LLM 系列 (十):推理模型:大模型如何从回答走向思考
如果说推理服务回答的是“模型如何更快、更便宜地生成 token”,那么推理模型回答的就是另一个更接近能力本质的问题:模型如何在复杂任务中不急着给出结论,而是先分解问题、展开推导、检查约束、验证结果,再输出更可靠的答案。
这里的“推理”不再是 Inference Serving,而是 Reasoning。前者关注系统效率:吞吐、延迟、KV Cache、batch 调度和单位 token 成本;后者关注能力机制:模型为什么愿意多想几步,为什么数学、代码、逻辑和规划任务需要更多 test-time compute,为什么 DeepSeek-R1、OpenAI o 系列、Qwen3 thinking mode 都把“思考过程”和“推理预算”变成核心能力。
简单来说,推理模型的本质,是把一部分能力提升从训练阶段转移到推理阶段,让模型用更多生成、搜索、验证和反思,换取更高的问题求解质量。
为什么需要推理模型?
普通 Chat Model 解决的是“如何快速给出一个符合用户意图的回答”,但很多复杂任务并不是看到问题就能直接输出结论。数学证明、代码修复、复杂规划、科研分析、长链工具调用,本质上都需要一个过程:
- 理解问题 -> 分解目标 -> 推导中间步骤 -> 检查约束 -> 验证结果 -> 修正答案
传统 Chat Model 的问题在于:它往往会直接把最终回答生成出来。这个回答可能很流畅、很像正确答案,但中间推导并不稳定。一旦某个中间步骤出错,后续生成仍然可能沿着错误方向继续补全,最后得到一个“表达完整但逻辑错误”的结果。这就是推理模型出现的背景:大模型已经具备了很多知识和模式,但在复杂任务上,缺少稳定展开、验证和修正的机制。
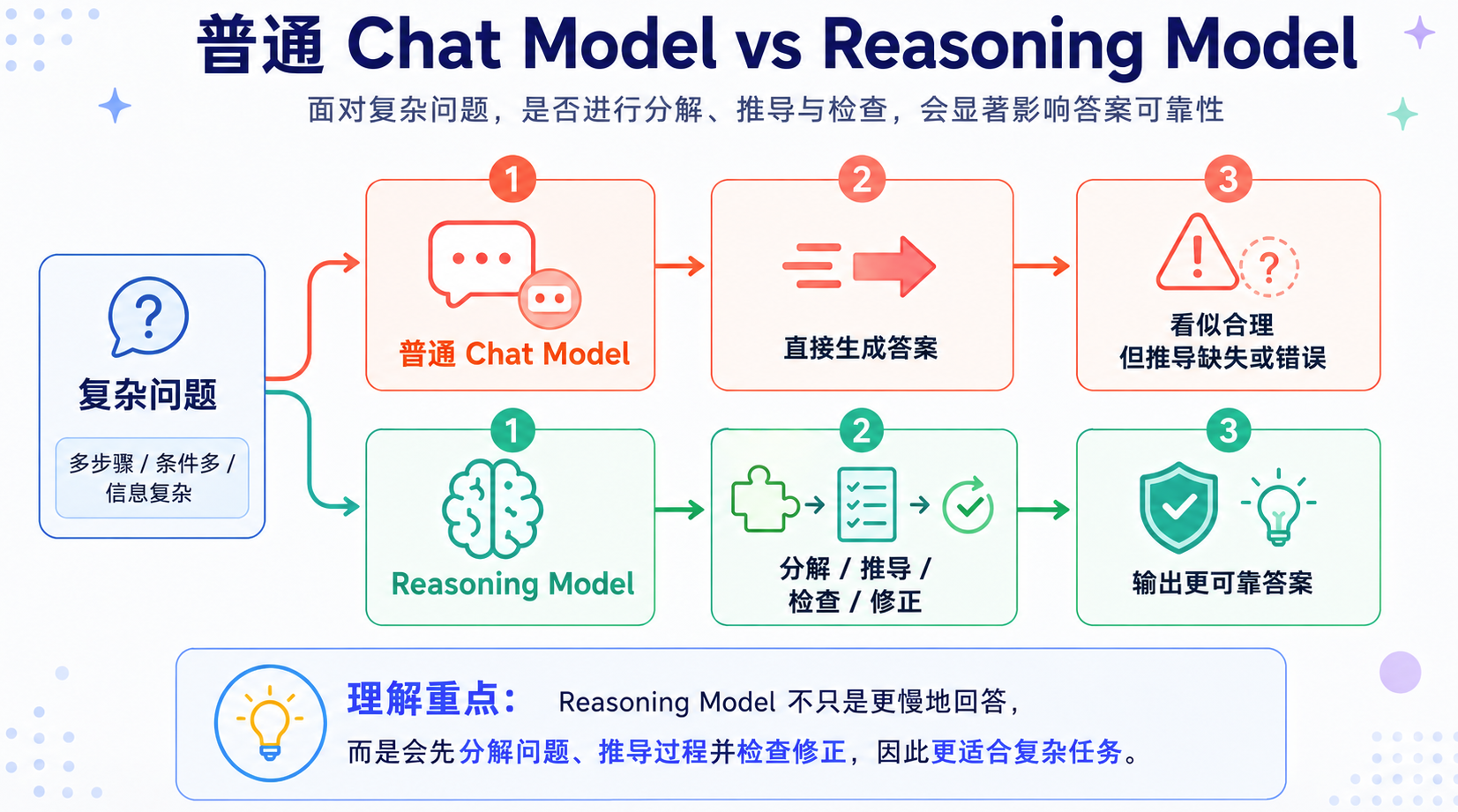
从任务类型看,推理模型更适合处理那些 不能一步到位、必须保持约束、需要验证结果 的任务:
- 数学推导:不能只猜最终答案,中间步骤必须成立,需要公式变换、多步推导和答案校验;
- 代码生成:不能只生成“看起来像代码”的文本,还要满足需求约束、边界条件和可运行性;
- 逻辑推理:前提、结论和中间状态必须一致,不能在多步推导中自相矛盾;
- Agent 任务:需要计划、执行、观察反馈,并根据环境结果调整下一步动作;
- 科研分析:需要提出假设、整合证据、检查反例,并明确不确定性。
推理模型的本质:从答案生成到计算展开
大模型的底层形式仍然是自回归生成器:
1 | P(next token | context) |
也就是说,模型每一步做的事情,仍然是根据当前上下文预测下一个 token。推理模型并没有脱离这个基本机制,它改变的是 生成过程的组织方式。普通回答模式更像:
- 问题 -> 直接生成答案
推理模型则把一次回答展开成更长的计算过程:
- 问题 -> 问题分解 -> 中间推导 -> 检查 / 验证 -> 最终答案
可以把它理解成一种 test-time compute scaling:模型在推理阶段投入更多 token、更多时间和更多计算,用更高的推理成本换取复杂任务上更高的成功率。
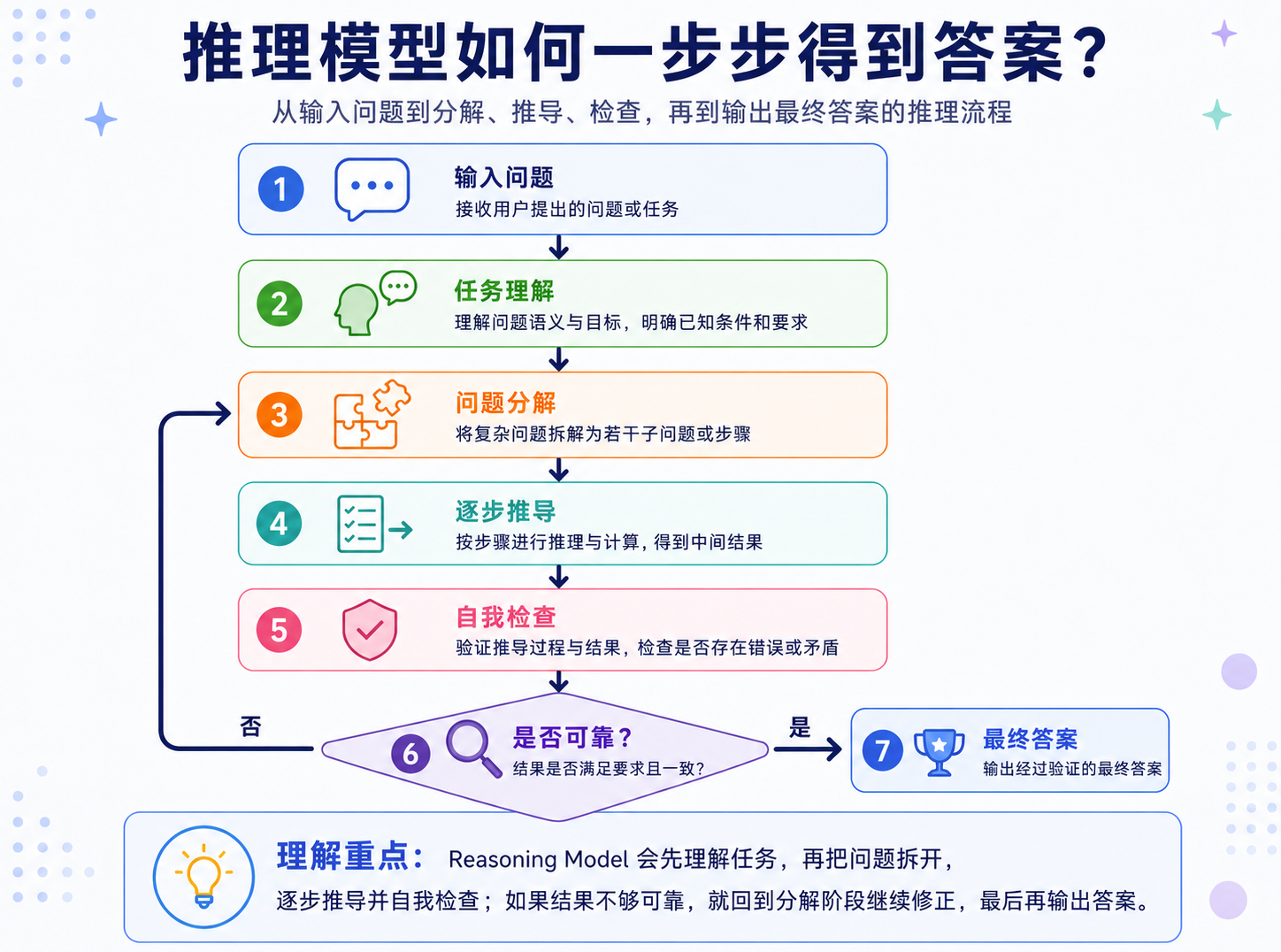
推理模型计算过程
推理模型本质上仍然是在生成 token。只是经过特定的后训练、强化学习和推理策略之后,模型学会在困难任务中先生成有助于求解的中间状态,再输出最终答案。推理模型的能力提升通常来自三个机制:
- 中间步骤展开: 把复杂问题拆成更小、更容易求解的子问题;
- 自我检查 / 外部验证:判断推导是否满足约束,结果是否正确;
- 推理预算扩展:对困难任务投入更多 token、时间和计算。
这也解释了为什么推理模型通常更慢。它不是直接从问题跳到答案,而是在输出前后做了更多中间计算。简单问题上,这种额外计算可能显得多余;复杂问题上,它往往能显著提高稳定性和正确率。
所以,推理模型的本质不是“神秘地拥有思考”,而是:把原本一次性的答案生成,改造成一个可展开、可检查、可修正的计算过程。
主流技术路线:CoT、Verifier 与 RLVR
Prompt 可以诱发模型展开步骤,但真正稳定的推理模型,通常依赖后训练、可验证反馈、强化学习和推理时计算共同塑形。它背后通常是一整套后训练机制:
- 先让模型学会展开中间步骤;
- 再让模型知道哪些结果是对的;
- 最后用可验证奖励强化更有效的推理策略。
可以把主流路线概括成五个环节:
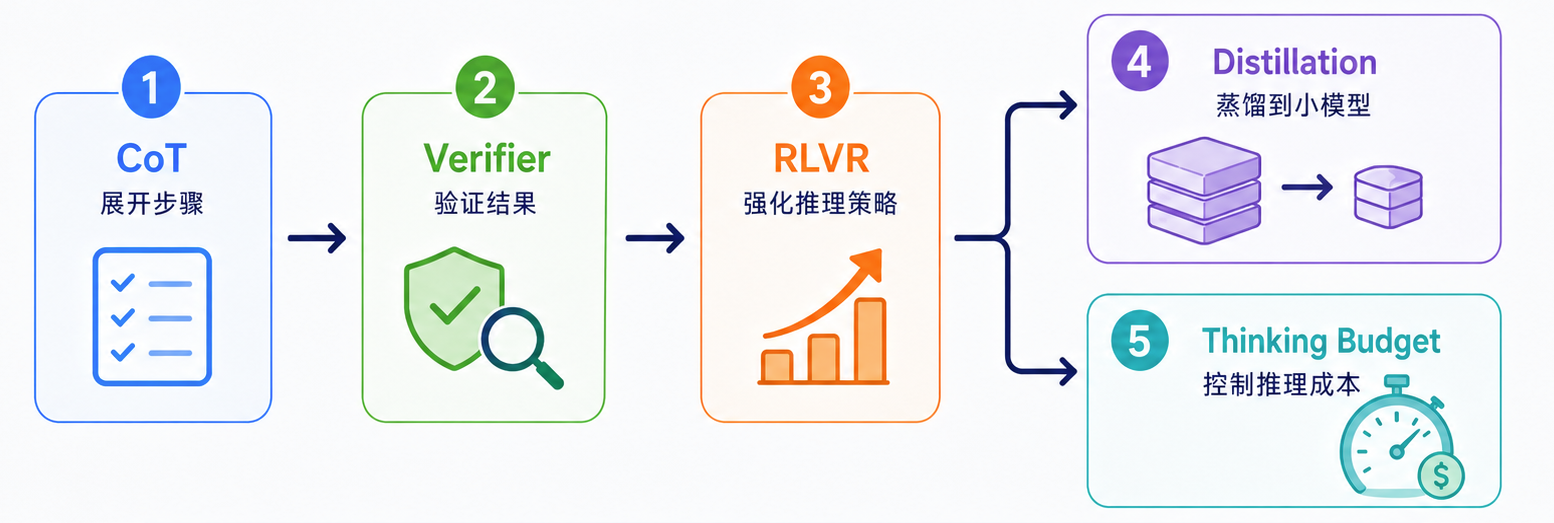
CoT:让模型学会展开步骤
CoT(Chain-of-Thought,思维链)让模型在回答前生成中间推理步骤:
- 问题 -> 分析步骤 -> 中间结论 -> 最终答案
它的价值是降低复杂任务“一步到位”的难度。模型不必直接从问题跳到答案,而是可以把问题拆成多个中间状态,逐步逼近结果。但 CoT 不是万能的:
- 会写步骤,不代表步骤一定正确;
- 中间过程可能自洽,但事实或计算是错的;
- 推理链越长,越可能引入新错误;
- 完整暴露思维链还会带来安全、隐私和可控性问题。
所以,现代推理模型通常不会只依赖 CoT,而会进一步引入验证器和强化学习。
Verifier:从“像对”走向“真的对”
Verifier 的作用是验证结果,而不是判断回答风格。对于数学、代码、逻辑和工具任务,很多结果可以被自动检查:
- 数学: 最终答案是否匹配,推导是否满足约束;
- 代码:单元测试、编译检查、静态分析;
- 逻辑题:是否违反规则或前提;
- 工具调用:API 参数是否正确,执行结果是否符合目标;
- 检索问答:答案是否被证据支持。
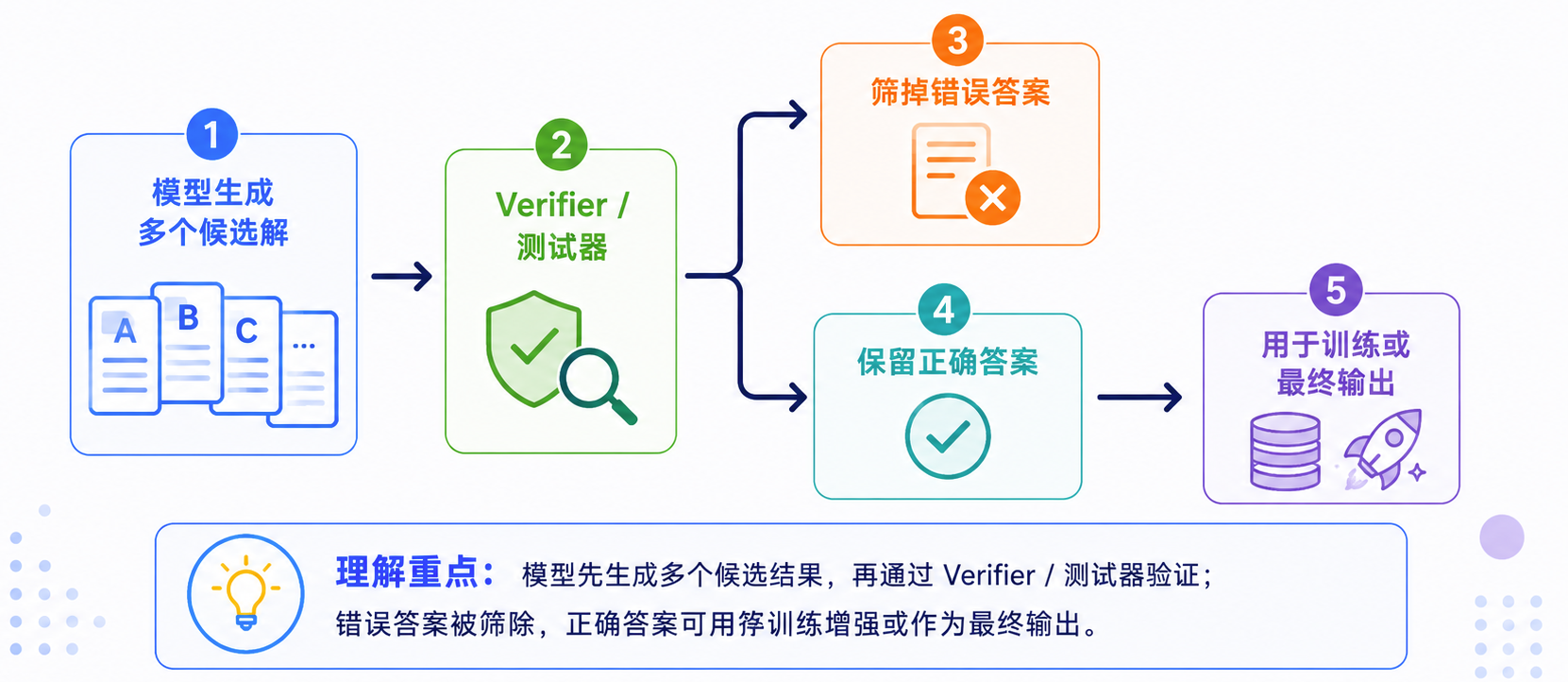
这一步非常关键,因为语言模型天然擅长生成“看起来像正确答案”的文本,但推理任务真正需要的是结果满足约束。
RLVR:用可验证奖励强化推理策略
RLVR,即 Reinforcement Learning with Verifiable Rewards,可以翻译为“可验证奖励强化学习”。它的核心思想是:如果一个任务的结果可以自动判断对错,就可以把验证结果转成 reward,让模型通过强化学习学会更有效的推理策略。
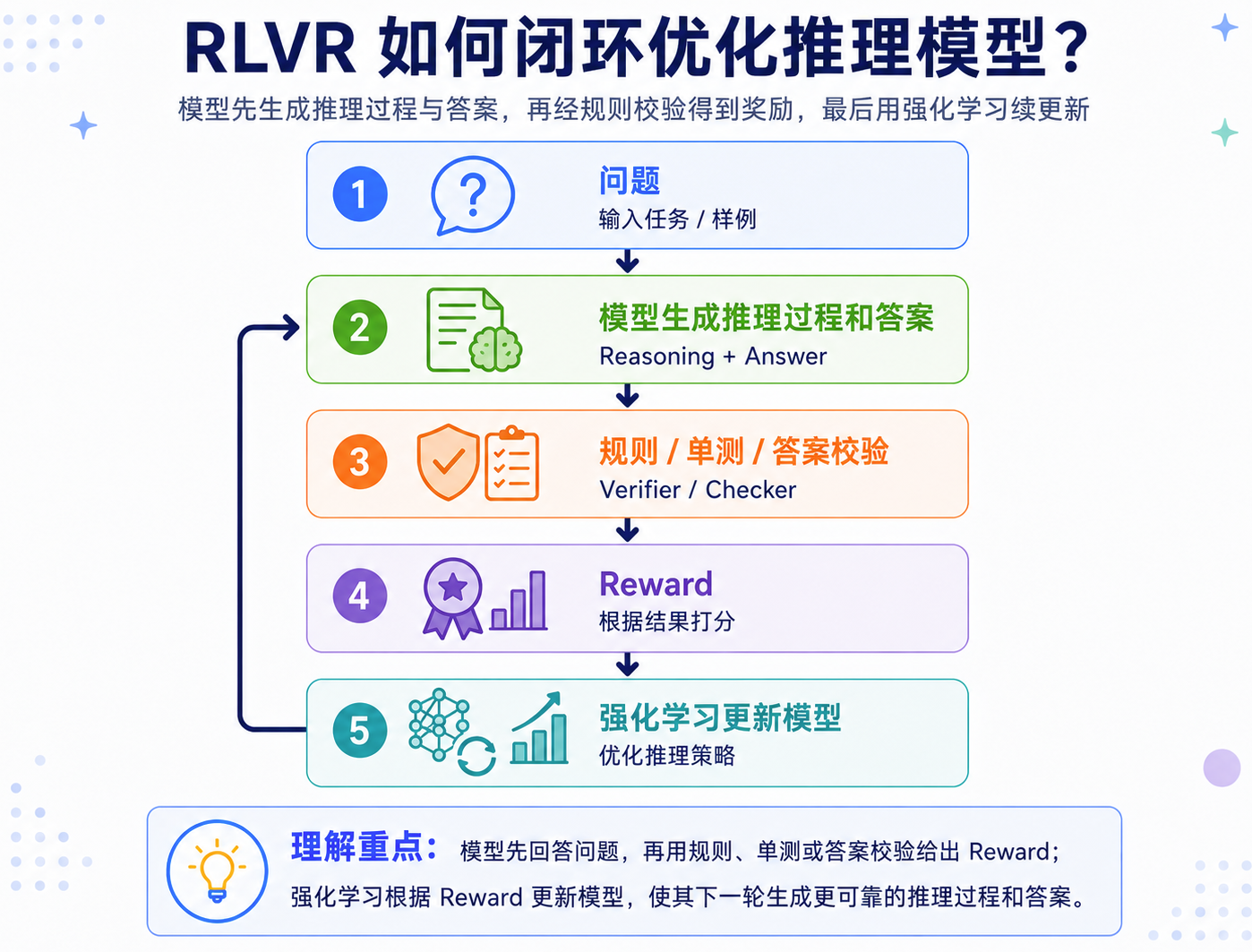
DeepSeek-R1 的关键启发就在这里。公开报告中,R1-Zero 在没有 SFT 冷启动的情况下,直接通过大规模 RL 激发出推理行为,出现了反思、回溯和自我修正等现象;但它也存在可读性差、语言混杂等问题。DeepSeek-R1 再引入 cold-start 数据和多阶段训练,改善了可读性和综合表现。
这说明一个重要趋势:当 reward 足够明确时,强化学习不只是对齐话术,也可以放大数学、代码和复杂推理能力(不过,RLVR 适合结果可自动验证的任务,比如数学、代码等;但是像开放写作、价值判断和复杂产品体验仍然需要偏好模型、人类评估或多维 reward)。
Distillation:把强推理能力迁移给小模型
强推理模型通常推理成本高、延迟高、部署贵。因此,行业常用蒸馏把强模型的推理能力迁移给更小模型。典型流程是:
- 强推理模型生成高质量推理轨迹;
- 用 verifier / 测试器过滤正确样本;
- 用这些样本微调小模型;
- 小模型获得部分推理能力。
这也是 DeepSeek-R1 Distill 系列和很多开源推理模型的重要路线。蒸馏的价值是降低部署成本,但它也有边界:小模型可以模仿强模型的推理轨迹,却不一定完整继承强模型的搜索能力、纠错能力和复杂任务泛化能力。
Thinking Budget:按任务分配思考成本
不是所有问题都需要深度思考,比如:
- “北京今天几点?” -> 快速回答;
- “证明这个算法复杂度” -> 多步推理;
- “修复这个代码仓库 bug” -> 计划 + 工具 + 验证。
因此,推理模型还需要学会控制“思考成本”。简单问题快速回答,复杂问题分配更多 token、更多时间和更多验证步骤。
Qwen3 的 thinking / non-thinking 统一框架和 thinking budget 就体现了这个方向:模型不应该所有问题都慢慢想,而应该根据任务复杂度动态分配推理预算。
简单总结一下:CoT 解决“怎么展开”,Verifier 解决“怎么判断对错”,RLVR 解决“怎么把正确反馈变成能力”,Distillation 解决“怎么降低成本”,Thinking Budget 解决“什么时候该想多久”。
业内实践与核心挑战
推理模型的发展,不是单个模型突然“变聪明”的故事,而是一条技术路线逐渐清晰的过程:从让模型写出推理步骤,到用验证器判断结果,再到用强化学习把“可验证正确”变成训练信号,最后进一步控制推理成本。
| 模型 / 工作 | 关键设计 | 解决的问题 | 行业启发 |
|---|---|---|---|
| OpenAI o 系列 | 强调 reasoning、test-time compute 和更高推理预算 | 复杂数学、代码、科学问题不能只靠快速生成 | 推理时计算成为能力扩展的新维度 |
| DeepSeek-R1-Zero | 不经过 SFT 冷启动,直接用大规模 RL 激发推理 | 证明 RL 可以诱导反思、回溯、自我修正等行为 | 可验证 reward 能显著放大推理能力 |
| DeepSeek-R1 | cold-start 数据 + 多阶段 RL + 蒸馏 | 解决 R1-Zero 可读性差、语言混杂等问题 | 纯 RL 有潜力,但工业可用仍需要工程化训练流程 |
| Qwen3 | thinking / non-thinking 统一,支持 thinking budget | 不是所有问题都需要深度思考 | 推理能力开始和推理成本控制绑定 |
| R1 Distill / 开源推理模型 | 用强模型生成推理轨迹,再蒸馏到小模型 | 强推理模型成本高、部署贵 | 推理能力可以部分迁移,但小模型不一定继承完整搜索能力 |
这些实践说明,推理模型已经形成三条主线:
- 能力增强:通过 CoT、RLVR、Verifier,让模型在数学、代码、逻辑任务上更可靠;
- 成本控制:通过 thinking budget、蒸馏、小模型,把深度推理变得可部署;
- 任务扩展:从文本推理走向工具调用、代码执行、多模态理解和 Agent 任务。
但推理模型并不是免费午餐。它带来的能力提升,本质上是用更多训练成本和推理成本换来的。当前仍然面临几类核心挑战:
过度思考:简单问题也生成很长推理过程,导致延迟和成本上升。
- 解决方向是 thinking budget、动态路由、快慢模式切换,让模型根据任务难度决定是否深度思考。
推理幻觉:推理链看似严密,但事实、计算或逻辑可能是错的。
- 解决方向是 verifier、工具调用、检索增强和结果校验,把“看起来合理”拉回到“结果正确”。
奖励黑客:模型可能学会钻 reward 漏洞,而不是真正解决问题。
- 解决方向是多 reward、过程监督、红队评测,避免模型只优化评分表面特征。
训练成本高:RL、长推理轨迹、验证数据和多阶段训练都很贵。
- 解决方向是蒸馏、样本筛选、小模型继承,把强模型的推理能力迁移到更低成本模型上。
推理成本高:thinking token 越多,延迟和费用越高。
- 解决方向是推理预算控制、早停机制、分层模型路由,让简单任务少想,复杂任务多想。
可控性问题:长链推理可能带来不可预测输出,也可能暴露不该展示的中间过程。
- 解决方向是隐式 reasoning、安全约束、输出边界控制,只把必要结论和可解释摘要暴露给用户。
安全风险:更强推理能力也可能增强危险任务的规划和执行能力。
- 解决方向是 deliberative alignment、安全 reward、风险分类器和场景化拒答策略。
这里最重要的判断是:推理模型不是让模型“凭空变聪明”,而是让模型学会在困难任务上投入更多计算,并把这些计算组织成可检查、可修正的过程。
所以推理模型的核心权衡是:
- 准确率 vs 延迟
- 深度思考 vs 成本
- 长链推理 vs 可控性
- 能力增强 vs 安全风险
推理模型真正难的地方,不只是让模型“想得更久”,而是让它知道 什么时候该想、想到什么程度、如何验证、何时停止。
未来演进与总结:从会思考到会行动
推理模型的未来,不是简单生成更长的 CoT,而是构建更可靠的计算过程。真正重要的不是“想得更长”,而是“想得更对、能验证、能修正、能行动”。
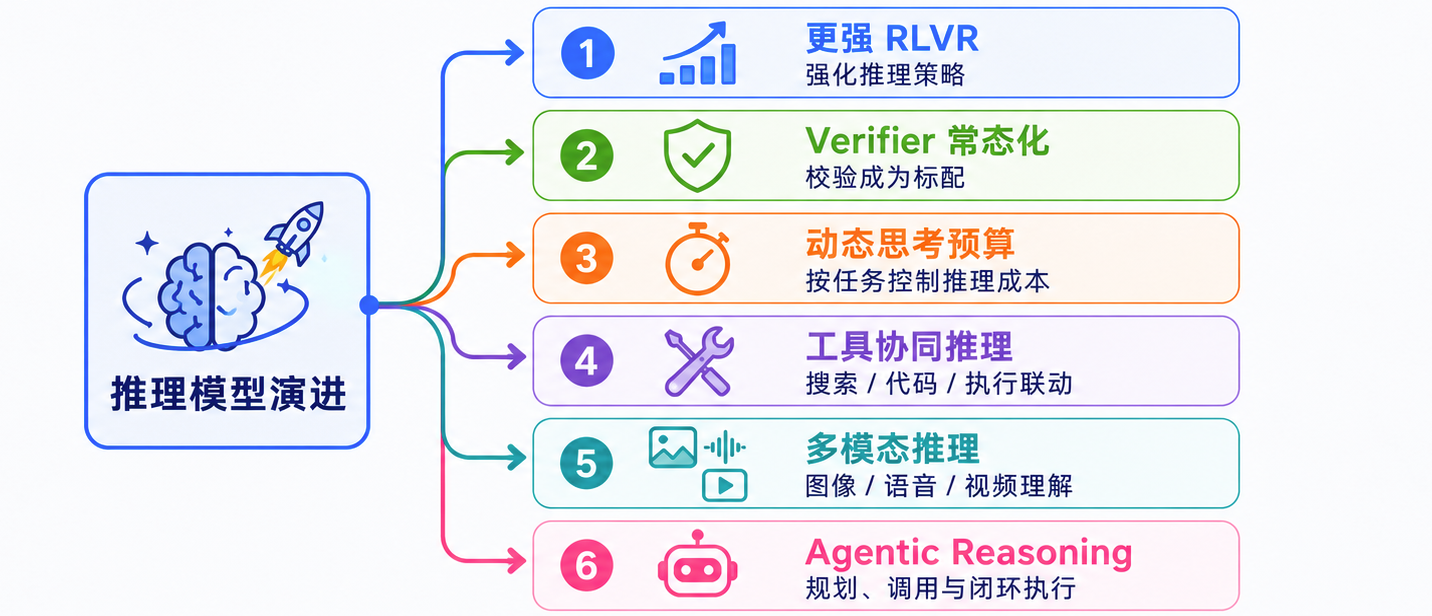
未来趋势可以概括为五点:
- 从 CoT 到可验证推理: 不只生成中间过程,还要验证结果是否正确;
- 从固定深度到动态预算:简单任务快答,复杂任务分配更多 thinking token 和验证步骤;
- 从文本推理到工具推理:搜索、代码执行、计算器、数据库等工具参与推理过程;
- 从单模态到多模态推理:图像、表格、视频、屏幕状态进入推理链路;
- 从回答到 Agentic Reasoning:模型不只给答案,还要计划、执行、观察、修正。
可以看到,推理模型正在从 Question -> Answer 走向 Goal -> Think -> Act -> Observe -> Verify -> Revise -> Result。
也就是说,推理模型不是系列终点,而是 Agent 的能力底座。Agent 不是只需要会调用工具,更需要在多步任务中持续判断:下一步做什么、结果是否可信、是否需要修正计划、什么时候停止。
总结一下,推理模型的本质,不是让模型说出更长的过程,而是把一次生成变成可分解、可验证、可修正、可行动的求解过程。
