LLM 系列 (六):预训练的本质:从预测下一个 Token 到通用能力
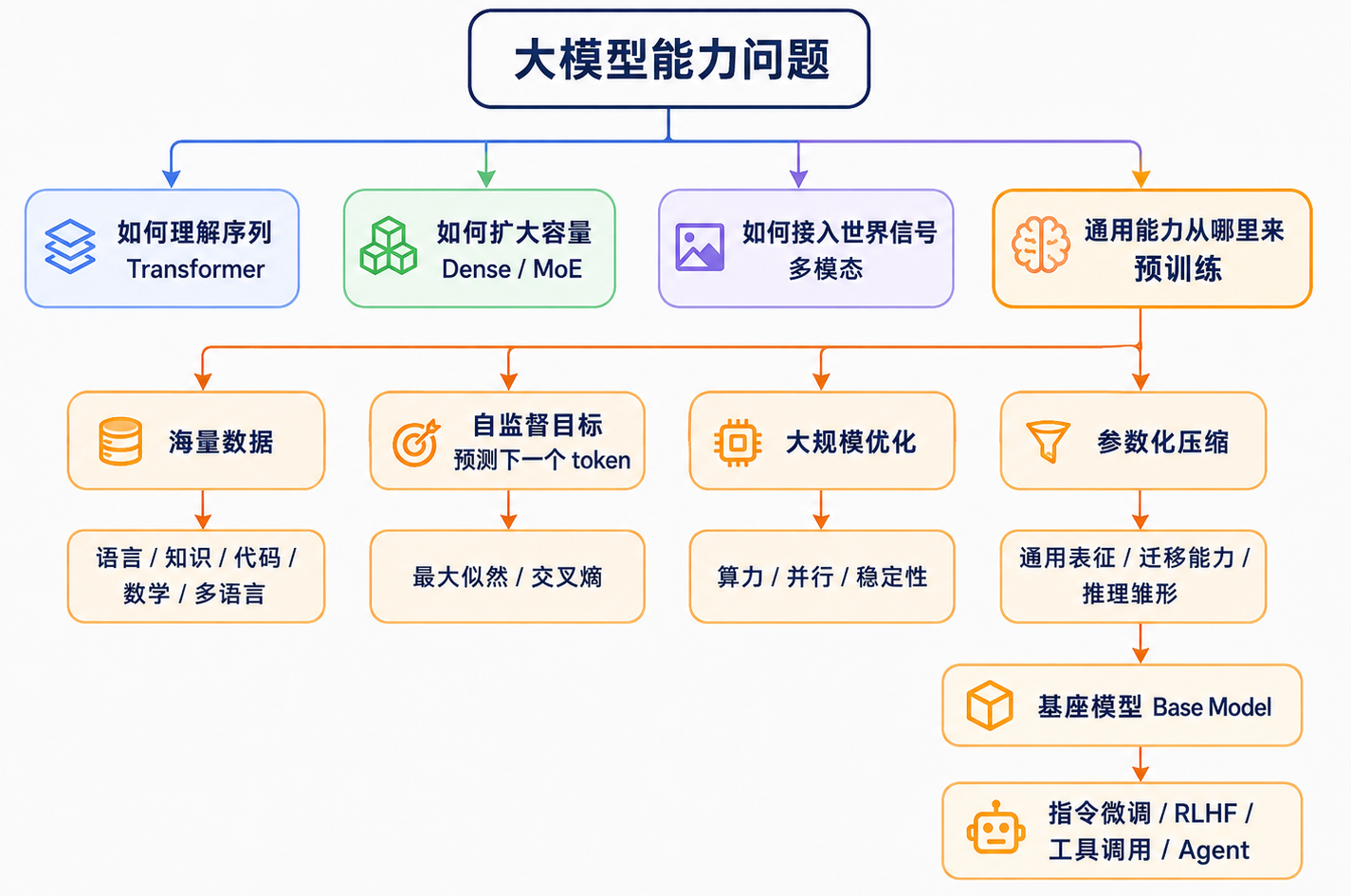
如果说 Transformer 解决的是“大模型如何理解序列”,Dense 与 MoE 解决的是“大模型如何扩展架构”,多模态解决的是“大模型如何接入更多世界信号”,那么预训练要回答的,就是一个更底层的问题:大模型的通用能力从哪里来?
前几篇我们已经铺垫了大模型的发展脉络、数学基础、算法原理、Transformer 架构和 Dense/MoE 架构。到这里,讨论进入 LLM 训练体系中最关键、最昂贵,也最决定能力上限的一环:预训练。它不是附属步骤,而是基座模型形成语言、知识、代码、推理和迁移能力的主要来源。
很多人会把预训练理解成“大规模背书”:把互联网文本喂给模型,模型记住很多知识,于是变聪明。这个理解只说对了一小部分。真正的预训练不是简单记忆,而是在不依赖人工任务标注的情况下,让模型从海量文本、代码、数学、文档、多语言甚至多模态数据中学习数据分布背后的结构。对自回归语言模型来说,这通常被简化为一个目标:根据上下文预测下一个 token。目标看似简单,但为了预测得更准,模型会被迫学习语法、语义、事实关系、程序结构、推理模式、上下文依赖和任务先验。
预训练不是孤立技术,而是大模型通用能力的生成过程,它是一套系统工程。数据提供经验,目标函数提供学习压力,算力提供规模,参数承载压缩后的结构,最后形成可以被后训练继续塑形的基座模型。
在进入正文之前,关于预训练部分涉及到 LLM 相关概念如下表所示:
| 概念 | 含义 |
|---|---|
| Base Model | 预训练后得到的基座模型,通常还没有充分对齐人类指令 |
| Pre-training | 预训练,在大规模未标注或弱标注数据上训练通用能力 |
| Post-training | 后训练,在基座模型上继续做 SFT、RLHF、DPO、RLAIF 等对齐和能力释放 |
| Self-supervised Learning | 自监督学习,数据本身构造监督信号,例如遮住一个词让模型预测,或让模型预测下一个 token |
| Causal LM | 自回归语言模型,只看左侧上下文预测下一个 token |
| Loss | 损失值,模型预测分布和真实 token 之间的差距 |
| Scaling Laws | 模型性能随参数、数据和算力变化的经验规律 |
| Compute-optimal | 在给定算力下,如何平衡模型参数量和训练 token 数 |
| MoE | Mixture-of-Experts,混合专家模型,每个 token 只激活部分专家参数 |
什么是预训练:通用能力的来源
预训练里的“预”,不是说它只是准备工作,而是说它发生在指令微调、偏好对齐和具体业务适配之前。它的目标不是训练一个会做某个单一任务的模型,而是先训练出一个具备通用语言、知识、代码、推理和迁移能力的基座模型。可以把大模型训练链路简化成这样:
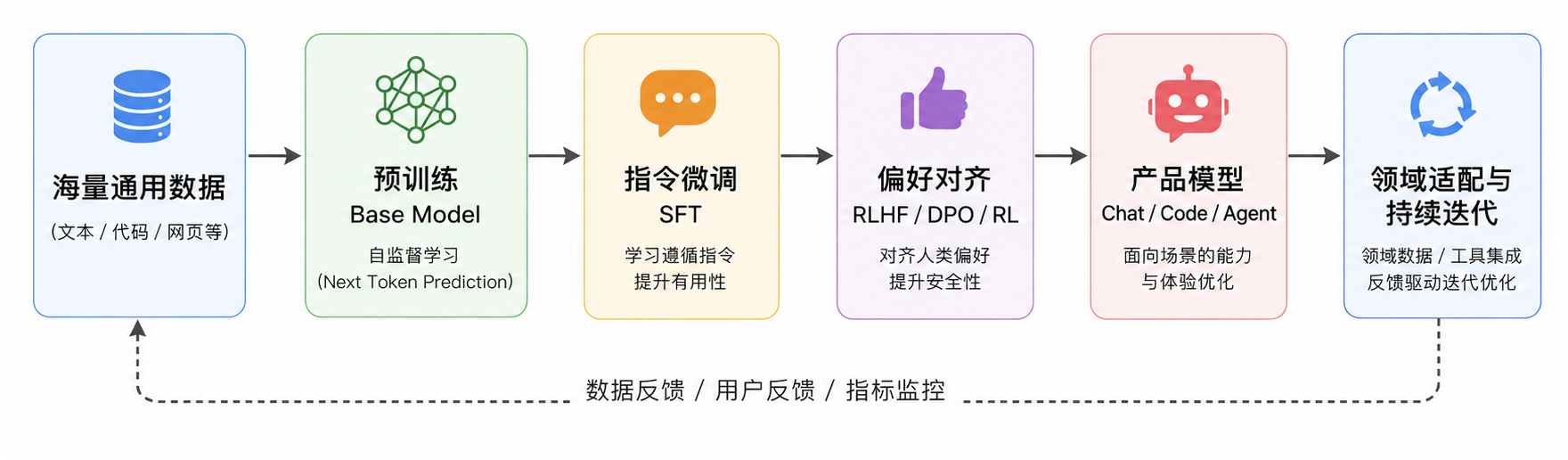
预训练决定模型的能力上限,后训练决定模型如何把这些能力以更符合人类意图的方式表达出来。一个预训练不足的模型,即使后训练做得再精细,也很难凭空补出强大的知识、代码和推理能力。
预训练到底训练什么?
对现代自回归语言模型来说,预训练最核心的任务可以概括为一句话:给定前面的上下文,预测下一个 token。也就是学习这个条件概率:
1 | P(next token | context) |
例如:
1 | 输入:牛顿提出了万有引力 |
模型并不是只输出“定律”这个答案,而是输出整个词表上的概率分布:
| 候选 token | 概率 |
|---|---|
| 定律 | 0.71 |
| 理论 | 0.13 |
| 概念 | 0.05 |
| 方程 | 0.03 |
| 其他 | 0.08 |
如果真实 token 是“定律”,模型给它的概率越高,损失越低;给它的概率越低,损失越高。训练就是不断调整参数,让模型在海量上下文中越来越擅长预测真实的下一个 token。这个目标看起来简单,但并不浅。为了预测得更准,模型会被迫学习很多隐藏结构:
| 表面任务 | 被迫学到的能力 |
|---|---|
| 预测语法上合理的词 | 词法、语法、句法结构 |
| 预测事实性内容 | 世界知识、实体关系、时间地点 |
| 预测代码下一行 | 变量作用域、API 模式、程序结构 |
| 预测数学推导 | 公式变换、约束关系、证明套路 |
| 预测对话回复 | 语境、意图、语气、社会常识 |
| 预测长文后续 | 篇章结构、主题一致性、长期依赖 |
所以,next token prediction 表面上是在预测语言,实际上是在用语言预测任务逼迫模型学习数据背后的结构。
预训练为什么是自监督学习?
传统有监督学习依赖人工标签:
1 | 输入:这家餐厅很好吃 |
模型的任务很明确:学会分类。预训练则不同,它通常不需要人工为每条数据打标签,而是直接从数据本身构造训练信号。例如一段文本:
1 | 深度学习改变了自然语言处理的发展路径。 |
可以自动变成很多训练样本:
1 | 输入:深度 |
这就是自监督学习:监督信号不是人工标出来的,而是从原始数据内部生成的。正因为如此,预训练可以利用远超人工标注规模的文本、代码、数学、网页、文档和多语言数据。
为什么预训练会带来通用能力?
预训练之所以重要,是因为不同任务共享大量底层结构。翻译、摘要、问答、代码生成、数学推理、工具调用,看起来是不同任务,但它们都依赖语言理解、语义表示、上下文建模、结构识别和模式迁移。预训练在大规模数据上学习到的,正是这些通用结构。
所以,基座模型的能力不是来自一个个任务专用模块,而是来自大规模分布学习之后形成的通用表征:
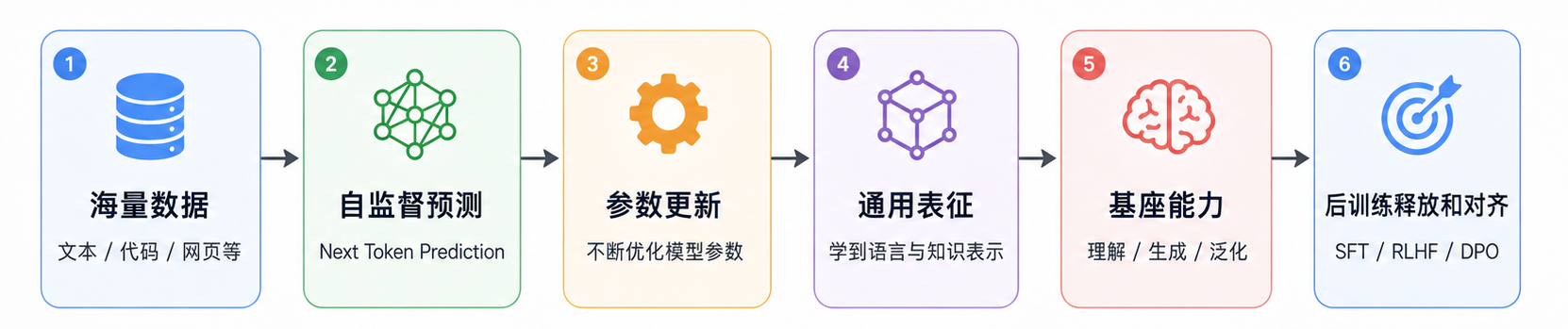
这也是为什么预训练决定模型上限。后训练可以让模型更会听指令、更安全、更像助手,但模型能不能写代码、懂数学、理解长上下文、迁移到新任务,根子上主要取决于预训练阶段学到了多少可复用结构。
预训练的基本流程
工业级预训练不是简单地把数据喂进模型跑一遍,而是一套完整的系统工程。它要同时解决三个问题:模型学什么、怎么稳定学、学完之后如何判断是否真的变强。
经典的预训练流程
一个经典的预训练流程如下图所示:
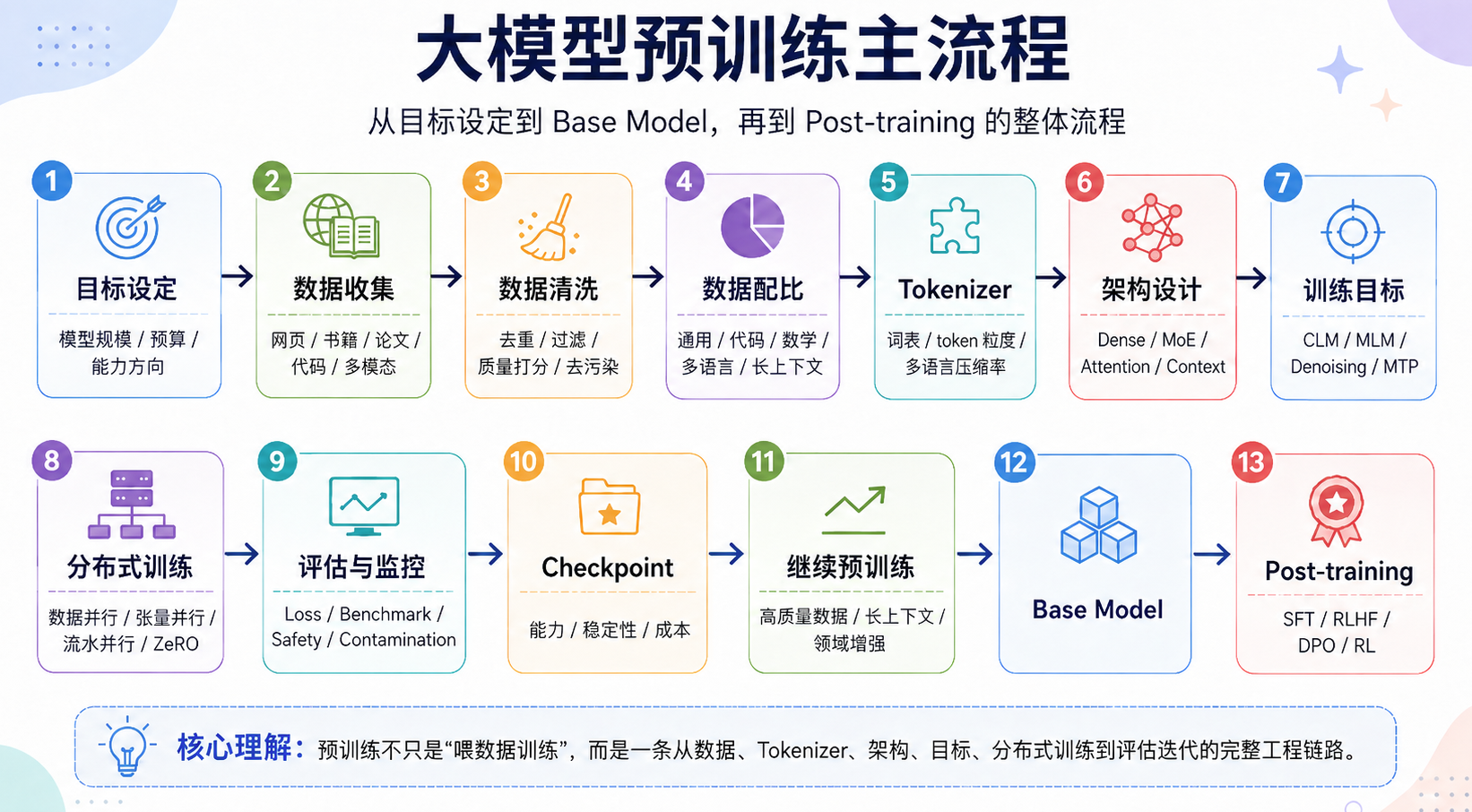
下面分别来看一下各个环节的主要内容:
- 目标设定:明确模型规模、训练预算、能力方向和上下文长度,它决定了这次预训练的工作目标;
- 数据收集:收集网页、书籍、论文、代码、数学、多语言、多模态等数据,为模型提供足够广的知识、语言和任务分布(crawl、合成数据等方案);
- 数据清洗:去重、过滤低质文本、处理隐私、安全和污染问题,避免模型学习垃圾内容、重复模式和评估集泄漏(MinHash 去重、质量分类器等方案);
- 数据配比:这里的第 2 到第 4 步可以合称为预训练数据工程,数据配比是设计通用文本、代码、数学、多语言、长上下文数据的比例,来控制模型的能力结构(数据混合策略、采样权重、curriculum learning、annealing data mix 等方案);
- Tokenizer 设计:把文本切成模型可处理的 token,决定模型看语言、代码和多语言内容的颗粒度(BPE、SentencePiece、Unigram、词表设计、多语言压缩率优化);
- 架构设计:确定模型主体结构、参数规模、Attention 和 MLP/MoE 形式,它决定了模型容量、训练效率和推理成本(Decoder-only Transformer、RoPE、GQA/MLA、SwiGLU、Dense/MoE);
- 训练目标:定义模型要优化的预测任务,决定模型从数据中接收什么样的学习信号(Causal LM、Masked LM、Denoising、Multi-token Prediction、Contrastive Learning);
- 分布式训练:在大规模 GPU 集群上稳定训练模型,需要解决单卡放不下、单机跑不动、训练周期过长等问题(Data/Tensor/Pipeline/Sequence Parallelism、ZeRO/FSDP、混合精度、FP8/BF16);
- 训练监控与评估:持续观察 loss、benchmark、稳定性和安全指标(validation loss、perplexity、MMLU/GSM8K/HumanEval、安全评估、污染检测);
- Checkpoint:Checkpoint 主要是解决训练故障恢复问题,同时为后续模型选择和继续训练保留可回退版本;
- 继续预训练:模型已经完成了一轮大规模通用预训练,但还没有进入正式指令微调之前,再用特定数据继续训练一段,让基座模型在某些能力上进一步增强,比如 Llama 4 官方博客把 continued training 称为 mid-training,并提到用专门数据做长上下文扩展。DeepSeek-V3 也公开描述了先预训练,再分两阶段把上下文扩到 32K 和 128K(mid-training、continued pre-training、context extension、final data mix);
- 得到 Base Model:完成预训练部分,为后续 SFT、RLHF、DPO、Agent 训练提供能力底座。
从这里可以看到,预训练不是单点算法,而是一条从数据构建 → 模型设计 → 大规模优化 → 评估筛选 → 基座模型产出的完整链路。数据决定模型能学到什么,架构决定模型能装下多少能力,训练系统决定模型能不能稳定学完,评估体系决定我们是否知道它真的学会了。
业内基模预训练路线总结
为了理解预训练在工业界如何落地,我们可以从几类代表性模型和论文入手。它们分别推动了预训练范式的不同阶段:BERT 证明了“预训练 + 微调”的有效性,GPT-3 展示了规模化自回归预训练的潜力,Scaling Laws 和 Chinchilla 让训练预算变得可估算,Llama、DeepSeek 等模型则进一步把重点推进到数据课程、MoE、多模态、长上下文和训练效率上。
- BERT:证明“预训练 + 微调”范式有效,BERT 虽然不是生成式模型的主流形态,但它证明了一件非常重要的事情,先在海量数据上学习通用表征,再针对具体任务微调,可以显著提升 NLP 系统的效果;
- GPT-3:把自回归预训练推向规模化,GPT-3 的关键贡献,不是发明 next token prediction,而是证明当模型参数、训练数据和计算规模足够大时,同一个自回归预测目标可以诱导出 few-shot 和 in-context learning 能力;
- Scaling Laws 与 Chinchilla 理论:让预训练从经验扩张走向预算优化,Scaling Laws 研究的是模型 loss 如何随参数量、数据量和训练算力变化,它给大模型训练提供了可预测的经验规律。Chinchilla 进一步指出,在固定算力下,不能只盲目增大模型参数,也要匹配足够多的训练 token。它修正了早期“参数越大越好”的直觉,让行业开始重视 compute-optimal:在给定预算下,如何平衡模型容量和训练数据量。这也是后来很多模型强调训练了多少 trillion tokens 的原因。
- Llama 系列:把强基座模型训练经验带到开源社区,Llama 系列的价值,不只是模型本身效果强,而是把现代基座模型的很多关键实践公开化:decoder-only Transformer、RoPE、GQA、SwiGLU、RMSNorm、更大规模的数据、更系统的评估,以及 base model 和 instruct model 的区分。Llama 3 进一步展示了开源 dense 模型在大规模数据和系统化训练下可以达到很强能力。Llama 4 则把路线推向 MoE、原生多模态、FP8、mid-training 和超长上下文,说明开源基模也在从“强语言模型”走向“稀疏激活 + 多模态 + 长上下文”的综合系统;
- DeepSeek-V3:把训练效率和系统工程变成核心竞争力,DeepSeek-V3 的重点不是单纯堆参数,而是在 MoE、MLA、FP8、Multi-token Prediction 和分布式训练系统上做了大量设计。它通过较大的总参数和较低的激活参数,在模型容量和每 token 计算成本之间取得平衡;通过 MLA 降低注意力开销;通过 FP8 和通信计算重叠提升训练效率。它代表了一个很重要的趋势:前沿预训练不再只是模型结构创新,而是架构、数据、精度、并行策略和训练系统的端到端协同优化。
预训练的核心挑战
预训练真正难的地方,不只是“把模型训大”,而是要在数据质量、训练规模、优化稳定性、架构效率、长上下文、事实可靠性和评估可信度之间取得平衡。任何一环处理不好,都会直接影响基座模型的能力上限。
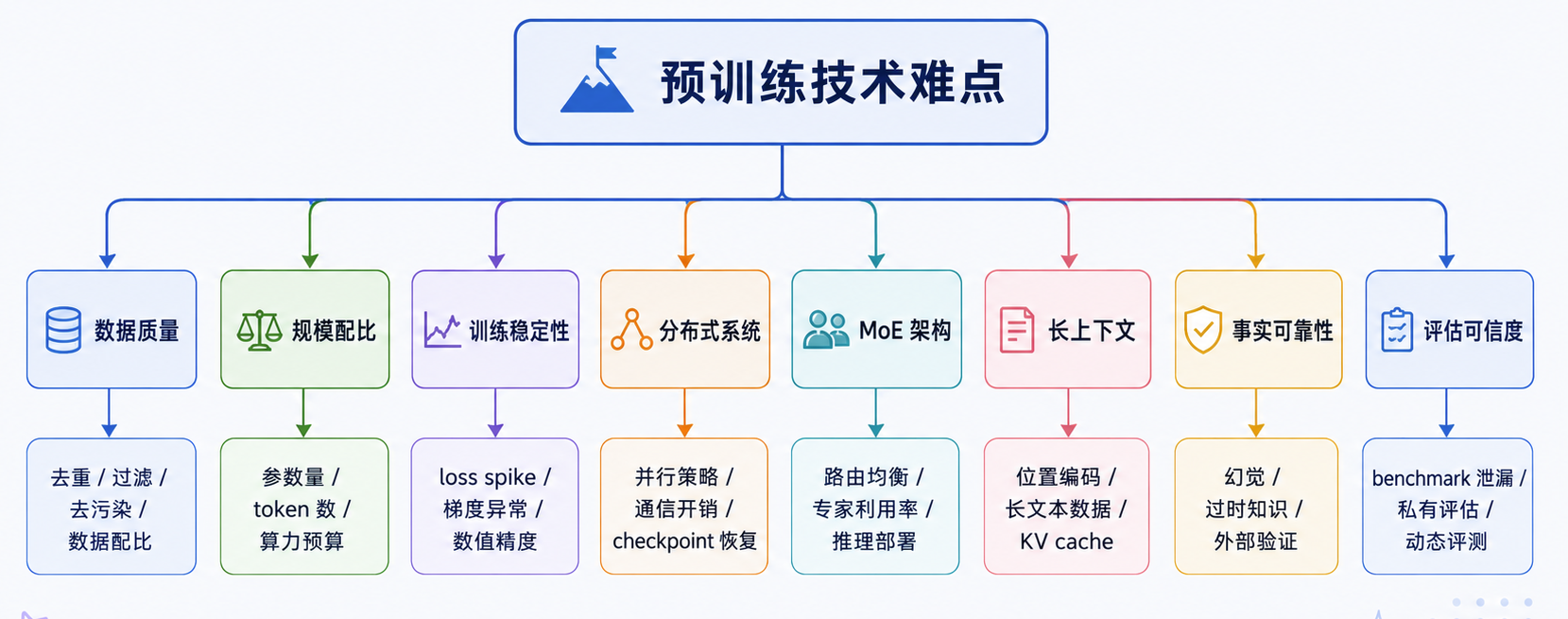
上面提到的这几个问题并不是孤立的。例如,数据质量会影响训练稳定性,长上下文会放大系统成本,MoE 会带来通信和路由问题,评估污染会让模型能力判断失真。所以工业级预训练本质上是一套综合优化工程。
数据层面的挑战
数据质量
- 挑战:训练数据里有重复、低质、错误、毒性、隐私、版权和评估集泄漏问题;
- 难点:模型会稳定学习数据中的模式,垃圾数据不会自动消失,反而会被参数吸收;
- 解决方案:文档级/URL 级/近重复去重,MinHash,质量分类器,安全过滤,隐私过滤,benchmark decontamination;
数据配比
- 挑战:通用文本、代码、数学、多语言、长上下文、合成数据比例如何分配;
- 难点:不同数据会塑造不同能力,比例失衡会导致模型偏科,比如代码强但自然语言变硬;
- 解决方案:数据混合策略,采样权重,能力导向数据配比,小模型 ablation,curriculum learning,final data mix;
高质量数据稀缺
- 挑战:数学、代码、科学、长文档、多语言低资源数据不足;
- 难点:互联网数据量大但质量不均,高知识密度数据有限,很多领域数据难获取;
- 解决方案:专家数据、教材化数据、合成数据、模型生成数据筛选、领域数据继续预训练。
技术和工程化层面挑战
训练稳定性
- 挑战:大规模训练中可能出现 loss spike、梯度爆炸、数值异常;
- 难点:训练周期长、GPU 数量多、数据复杂,任何局部异常都可能放大成全局训练问题;
- 解决方案:learning rate warmup,cosine decay,gradient clipping,loss scaling,异常 batch 检测,checkpoint 回滚;
分布式训练
- 挑战:单卡放不下模型,单机跑不动数据,训练需要跨大量 GPU;
- 难点:并行方式复杂,通信开销高,节点故障、网络抖动都会影响训练;
- 解决方案:Data Parallel、Tensor Parallel、Pipeline Parallel、Sequence Parallel、ZeRO/FSDP、通信计算重叠;
Checkpoint 管理
- 挑战:训练中断后如何恢复,异常模型如何回滚;
- 难点:大模型训练成本极高,一次故障可能损失大量 GPU 小时;
- 解决方案:高频 checkpoint,异步保存,参数/优化器/学习率状态保存,断点恢复,版本管理;
长上下文
- 挑战:模型能接收长输入,不代表能真正用好长输入;
- 难点:attention 成本高,位置编码外推有限,长文本训练数据不足,模型容易忽略中间信息;
- 解决方法:RoPE scaling、YaRN、ALiBi,长上下文继续预训练,长文档/代码库数据,稀疏 attention,KV cache 优化;
训练成本
- 挑战:预训练需要巨大算力、存储、网络和工程投入;
- 难点:成本不仅来自 GPU,还来自数据处理、失败重训、评估、部署和推理;
- 解决方案:高效架构,MoE,FlashAttention,FP8,训练系统优化,数据质量提升,训练-推理协同设计;
小结
本质上,预训练的核心挑战,是在有限算力下,用足够干净、足够多样、足够高密度的数据,稳定训练一个容量足够大、成本可接受、评估可信、后训练潜力强的基座模型。其中几个关键权衡如下:
| 矛盾 | 本质 |
|---|---|
| 数据规模 vs 数据质量 | 不是 token 越多越好,而是模型是否值得学习这些 token |
| 模型容量 vs 训练成本 | 参数越多能力潜力越大,但训练和推理成本也越高 |
| 稳定性 vs 效率 | 更激进的精度、并行和学习率策略能提速,也更容易不稳定 |
| 长上下文能力 vs 系统成本 | 上下文越长,attention、KV cache 和数据构建成本越高 |
| benchmark 分数 vs 真实能力 | 榜单高分不一定代表真实任务表现强 |
| 会生成 vs 说真话 | 预训练让模型更会生成文本,但事实可靠性需要额外机制保证 |
预训练的本质:从分布拟合到能力涌现
预训练表面上是在做一件很简单的事:根据上下文预测下一个 token。
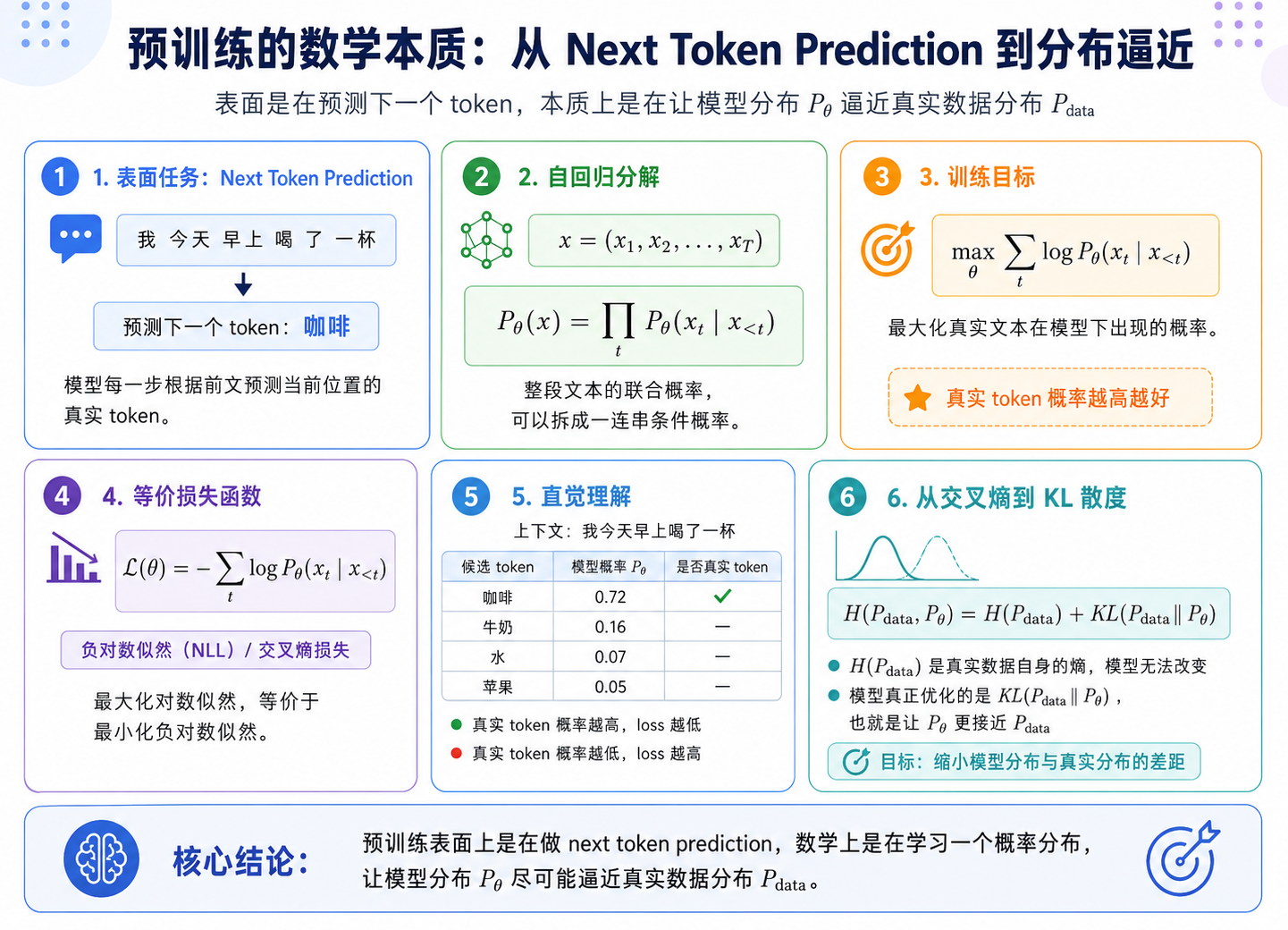
数学本质
预训练表面上是在做 next token prediction,但数学上是在学习一个概率分布:让模型分布 Pθ 尽可能逼近真实数据分布 P_data。设一段 token 序列为:
1 | x = (x1, x2, ..., xT) |
自回归语言模型会把整段文本的概率拆成一连串条件概率:
1 | Pθ(x) = Π_t Pθ(x_t | x_<t) |
也就是:每一步都根据前文 x_<t,预测当前位置的真实 token x_t。因此,预训练的目标是最大化真实文本出现的概率:
1 | max θ Σ_t log Pθ(x_t | x_<t) |
实际训练时,通常写成最小化负对数似然:
1 | L(θ) = - Σ_t log Pθ(x_t | x_<t) |
这就是交叉熵损失的核心形式。直觉上:
1 | 真实 token 概率越高,loss 越低; |
进一步看,交叉熵可以分解为:
1 | H(P_data, Pθ) = H(P_data) + KL(P_data || Pθ) |
其中 H(P_data) 是真实数据自身的熵,模型无法改变;模型真正能优化的是 KL(P_data || Pθ),也就是模型分布和真实数据分布之间的差距。
所以,预训练的数学本质可以概括为:
1 | 预测下一个 token |
这也解释了为什么 loss 是预训练最核心的指标:loss 下降,通常意味着模型更好地拟合了数据分布。但它也有边界:数据分布不等于事实真理,模型学到的是“什么文本更可能出现”,不等于“什么内容一定正确”。
智能涌现
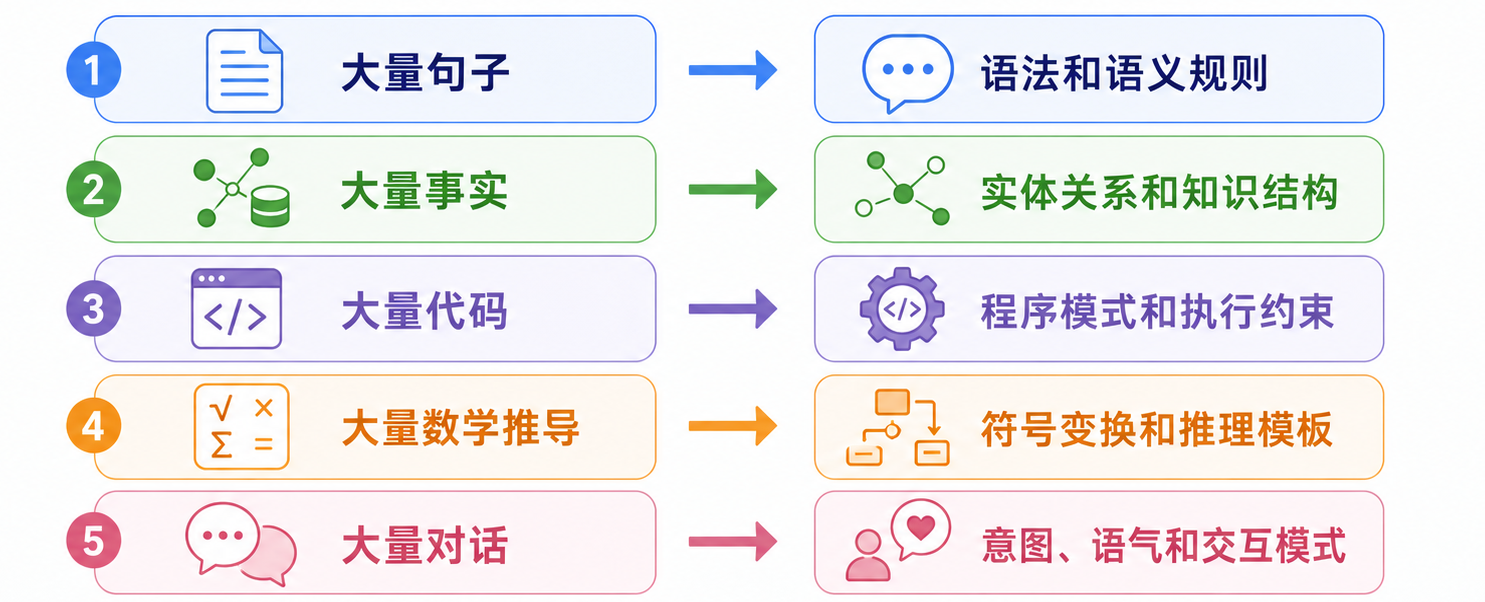
为什么预测下一个 token 会产生看似更高级的能力?因为真实语料中的 token 并不是随机出现的。语言背后包含语法、语义、事实、代码结构、数学规则、社会常识和任务模式。要持续预测得更准,模型不能只学表层词频,它必须学习更深的隐藏结构。例如:
| 表面预测任务 | 背后必须学习的结构 |
|---|---|
| 预测一句话的下一个词 | 语法、语义、上下文依赖 |
| 预测事实性内容 | 实体关系、时间地点、常识结构 |
| 预测代码下一行 | 变量作用域、控制流、API 模式 |
| 预测数学推导 | 符号规则、约束关系、证明路径 |
| 预测对话回复 | 用户意图、语气、社会语境 |
| 预测长文后续 | 篇章结构、主题一致性、长期依赖 |
所以,next token prediction 表面上是语言任务,本质上是一个高压缩率的结构学习任务。模型为了降低 loss,会把一切有助于预测的规律压缩进参数中。可以把这个过程理解成:
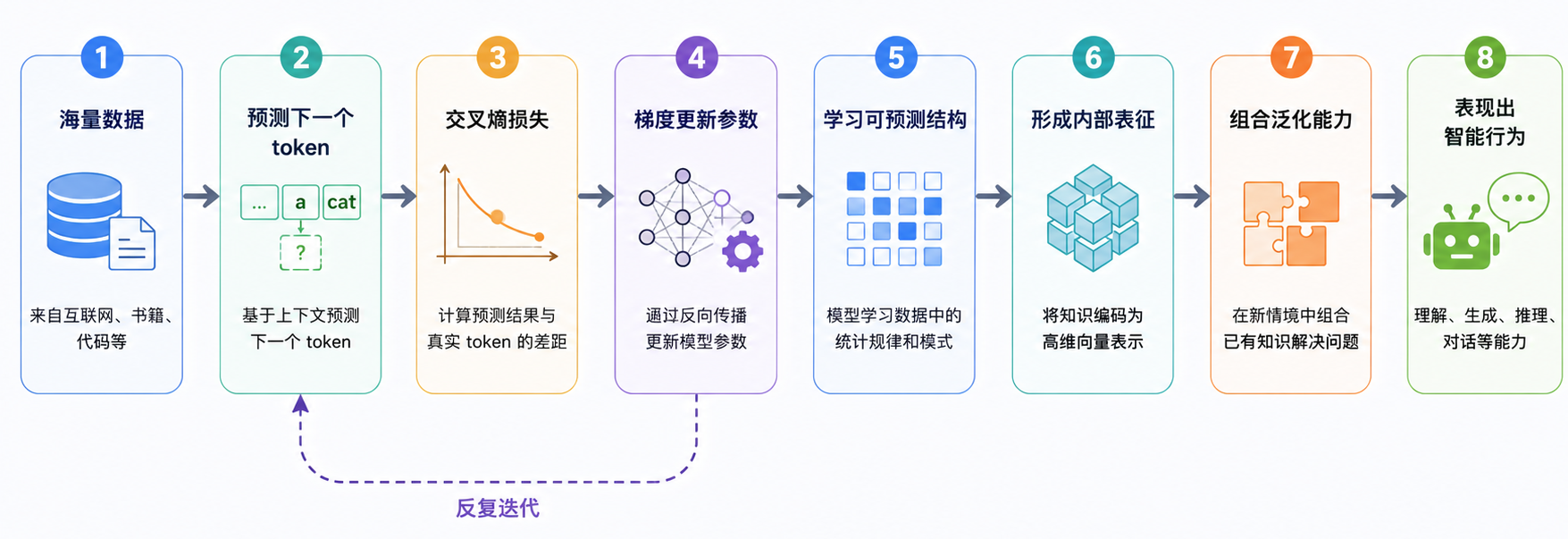
从信息论角度看,预训练也是一种压缩。模型参数远远小于训练数据本身,它不可能把所有样本逐字存下来。为了在有限参数中解释海量数据,模型必须抽取更抽象、更可复用的结构:
好的模型不是记住每个样本,而是找到一套更短、更抽象的结构来解释大量样本。所谓“智能涌现”,它不是某个显式模块突然觉醒,而是当数据足够广、模型容量足够大、训练目标足够统一、优化足够充分时,模型内部形成了可组合的表征空间。这个表征空间让模型能够把旧结构迁移到新问题中。更准确地说,是一种可泛化的预测与组合能力。它来自模型对数据中可预测结构的深度压缩,而不是来自显式规则库,也不是来自人工标注任务的堆叠。
但也要看到边界。预训练优化的是文本分布,不是真理本身。模型学会的是“什么输出在这个上下文中更像真实数据”,而不是“这个输出是否一定符合现实”。因此,预训练可以提供强大的语言、知识、代码和推理底座,但事实可靠性、价值对齐、工具使用、长期规划和安全边界,还需要后训练、检索、工具调用和外部验证来补足。
预训练的未来趋势
从公开论文和技术报告看,预训练正在从“单纯扩大规模”走向更精细的系统优化。未来的核心不只是训练更大的模型,而是用更高质量的数据、更高效的架构和更贴近真实任务的训练方式,提升基座模型的通用能力。
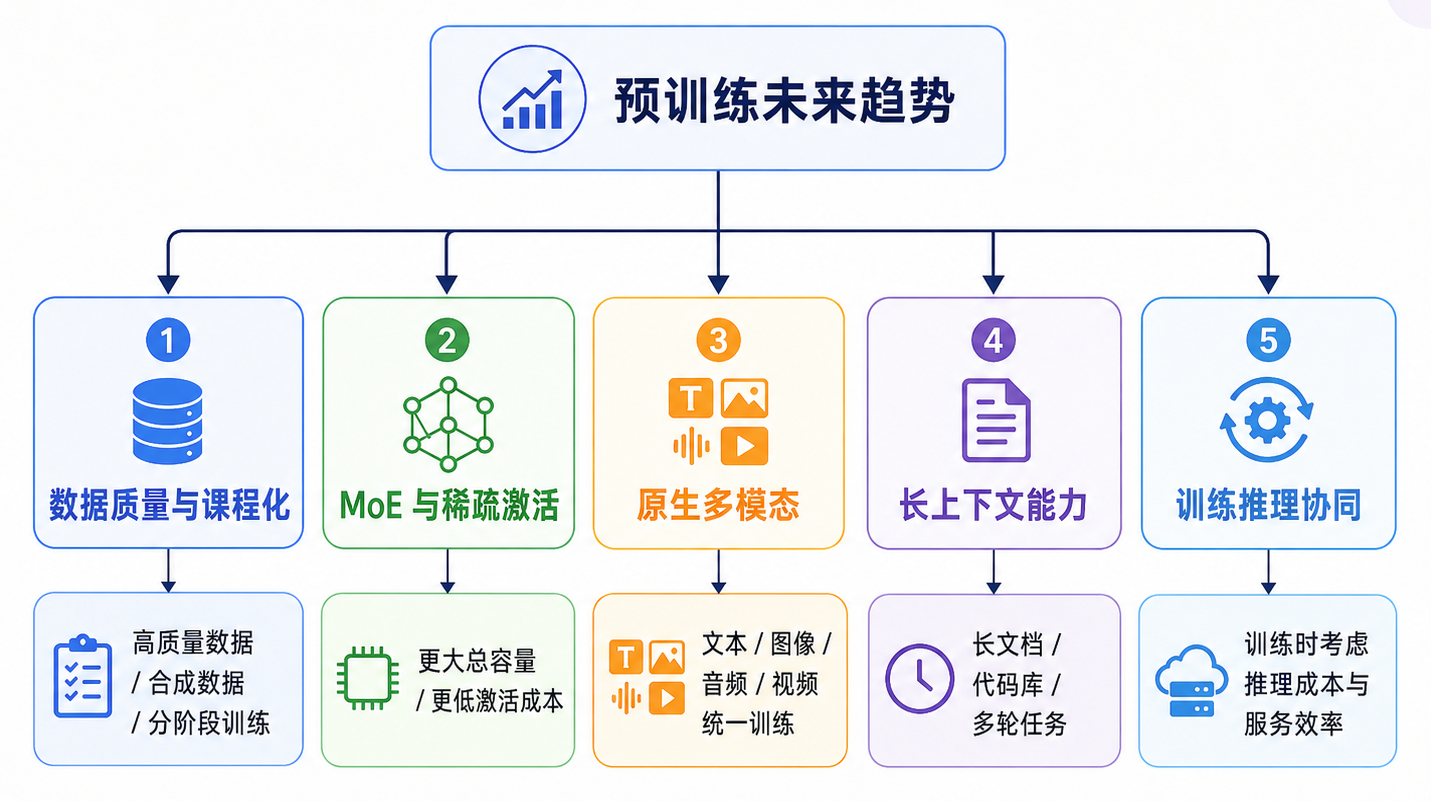
- 从堆规模走向数据质量与课程设计:早期预训练更强调参数量和 token 数,但现在行业越来越重视数据质量、数据配比和训练阶段设计。现代基模通常不会把所有数据简单混在一起训练,而是会分阶段加入通用文本、代码、数学、长上下文、多语言和合成数据,让模型能力按目标逐步形成。
- MoE 与稀疏激活成为扩容主线:Dense 模型继续扩大参数会带来很高的训练和推理成本,因此 MoE 成为重要方向。它的核心思路是:模型拥有更大的总参数容量,但每个 token 只激活其中一部分专家。这样可以在提升模型容量的同时,控制每次推理的计算成本。
- 预训练从纯文本走向原生多模态:多模态能力不再只是“语言模型外接视觉模块”,而是越来越多地进入预训练阶段。文本、图像、音频、视频、代码、屏幕操作轨迹,都可能被 token 化后进入统一训练流程。未来基座模型会更像一个统一的信息处理系统,而不是单纯的文本生成器。
- 长上下文成为基座能力的一部分:长上下文不再只是推理阶段的补丁,而会在预训练或继续预训练阶段被系统性增强。真正有价值的长上下文能力,不只是“能塞更多 token”,而是能处理整份代码仓库、多篇论文、长会议记录、多文档任务和长期交互历史。
- 训练和推理开始协同设计:未来模型不会等训练完成后才考虑部署成本,而是在预训练阶段就考虑推理效率、KV cache、MoE 调度、精度格式、并行策略和服务吞吐。强模型不只要能力强,还要能以可控成本稳定服务真实用户。
