LLM 系列 (七):后训练与对齐:从续写器到协作者
如果说预训练回答的是“大模型的通用能力从哪里来”,那么后训练回答的就是另一个更关键的问题:这些能力如何被稳定、可靠、可控地组织成用户真正可用的行为。
预训练后的 Base Model 已经学到了大量语言、知识、代码、数学和推理模式,但它本质上仍然是一个基于上下文预测下一个 token 的生成模型。它可以续写论文、代码、对话和网页,也可能生成看似合理但不一定真实、安全或符合用户意图的内容。换句话说,Base Model 拥有能力,但还没有被塑造成一个“助手”:它不天然知道什么叫听指令,什么叫有帮助,什么时候应该拒绝,什么时候应该承认不确定,什么时候应该调用工具完成任务。
后训练要解决的,正是从“能力”到“行为”的转化问题。它通过指令微调(SFT)、偏好对齐、强化学习(RL)、安全约束和工具训练,把预训练中形成的潜在能力重新塑造成可交互、可约束、可协作的输出模式。预训练让模型学会世界如何被语言表达,后训练则让模型学会如何在人类任务中正确使用这些能力。
一句话概括:预训练决定模型会什么,后训练决定模型如何把这些能力用好。
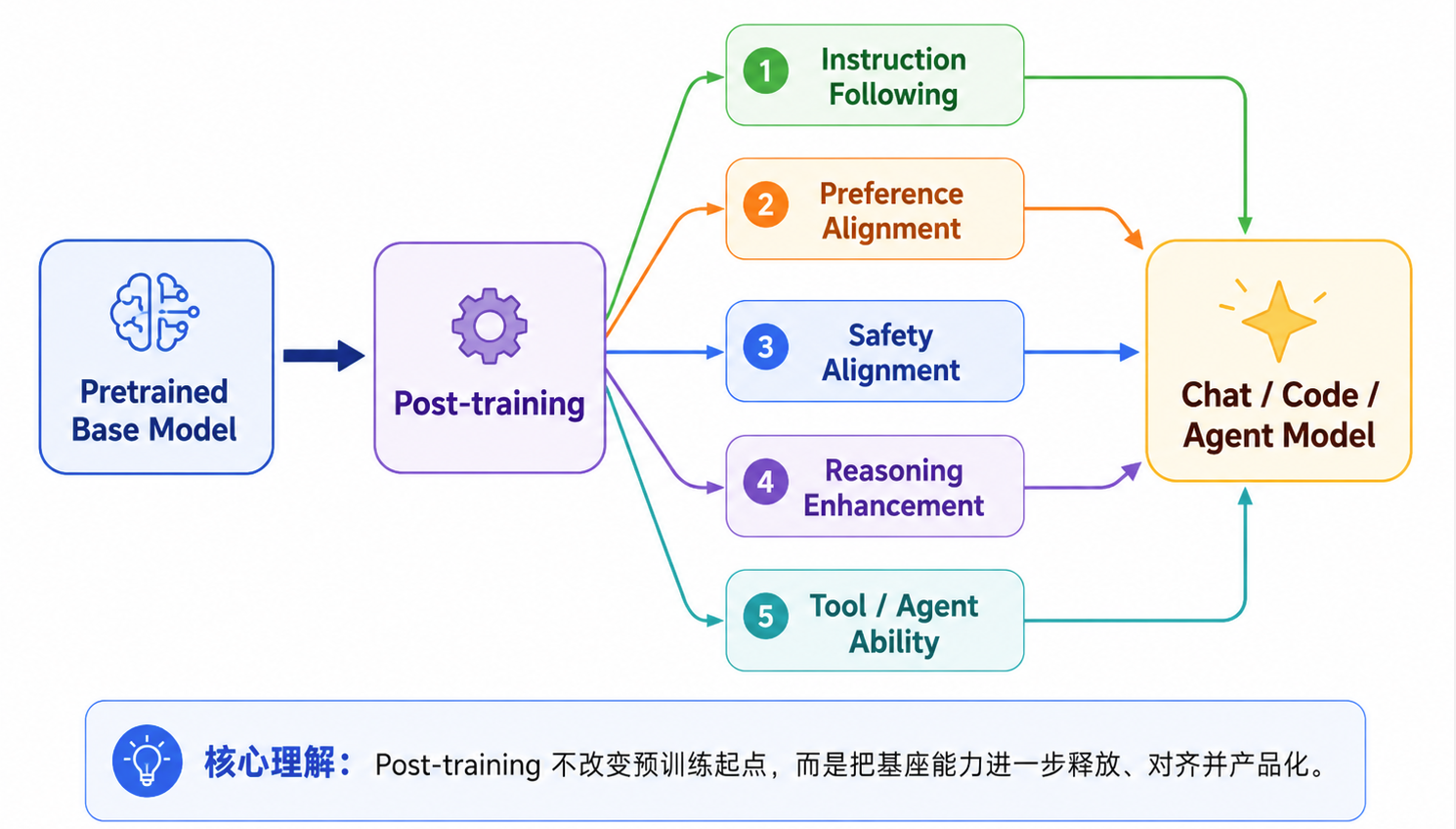
后训练的定位
后训练,指的是在预训练基座模型之上,继续使用指令数据、偏好数据、安全数据、推理数据、工具调用轨迹和环境反馈,对模型行为进行定向塑形的训练过程。它要解决的问题不是“模型有没有知识”,而是:
- 能不能理解用户真实意图;
- 能不能按任务要求组织答案;
- 能不能输出更符合人类偏好的结果;
- 能不能在高风险问题上保持边界;
- 能不能通过推理、工具和反馈完成复杂任务。
预训练优化的是:maximize P(text),也就是让模型生成更像训练语料的文本。
后训练优化的是:
1 | maximize P(good response | instruction, preference, safety, context) |
也就是让模型在给定指令、偏好和约束下,生成更有用、更可靠、更安全的回答或行动。
| 维度 | 预训练 | 后训练 |
|---|---|---|
| 核心目标 | 学习数据分布 | 塑造模型行为 |
| 模型形态 | Base Model | Chat / Instruct / Reasoning / Agent Model |
| 数据来源 | 海量文本、代码、多模态数据 | 指令、偏好、安全、推理、工具轨迹 |
| 监督信号 | 下一个 token | 示范答案、偏好排序、奖励、验证器 |
| 训练规模 | token 规模极大 | 数据更少,但质量要求极高 |
| 主要能力 | 语言、知识、代码、表征、模式 | 指令跟随、偏好对齐、安全边界、工具使用 |
| 核心风险 | 数据污染、训练不稳、知识错误 | 奖励黑客、过度拒答、能力退化、评估失真 |
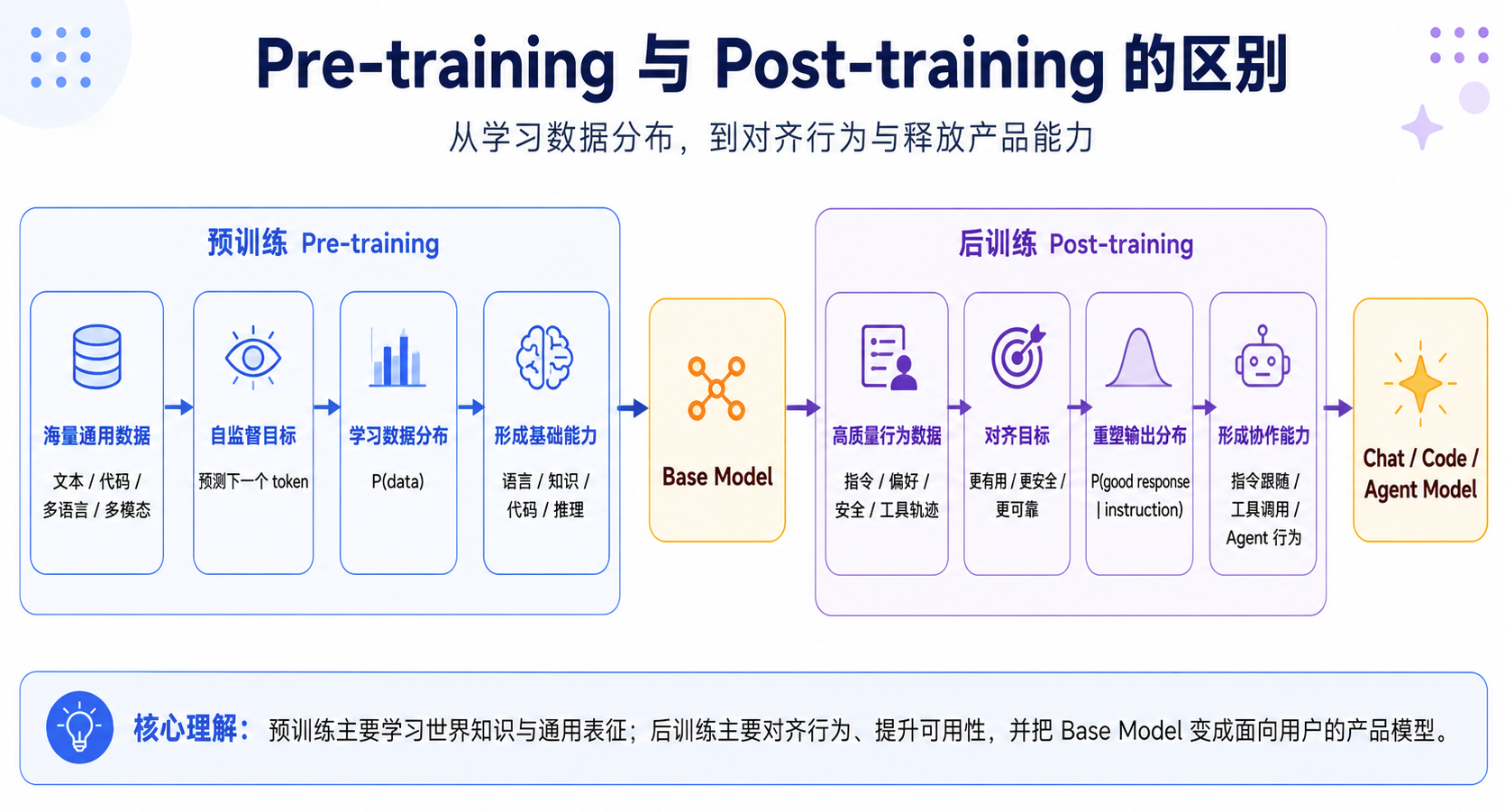
可以用一个更直观的对比:
| 模型类型 | 用户输入 | 模型可能行为 |
|---|---|---|
| Base Model | “请解释 Transformer” | 可能续写一段网页、论文、问答或代码注释 |
| Chat Model | “请解释 Transformer” | 识别为用户请求,并组织成清晰解释 |
| Agent Model | “帮我分析这个项目的性能瓶颈” | 读取文件、运行工具、定位问题、给出修改建议 |
后训练的关键作用,就是让模型从“预测文本”转向“完成任务”。
后训练主流程:从 SFT 到 Agent 训练
后训练不是单一步骤,而是一组围绕行为塑形展开的训练阶段。不同公司细节不同,但主链路大体相似。
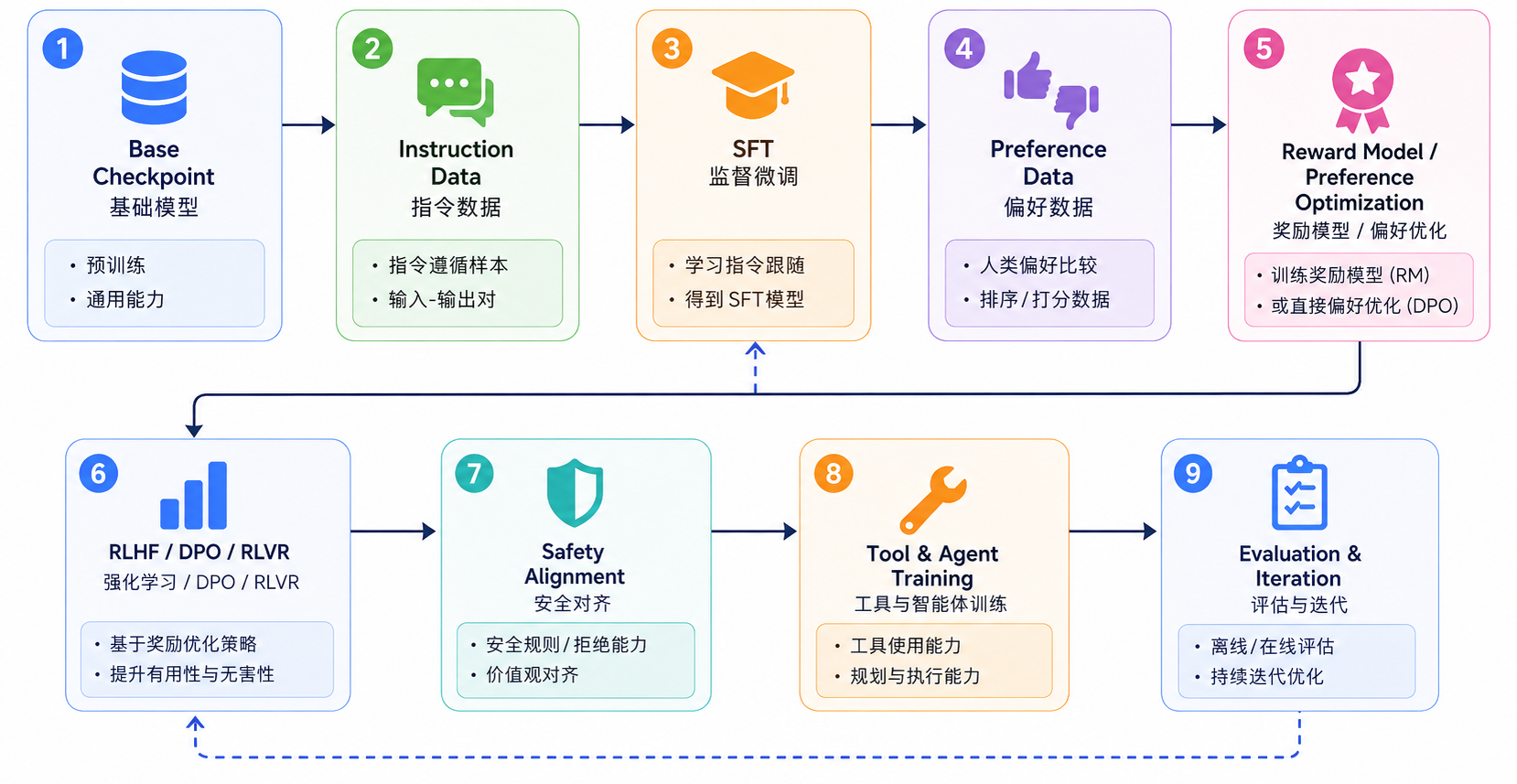
这些阶段如下所示:
| 阶段 | 要解决的问题 | 核心难点 | 主流方案 |
|---|---|---|---|
| Base Checkpoint 选择 | 选出适合后训练的预训练模型 | loss 最低不等于最好对齐;能力短板可能被后训练放大 | 综合看通用能力、推理能力、安全风险、领域覆盖和稳定性 |
| 指令数据构建 | 让模型知道用户是在下任务 | 数据容易模板化、浅层化、污染评测 | 人工高质量示范、合成指令、难度分层、数据去重 |
| SFT 指令微调 | 把“续写器”变成“指令跟随模型” | 学少了不听指令,学多了容易套路化 | 用高质量 prompt-response 数据做监督微调 |
| 偏好数据构建 | 定义什么回答更好 | 人类偏好主观、昂贵、不一致 | pairwise ranking、多标注一致性、AI 辅助标注 |
| Reward Model | 学习人类偏好的近似函数 | 偏好数据噪声、reward 泛化差、校准困难 | pairwise ranking / Bradley-Terry loss、多维 reward、reward calibration |
| RLHF / DPO | 让输出更符合偏好 | PPO 复杂,DPO 依赖数据质量 | PPO、DPO、IPO、KTO、ORPO 等 |
| RLVR | 强化数学、代码、推理能力 | 很多任务没有明确 reward | 答案校验、单元测试、规则验证器、环境反馈 |
| 安全对齐 | 降低有害输出和越狱风险 | 拒答过多会损害可用性 | 安全 SFT、红队数据、RLAIF、安全分类器 |
| 工具与 Agent 训练 | 让模型从回答走向行动 | 工具时机、参数、状态跟踪、失败恢复都难 | function calling、工具轨迹、多步任务、环境交互 |
| 评估与迭代 | 判断模型是否真的变好 | benchmark 高不等于真实好用 | 自动评测、人工评测、红队、真实任务成功率 |
SFT:从续写到指令跟随
SFT(Supervised Fine-Tuning,监督微调,又叫做指令微调)是后训练的第一步,目标是让 Base Model 从“继续写下去”,变成“按用户指令回答”。它使用的是高质量的指令-回答样本:
1 | User: 用三句话解释 Transformer 的核心思想。 |
训练时,用户指令作为条件输入,理想回答作为监督目标,模型继续用交叉熵优化回答 token:
1 | L_SFT = - Σ_t log πθ(y_t | x, y_<t) |
其中,x 是用户指令,y 是标准回答。SFT 的核心作用不是重新教模型知识,而是教模型一种交互模式,它让模型学会识别任务意图、遵循输出格式、组织答案结构、保持对话角色,并在翻译、总结、代码、解释、问答等常见场景中形成稳定响应。
1 | 理解指令 -> 判断任务 -> 组织答案 -> 按期望格式输出 |
所以 SFT 数据的质量极其重要。一句话概括:SFT 不是给模型注入全部能力,而是把预训练中已有的能力,校准到人类可用的指令响应方式上。
偏好对齐:把“更好”变成训练信号
SFT 让模型学会“按指令回答”,但它并不能充分解决“什么回答更好”的问题。很多任务并没有唯一标准答案:两个回答都可能事实正确,但一个更清晰、更简洁、更符合上下文;也可能一个语气很好,却在关键事实上犯错。偏好对齐要解决的,就是把这种难以直接写成规则的质量判断,转化为模型可以学习的训练信号。
典型做法是:给定同一个 prompt,让模型生成多个回答,再由人类标注员、专家或更强模型比较哪个更好:
1 | Prompt: 解释一下 RLHF。 |
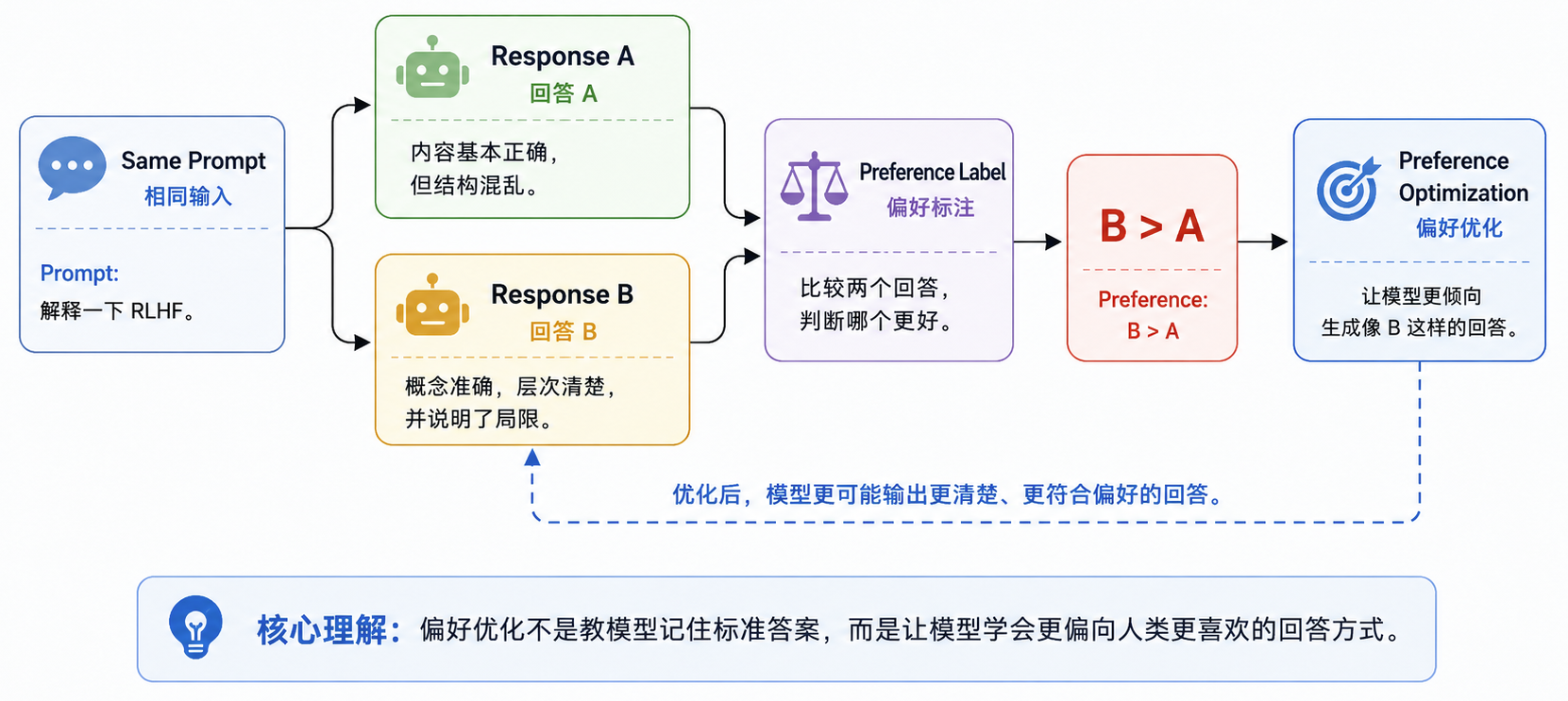
偏好数据通常不是给每个回答打绝对分,而是构造相对排序:
1 | chosen response > rejected response |
这样做更符合真实标注过程:人类很难完整定义“好回答”的评价函数,但通常能在两个候选回答之间做出选择。
从原理上看,偏好对齐学习的不是事实知识本身,而是回答选择策略:在多个可能输出中,提高更有帮助、更真实、更安全、更符合用户意图的回答概率,降低表面合理但质量更差的回答概率。
RLHF、DPO 与 RLVR:从模仿到优化
SFT 主要是模仿学习:让模型学习高质量示范回答的形式和行为。偏好优化则更进一步,它不只是让模型“像示范答案”,而是让模型在多个可能输出中,更倾向于生成被偏好的回答。
RLHF 是经典路线。它通常先用偏好数据训练一个 Reward Model,再用强化学习优化语言模型,使模型输出获得更高奖励。目标可以简化理解为:
1 | maximize reward(response) - β · KL(πθ || πref) |
其中,reward(response) 鼓励模型生成更符合人类偏好的回答;KL(πθ || πref) 约束模型不要偏离原始参考模型太远,避免为了追求奖励而出现语言质量下降、模式崩坏或 reward hacking。
DPO 则把这条路径简化了。它不显式训练 Reward Model,也不跑 PPO,而是把偏好对转化为一个直接优化策略的损失:让 chosen response 相对于 reference model 的概率优势更大,让 rejected response 的相对优势更小。直观上,它是在用偏好数据直接调整模型的输出分布。
RLVR(Reinforcement Learning with Verifiable Rewards,可验证奖励强化学习)把反馈信号从“人类更喜欢哪个回答”,扩展到“这个结果是否真的正确”。它特别适合数学、代码、工具调用这类可自动验证的任务:
| 任务 | 可验证反馈 |
|---|---|
| 数学 | 最终答案是否正确 |
| 代码 | 单元测试是否通过 |
| 工具调用 | 参数是否正确、执行是否成功 |
| 检索问答 | 答案是否被证据支持 |
RLHF 和 DPO 主要优化“回答是否符合偏好”,RLVR 则更直接优化“任务是否成功”。这也是近年推理模型的重要方向:当奖励信号足够明确时,后训练不只是让模型更会说话,还能显著放大数学、代码和复杂推理能力。
安全对齐与工具训练
RLHF / DPO / RLVR 解决的是回答质量和任务成功率,但产品模型还需要安全边界和行动能力。安全对齐通过安全 SFT、拒答数据、红队样本和风险分类器降低有害输出;工具与 Agent 训练则通过 function calling、工具轨迹和环境反馈,让模型学会何时调用工具、如何传参、如何读取结果并修正下一步行动。
工程挑战与模型实践
工程挑战
后训练难,不是因为流程复杂,而是因为它优化的是“行为”。而行为质量不是单一指标:准确、有用、安全、简洁、诚实、可执行之间经常互相牵制。
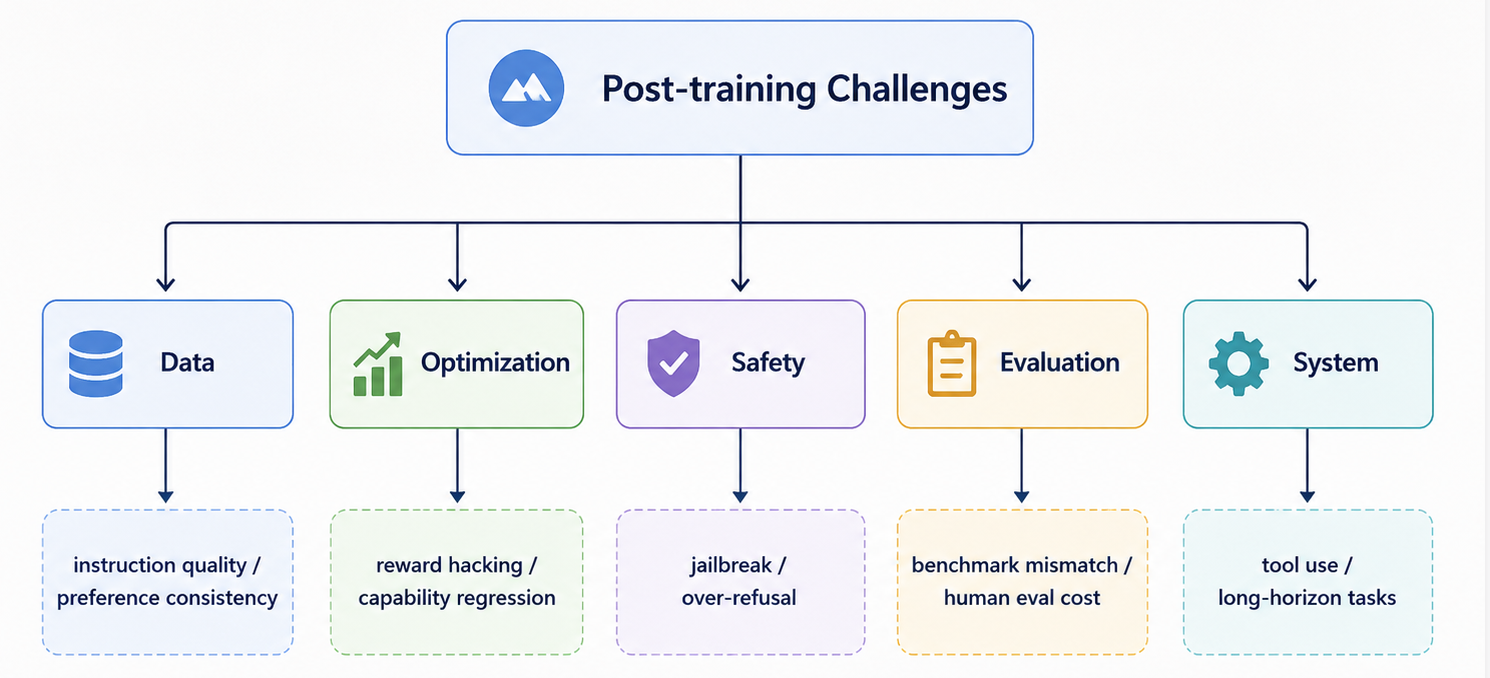
| 挑战 | 本质问题 | 解决思路 |
|---|---|---|
| 指令数据质量 | 模型会强烈模仿数据风格 | 高质量人工数据、合成数据筛选、难度分层 |
| 偏好不一致 | 不同人对“好回答”标准不同 | 标注规范、多标注投票、场景化偏好 |
| Reward hacking | 模型优化 reward,而不是真实质量 | 多奖励模型、KL 约束、红队测试、真实任务验证 |
| 过度对齐 | 模型变得保守,拒答过多 | 精细安全分类、分级拒答、安全替代回答 |
| 能力退化 | 后训练损害预训练能力 | 混合通用数据、能力回归测试、checkpoint 筛选 |
| 推理不稳定 | 会写推理过程,不代表真会推理 | 可验证 reward、过程监督、验证器、工具反馈 |
| 工具调用失败 | 会调用工具,但不会稳定完成任务 | 工具轨迹训练、失败恢复数据、多步环境训练 |
| 评估失真 | 榜单高不等于用户觉得好 | 私有评测、动态评测、人工 blind review、真实任务成功率 |
头部模型实践
后训练的行业实践,本质上是一条能力塑形路线的演进。早期重点是让 Base Model 学会听指令、符合人类偏好;随后开始系统化处理安全边界、拒答策略和事实可靠性;近两年,随着数学、代码和复杂推理任务的重要性上升,后训练进一步转向可验证奖励、长链推理、工具调用和动态推理预算。下面选取几个代表性模型与工作,观察后训练范式是如何一步步演化的。
| 模型 / 工作 | 关键后训练设计 | 解决的核心问题 | 可复用经验 |
|---|---|---|---|
| InstructGPT / ChatGPT | SFT 示范数据 -> Reward Model -> PPO/RLHF | Base Model 不等于好助手,规模变大也不会自然学会遵循用户意图 | 后训练可以显著改变用户感知质量;InstructGPT 论文中,1.3B InstructGPT 在人工偏好上可超过 175B GPT-3 |
| GPT-4 | 闭源细节有限,但公开报告强调 post-training alignment 提升事实性和期望行为遵循 | 前沿模型的能力、安全和可靠性需要在后训练阶段系统调优 | 后训练不只是 SFT/RLHF,而是训练、红队、安全评估、策略约束和上线反馈的组合工程 |
| Claude / Constitutional AI | 用显式原则生成 critique/revision,再用 AI Feedback 做 RLAIF | 纯人工偏好标注成本高,且安全价值观难以隐式学全 | 把“价值原则”显式写入训练流程,让模型基于原则自我批评、自我修正,减少部分有害样本人工标注依赖 |
| Llama 3 | 同时发布 pre-trained 与 post-trained 版本,并配套 Llama Guard 安全模型 | 开源基模不只发布权重,也开始系统公开 instruct model、安全模型、评估方法和关键训练经验。 | 后训练开始成为开源基模能力的一部分:instruct model、安全模型、评测方法需要一起发布 |
| DeepSeek-V3 | 预训练后经过 SFT 和 RL 释放能力,强调训练效率、推理效率和稳定性 | 后训练不再是孤立算法,而要和模型架构、训练系统、推理成本一起设计 | 强模型竞争进入“端到端效率”阶段:MoE、MLA、FP8、SFT、RL、部署成本共同决定模型价值 |
| DeepSeek-R1 | R1-Zero 直接用大规模 RL 激发推理;R1 再加入冷启动数据和多阶段训练 | 传统 SFT/RLHF 更偏行为对齐,难以充分放大数学、代码、复杂推理 | 可验证 reward 是推理模型的关键路径;当答案能自动校验时,RL 可以诱导出反思、长链推理和自我修正 |
| Qwen3 | 统一 thinking / non-thinking 模式,并引入 thinking budget | 推理模型不能所有问题都“深思考”,否则成本和延迟不可控 | 后训练开始从“提高回答质量”走向“调度推理预算”:简单问题快答,复杂问题分配更多计算 |
从这些实践可以看到,后训练已经形成三条清晰主线:
- 行为对齐:以 InstructGPT、ChatGPT、Llama Instruct 为代表,重点是让模型从“续写文本”转向“理解指令、组织回答、符合人类偏好”。
- 安全对齐:以 Claude / Constitutional AI、Llama Guard、GPT-4 为代表,重点是把拒答边界、风险识别、价值约束和安全评估系统化。
- 能力强化:以 DeepSeek-R1、Qwen3 等推理模型为代表,重点是用可验证 reward、长链推理和推理预算控制,进一步释放数学、代码、工具和复杂推理能力。
这说明后训练已经不再只是把 Base Model 调成 Chat Model,而是在决定模型能否成为真正可用、可信、可协作的智能系统。
后训练的未来演进方向
未来后训练的核心,不只是让模型回答得更好,而是让模型在真实任务中完成得更可靠。
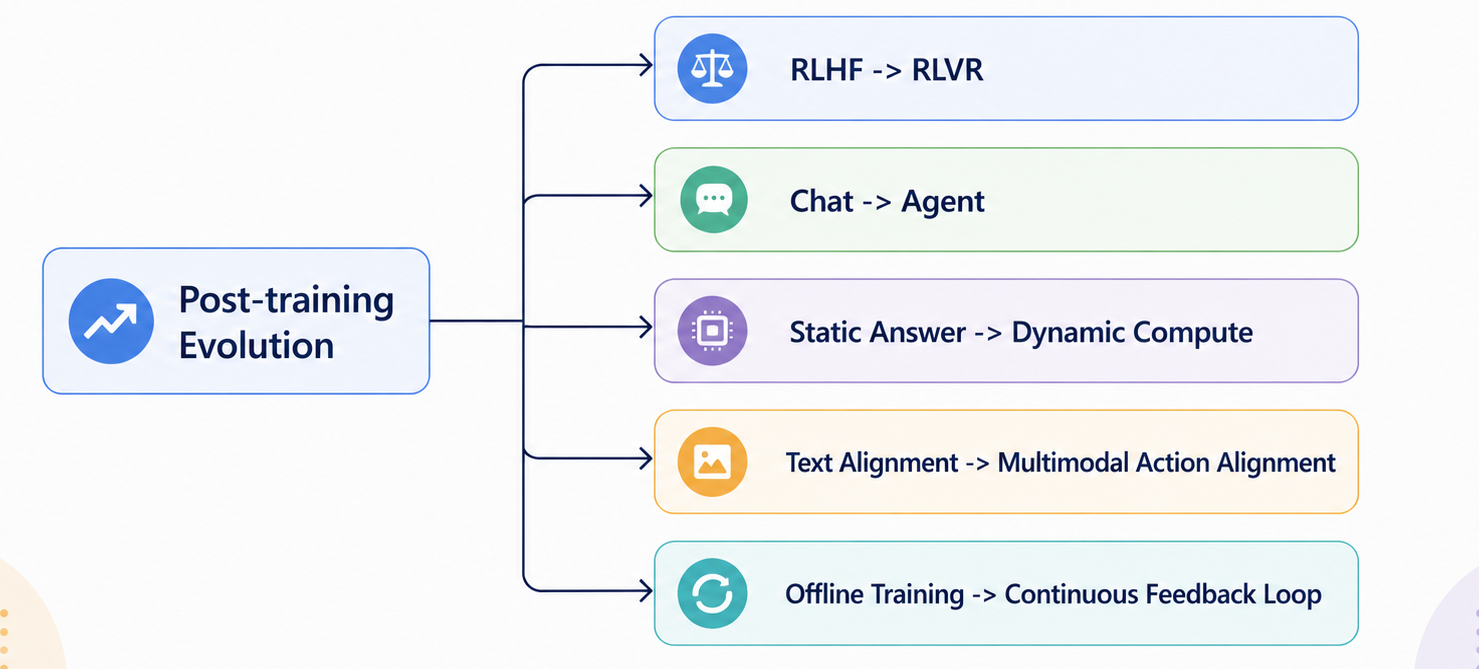
| 方向 | 核心变化 | 意义 |
|---|---|---|
| 从单一 RLHF 到 RLHF + RLVR | 从人类偏好转向可验证反馈 | 数学、代码、工具任务可以直接优化成功率 |
| 从 Chat 到 Agent | 从单轮问答转向长程任务执行 | 模型需要计划、调用工具、观察结果、修正策略 |
| 从统一回答到动态推理预算 | 简单问题快答,复杂问题深思考 | 推理时计算成为可调资源 |
| 从文本对齐到多模态行动对齐 | 文本、图像、音频、屏幕、工具轨迹统一训练 | 模型从语言助手走向真实环境协作者 |
| 从离线训练到持续反馈闭环 | 线上失败案例反哺训练 | 模型迭代速度成为核心竞争力 |
可以把未来的后训练理解成一个闭环:
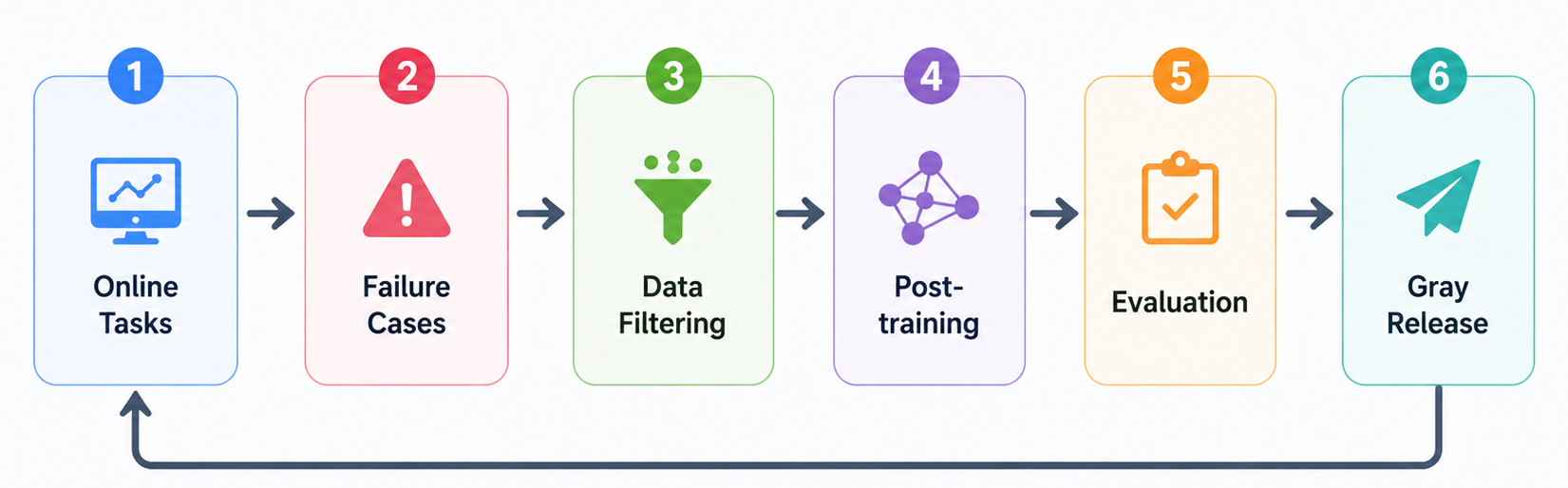
未来强模型的差距,可能不只来自预训练规模,而来自谁能更快完成这个循环:
1 | 发现失败 -> 构造数据 -> 训练改进 -> 验证收益 -> 稳定上线 |
总结
预训练阶段,模型通过海量数据学习语言、知识、代码和世界结构,获得的是一片“能力空间”。但这些能力默认只是以生成概率的形式存在,并不天然等价于可靠的助手行为。
后训练要做的,是在指令、偏好、安全、工具和任务反馈的约束下,重新校准模型的输出分布,让模型更稳定地生成符合目标、约束和场景的回答。
一句话概括:预训练让模型拥有能力,后训练让模型学会正确使用能力。
| 阶段 | 本质 | 产物 |
|---|---|---|
| 预训练 | 学习数据分布,形成通用能力 | Base Model |
| SFT | 模仿高质量示范,建立指令响应模式 | 会听指令的模型 |
| 偏好建模 | 学习什么回答更符合人类偏好 | 可评价回答质量的信号 |
| RLHF / DPO | 调整输出概率,让好回答更容易出现 | 更符合偏好的 Chat Model |
| RLVR | 用可验证反馈强化推理和任务成功率 | 更强的数学 / 代码 / 推理模型 |
| 安全对齐 | 注入边界、拒答和风险判断 | 更可控的模型 |
| 工具与 Agent 训练 | 学习调用工具、观察反馈、完成任务 | 能协作的智能体模型 |
所以,后训练不是预训练之后的“包装层”,而是从能力到行为的关键转换层。它决定模型能不能听懂用户目标,能不能按约束完成任务,能不能在不确定时停下来,能不能在需要时调用工具,也能不能在复杂环境中持续修正自己的行动。
一个真正好用的大模型,不只是会生成流畅文本,而是能把预训练中学到的能力组织成可靠行为:
1 | 理解目标 -> 遵守约束 -> 调用能力 -> 校验结果 -> 修正输出 -> 完成任务 |
这就是后训练与对齐真正要完成的事:让模型不只是会说,而是会协作。
