LLM 系列 (十二):预训练数据工程:大模型的燃料是如何炼成的
前面几篇我们已经把 LLM 的几条主线串起来了:从 AI 到 LLM,理解大模型为什么会出现;从数学、算法、Transformer 到 Dense/MoE,理解模型结构和学习机制;再到预训练、后训练、分布式训练、推理服务和长上下文,理解一套大模型系统如何被训练出来、部署出去。到了这里,还有一个更底层的问题需要单独展开:模型训练时,究竟吃了什么?
很多人讨论大模型时,容易把注意力放在参数量、GPU 数量、训练框架、Attention 结构、MoE 路由和推理加速上。但如果把大模型训练看成一条生产线,数据才是最早进入系统的原材料。没有好的数据,再大的模型也只是在更大规模地学习噪声;没有合理的数据配比,模型就会偏科;没有去重和去污染,模型可能只是记住了训练集和评测答案;没有隐私、安全、版权和版本治理,模型能力越强,风险也越难控制。
所以这篇文章想讲的,不是“怎么多收集一些文本”,而是预训练数据工程如何把互联网、书籍、代码、论文、百科、问答和合成样本,炼成一个可学习、可控制、可评估的数据分布。它贯穿数据来源、解析抽取、清洗规范化、去重、质量过滤、安全过滤、数据配比、采样、tokenization、packing、评测去污染、合成数据和版本治理,最终决定模型会学到什么、偏向什么、遗漏什么。
数据决定能力
讨论预训练时,我们经常会听到三个词:模型、算力、数据。模型决定表达能力,算力决定训练规模,数据决定模型学习的对象。可以把这三者想象成做饭:
| 训练要素 | 类比 | 作用 |
|---|---|---|
| 模型架构 | 锅和厨具 | 决定能处理什么样的食材、能做多复杂的菜 |
| 算力 | 火力和时间 | 决定能处理多少食材、能训练多久 |
| 数据 | 食材 | 决定最后做出来的味道和营养 |
锅再好,火再猛,如果食材是坏的,最后也只是更大规模地把坏味道炖出来。大模型训练也是一样:架构和算力决定“能不能学”,数据决定“学什么、学得偏不偏、学到的是知识还是噪声”。
预训练数据工程的知识地图
在进入细节前,可以先用一张图建立整体视角。预训练数据工程不是某一个清洗脚本,而是一条从数据来源到模型能力的完整链路。
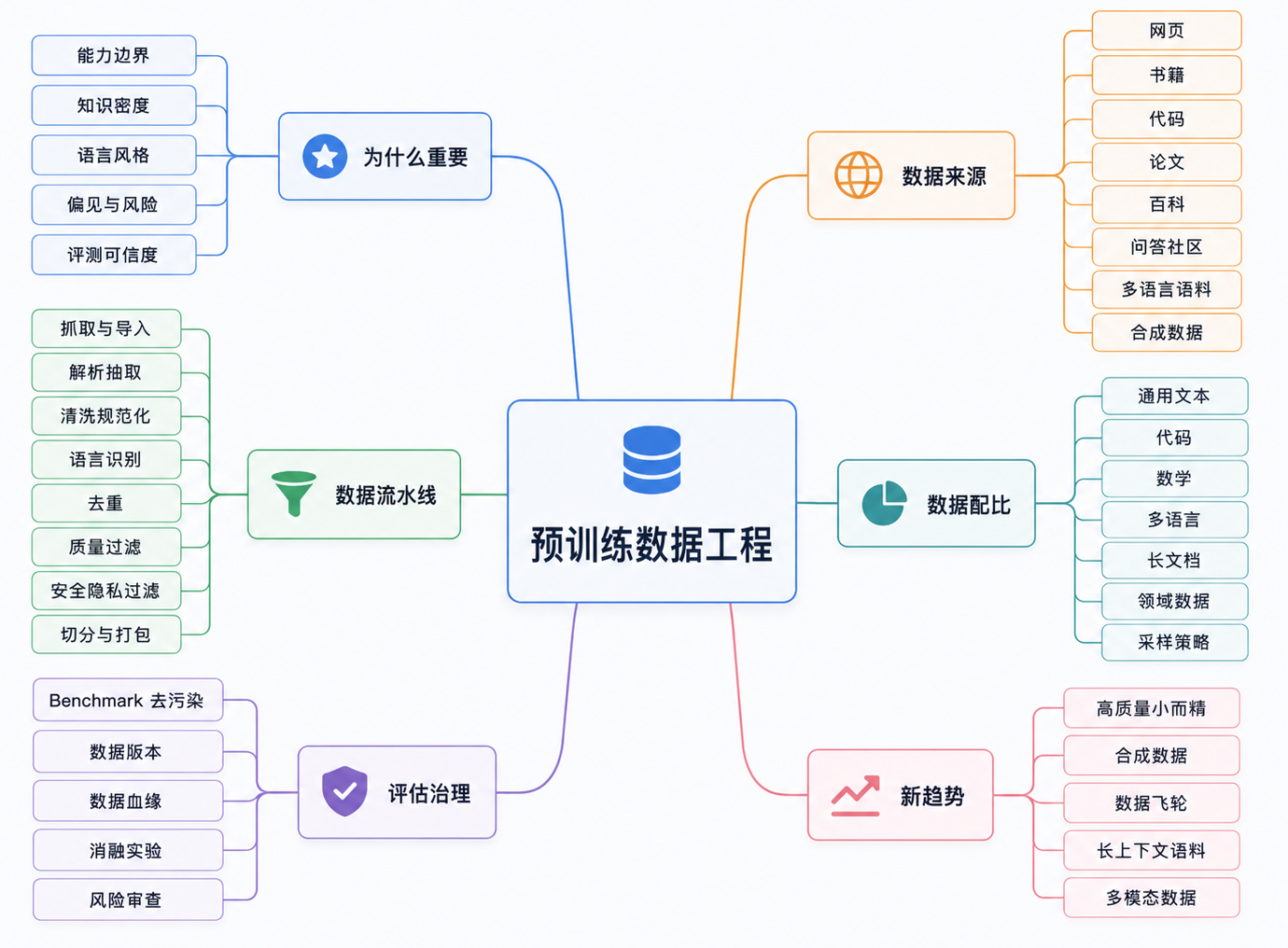
这张图的主线很简单:
1 | 原始内容世界 -> 数据工程流水线 -> 训练数据分布 -> 模型参数 -> 模型能力 |
也就是说,模型最后表现出来的能力差异,很多时候都可以沿着这条链路往回追:它看过什么数据,数据质量如何,哪些数据被放大,哪些数据被过滤,哪些数据污染了评测,哪些数据根本没有进入训练。
核心概念
后面会不断提到数据分布、去重、配比、污染、合成数据等词。先把这些概念放在这里,后面读起来会更顺。
| 概念 | 含义 | 为什么重要 |
|---|---|---|
| Corpus | 语料库,一批用于训练或评估的文本、代码、图文等数据集合 | 它是模型学习的原材料 |
| Document | 一个文档单元,可以是一篇网页、一章书、一个 README、一个代码文件 | 数据处理通常以文档为基本单位 |
| Token | 模型处理文本的基本单位,可能是字、词、子词或符号片段 | 预训练最终是在 token 序列上进行 |
| Data Distribution | 数据分布,指训练数据中不同内容、语言、领域、质量的整体比例 | 决定模型更常见什么、忽略什么 |
| Data Mixture | 数据混合配比,例如网页、代码、数学、多语言各占多少 | 本质上是模型能力的配方表 |
| Deduplication | 去重,删除完全重复或高度相似的内容 | 减少无效训练和记忆风险 |
| Quality Filtering | 质量过滤,把乱码、广告、采集页、低信息密度文本过滤掉 | 提升有效 token 密度 |
| PII | 个人可识别信息,例如手机号、邮箱、身份证号等 | 涉及隐私和合规风险 |
| Data Contamination | 数据污染,训练集中包含评测集、答案或高度相似样本 | 会让 benchmark 分数失真 |
| Packing | 把多个较短样本拼接成接近上下文长度的训练序列 | 提高训练效率 |
| Synthetic Data | 合成数据,由模型、规则、程序或人机协作生成的数据 | 可以补齐自然数据不足,但需要验证 |
| Data Ablation | 数据消融实验,移除或改变某类数据,观察模型能力变化 | 用来判断某类数据是否真的有价值 |
模型学到的是数据分布
自回归语言模型的训练目标,是根据前文预测下一个 token:
1 | P(x_t | x_1, x_2, ..., x_{t-1}) |
这意味着模型在预训练时,并不是被直接灌输“正确知识”,而是在不断学习训练语料中的统计规律。
- 如果训练数据里有大量高质量教材、论文和技术文章,模型更容易学到清晰的概念表达、结构化推理和专业术语。
- 如果训练数据里有大量代码仓库、issue、文档和测试用例,模型更容易学到编程模式、API 使用和调试习惯。
- 如果训练数据里有大量重复、广告、低质 SEO 页面和采集站,模型也会把这些表达模式学进去。
所以,数据工程的第一个意义是:它控制模型能看见什么世界。
数据不是越多越好,而是“有效 token”越多越好
早期大家容易把预训练规模简单理解成:token 越多 -> 模型越强。但真正做数据时会发现,token 和 token 的价值并不一样。比如下面三类文本:
1 | 高质量教材: |
它们都能产生 token,但学习价值完全不同。更准确的说法应该是:高质量、多样、低重复、低污染、配比合理的有效 token,才真正提升模型能力。
这也是为什么数据工程不能只统计 token 总量,还要统计质量、来源、重复率、语言分布、领域分布和污染风险。
数据决定模型的“偏科”
大模型的能力往往不是均匀发展的,而是和数据分布强相关。
| 数据问题 | 可能表现 |
|---|---|
| 代码数据少 | 写代码、读报错、理解工程结构能力弱 |
| 数学推导少 | 多步推理、公式变换、证明能力弱 |
| 高质量中文少 | 中文表达不自然,中文事实知识薄 |
| 长文档少 | 长上下文里容易丢主题、丢约束 |
| 专业领域数据少 | 医疗、法律、金融、芯片等领域容易泛泛而谈 |
| 低质网页过多 | 输出啰嗦、模板化、广告腔、信息密度低 |
| 重复数据过多 | 容易记忆样本,泛化能力不一定提升 |
| 评测数据泄露 | benchmark 分数虚高,但真实能力不足 |
这也是为什么不同模型即使参数规模接近,能力画像也可能差别很大。背后不只是架构不同,也可能是数据来源、清洗策略、配比策略、去污染策略和后训练数据不同。
预训练数据从哪里来?
预训练数据来源通常非常复杂。一个大模型看到的“世界”,不是单一数据集,而是很多来源混合后的结果。常见来源可以分成几类:
| 数据来源 | 典型内容 | 优点 | 风险 |
|---|---|---|---|
| 网页语料 | 新闻、博客、论坛、百科、文档站、问答页面 | 覆盖广、规模大、更新快 | 噪声多、重复多、广告多、版权和隐私复杂 |
| 书籍 | 教材、小说、科普、专业书 | 长文结构好,语言质量高 | 授权和版权要求高,领域覆盖有限 |
| 论文 | arXiv、会议论文、技术报告 | 知识密度高,结构严谨 | 解析难,公式图表处理复杂 |
| 代码 | Git 仓库、文档、issue、测试用例 | 提升编程能力和工具使用能力 | 许可证、重复仓库、自动生成代码、密钥泄露 |
| 百科 | Wikipedia、专业百科 | 实体知识密集,格式相对规范 | 更新频率、覆盖偏差、多语言质量差异 |
| 问答社区 | Stack Overflow、知乎式问答、论坛讨论 | 问题-答案结构天然适合任务学习 | 质量波动、主观内容多、噪声和过时答案 |
| 多语言数据 | 各语言网页、书籍、新闻和社区内容 | 提升跨语言和本地化能力 | 低资源语言数据稀缺,机器翻译腔问题 |
| 领域数据 | 法律条文、医疗文献、金融研报、企业文档 | 提升专业能力 | 合规、权限、隐私、专业质量评估难 |
| 合成数据 | 模型生成的题目、解释、代码、推理过程 | 可控、可扩展、可针对短板补齐 | 错误放大、风格单一、分布失真 |
预训练数据不是一个“文件夹”,而是一个经过选择、过滤、混合和治理的数据生态。
网页数据:规模最大,也最脏
网页是大模型预训练最重要的数据来源之一。它的优点是规模巨大、覆盖广泛,从新闻、博客、论坛、产品文档、百科到教程都能找到。但网页数据也很脏。一篇网页里真正有价值的正文,可能只占很小一部分,其余都是:
- 导航栏
- 页脚
- 相关推荐
- 广告
- 登录弹窗
- 评论模板
- 版权声明
- cookie 提示
- 站点统计代码
- 重复转载内容
如果直接把 HTML 扔给模型,模型会学到大量无意义模板。所以网页数据工程的第一步,通常不是“清洗文本”,而是:从网页中抽取真正的正文。
这一步做不好,后面的过滤再复杂,也会被前面的脏解析拖累。
代码数据:训练代码能力,也训练结构化思维
代码数据不只是让模型会写 Python、Java、C++。它还会让模型学到很多结构化能力:
- 变量命名和抽象
- 函数拆分
- API 调用模式
- 类型约束
- 测试用例
- 错误处理
- 依赖关系
- 注释与实现的对应关系
- issue、PR、commit message 里的问题描述和修复过程
这就是为什么代码数据对大模型很重要。它不只是“编程语料”,也是一种高密度的形式化语言和问题解决数据。但代码数据也有风险:
- 大量 fork 仓库会造成重复。
- minified JS、自动生成代码、lock 文件学习价值低。
- 许可证不一致,不能随意使用。
- 仓库里可能包含密钥、token、邮箱、内部地址等敏感信息。
- 测试集或面试题泄露会导致评测失真。
所以代码数据工程通常要额外做许可证过滤、仓库级去重、文件类型过滤、密钥扫描和近似重复检测。
高质量长文:决定模型能不能学会完整表达
书籍、论文、长篇教程、技术文档、规范文档有一个很重要的价值:它们天然包含长距离结构。一篇好文章会有主题、章节、递进、论证和总结;一本书会有完整的知识体系;一篇论文会有问题、方法、实验、结论。这些长文档对模型很重要,因为它们训练的不只是局部 token 预测,还包括:
- 长距离主题一致性
- 章节结构
- 概念逐步铺垫
- 论证链条
- 前后引用
- 摘要和展开之间的对应关系
长上下文能力不只是把位置编码拉长,还要让模型在训练中见过足够多高质量的长结构数据。
预训练数据流水线
从原始数据到训练样本,中间不是简单地“下载文本 -> 喂给模型”,而是一条很长的数据工程流水线。它看起来像传统 ETL,但目标不是生成报表,而是构造一个适合模型学习的数据分布。
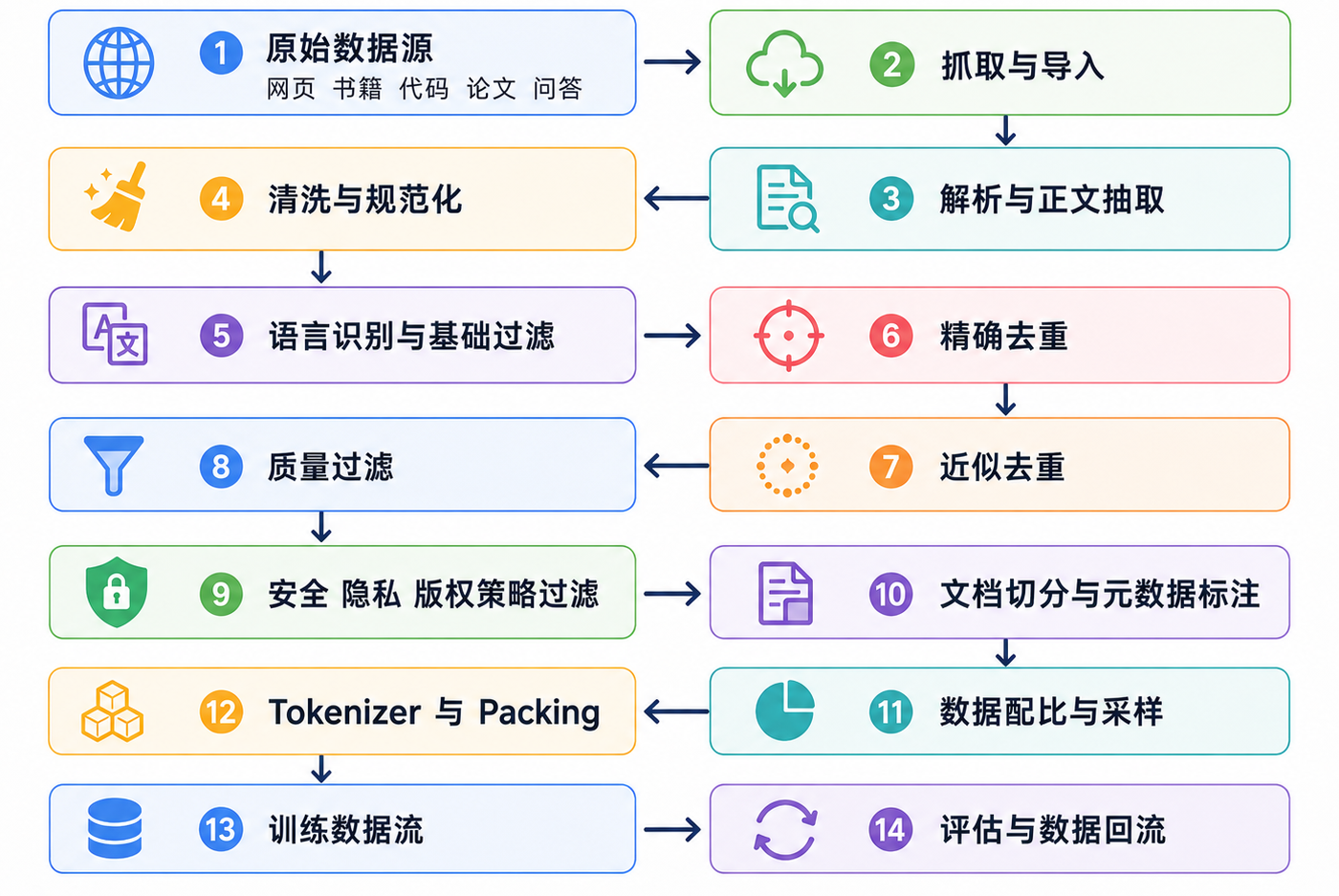
这条链路里,每一步都会改变模型最终看到的世界。解析错了,模型会学到乱码;去重没做好,模型会反复背同一批内容;质量过滤过狠,模型语言风格会变窄;格式设计不好,后面的训练、采样、追踪和复现实验都会变困难。
抓取与解析:先把世界变成文档
第一步是把不同来源的数据变成统一的文档对象。网页通常来自 Common Crawl、站点抓取或内部数据湖;代码来自 Git 仓库、包管理平台和 issue/PR;论文可能来自 arXiv、PDF、LaTeX 源文件;企业数据则可能来自文档系统、工单、IM、知识库和代码仓库。
业内常见做法不是直接保存一段纯文本,而是保留正文和元数据:
1 | { |
解析阶段的关键是“抽正文、保结构、去噪声”。网页要去掉导航栏、广告、脚本、页脚和相关推荐;PDF 要处理换行、分栏、公式、表格和引用;代码要保留文件路径、语言、缩进、注释和许可证;书籍和长文档要保留章节层级。
| 数据类型 | 业内常见方案 | 关键问题 |
|---|---|---|
| 网页 | WARC 解析、HTML boilerplate removal、Readability/Trafilatura 类正文抽取 | 广告、导航、模板、乱码 |
| PDF/论文 | GROBID、Nougat、Marker、Docling、LaTeX 解析 | 公式、表格、分栏、引用 |
| 代码 | Git clone/archive、Tree-sitter、语言检测、license 扫描、secret 扫描 | fork、生成代码、密钥、许可证 |
| 企业文档 | 权限导出、格式转换、脱敏、版本快照 | 权限、隐私、过期内容 |
| 问答社区 | HTML/Markdown 解析、问答结构保留、投票/时间元数据 | 低质回答、过时答案、主观内容 |
这一层最容易被低估。很多模型输出里的奇怪换行、广告腔、代码缩进错误,往往不是模型“突然犯病”,而是训练数据在解析阶段就坏了。
清洗与语言识别:稳定文本,但不要抹掉结构
清洗的目标不是把文本变得“统一好看”,而是减少无意义噪声,同时保留对学习有价值的结构。
| 内容 | 处理方式 |
|---|---|
| HTML 标签、脚本、样式 | 删除 |
| 广告、导航、重复页脚 | 删除 |
| 标题、段落、列表 | 保留 |
| Markdown 结构 | 保留 |
| 代码缩进 | 必须保留 |
| 数学公式 | 尽量保留或转成稳定格式 |
| 表格 | 转成 Markdown 或结构化文本 |
| 异常空白、不可见字符、乱码 | 规范化或过滤 |
语言识别也很关键。多语言模型不是把所有语言混在一起就行,而是要知道每篇文档主要是什么语言,再根据语言控制采样比例、过滤规则和质量阈值。业内常见方案是用 fastText、CLD3、langid、lingua 这类语言识别器,再结合字符集、词表、停用词和脚本比例做二次校验。
低资源语言尤其麻烦。采样太少,模型学不到;过度上采样,又会反复训练少量样本,造成记忆和过拟合。所以语言识别不只是清洗步骤,也是后面数据配比的基础。
去重:SimHash、MinHash 与“虚假的规模”
去重是预训练数据工程里最硬核、也最值钱的一步。互联网上重复内容非常多:转载文章、镜像站、采集站、多个 URL 指向同一篇正文、GitHub fork、模板页、重复页脚、同一段说明出现在大量文档里。如果不去重,训练集看起来很大,实际是在反复训练相同内容。这会带来三个问题:
- 浪费训练 token。
- 增加模型记忆风险。
- 让某些站点、模板、题库或 benchmark 被过度放大。
去重一般分三层:
| 层次 | 方法 | 解决什么问题 |
|---|---|---|
| 精确去重 | MD5/SHA/BLAKE3 hash | 完全一样的文档或片段 |
| 近似去重 | SimHash、MinHash + LSH | 转载、改写、插入广告、格式变化 |
| 语义去重 | Embedding + ANN 聚类 | 表达不同但语义高度重复的内容 |
精确去重最简单:对规范化后的正文算 hash,相同 hash 只保留一份。NVIDIA NeMo Curator 的 exact dedup 就是这类思路,用文档文本的 MD5 来识别完全重复文档。
近似去重要复杂得多。这里最常见的是 SimHash 和 MinHash。
SimHash 的思路是:把文档拆成特征,比如词、字符 n-gram、token n-gram;每个特征 hash 成一个 bit 向量,再按权重累加,最后得到一个 64-bit 或 128-bit 指纹。两个文档的 SimHash 如果汉明距离很小,就认为它们很相似。
1 | 文档 -> 特征集合 -> 特征 hash -> 加权求和 -> SimHash 指纹 -> 比较汉明距离 |
SimHash 的优点是快、指纹小、适合大规模网页近似去重,尤其适合发现模板页、轻微改写页、正文大体相同的转载页。缺点是它更像“快速相似度指纹”,对阈值比较敏感,遇到长文局部重复或结构变化时不一定足够稳。
MinHash 更常用于大规模文本 near-dedup。它先把文档切成 shingle,比如字符 5-gram、词 3-gram、token n-gram,然后把文档表示成一个集合。两个文档的 Jaccard 相似度越高,说明它们共享的 shingle 越多。MinHash 用一组最小 hash 值近似估计 Jaccard 相似度,再用 LSH 把相似文档快速分桶。
1 | 文档 -> shingles -> MinHash signatures -> LSH 分桶 -> 候选相似对 -> 聚类 -> 删除重复 |
MinHash + LSH 的优点是更适合处理“正文大部分相同但有增删改”的文档,也是现在很多开源数据清洗管线采用的主力方案。NeMo Curator 的 fuzzy dedup 就使用 MinHash 和 LSH 来找近似重复文档;FineWeb、Dolma、DataTrove 这类开放数据工程也都非常重视 dedup 和 filtering 的组合。
去重时还有一个工程细节:发现重复簇后,不能随机删。通常会保留质量更高、来源更可信、时间更新、正文更完整、元数据更清晰的那一份。
质量、安全与版权过滤:判断哪些内容值得学
去重之后,还要判断一段文本值不值得模型学习。质量过滤通常不是单一模型完成,而是多层信号组合:
| 信号 | 可能说明 |
|---|---|
| 文档太短 | 可能是导航页、碎片页 |
重复 n-gram 很多 |
可能是模板、广告、采集页 |
| 标点比例异常 | 可能是乱码、列表堆叠 |
| 链接比例过高 | 可能是目录页或聚合页 |
| 困惑度异常高 | 不像自然语言,可能解析失败 |
| 困惑度异常低 | 可能是模板化重复内容 |
| 分类器质量分低 | 可能是垃圾、成人、恶意或低质量内容 |
| 教育价值分高 | 适合保留或上采样 |
业内常见做法是“规则过滤 + 模型过滤 + 抽样人工审查”。规则过滤负责便宜、稳定、可解释的信号,比如长度、重复率、字符比例;模型过滤负责更抽象的质量判断,比如教育价值、毒性、成人内容、垃圾内容;人工抽检负责校准阈值,避免过滤器把某些语言、领域或表达风格误伤。
安全和版权过滤也要在这一层做。常见处理包括:
| 风险 | 解决方案 |
|---|---|
| PII 隐私信息 | 正则、NER、Presidio 类脱敏工具、抽样审计 |
| 代码密钥 | secret scanner、token pattern、熵检测 |
| 有害内容 | 安全分类器、黑白名单、策略规则 |
| 版权风险 | robots、terms、license 元数据和来源白名单等风险控制策略 |
| benchmark 污染 | 精确匹配、n-gram 匹配、近似匹配、来源排除 |
这里有一个重要平衡:过滤不是越狠越好。只保留“像百科”的文本,模型可能会变得不会聊天;只保留高学历文本,会损失口语、社区知识和真实用户表达。好的数据工程是在干净、多样、真实之间做取舍。
训练数据格式:从文档到可训练的数据流
数据清洗完,还要选择训练数据格式。这一步很容易被忽略,但它会直接影响训练吞吐、随机访问、断点恢复、数据版本管理和问题追踪。可以把格式分成三层:
| 阶段 | 常见格式 | 适合场景 |
|---|---|---|
| 原始归档层 | WARC、PDF、HTML、Git archive、对象存储原文件 | 保留原始证据,方便复查 |
| 清洗文档层 | JSONL、Parquet、Arrow、Iceberg/Delta 表 | 数据分析、过滤、去重、配比、版本管理 |
| 训练样本层 | tokenized binary、Megatron .bin/.idx、MDS、WebDataset、TFRecord | 高吞吐训练、流式读取、分布式采样 |
小规模实验可以用 JSONL,因为直观、好调试。但到大规模预训练,JSONL 的压缩、列裁剪、扫描效率和 schema 管理都不够理想。工业里更常见的是 Parquet/Arrow 这类列式格式:Parquet 适合数据湖存储和大规模扫描,Arrow 适合本地缓存和高效内存映射。Hugging Face Datasets 使用 Arrow 做本地 cache 和 memory mapping,就是为了让大数据集不必一次性加载进内存。
清洗后的文档层通常会包含这些字段:
1 | { |
真正进入训练前,还要 tokenization 和 packing。
1 | 文档文本 -> tokenizer -> token ids -> 加 EOD -> 切分/拼接 -> 固定长度训练序列 |
以 Megatron-LM 系训练为例,常见做法是把 tokenized 数据写成 .bin/.idx:.bin 存 token id,.idx 存长度、offset、文档边界等索引信息,方便训练时高效随机访问。NeMo Curator 也提供了直接导出 Megatron .bin/.idx 的 writer。
Packing 也有讲究。为了提高 GPU 利用率,短文档通常会被拼接到接近上下文长度。但不能无脑拼:文档之间要加 EOD token;长文档要考虑是否跨段保留结构;代码、数学、长上下文样本有时要单独处理,避免被普通网页样本稀释。
最终,一个成熟的数据流不是“一个大文件”,而是一组可追踪、可采样、可复现的训练 shard:
1 | dataset_v12/ |
评估回流:数据流水线不是一次性的
数据工程不是训练前做完就结束。模型训练后,评测结果和错误案例要回流到数据侧。
- 如果模型代码能力差,可能要检查代码数据比例、许可证过滤、生成代码比例、测试样本质量。
- 如果中文表达弱,可能要检查高质量中文数据量、中文网页过滤是否过狠、中文长文档是否不足。
- 如果长上下文容易丢约束,可能要检查训练中是否有足够真实长文档,而不只是短文本 packing。
- 如果 benchmark 分数异常高,要反查是否存在数据污染。
成熟团队会把这件事做成闭环:
1 | 训练结果 -> 能力评测 -> 错误分析 -> 数据归因 -> 调整过滤/配比/采样 -> 下一轮训练 |
所以,预训练数据流水线真正的目标不是产出一个“干净数据集”,而是建立一个可以持续迭代的能力工厂。
数据配比:能力的配方表
当数据经过解析、清洗、去重和过滤之后,还有一个更关键的问题:训练时,各类数据应该按什么比例出现?这就是数据配比。
数据配比不是简单地把所有数据混在一起,也不是谁的数据量大谁就占比高。真实的训练数据分布,往往是人为设计出来的学习分布:哪些数据多看一点,哪些数据少看一点,哪些数据放到后期再看,都会影响模型最后形成的能力形状。可以先用一张图理解:
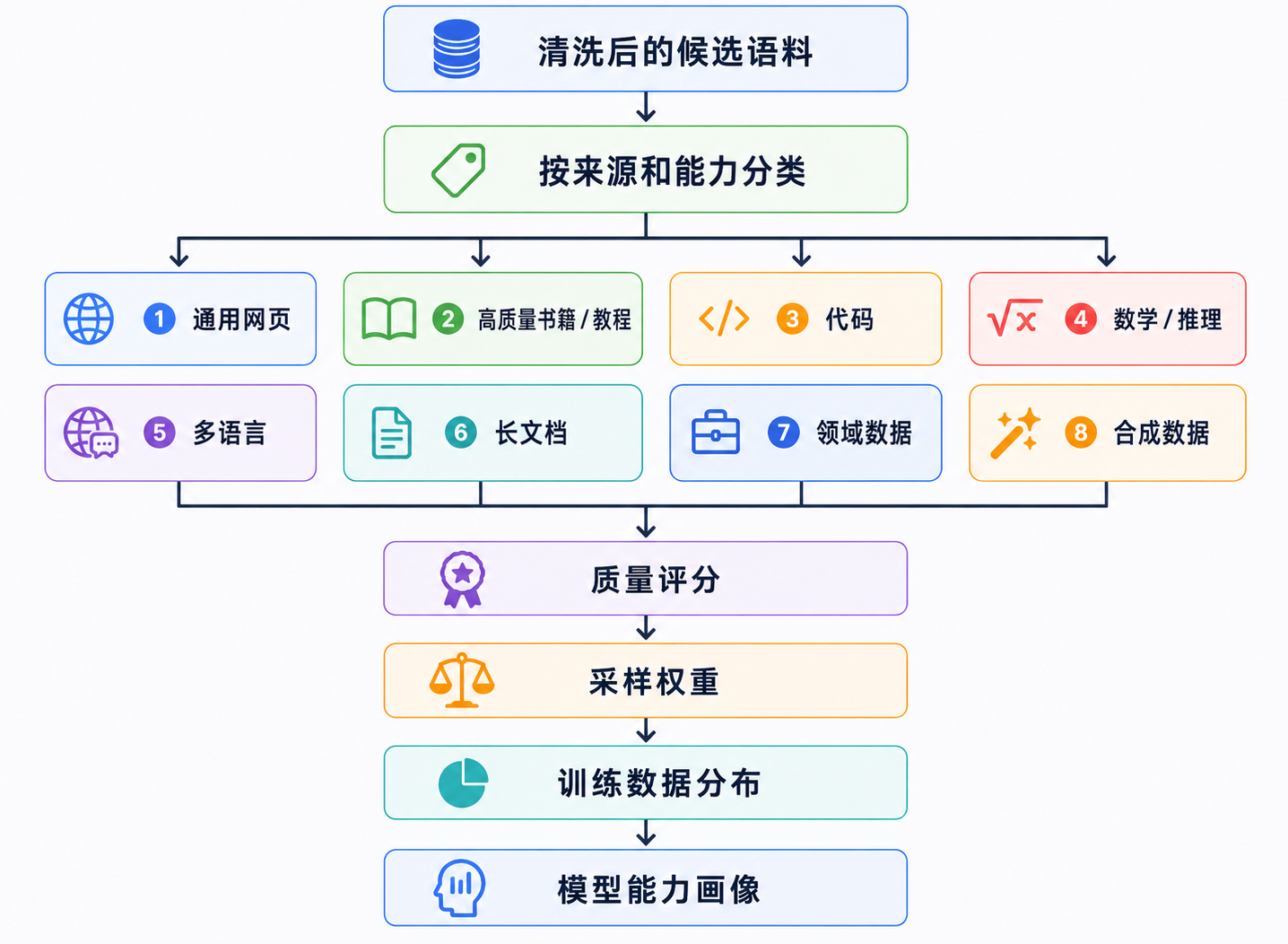
一句话理解:训练数据分布不是原始互联网分布,而是根据质量、能力目标和风险控制重新调配后的学习分布。
数据配比决定模型偏向什么
不同类型的数据,对模型能力的影响是不一样的。
| 数据类型 | 对能力的影响 | 配比过低的问题 | 配比过高的问题 |
|---|---|---|---|
| 通用网页 | 常识、语言覆盖、世界知识 | 知识面窄,表达不自然 | 噪声和低质内容风险高 |
| 高质量书籍/教程 | 长文结构、概念解释、稳定表达 | 文章组织和系统讲解能力弱 | 风格可能过于书面 |
| 代码 | 编程、API、结构化推理 | 代码能力弱 | 普通语言里可能混入代码式表达 |
| 数学/推理 | 多步推理、符号操作、证明 | 复杂推理能力弱 | 如果质量差,容易学到伪推理 |
| 多语言 | 跨语言、本地文化、翻译 | 非英语能力弱 | 低质量语言数据会放大噪声 |
| 长文档 | 长上下文、章节结构、长期依赖 | 长文本里容易丢信息 | packing 和训练效率压力大 |
| 领域数据 | 医疗、法律、金融、企业知识等专业能力 | 专业问答空泛 | 可能损伤通用能力或引入合规风险 |
| 合成数据 | 针对性补短板 | 无法补齐稀缺能力 | 风格收缩、错误放大 |
可以把它想象成一个“能力调音台”:
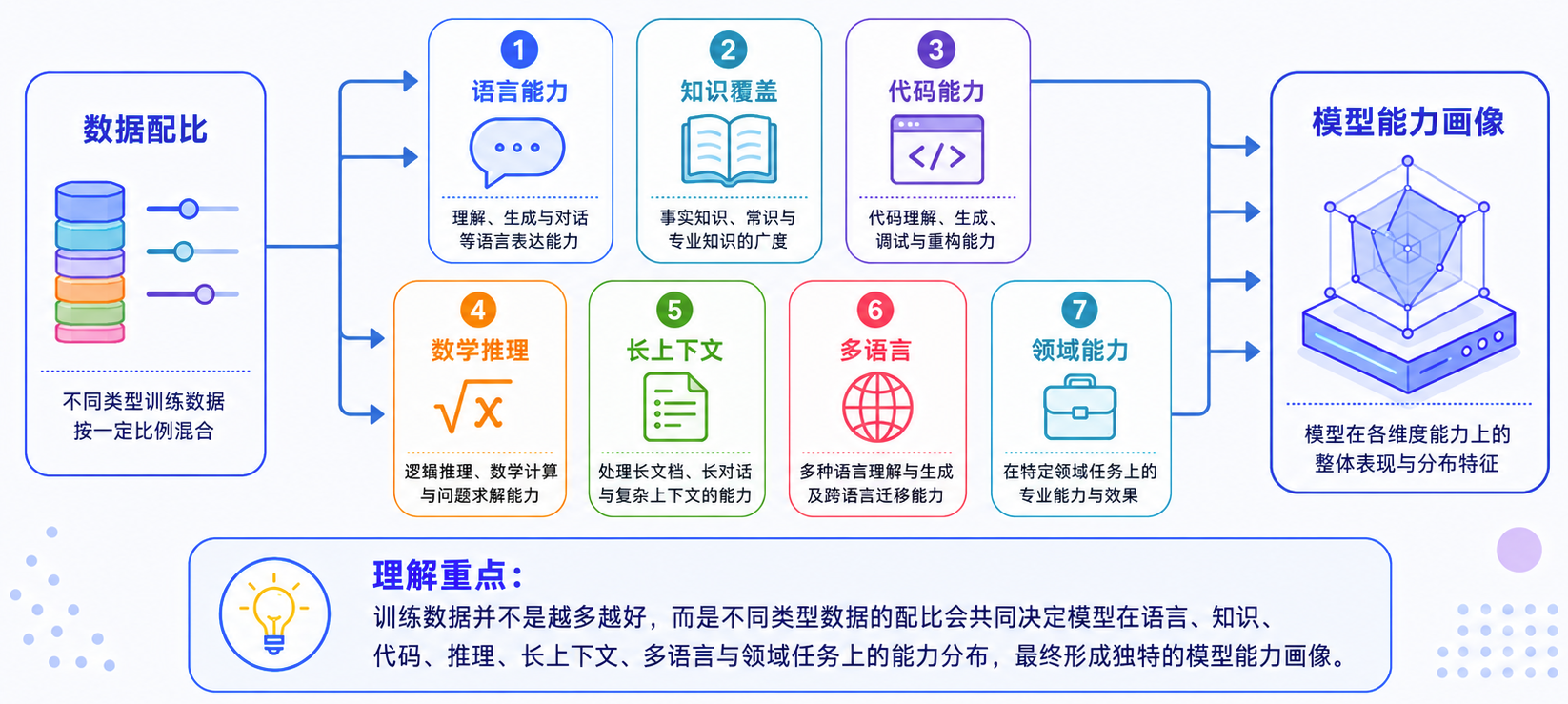
所以,两个模型即使参数规模接近,能力表现也可能很不一样。一个更会写代码,一个更会中文表达,一个更擅长数学,一个更适合企业知识问答,背后往往不只是架构差异,也可能是数据配比差异。
配比不是静态的,而是分阶段变化的
预训练不一定从头到尾都使用同一套数据比例。一种常见思路是分阶段调整:
- 早期:覆盖广,多样性强,让模型先学语言、常识和基本模式;
- 中期:提高高质量知识、代码、数学、长文档比例;
- 后期:加入更难、更高质量、更任务相关的数据做能力打磨。
这有点像人的学习过程:
- 先广泛阅读,建立语言和常识底座;
- 再学习教材、代码和专业材料;
- 最后做更难的题和更复杂的项目。
如下图所示:
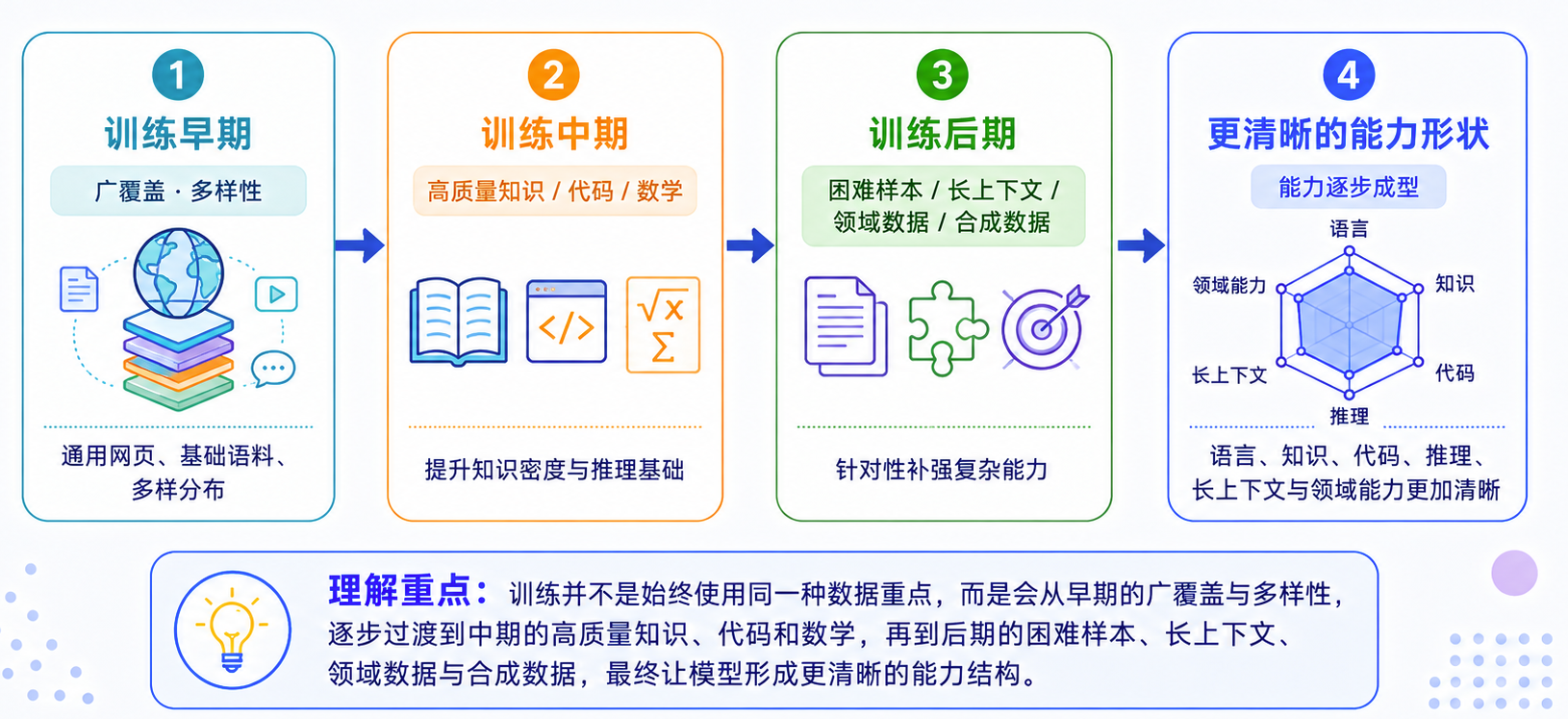
这里的关键理解一个原则:数据顺序和数据比例,会影响模型最后形成的能力路径。如果早期低质网页太多,模型可能先学到很多噪声模式;如果后期没有足够高质量数据,模型能力可能停留在“会说很多话”,但不够准确、不够结构化、不够专业。
上采样与下采样:让重要数据被模型看见
有些数据很重要,但天然规模小。例如高质量数学题、低资源语言、专业领域文档、长上下文问答。如果完全按原始数据量采样,它们在训练中出现得太少,模型几乎学不到。于是工程上会对这些数据做上采样。相反,有些数据规模巨大但质量一般,例如低质网页、采集站内容、模板化页面,就需要下采样。
- 上采样:重要但少的数据,多看几遍;
- 下采样:多但价值低的数据,少看一点;
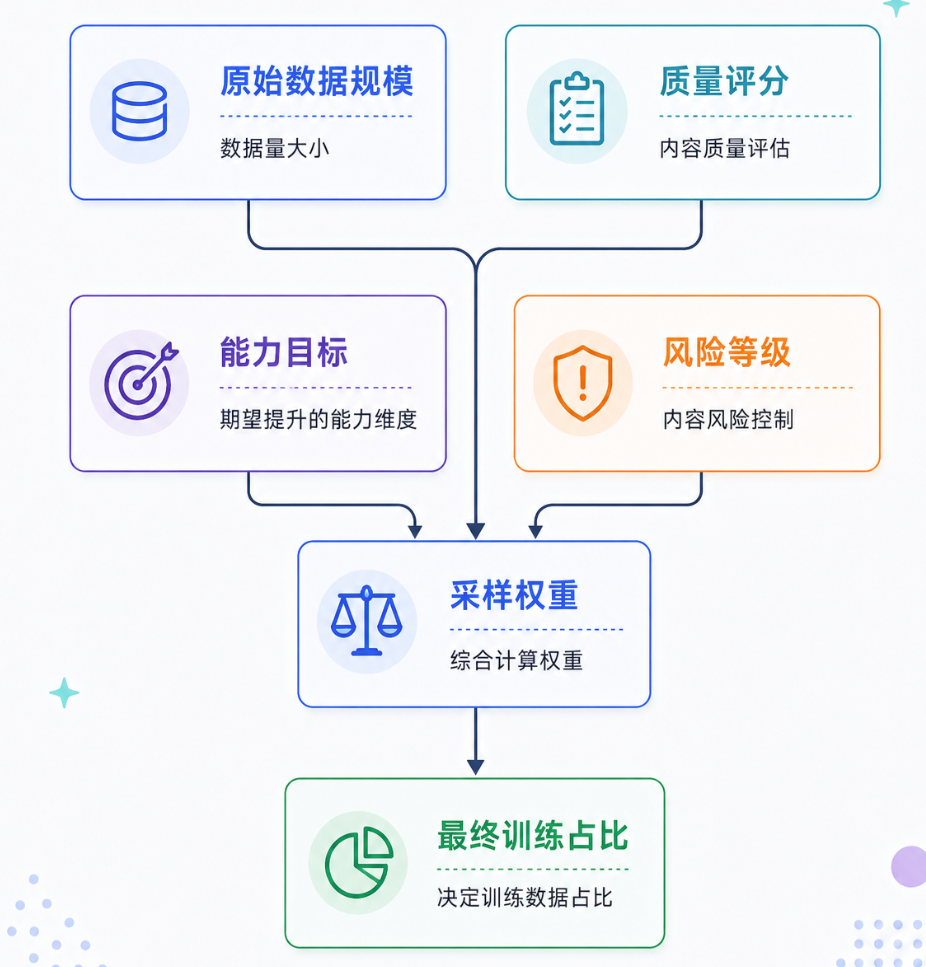
可以用一个简单公式理解:
1 | 最终采样权重 = 原始规模权重 × 质量权重 × 能力目标权重 × 风险控制权重 |
举个例子:
| 数据 | 原始规模 | 质量 | 能力价值 | 采样策略 |
|---|---|---|---|---|
| 普通网页 | 很大 | 中等 | 常识覆盖 | 下采样 |
| 高质量教材 | 中等 | 高 | 概念解释 | 上采样 |
| 数学推导 | 较小 | 高 | 推理能力 | 上采样 |
| 低质采集页 | 很大 | 低 | 价值低 | 强过滤或下采样 |
| 低资源语言 | 很小 | 不稳定 | 多语言能力 | 清洗后适度上采样 |
| 企业领域文档 | 小 | 高 | 专业能力 | 权限过滤后上采样 |
这说明,模型训练看到的世界,并不是数据自然存在的比例,而是工程师重新设计后的比例。
配比要写进配置,而不是写在脑子里
成熟的数据工程里,配比通常不会靠口头约定,而是写成可追踪、可复现的配置。例如可以有一个类似这样的 mixture.yaml:
1 | dataset_mixture: |
这个配置不一定代表真实模型比例,只是说明一个重要思想:数据配比应该是工程资产,而不是拍脑袋经验。
这样团队才能回答:
- 这次模型用了哪些数据?
- 每类数据占比多少?
- 哪些数据被上采样?
- 哪些数据被下采样?
- 配比变化后,哪些能力变好了?
- 哪些能力被牺牲了?
数据消融:配比调整必须能被验证
如果一个团队说:我们把数学数据加到 10%,模型推理更强了。这句话要可信,至少需要配套实验。
| 要检查的问题 | 为什么重要 |
|---|---|
| 其他训练条件是否基本一致 | 避免把训练步数、学习率、batch size 的影响误认为数据效果 |
| 数学评测是否提升 | 验证目标能力是否真的增强 |
| 通用问答是否下降 | 检查是否牺牲通用能力 |
| 代码能力有没有变化 | 防止数据挤占导致其他能力退化 |
| 中文能力有没有变化 | 检查语言分布是否被稀释 |
| 提升来自数据质量还是数据数量 | 判断是“更好数据”还是“更多 token”带来的收益 |
| 是否存在评测污染 | 防止模型只是看过题目 |
这就是数据消融实验:只改变某类数据,观察模型能力变化。如下图所示:
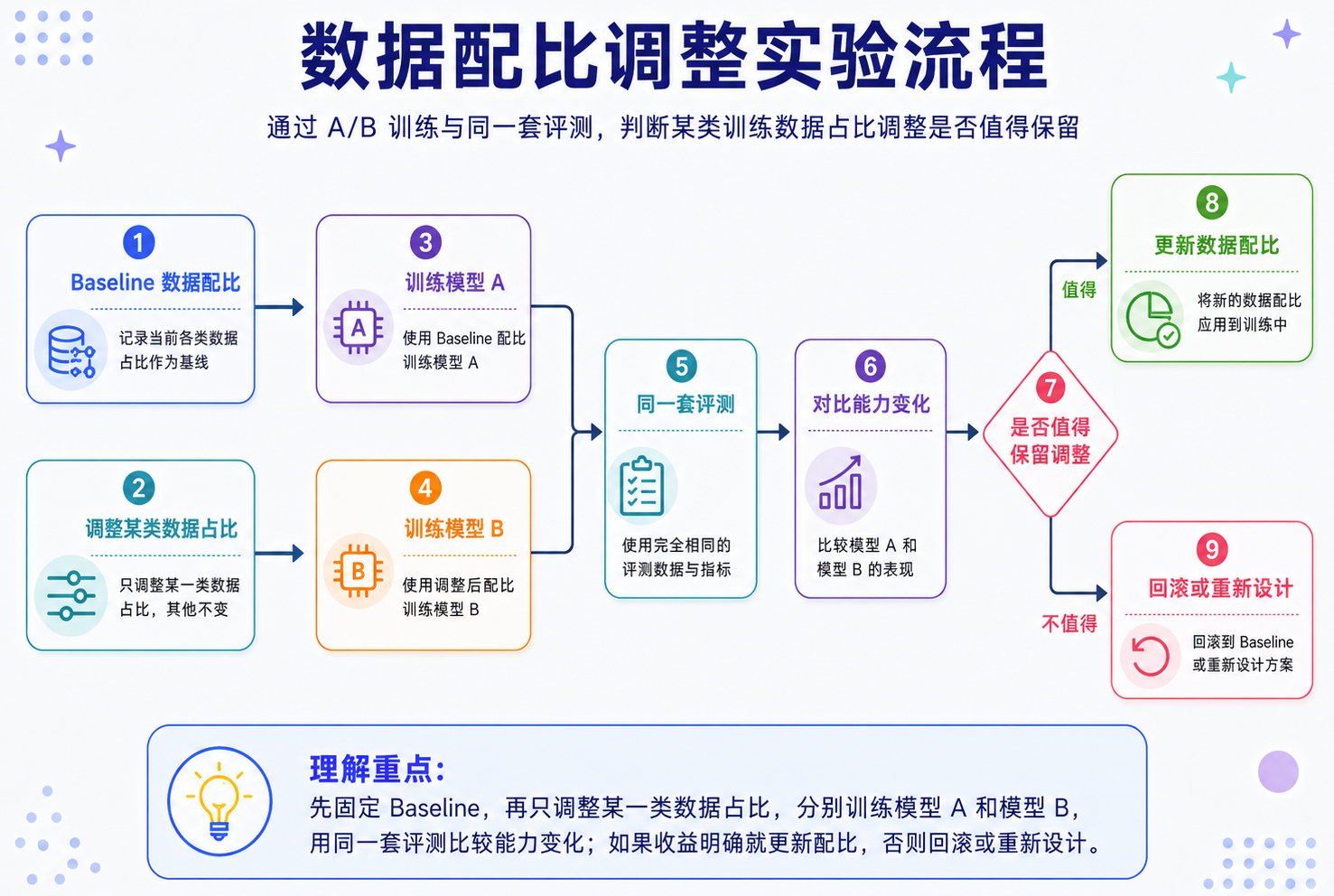
没有数据消融,配比调整就很容易变成玄学。看起来是在优化模型,实际可能只是把某类 benchmark 刷高了,或者用一个能力的提升换来了另一个能力的下降。
小结:配比决定模型的能力形状
数据配比不是简单的百分比问题,而是模型能力设计问题。它决定了模型:
- 更熟悉哪类知识。
- 更擅长哪种语言。
- 是否会写代码。
- 是否能做数学推理。
- 是否能读长文档。
- 是否懂某个专业领域。
- 是否容易学到低质表达。
- 是否会在某些能力上偏科。
最后可以用一句话总结:数据清洗决定模型少学坏东西,数据配比决定模型重点学什么。配比设计得越清楚,模型能力画像就越可控。
评测污染、合成数据与长上下文:数据工程的三个高级问题
前面讲的数据来源、清洗、去重、过滤和配比,更多是在解决“训练数据怎么变干净、怎么变有效”的问题。但数据工程还不止这些。越往后走,会遇到三个更高级的问题:
- 评测是否可信?
- 自然数据不够怎么办?
- 模型如何真正学会长上下文?
这三个问题分别对应评测污染、合成数据和长上下文数据工程。它们决定的不是数据集表面有多大,而是模型能力到底能不能被真实验证、能不能持续扩展、能不能处理更复杂的信息结构。
评测污染:分数可信吗?
预训练数据工程里有一个非常重要但常被忽略的问题:训练集是否包含了评测集?如果包含了,模型在 benchmark 上表现很好,不一定代表它真的具备泛化能力,也可能只是训练时见过题目、答案或解析。这就是数据污染。
数据污染很容易发生,因为很多评测集本身是公开的。一旦公开,它们就可能被放进 GitHub 仓库,被博客讲解,被论坛讨论,被论文引用,被教程整理,也可能被数据集镜像站收录。然后这些内容又会进入网页语料、代码语料或论文语料。污染路径如下所示:
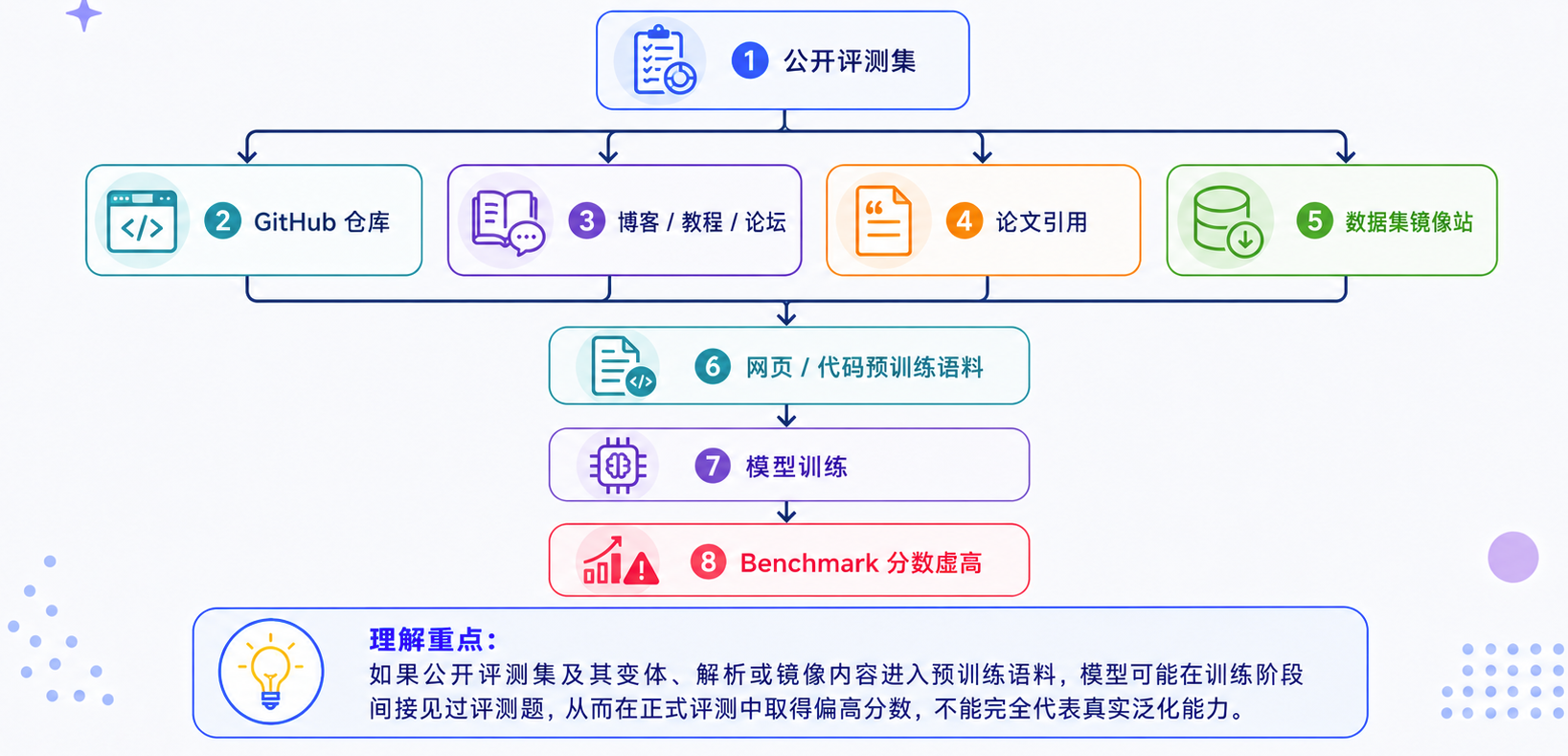
去污染通常要分几层做:
| 层次 | 做法 | 解决什么问题 |
|---|---|---|
| 精确匹配 | 搜索评测题文本、答案文本 | 原题和答案直接泄露 |
| n-gram 匹配 | 找出和评测样本高度重合的片段 | 局部复制、题目解析泄露 |
| 近似匹配 | 检测改写、转载、格式变化后的相似样本 | 改写版题目和镜像内容 |
| 元数据过滤 | 排除 benchmark 仓库、评测代码目录、数据集镜像站 | 来源级污染 |
| 时间切分 | 使用训练截止时间之后的新评测 | 降低提前见过的概率 |
| 私有评测 | 保留不公开的内部评测集 | 验证真实泛化能力 |
去污染不是为了让数字难看,而是为了让数字可信。如果一个模型在干净评测上提升,说明它更可能真的学会了能力;如果只在可能泄露的 benchmark 上提升,结果就要谨慎解释。
这里还要区分记忆和泛化。大模型当然会记住一些内容,训练数据里反复出现的事实、代码片段、文章、题库,都可能被模型记忆。问题不在于模型是否完全不记忆,而在于:
- 它是否能把训练中学到的规律,迁移到没见过的问题上?
数据工程要做的,是减少无意义记忆,提高可泛化学习:减少重复样本,提高数据多样性,控制 benchmark 泄露,让评测覆盖新问题,并用消融实验判断能力来源。
合成数据:可控扩展,但必须验证
传统预训练主要依赖人类已经产生的数据:网页、书籍、代码、论文、百科和问答。但随着模型能力增强,越来越多训练数据开始由模型参与生成,这就是合成数据。合成数据的核心价值是:当自然数据不够、太脏、太贵或不够可控时,用模型、规则、程序或人机协作生成更有目标的数据。它既可以进入继续预训练,也更常出现在后训练、推理数据和评测构造中,关键区别在于目标、格式和验证方式。
它特别适合补齐那些稀缺、昂贵、需要结构化验证的数据短板。
| 场景 | 为什么适合合成 |
|---|---|
| 数学题 | 可以生成题目、步骤、答案,并用规则或程序验证 |
| 代码题 | 可以生成函数、测试用例、修复任务,并运行测试验证 |
| 指令数据 | 可以围绕任务类型批量生成问答和解释 |
| 长上下文任务 | 可以构造长文档、跨段落问题和引用答案 |
| 多语言迁移 | 可以翻译、改写、对齐多语言内容 |
| 领域数据增强 | 可以把专业资料改写成问答、摘要、案例 |
| 安全数据 | 可以生成拒答、边界、风险识别样本 |
合成数据的优势是可控。想要更多数学证明,可以生成数学证明;想要更多代码调试,可以生成 bug-fix 样本;想要更多长文问答,可以基于长文构造问题。
但合成数据必须有验证。模型会编,也会把编出来的东西包装得很像真的。所以合成数据不能只看“像不像”,还要看“对不对”。
| 数据类型 | 验证方式 |
|---|---|
| 数学 | 规则校验、符号计算、答案一致性、多模型交叉验证 |
| 代码 | 单元测试、编译、静态检查、运行结果 |
| 知识问答 | 检索证据、来源引用、事实一致性检查 |
| 长文问答 | 答案必须能在原文定位,引用段落可追踪 |
| 安全样本 | 人工审核、策略规则、红队测试 |
| 领域样本 | 专家审核、术语一致性、来源追溯 |
当模型足够强之后,会形成一种数据飞轮:
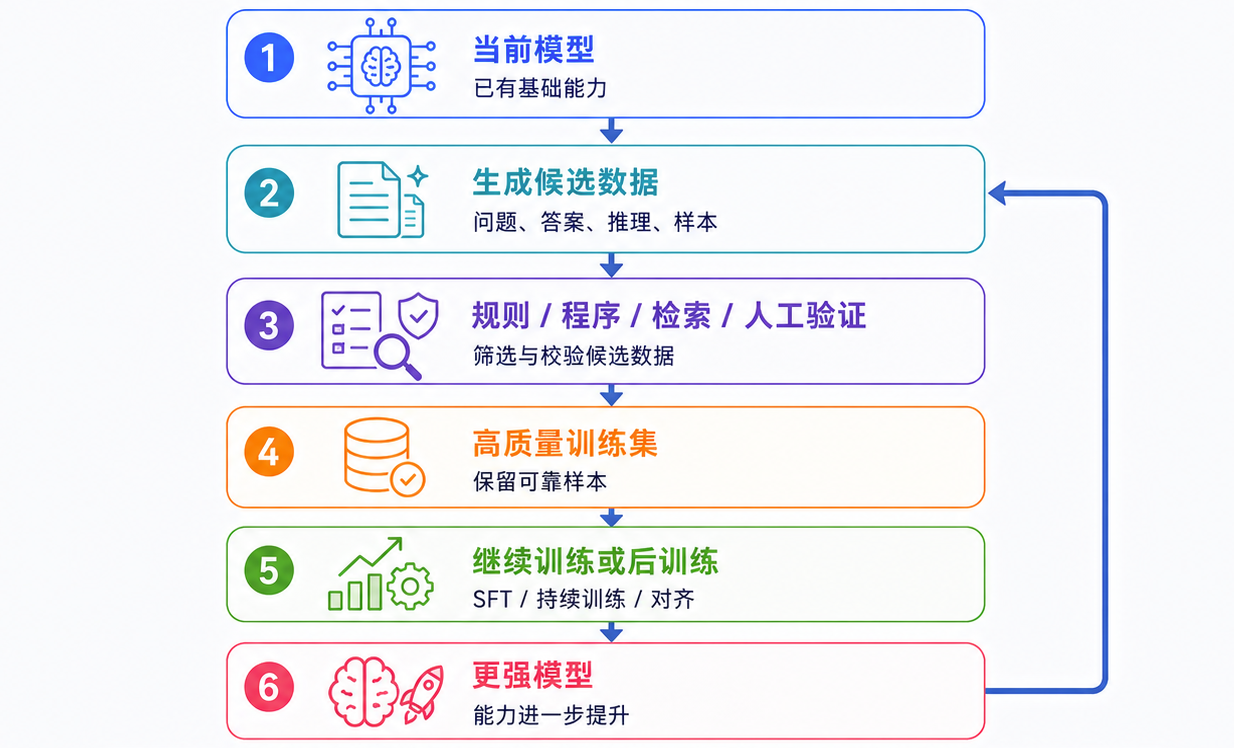
这个飞轮的关键不在“模型生成”,而在“验证筛选”。如果只是让模型无限生成,再拿生成内容继续训练,可能会导致错误被放大、表达风格变窄、数据多样性下降,模型也会越来越擅长模仿模型,而不是理解真实世界。
健康的数据飞轮应该是:
- 生成更多候选 -> 用更强验证筛掉坏样本 -> 只把高价值样本放回训练。
合成数据既可以进入继续预训练,也更常出现在后训练、推理数据和评测构造中,关键区别在于目标、格式和验证方式。
长上下文数据:不是拼长,而是保结构
上一篇文章已经讨论过长上下文了:模型如何读懂更长的信息。这里从数据工程的角度再看下这个问题:
- 长上下文能力不只是位置编码、Attention 优化和推理缓存问题;
- 也取决于模型训练时有没有见过足够多高质量长序列。
长上下文数据不等于把短文本简单拼长。最简单的做法是:
1 | 短文 A + 短文 B + 短文 C + 短文 D |
这种 packing 可以提高训练效率,但不一定训练真正的长文理解。因为这些短文之间可能没有任何关系,模型学到的更多是“如何在长窗口里忽略无关内容”,而不是“如何理解一个长结构”。真正有价值的长上下文数据,应该包含长距离依赖:
- 前文定义的概念,后文继续使用。
- 开头提出的问题,结尾给出答案。
- 多章节之间有递进关系。
- 代码仓库里多个文件互相引用。
- 长合同前后条款互相约束。
- 论文中的方法、实验和结论相互对应。
长文档训练还要特别重视结构保留:
| 结构 | 价值 |
|---|---|
| 标题层级 | 帮助模型理解章节关系 |
| 段落 | 保留语义单元 |
| 列表 | 保留并列和步骤 |
| 表格 | 保留属性对比 |
| 代码文件路径 | 帮助理解仓库结构 |
| 引用和脚注 | 帮助追踪来源 |
| 文档边界 | 避免不同文档无意义混合 |
这也是为什么粗暴清洗会伤害长上下文能力。把标题、段落、表格、代码路径和文档边界全部抹掉,模型看到的就只是一长串 token,而不是一篇有组织的文档。
长上下文评测也要去污染。比如某些长文问答题,如果原文、问题和答案在公开仓库里出现过,模型可能不是现场阅读,而是凭记忆回答。更可靠的长上下文评测往往需要使用新构造的文档、动态生成问题、要求答案引用原文位置,并加入干扰信息,测试模型能否真正定位关键段落。
从数据工程角度看,长上下文能力的核心不是“窗口变大了”,而是:模型能否在更长的信息结构里稳定定位、保持约束、整合证据并输出答案。
小结:可信与扩展
评测污染、合成数据和长上下文,看起来是三个不同问题,其实都指向同一件事:数据工程不能只负责“把数据送进训练”,还要负责模型能力的可信度、增长方式和复杂信息处理能力:
- 评测污染:确认模型是真的会了,而不是提前看过答案;
- 合成数据: 在自然数据不足时,制造可验证、可控的高价值数据;
- 长上下文: 让模型学习真实长结构,而不是只处理更长 token 串。
如果说前面的清洗、去重、过滤和配比,是在决定模型“学什么”,那么这三个问题就是在进一步追问:
- 学到的能力可信吗?
- 能力还能继续增长吗?
- 模型能处理更复杂的信息结构吗?
这也是预训练数据工程从基础处理走向高级能力设计的关键一步。
数据治理:让数据工程可复现
前面讲的是数据工程的关键环节:数据来源、清洗、去重、过滤、配比、评测污染、合成数据和长上下文。真正落到工程里,这些能力不能只靠几个脚本临时拼起来,而要变成一套可复现、可追踪、可评估的数据治理系统。一个简化的数据平台可以长这样:
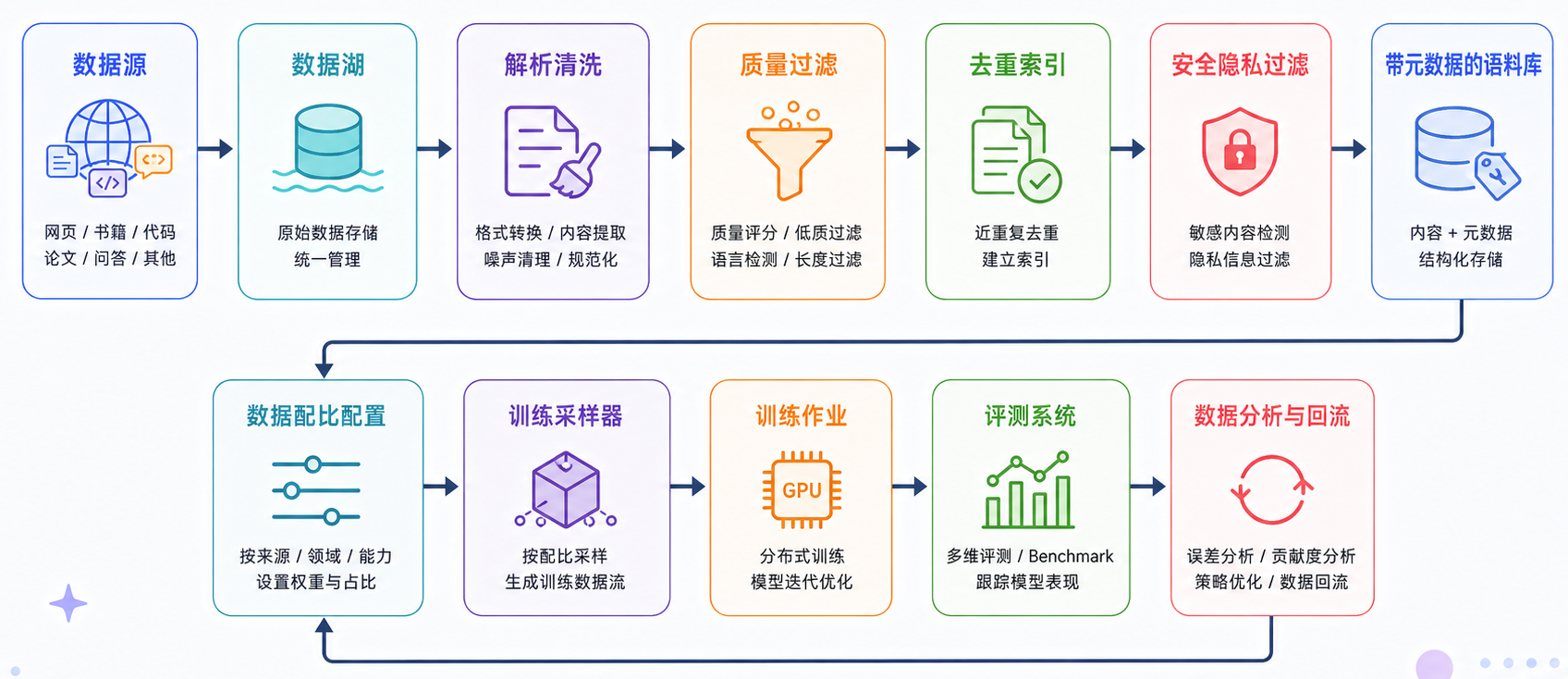
这套系统最核心的目标,是让团队能回答几个问题:
| 问题 | 为什么重要 |
|---|---|
| 这次训练用了哪些数据源 | 解释模型能力来源 |
| 每个数据源是什么版本 | 保证实验可复现 |
| 清洗、去重、过滤规则是什么 | 判断数据处理是否影响能力 |
| 各类数据配比是多少 | 分析模型为什么偏科 |
| tokenizer 是哪个版本 | 避免训练样本不可复现 |
| 是否排除了 benchmark | 控制评测污染 |
| 哪些数据被上采样或下采样 | 理解能力增强或退化的原因 |
所以,数据版本管理不是形式主义,而是模型迭代的记忆系统。没有版本、元数据和质量报告,训练一次模型之后,团队很难说清楚“模型为什么变好了”,也很难说清楚“模型为什么变差了”。
一个训练样本最好不只是文本,还要有身份信息:
1 | { |
有了元数据,团队才能按语言统计、按领域采样、排除风险来源、对高质量数据上采样、做数据消融,也能在模型出问题时追踪问题可能来自哪类数据。没有元数据,数据湖就只是一个巨大的文本堆。
这套思路不只适用于训练基座模型。普通团队做领域继续预训练、指令微调、RAG 知识库、企业知识问答、代码助手私有化和评测集构建时,同样绕不开数据治理。
比如做企业知识问答,最容易犯的错误是:把所有文档直接丢进去。更合理的流程应该是:
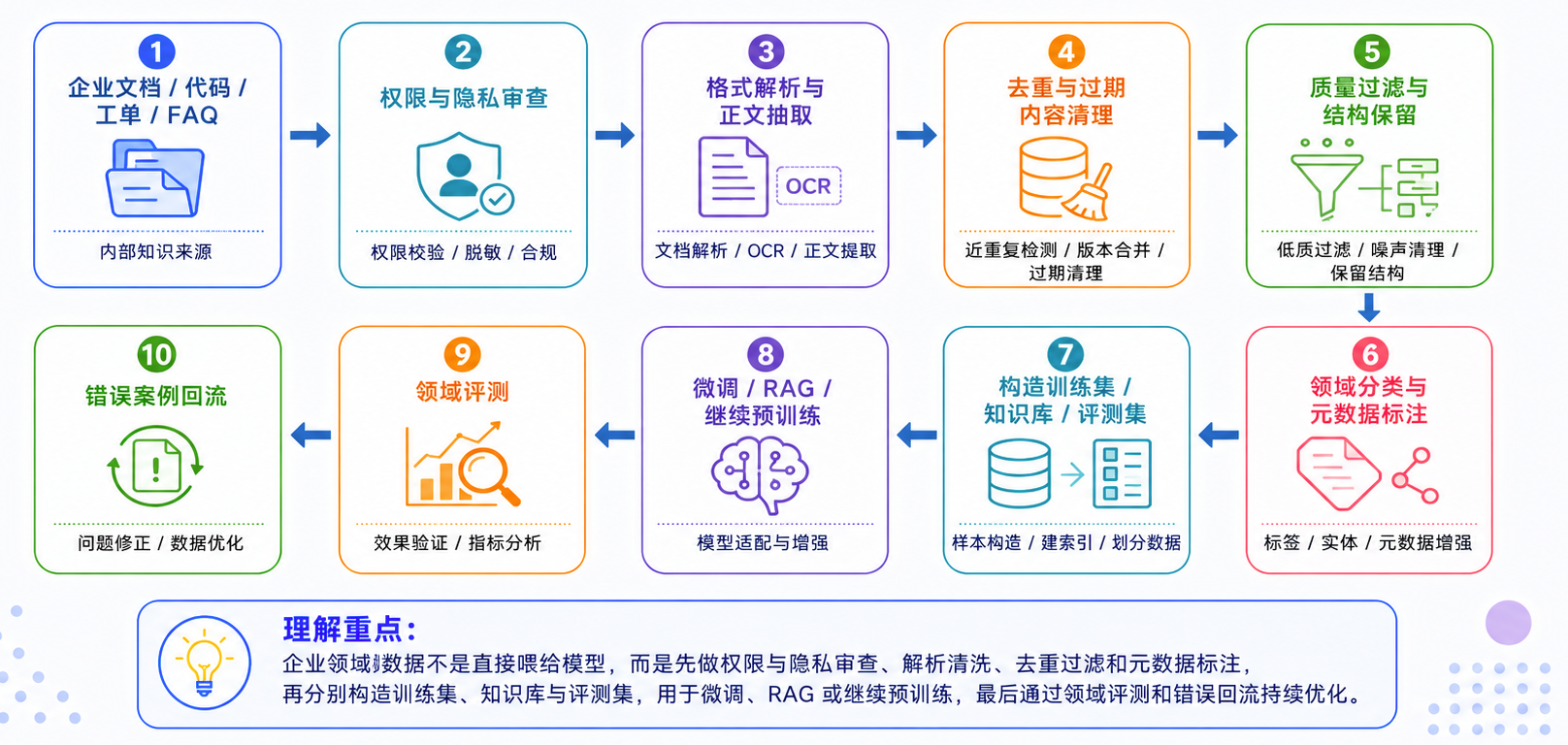
可以这样理解:预训练数据工程,是在训练前整理模型的长期记忆;RAG 数据工程,是在推理时整理模型的临时参考资料。两者规模不同,但底层逻辑很像:都要解析、清洗、去重、加元数据、控权限、做质量评估,并通过评测和日志持续回流。
最后,再整理几个常见误区:
- 只追求 token 数量:更重要的是有效 token,高质量、多样、低重复、低污染;
- 清洗越狠越好:过度清洗会损失标题、列表、表格、代码缩进等结构信号;
- 评测分提升就等于模型变强:可能是数据污染、记忆提升或格式适配;
- 合成数据越多越好:合成数据必须可验证、有筛选、有多样性;
- 不做数据版本管理:无法解释模型变化,也无法复现实验;
- 忽略合规和隐私:训练数据里的 PII、密钥、版权内容必须前置处理。
数据治理的价值,就是把数据工程从“临时清洗脚本”变成“可持续迭代的能力系统”。
总结:大模型的燃料工程
回到开头的问题:大模型到底吃了什么?
更准确的答案不是“互联网文本”,而是经过数据工程加工后的训练数据分布。这个分布里包含网页、书籍、代码、论文、问答、长文档、领域数据和合成样本;也可能混入噪声、重复、过时信息、隐私风险和评测污染。
所以,预训练数据工程要解决的核心问题不是“数据够不够多”,而是:
1 | 数据是否干净? |
如果把整个 LLM 系列连起来,可以看到一条完整链路:
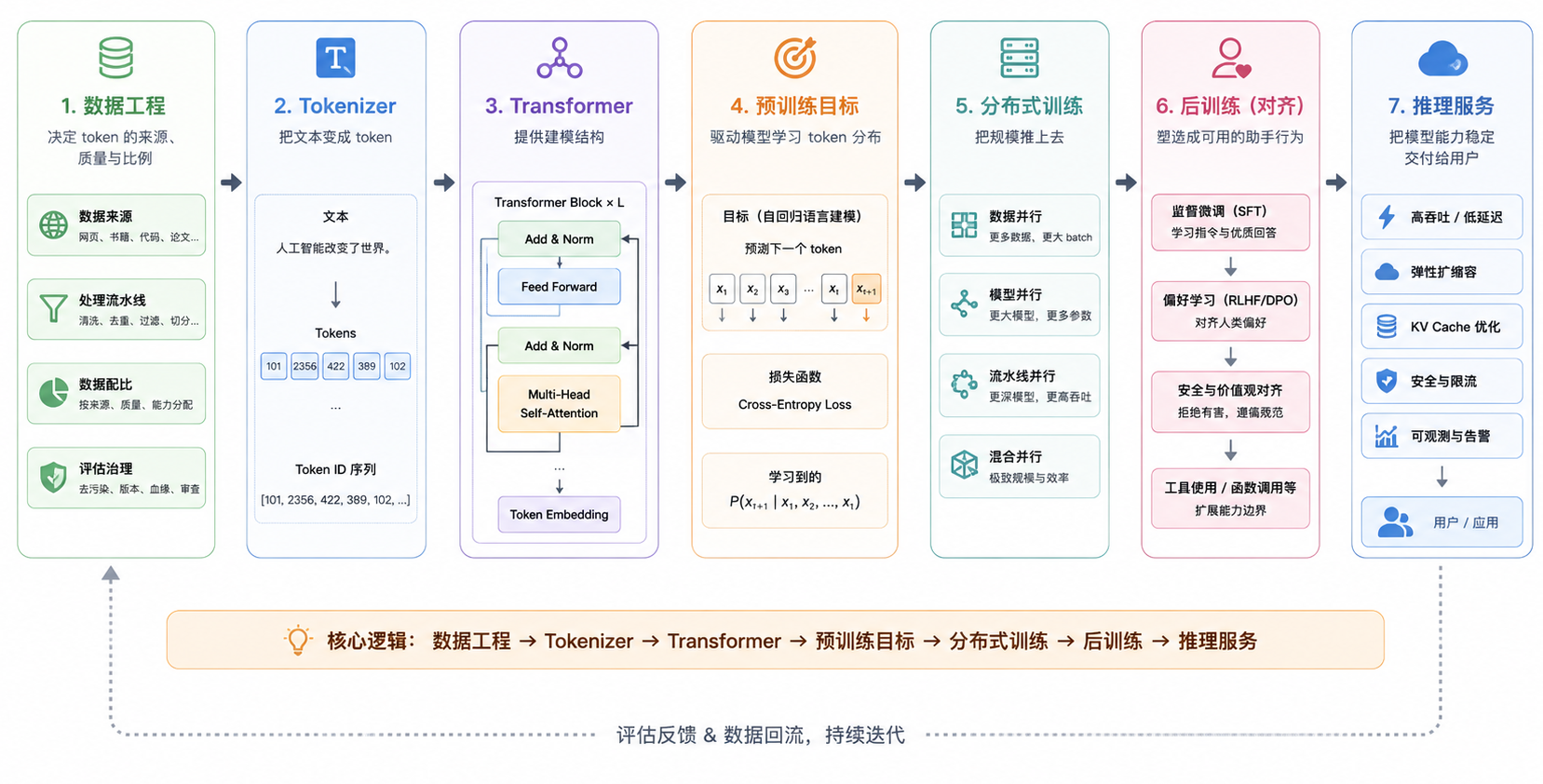
理解了这条链路,再看大模型能力差异,就不会只问“参数有多大”,而会继续追问:它看过什么数据?这些数据怎么清洗、去重、配比、去污染、验证和回流?
最后,总结一下:数据工程不是大模型训练前的脏活,而是大模型能力的燃料工程。模型最终能学到什么,从数据进入训练系统的那一刻,就已经开始被决定了。
