗口内的 token,适合长文本、长对话这类局部连续性较强的任务。
- Global + Local Attention:大部分 token 只做局部 Attention,少数特殊 token 负责全局信息汇聚。
- Block Attention:把长序列切成多个 block,以块为单位组织计算,更适合工程实现和并行优化。
- Context Parallel / Ring Attention:当序列太长,单卡放不下时,可以把序列维度拆到多张 GPU 上,让多卡共同处理一个长上下文。
可以简单理解为:
- FlashAttention:全量 Attention 仍然做,但算得更高效;
- Sparse / Sliding Window:减少需要计算的 token 关系;
- Context Parallel:把超长序列拆到多卡上处理;
这些方法解决的是同一个问题:让长上下文在计算上变得可承受。
KV Cache 优化:让长上下文推理跑得起来
训练阶段关注 Attention 计算,推理阶段还要重点关注 KV Cache。KV Cache 的问题是:上下文越长,缓存越大;并发越高,缓存还会叠加。常见优化方法包括:
- GQA / MQA:标准 Multi-Head Attention 中,每个 Query head 通常都有自己的 Key / Value。GQA 和 MQA 会减少 KV head 数量,让多个 Query head 共享 Key / Value,从而显著降低 KV Cache(MHA:多个 Q head,各自配 K/V,GQA:多个 Q head 共享一组 K/V,MQA:所有 Q head 共享一组 K/V)。
- PagedAttention:像操作系统分页一样管理 KV Cache。它不要求每个请求的缓存连续存放,而是拆成固定大小的 block,减少显存碎片。
- KV Cache 量化:用 INT8、INT4 等低精度格式存储 KV,降低显存占用。代价是可能带来一定精度损失。
- Prefix Cache:如果多个请求共享相同前缀,比如系统提示词、固定文档开头、多轮对话历史,就可以复用这部分 KV Cache,减少重复 prefill。
- Chunked Prefill:把长 prompt 拆成多个 chunk 分块处理,避免超长 prefill 阻塞其他请求的 decode。
- KV Cache 压缩:对历史 token 的 KV 进行筛选、聚合或压缩,保留更重要的信息,减少长期上下文缓存成本。
KV Cache 优化的本质是:用更少显存、保存更长历史、服务更多并发、维持更低延迟。
对于长上下文推理来说,KV Cache 往往比模型参数本身更容易成为瓶颈。
长上下文训练:让模型真的学会使用长信息
只在推理时把窗口拉大是不够的。模型还需要在训练阶段见过足够多的长序列,并且学会如何利用长序列中的信息。否则模型可能只是“能接收长输入”,但并不会稳定利用长输入。长上下文训练通常包括几类数据和任务:
- 长序列继续预训练:在基础模型上继续使用更长序列训练,让模型适应长上下文分布。
- 长文档数据:使用论文、书籍、技术文档、代码仓库、法律文本、财报等真实长文本材料。
- 长距离检索任务:把关键信息放在很远的位置,让模型学会在长上下文中定位目标内容。
- Needle in a Haystack 任务:在大量无关文本中插入一条关键信息,训练模型从长上下文中找出“针”。
- 多跳推理数据:答案不能只依赖一个片段,而要综合多个远距离片段才能得到。
- 长上下文 SFT:使用长文档问答、长代码分析、多轮对话总结等指令数据,让模型学会按用户任务处理长材料。
这里有一个关键点:长上下文训练不是把短文本简单拼起来。
如果只是把很多短样本拼成一个长样本,模型可能学到的只是“上下文变长了”,但没有学会远距离依赖、干扰过滤和全局结构理解。真正有效的长上下文训练,要让模型面对这些问题:
- 关键信息很远;
- 干扰信息很多;
- 多个片段互相关联;
- 答案需要跨段落推理;
- 输出需要保持全局一致。
这样模型才会从“能放下长文本”,走向“能读懂长文本”。
长上下文与 RAG:不是替代,而是组合
长上下文出现后,一个常见误解是:既然模型能放下更多内容,是不是就不需要 RAG 了?答案是否定的。长上下文和 RAG 不是替代关系,而是互补关系。
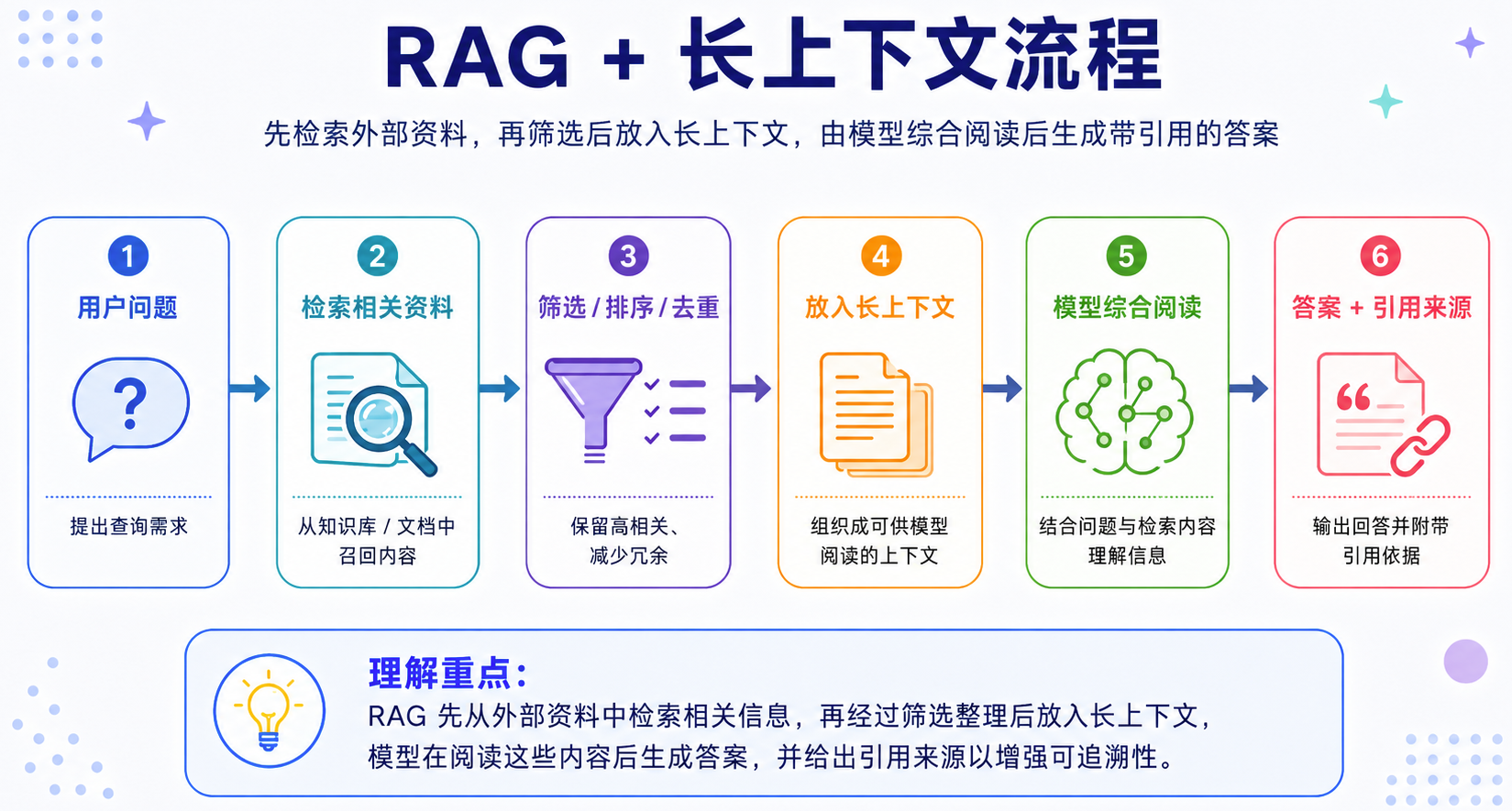
长上下文的优势是信息更完整,模型可以在更大范围内综合理解。但它也有代价:成本高、噪声多、推理慢。RAG 的优势是可以先筛选信息,把最相关的资料交给模型。它能降低成本,也能让知识更新更灵活。但它依赖检索质量,如果召回不到关键材料,模型后面也很难答对。
所以更合理的架构是:
- RAG 负责找资料、长上下文负责读资料;
- 模型负责综合推理、引用系统负责提供证据。
未来更常见的形态可能是:短期上下文 + 长上下文 + 外部记忆 + RAG + 工具调用。简单来说:长上下文解决“模型一次能读多少”,RAG 解决“应该让模型读什么”,外部记忆和工具调用解决“信息如何长期保存和动态获取”。
如何评估长上下文能力
长上下文不能只看“最大支持多少 token”。真正重要的是:模型能否在长输入里稳定找到信息、理解关系,并给出可靠答案。
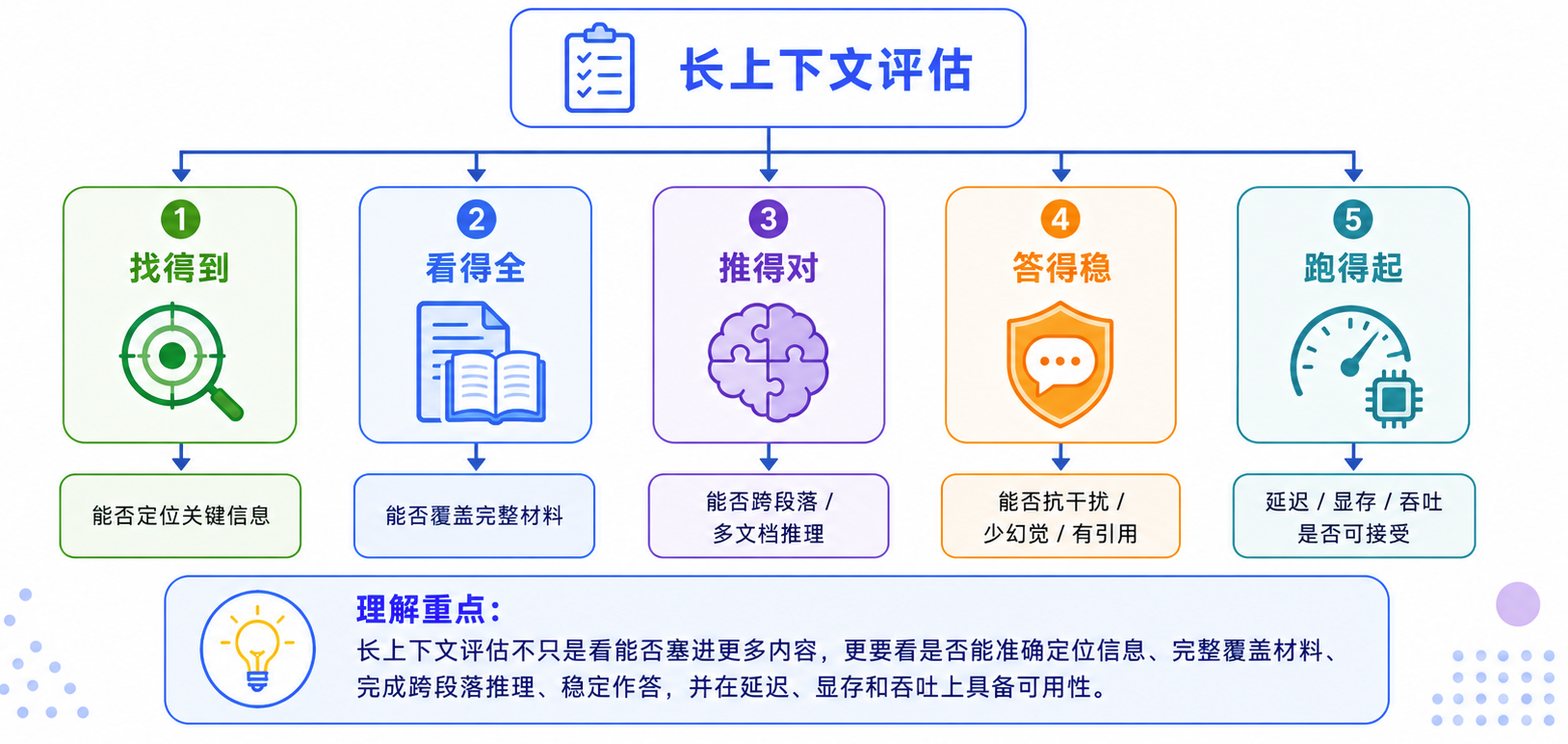
常见评估方向可以分成五类:
- 信息检索能力:典型方法是 Needle in a Haystack:在大量文本中插入一条关键信息,再观察模型能否准确找出来。但真实任务往往更复杂,需要支持多条关键信息、多位置分布和相似内容干扰。
- 长文档理解能力:不只是回答某一句话在哪里,而是能否理解完整文档结构,比如章节关系、核心观点、约束条件、前后依赖和全局结论。
- 跨段落推理能力:很多答案不会直接出现在一个位置,而是需要综合多个段落、多份文档,甚至多个时间点的信息。这类能力更接近真实业务场景。
- 抗干扰与可追溯性:长上下文里经常有重复信息、无关信息和冲突信息。好的模型不仅要答对,还要说明依据来自哪里,哪些信息存在冲突,哪些地方证据不足。
- 系统成本指标:长上下文能力最终要落到生产系统里,所以还要看 prefill 延迟、decode 延迟、KV Cache 显存占用、并发吞吐和单位请求成本。
生产环境里尤其要警惕一种情况:模型看起来读懂了大部分内容,但漏掉关键细节。比如合同问答中漏掉免责条款,代码分析中漏掉异常分支,这类错误比直接失败更危险。
所以,长上下文评估最好和引用、证据链、可追溯性结合起来。模型不仅要给答案,还要尽量说明:答案依据来自哪里,引用了哪些段落,哪些信息存在不确定性。
未来演进:从更长窗口到记忆系统
未来长上下文不会只是比拼 128K、1M、10M 这类数字。更重要的方向,是提高有效利用率、降低推理成本,并把上下文能力融入更完整的记忆系统。
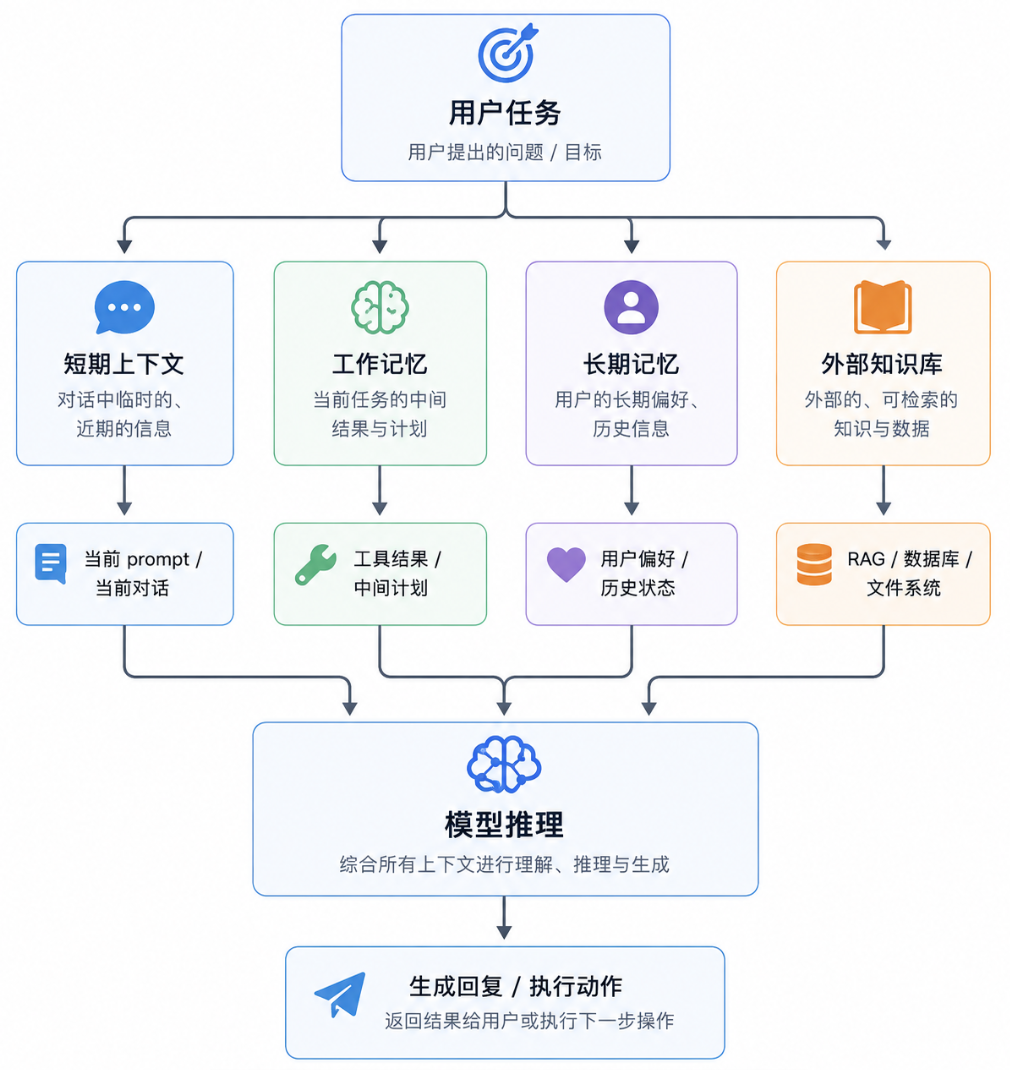
未来演进大致有五个方向:
- 更高效的 Attention:通过稀疏注意力、滑动窗口、块级注意力、上下文并行等方法,降低超长序列的计算压力。
- 更低成本的 KV Cache:通过 GQA/MQA、PagedAttention、KV 量化、缓存压缩和 Prefix Cache,让长上下文推理能承载更高并发。
- 更强的长程训练数据:模型需要见过真正有价值的长序列任务,而不是简单拼接短文本。未来训练会更强调长文档理解、多跳推理、干扰过滤和全局一致性。
- 上下文与 RAG 深度结合:RAG 负责“找资料”,长上下文负责“读资料”。更常见的系统不是把所有内容都塞进去,而是先检索、筛选、排序,再交给模型综合阅读。
- Agent 分层记忆:Agent 不能无限堆上下文。更合理的方式是把记忆分层:短期上下文保存当前任务,工作记忆保存中间状态,长期记忆保存用户偏好和历史结论,外部知识库存放可检索资料。
多模态也会进一步放大长上下文需求。一段视频、一场会议、一个设计稿、一组系统日志,都可能产生大量 token。未来模型处理的不会只是长文本,而是更长、更复杂的信息流。
总结
长上下文是 LLM 从聊天工具走向复杂任务系统的关键能力。它让模型可以处理完整文档、代码仓库、多轮对话、Agent 轨迹和多模态资料。但长上下文不是简单把窗口调大。它至少涉及五类问题:
- Attention 计算如何承受更长序列;
- KV Cache 如何控制显存成本;
- 位置编码如何泛化到更远位置;
- 模型如何真正利用长上下文信息;
- 系统如何在成本、延迟和准确率之间取得平衡。
简单总结:长上下文的目标,不是让模型机械地塞进更多 token,而是让模型在更长、更复杂的信息中,稳定找到关键内容,理解远距离关系,并以可承受的成本完成推理。这也是大模型从“会回答问题”,走向“能处理复杂信息任务”的重要一步。
