LLM 系列 (五):Dense 与 MoE,大模型如何从全量计算走向稀疏激活
过去几年,LLM 能力的提升很大程度上来自 Scaling Law:当模型参数量、训练数据规模和计算量持续扩大时,模型的 loss 往往会呈现较稳定的下降趋势,模型能力也会随之提升。简单来说,规模化训练证明了一件事:更大的模型、更大的数据、更大的算力,通常可以带来更强的模型能力。
但 Scaling Law 也带来了一个现实问题:如果能力提升依赖规模扩展,那么训练成本、推理成本、显存占用和部署复杂度也会同步上升。模型越大,每个 token 需要经过的参数越多;上下文越长,Attention 和 KV Cache 的压力越大;多模态输入又会引入更多 token 和更复杂的计算路径。
因此,在 Transformer 成为现代 LLM 的基础架构之后,新的问题开始出现:能不能让模型拥有更大的参数容量,但每次推理时只激活其中一部分计算?
围绕这个问题,大模型架构逐渐形成了两条重要路线:一条是经典的 Dense Transformer,每个 token 都经过完整模型参数;另一条是越来越重要的 MoE(Mixture of Experts,混合专家),模型拥有更大的总参数量,但每个 token 只路由到少数专家模块中计算。
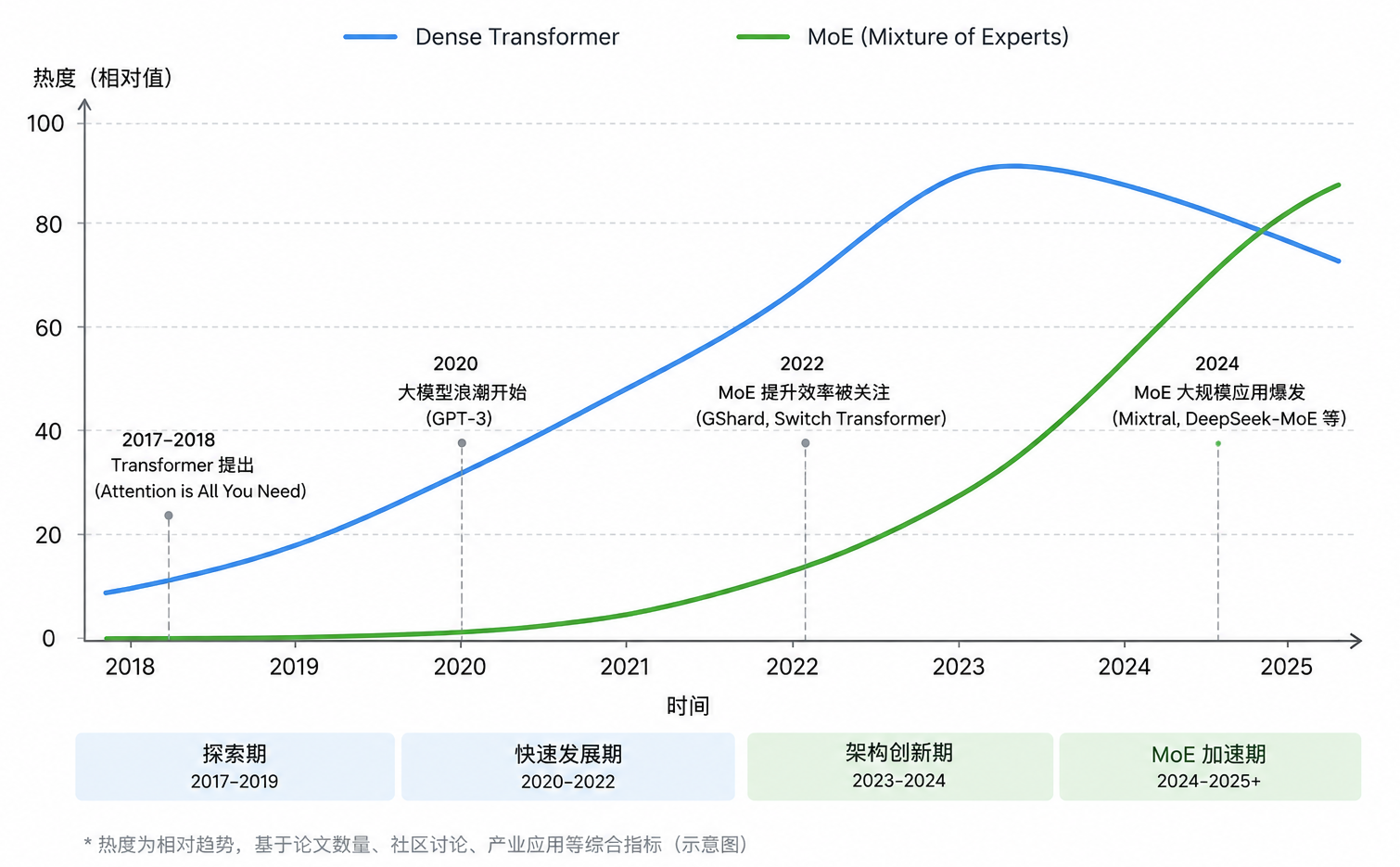
Dense Transformer 与 MoE 架构热度趋势(图片来自 GPT 5.5)
这一篇,我们重点看清楚:Dense Transformer 和 MoE 到底差在哪里,MoE 解决了什么问题,以及为什么它正在成为很多头部基模的重要架构选择。
Scaling Law 带来的挑战
Scaling Law 给大模型发展指明了一条非常清晰的路径:继续扩大模型、数据和计算,通常可以换来更强的能力。但当这条路径进入工程落地阶段,问题就不再只是“模型能不能继续变大”,而是:模型变大之后,每一次训练和推理到底要付出多少计算成本?
对于传统 Transformer 路线来说,这个问题尤其关键:模型容量扩大时,单 token 的计算成本通常也会同步上升。换句话说,Scaling Law 推动模型继续变大,但 Dense 架构会把“更大容量”和“更高计算成本”绑定在一起。
参数扩展如何放大计算成本
在 LLM 中,我们常说的“参数”,主要指模型训练过程中学出来的权重,而不是人工配置项。以 Transformer 为例,参数主要分布在几个位置:
| 参数位置 | 主要内容 | 作用 |
|---|---|---|
| Embedding | token embedding | 把 token 转成向量表示 |
| Attention | Q/K/V/O 投影矩阵 | 建模 token 之间的上下文关系 |
| FFN | Up / Gate / Down 等线性变换矩阵 | 对每个 token 的表示做非线性特征变换 |
| LayerNorm/RMSNorm | 归一化缩放参数,用于稳定训练 | 稳定训练过程中的数值分布 |
| Output Head | 输出词表投影矩阵 | 把 hidden state 转成下一个 token 的概率分布 |
一般来说模型变大,通常不是简单地“多存了一些数字”,而是意味着模型结构里的几个关键维度一起变大:
| 扩展方式 | 对计算量的影响 |
|---|---|
| 层数更多 | 每个 token 要经过更多 Transformer Block |
| FFN 中间维度更大 | FFN 参数量和计算量显著增加 |
| Attention head / hidden size 配套扩大 | 投影矩阵和注意力计算都会增加 |
| 上下文更长 | Attention 和 KV Cache 压力上升 |
尤其是 hidden size 的扩大,会显著放大计算量。因为 Transformer 里的核心计算大多是矩阵乘法,矩阵规模变大时,计算量不是线性增加,而是接近按平方级增长。
以 FFN 为例, hidden size 是 d,FFN 中间维度是 4d,其计算量如下所示:
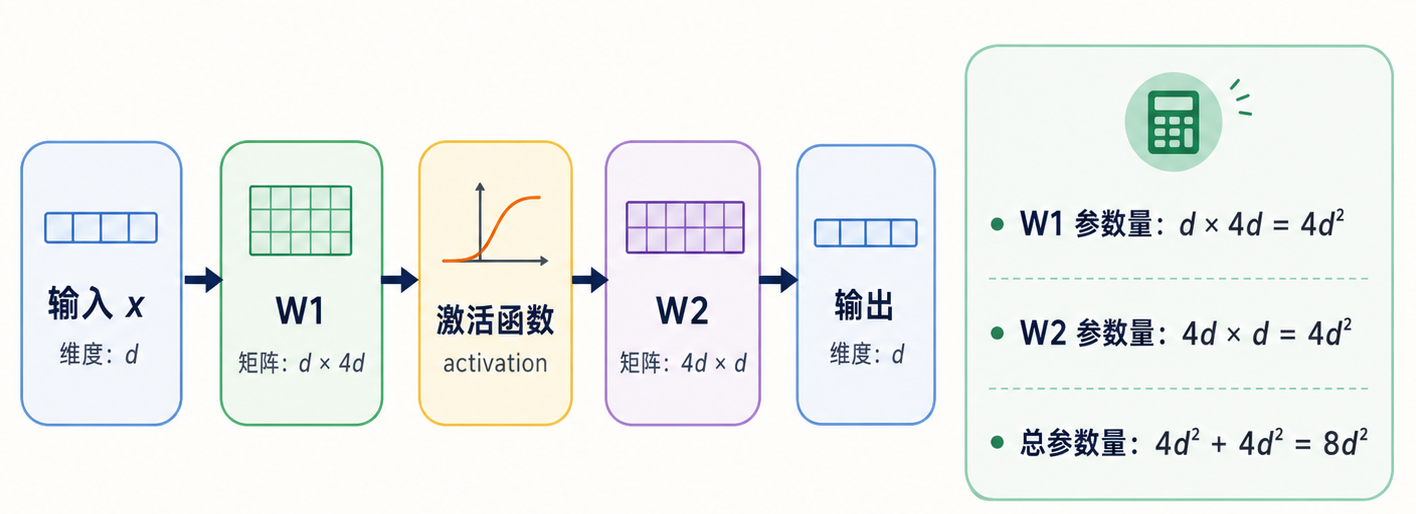
FNN 计算量
这意味着,当 d 变成原来的 2 倍时,FFN 的参数量和矩阵计算量大约会变成原来的 4 倍。
前馈网络(Feed-Forward Network, FFN)是在 Attention 完成上下文信息聚合之后,对每个 token 的 hidden state 进行进一步特征变换的模块。经典的 FFN 通常由两层线性变换和一个非线性激活函数组成:先把 hidden size 扩展到更高维度,再投影回原来的维度。由于这个“升维再降维”的过程会引入大规模矩阵计算,FFN 往往占据 Transformer Block 中很大一部分参数和计算量。在 Dense Transformer 中,每一层只有一个共享 FFN,所有 token 无论语义和任务类型如何,都会经过同一组 FFN 参数。
MoE 优化了哪里?
在 Transformer Block 中,Attention 和 FFN 都会消耗计算,但二者的角色不同。Attention 负责让 token 之间交换信息,而 FFN 更像是对每个 token 的表示做进一步加工。更重要的是,FFN 通常占据了大量参数和计算量,并且它是 逐 token 独立计算 的:一个 token 经过 FFN 时,不需要和其他 token 交互。
这就给架构优化留下了空间:如果 FFN 主要是对每个 token 独立做特征变换,那么能不能不要让所有 token 都经过同一个巨大的 FFN,而是为不同 token 选择不同的 FFN 子网络? 这就是 MoE 的核心思路。
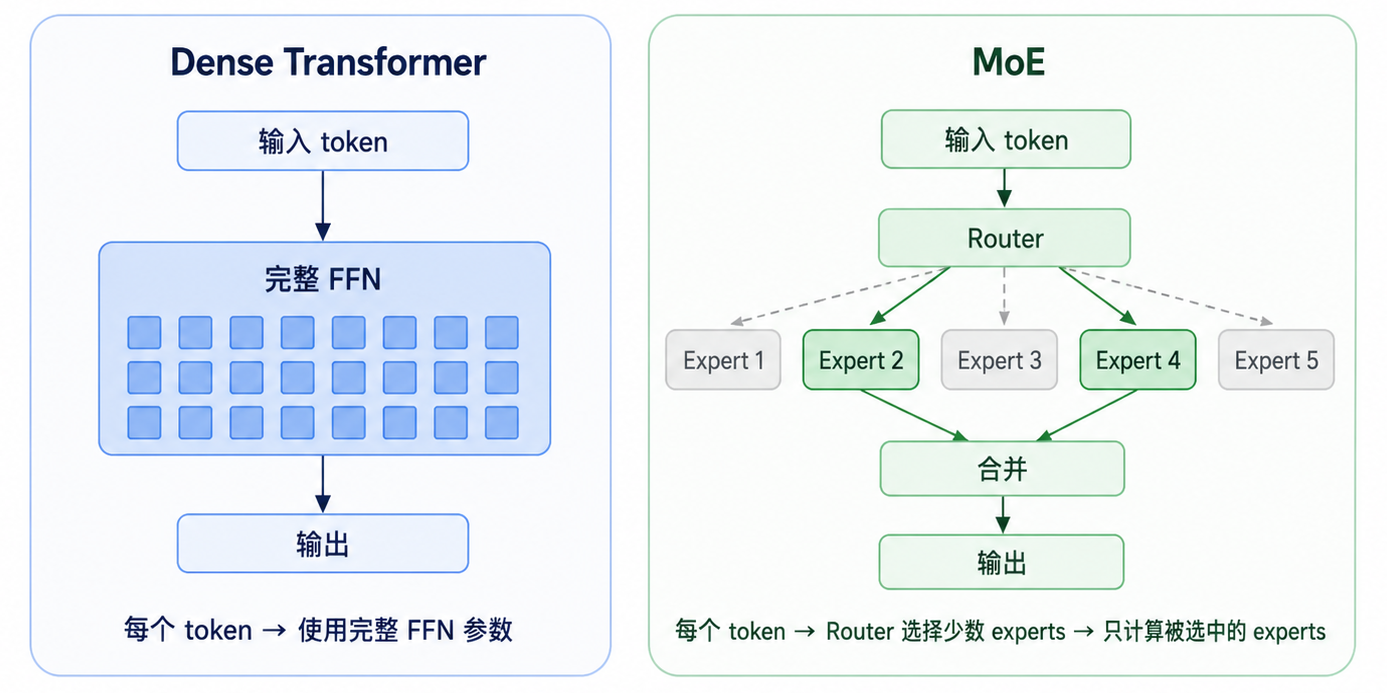
Dense Transformer VS MOE
MoE 不是把 Transformer 推翻,而是把原来的 Dense FFN 拆成多个 expert。这样的话,模型可以拥有很多 expert,也就是更大的 Total Parameters;但每个 token 只激活少数 expert,也就是更小的 Active Parameters。
| 架构 | 参数关系 | 含义 |
|---|---|---|
| Dense | Total Parameters ≈ Active Parameters | 与模型参数强绑定(主要指 Transformer Block 主体计算路径) |
| MoE | Total Parameters >> Active Parameters | 模型容量很大,但每次只用一部分 |
Scaling Law 继续推动模型变大,但 Dense 架构让成本同步上涨。MoE 则是在 Scaling Law 压力下,对“容量”和“计算成本”进行解耦的一种架构尝试。
Dense Transformer:经典路线
Dense Transformer 是现代 LLM 最经典的架构路线。它延续了《Attention Is All You Need》提出的 Transformer 思想:用一个完整、连续的神经网络来处理每个 token,让所有参数共同参与表示学习和上下文建模。
稠密计算:每个 token 激活全部参数
Dense Transformer 中的 Dense,指的是一种“稠密计算”方式:每个 token 在经过模型时,都会依次通过所有 Transformer Block,并使用每一层里的完整参数。
在这个范式中,Attention 负责让 token 与上下文交互,FFN 负责对每个 token 的 hidden state 做进一步非线性变换。对于 Dense Transformer 来说,无论输入的是哪个 token,它都会经过同样的 Attention、同样的 FFN、同样的层数。如下图所示:
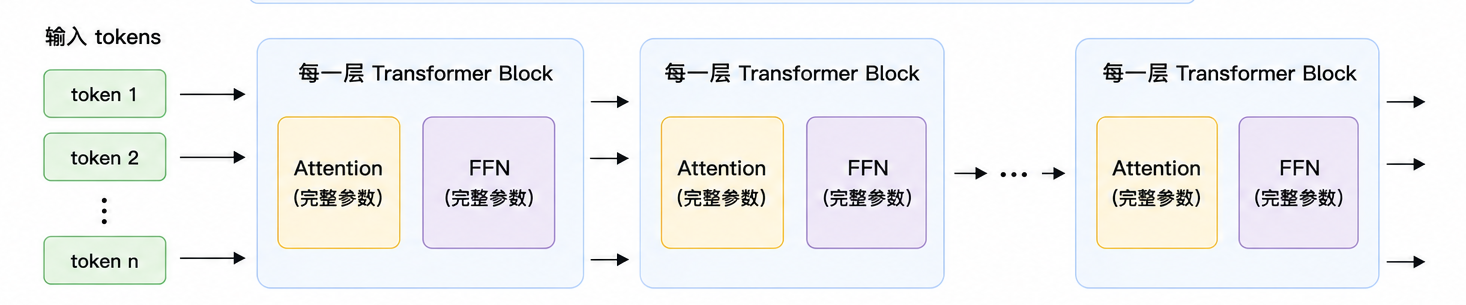
Dense Transformer 流程
因此 Dense 模型里的一个重要特点是:Total Parameters ≈ Active Parameters(主要指 Transformer Block 主体计算路径)
| 概念 | 含义 |
|---|---|
| Total Parameters | 模型拥有的总参数量 |
| Active Parameters | 每个 token 实际参与计算的参数量 |
在 Dense Transformer 中,模型有多少主体参数,每次前向计算基本就要使用多少主体参数。这种方式非常直接,也非常稳定:所有参数共同参与学习,模型内部没有路由选择,也没有专家分配,训练和推理路径都比较固定。
这也是 Dense Transformer 长期成为主流架构的原因:结构清晰、训练稳定、工程实现成熟。
规模化困境:能力变强,成本同步上升
Dense Transformer 的核心问题是:模型容量和计算成本强绑定。模型越大,能力通常越强,但训练、推理和部署成本也会同步上升,主要体现在几个方面:
- 训练 FLOPs 增加:参数量越大,前向传播和反向传播的矩阵计算越重,完整训练一次模型需要更多 GPU 时间;
- 显存占用增加:模型参数、梯度、优化器状态都需要占用显存,使用 Adam 这类优化器时,显存压力会进一步放大;
- 分布式训练更复杂:超大模型通常需要数据并行、张量并行、流水线并行等组合,GPU 间通信成本和调度复杂度上升;
- 推理成本和延迟变高: LLM 是一个 token 一个 token 生成的。即使有 KV Cache 减少重复计算,每生成一个新 token,模型仍然要经过所有层的 Attention 和 FFN,因此模型越大,在线服务的成本和延迟压力越明显;
- 服务成本上升:在线服务需要同时处理大量请求,大模型会带来更高 GPU 资源消耗和更低吞吐;
- 长上下文压力更明显:上下文越长,KV Cache 占用越大,显存和带宽压力越高;
- 多模态进一步放大成本:图像、音频、视频会引入更多 token 或特征表示,使计算路径更复杂。
可以用一句话总结:Dense Transformer 的问题不是不能继续变大,而是每一次变大都会让训练和推理成本一起变大。
典型 Dense 模型
Dense Transformer 的代表模型非常多。早期最有影响力的路线,是 OpenAI 的 GPT 系列,尤其是 GPT-3。
- OpenAI GPT-3:GPT-3 是 Dense Transformer 规模化路线中最具代表性的早期模型之一,采用 Decoder-only Transformer 架构,参数规模达到 175B。它的重要意义不只是“模型很大”,而是验证了大规模预训练带来的 few-shot learning 能力:模型不需要针对每个任务单独微调,只通过 prompt 中的少量示例,就能完成翻译、问答、文本生成等任务。GPT-3 让行业真正看到:Dense Transformer 在规模化之后,可以从“专用 NLP 模型”走向“通用语言模型”。
- Meta Llama 2:Llama 2 是 Meta 推出的开放权重 Dense 模型家族,参数规模覆盖 7B、13B、70B。它遵循标准的自回归 Dense Transformer 架构,同时使用 RoPE、SwiGLU、RMSNorm 等现代 LLM 常见设计。Llama 2 对行业的影响在于,它把高质量基模能力带入开放生态,让开发者可以基于开放权重进行本地部署、指令微调、领域适配和二次训练,极大推动了开源 LLM 生态的发展。
- Qwen Dense 系列:Qwen 系列中包含多种 Dense 基模,覆盖不同参数规模,并在中文、代码、数学、工具调用和多语言任务上持续增强。它的意义在于推动了中文和多语言 LLM 生态的发展,也让 Dense 基模在企业落地中有了更多选择:既可以选择较小模型做本地部署,也可以选择较大模型做复杂任务和行业应用。
Dense Transformer 是大模型规模化的经典起点,也是今天很多高质量基模仍然依赖的稳定底座。MoE 的出现,并不是否定 Dense,而是在更大规模和更高成本压力下,对 Dense 路线的一种架构扩展。
MoE:稀疏激活路线
如果说 Dense Transformer 的特点是“所有 token 都走同一条完整计算路径”,那么 MoE 的核心思路就是“让不同 token 走不同的专家路径”。MoE 在 Transformer Block 内部引入稀疏激活机制:模型可以拥有更多参数,但每个 token 只调用其中一部分。
核心架构:把一个 FFN 变成多个专家
MoE,全称是 Mixture of Experts,直译是“专家混合模型”。在 LLM 中,MoE 通常不是替换整个 Transformer,而是主要改造 Transformer Block 里的 FFN / MLP 层。Dense Transformer 中,每一层通常只有一个共享 FFN,所有 token 都经过同一组 FFN 参数。而 MoE 的做法是:把这个 FFN 替换成多个独立的 FFN 子网络,每个子网络就是一个 expert。如下图所示:
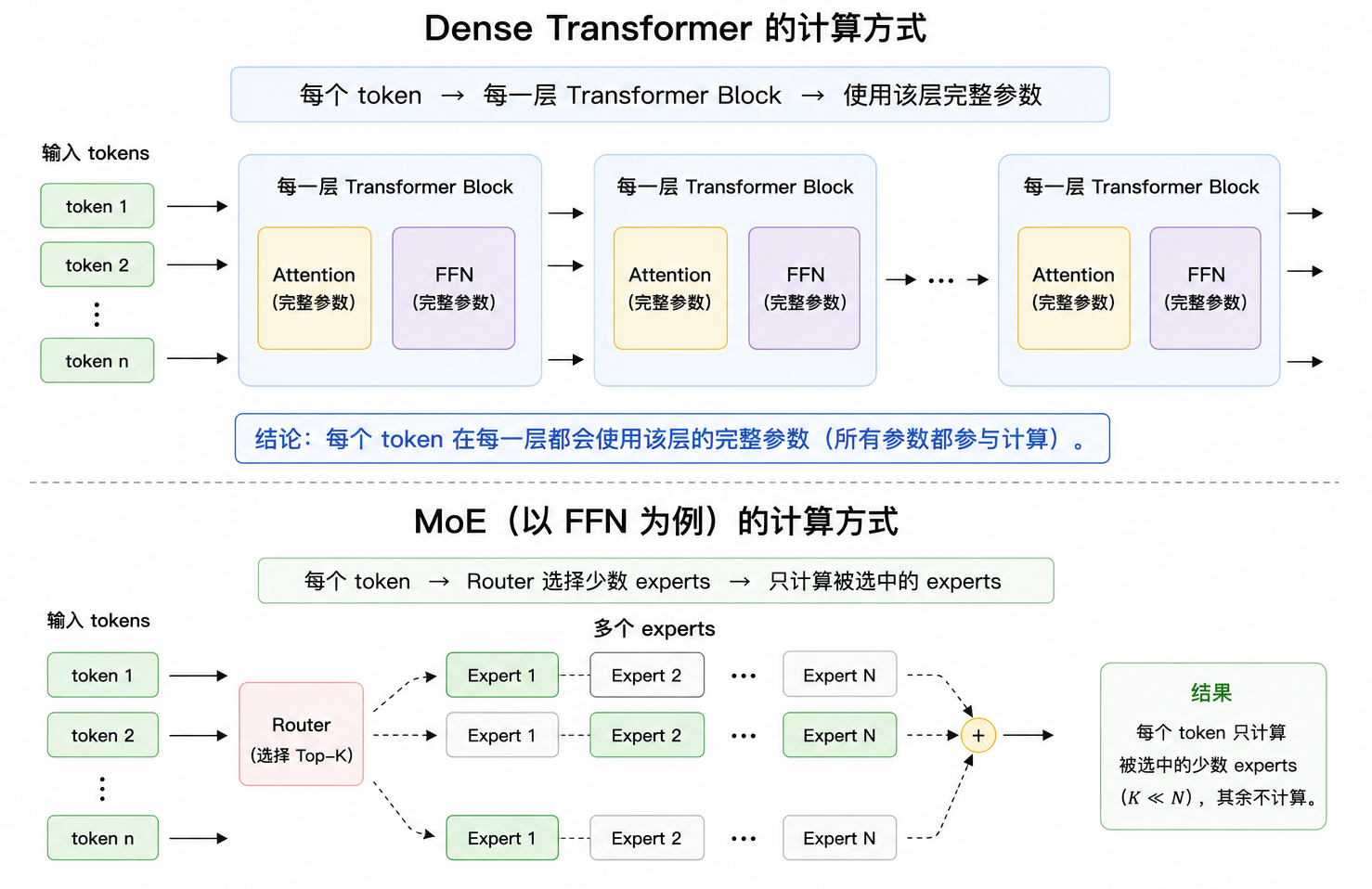
MoE 的核心架构设计可以概括为 5 点:
- Expert 化: 把原来的单个 FFN 拆成多个独立 FFN,每个 FFN 是一个 expert;
- Router 路由:为每个 token 计算 expert 分数,决定它应该交给哪些 expert;
- Top-k 激活:每个 token 只选择分数最高的 k 个 expert,而不是使用全部 expert;
- Gate 加权:被选中的 expert 输出会按 router 权重加权合并;
- 负载均衡:通过 aux loss、capacity factor 等机制,避免 token 都挤到少数 expert。
MoE 如何降低单 token 计算成本
MoE 解决的核心问题是:解耦模型总容量和单 token 计算成本。
- 在 Dense Transformer 中:
Total Parameters ≈ Active Parameters(主要指 Transformer Block 主体计算路径); - 在 MoE 中:
Total Parameters >> Active Parameters。
模型可以拥有大量 expert,形成很大的总参数量;但每个 token 只经过少数 expert,因此实际参与计算的参数量远小于总参数量。
举个例子:以 400B 参数模型为例,在主体计算路径上,一个 400B Dense 模型的单 token 计算会接近总参数规模;而 400B MoE 模型通常只激活少量 expert 参数,再加上共享 Attention、共享层等模块。
这样模型拥有更大的容量,但推理时的计算量接近一个小得多的 active model。所以 MoE 的低成本来自三个方面:
- 稀疏激活: 每个 token 只计算少数 expert,避免全量参数参与计算;
- 扩大容量:通过增加 expert 扩大总参数量,而不让单 token 计算同步增长;
- 专家分工:不同 expert 有机会学习不同模式,提高参数利用效率。
但 MoE 的代价也很明显:
- 显存仍然高:总参数仍然需要存储;
- 通信更复杂:token 需要被路由到不同 expert,分布式场景会产生 all-to-all 通信;
- 训练更难稳定:需要处理 expert collapse、负载不均、路由抖动等问题;
- 部署更复杂:推理延迟可能受路由分布和 expert 热点影响。
因此,MoE 的本质不是“免费变大”,而是:用更复杂的路由和系统调度,换取更高的模型容量与更好的性能成本比。
典型 MoE 模型
- Mixtral 8x7B:Mixtral 是 Mistral AI 推出的典型 Sparse MoE 模型。它在每一层设置 8 个 FFN experts,每个 token 选择其中 2 个 expert 参与计算。它的重要意义在于,把 MoE 从研究路线推进到高性能开放模型生态中,让业界直观看到:MoE 可以在较低 active parameters 下,获得接近甚至超过更大 Dense 模型的效果。
- DeepSeek-V3:DeepSeek-V3 是近年来 MoE 路线中非常有代表性的模型之一,总参数达到 671B,但每个 token 只激活约 37B 参数。它采用 DeepSeekMoE 架构,并结合 MLA、负载均衡优化、多 token prediction 等设计。它对行业的影响在于证明:MoE 不只是“参数更多”,还可以通过系统级训练和推理优化,把大规模模型的性能成本比做到非常激进。
- Qwen3 MoE:Qwen3 同时发布 Dense 与 MoE 模型,其中 MoE 模型包括 Qwen3-30B-A3B 和 Qwen3-235B-A22B。这里的
A3B、A22B指 activated parameters,也就是每个 token 实际激活的参数量。Qwen3 的意义在于,它把 Dense 和 MoE 放在同一代模型体系中,让开发者可以根据成本、延迟和能力需求选择不同架构路线。 - Llama 4:Llama 4 是 Meta Llama 系列首次明确转向 MoE 的重要节点。比如 Llama 4 Scout 是 17B active parameters、16 experts;Llama 4 Maverick 是 17B active parameters、128 experts、400B total parameters。它的行业意义在于,Meta 这样的头部开源生态也开始把 MoE 作为下一代基模的重要架构选择,尤其结合多模态和长上下文能力。
- Gemini 1.5:Google 在 Gemini 1.5 中明确提到使用 MoE 架构,以提升训练和服务效率,并支持更长上下文能力。它说明 MoE 不只用于开源模型,也已经成为闭源头部模型在长上下文、多模态和高效推理方向上的重要架构选择。
MoE 的挑战:稀疏激活背后的训练与系统复杂度
MoE 的核心价值,是用稀疏激活降低单 token 的计算成本。但它并不是“免费变大”。相比 Dense Transformer,MoE 把问题从单纯的矩阵计算,转移到了 路由稳定性、专家负载、显存管理、跨卡通信和推理调度 上。
路由机制:token 应该交给哪个 expert?
MoE 的关键是 Router。它会根据 token 的 hidden state 计算 expert 分数,并选择 Top-k 个 expert:selected_experts = TopK(router(x))。
这带来的问题是:路由选择是动态的,不同 token 会走不同 expert。训练早期 Router 还不稳定,可能导致 token 分配剧烈波动,进而影响模型收敛。
| 挑战 | 说明 | 常见方案 |
|---|---|---|
| 路由不稳定 | token 在不同 expert 之间频繁跳动 | router 正则、noisy routing |
| 专家选择过早固化 | Router 很早偏向少数 expert | 加噪声、温度控制、负载均衡约束 |
| 梯度稀疏 | 只有被选中的 expert 得到更新 | top-2 routing、shared expert |
训练稳定性:专家塌缩与负载不均
MoE 最典型的问题是 expert collapse:大量 token 被路由到少数 expert,其他 expert 几乎没有训练机会。这会造成两个后果:一是热门 expert 过载,训练效率下降;二是冷门 expert 学不到东西,模型容量被浪费。
| 问题 | 影响 | 常见方案 |
|---|---|---|
| Expert Collapse | 少数 expert 被过度使用 | auxiliary load balancing loss |
| 负载不均 | GPU 利用率不均,训练吞吐下降 | capacity factor、expert bias |
| Token Dropping | expert 超载时部分 token 被丢弃 | dropless MoE、block-sparse kernel |
| 主任务受干扰 | 负载均衡 loss 可能影响语言建模目标 | auxiliary-loss-free balancing |
MoE 为了解决专家负载不均,早期常见做法是在主训练目标之外加入 auxiliary load balancing loss,用一个额外的损失项鼓励 token 更均匀地分配到不同 expert。这样可以缓解 expert collapse,但也会带来一个副作用:辅助损失可能和语言建模主目标产生拉扯,影响模型最终效果。
因此,后来一些 MoE 模型开始探索更弱侵入的负载均衡方法。例如 DeepSeek-V3 使用了 auxiliary-loss-free load balancing,不再简单依赖额外的辅助损失来约束路由,而是通过更细的路由调节机制,让 expert 使用保持均衡,同时尽量减少对主任务训练目标的干扰。
内存压力:Active 少,不代表 Total 小
这是 MoE 很容易被误解的一点。MoE 的优势是:每个 token 只激活少量 expert。
但它的问题是:所有 expert 参数仍然需要存储。
也就是说,MoE 用稀疏激活降低了单 token 的计算 FLOPs,但它并没有消除大模型的存储成本。模型总参数、expert 权重、优化器状态、路由缓存和跨卡通信 buffer,都会带来额外的内存和系统复杂度。
| 问题 | 常见方案 | 作用 |
|---|---|---|
| 总参数太大 | Expert Parallelism / Expert Sharding | 把不同 expert 分布到不同 GPU,避免单卡存完整模型 |
| 训练显存高 | ZeRO / FSDP | 切分参数、梯度和优化器状态,降低单卡显存压力 |
| 激活值占用大 | Activation Checkpointing | 反向传播时重新计算部分激活,换显存为计算 |
| 参数和计算精度高 | BF16 / FP8 / Quantization | 降低权重、激活和计算的显存占用 |
| 路由通信开销大 | All-to-All Overlap / Dispatch 优化 | 将 token 分发通信和 expert 计算尽量重叠 |
| expert 热点 | Expert Replication / Load Balancing | 对热门 expert 做副本或调节路由,避免单点瓶颈 |
通信与推理:稀疏计算带来动态调度
MoE 在分布式训练和推理时,需要把 token 分发到不同 expert 所在的 GPU 上:
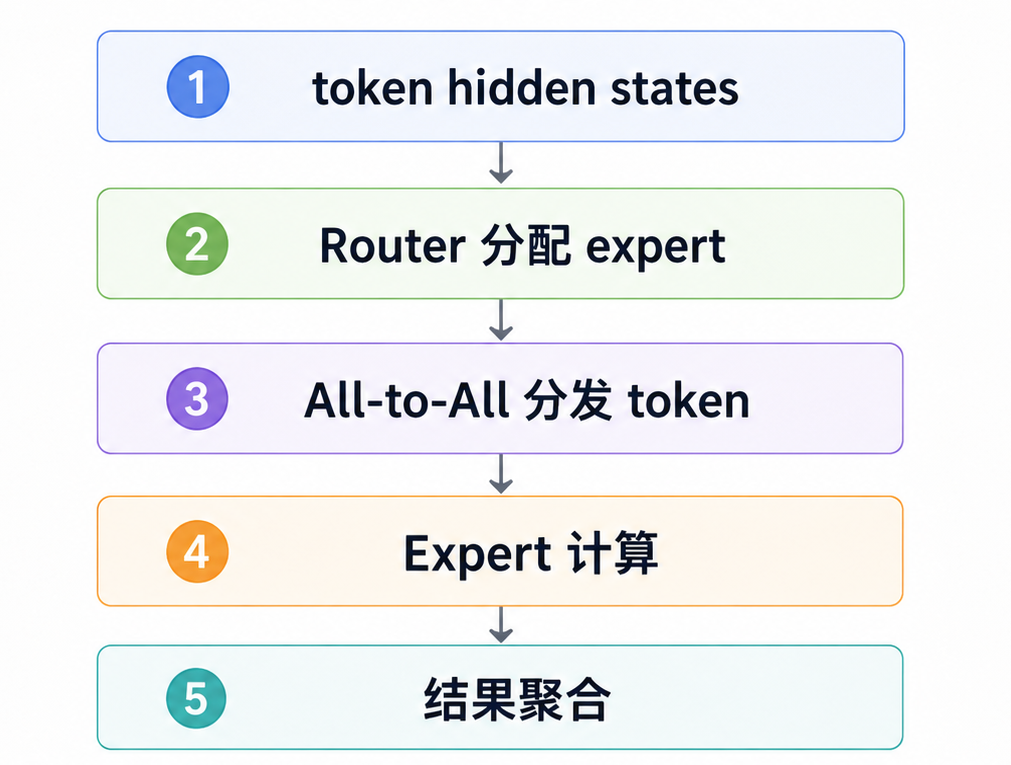
MoE 中 token 计算
这会引入明显的通信和调度复杂度:
| 挑战 | 说明 | 常见方案 |
|---|---|---|
| All-to-All 通信 | token 需要跨 GPU 分发 | 通信计算重叠 |
| 动态 shape | 每个 expert 接收 token 数不同 | grouped GEMM、block-sparse kernel |
| 热点 expert | 某些 expert 被频繁调用 | expert replication、负载均衡 |
| 延迟抖动 | 不同请求路由不同,耗时不稳定 | router-aware batching |
| 小 batch 低效 | 在线推理 batch 小,expert 利用率低 | continuous batching、缓存优化 |
因此,MoE 的推理优化不是只看 active parameters,还要看系统能不能高效完成 token dispatch、expert 计算和结果聚合。
小结:MoE 是架构问题,也是系统问题
简单总结一下:MoE 用稀疏激活降低了单 token 计算成本,但代价是引入了更复杂的训练稳定性、内存管理和分布式调度问题。它不是简单的模型结构优化,而是模型架构和系统工程共同演进的结果。
| 挑战 | 本质 | 技术方案 |
|---|---|---|
| 路由稳定性 | token 如何稳定选择 expert | noisy routing、router z-loss、top-k |
| 训练稳定性 | expert 是否都能有效学习 | aux loss、expert bias、shared expert |
| 内存压力 | total parameters 很大 | expert parallel、参数切分、量化 |
| 通信开销 | token 需要跨卡分发 | all-to-all overlap、grouped GEMM |
| 推理复杂度 | 动态路径导致延迟不稳定 | expert placement、hot expert replication |
未来趋势:从单一架构到混合架构
Dense Transformer 和 MoE 并不是大模型架构演进的终点。Dense 更稳定,MoE 更适合扩展容量,但两者都有各自的成本和边界。未来的大模型架构,大概率会走向更灵活的混合形态。
| 方向 | 核心思路 |
|---|---|
| Dense + MoE 混合 | 部分层保持 Dense,保证训练稳定和通用能力;部分层使用 MoE,提升容量和效率 |
| 更细粒度专家 | expert 数量更多、粒度更小,让路由选择更灵活,专家分工更细 |
| 动态计算路径 | 根据 token 类型、任务难度或推理阶段,动态决定激活多少计算 |
| 多模态 MoE | 文本、图像、语音、视频可能路由到不同 expert,提高多模态处理效率 |
| 推理模型结合 MoE | 简单问题走轻量路径,复杂推理激活更多专家或更长计算过程 |
从 Dense 到 MoE,本质上是大模型从“全量计算”走向“按需计算”的开始。Dense Transformer 代表最稳定、最成熟的规模化路线;MoE 则代表在成本压力下,通过稀疏激活扩展模型容量的方向。
未来的大模型不会只有一种架构答案,而是在能力、成本、延迟、稳定性和部署复杂度之间不断做权衡。理解 Dense 与 MoE 的差异,也就理解了现代基模架构演进中最重要的一条主线。
