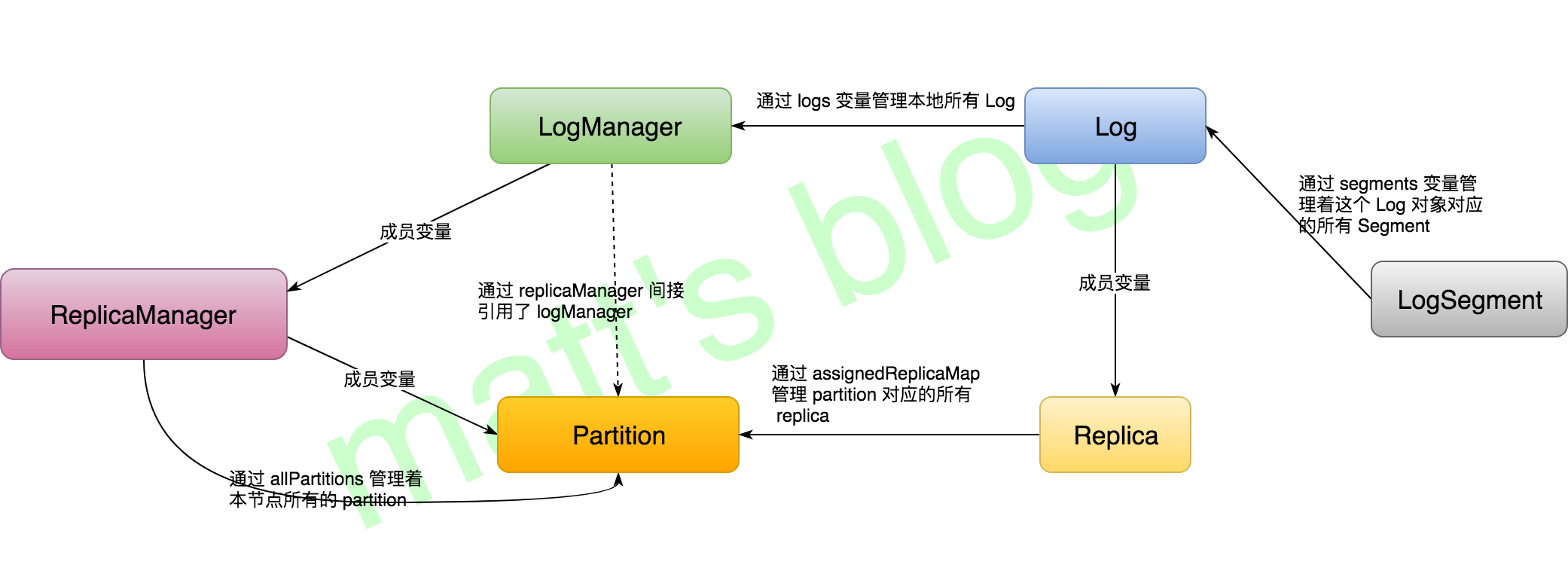
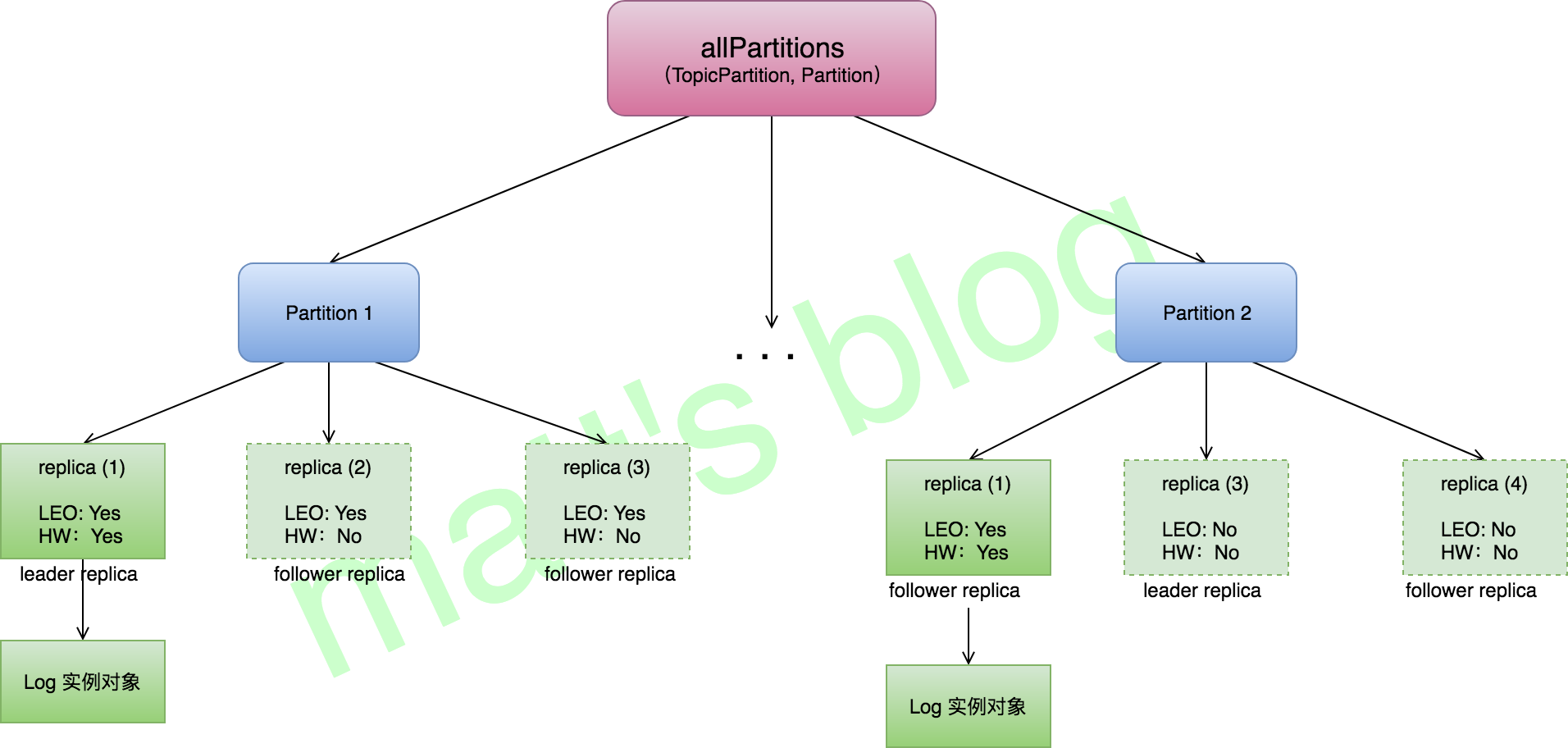
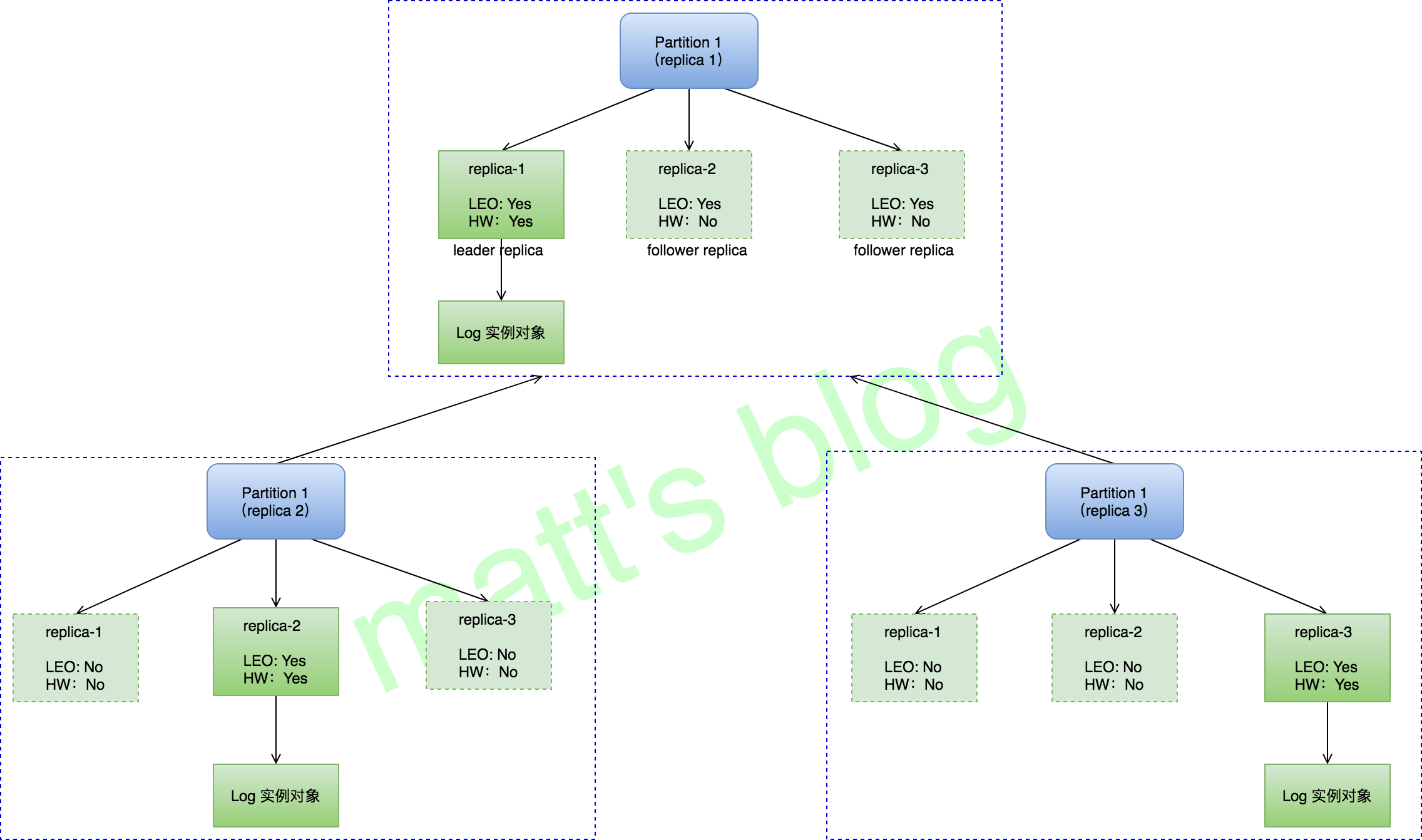
/* start replica manager */ //note: 启动 replica manager replicaManager = newReplicaManager(config, metrics, time, zkUtils, kafkaScheduler, logManager, isShuttingDown, quotaManagers.follower) replicaManager.startup() } catch { case e: Throwable => fatal("Fatal error during KafkaServer startup. Prepare to shutdown", e) isStartingUp.set(false) shutdown() throw e } }
startup
ReplicaManager startup() 方法的实现如下:
1 2 3 4 5 6 7 8
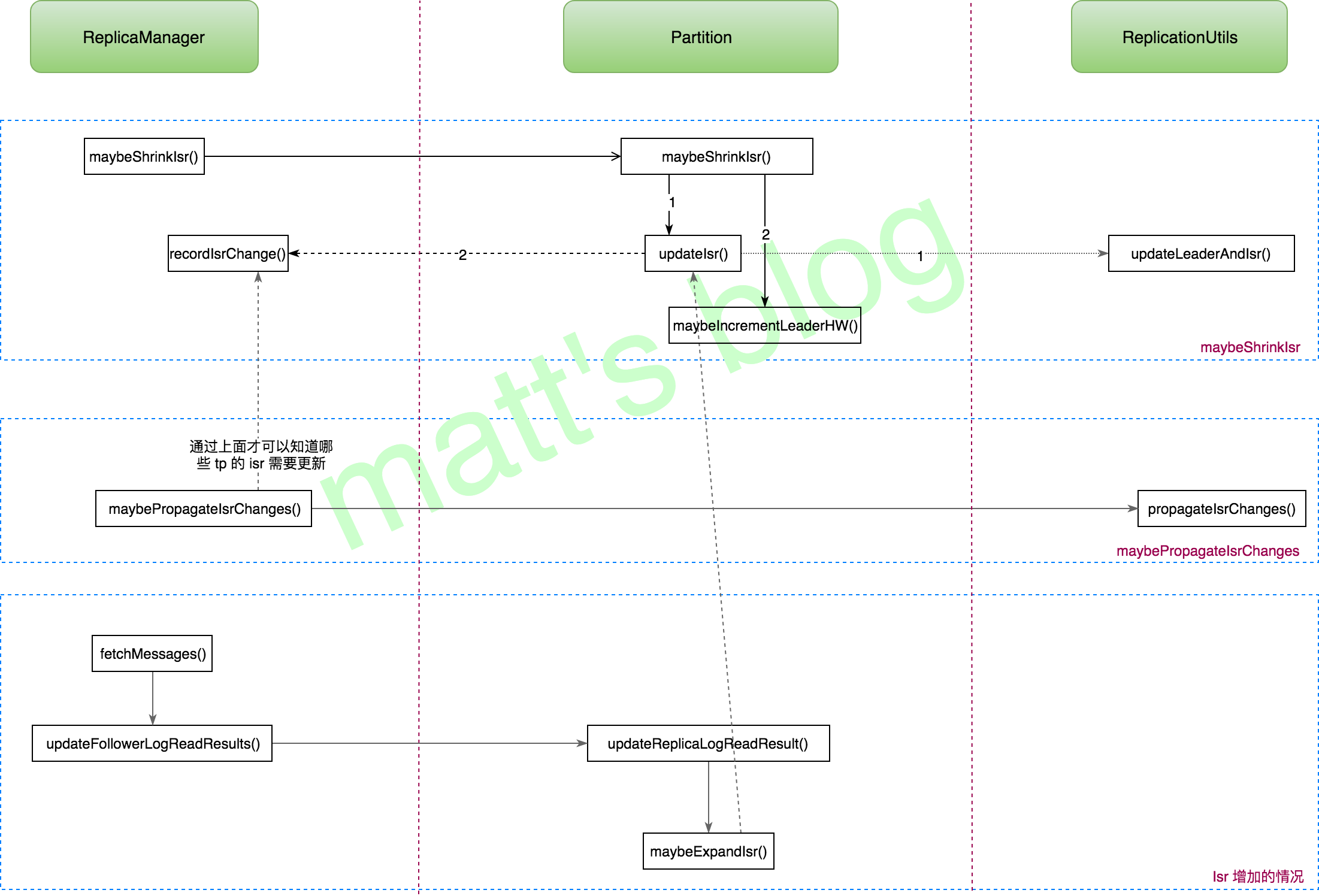
defstartup() { // start ISR expiration thread // A follower can lag behind leader for up to config.replicaLagTimeMaxMs x 1.5 before it is removed from ISR //note: 周期性检查 isr 是否有 replica 过期需要从 isr 中移除 scheduler.schedule("isr-expiration", maybeShrinkIsr, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS) //note: 周期性检查是不是有 topic-partition 的 isr 需要变动,如果需要,就更新到 zk 上,来触发 controller scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges, period = 2500L, unit = TimeUnit.MILLISECONDS) }
//note: 遍历所有的 partition 对象,检查其 isr 是否需要抖动 privatedefmaybeShrinkIsr(): Unit = { trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR") allPartitions.values.foreach(partition => partition.maybeShrinkIsr(config.replicaLagTimeMaxMs)) }
//note: 检查这个 isr 中的每个 replcia defmaybeShrinkIsr(replicaMaxLagTimeMs: Long) { val leaderHWIncremented = inWriteLock(leaderIsrUpdateLock) { leaderReplicaIfLocal match { //note: 只有本地副本是 leader, 才会做这个操作 caseSome(leaderReplica) => //note: 检查当前 isr 的副本是否需要从 isr 中移除 val outOfSyncReplicas = getOutOfSyncReplicas(leaderReplica, replicaMaxLagTimeMs) if(outOfSyncReplicas.nonEmpty) { val newInSyncReplicas = inSyncReplicas -- outOfSyncReplicas //note: new isr assert(newInSyncReplicas.nonEmpty) info("Shrinking ISR for partition [%s,%d] from %s to %s".format(topic, partitionId, inSyncReplicas.map(_.brokerId).mkString(","), newInSyncReplicas.map(_.brokerId).mkString(","))) // update ISR in zk and in cache updateIsr(newInSyncReplicas) //note: 更新 isr 到 zk // we may need to increment high watermark since ISR could be down to 1
val laggingReplicas = candidateReplicas.filter(r => (time.milliseconds - r.lastCaughtUpTimeMs) > maxLagMs) if (laggingReplicas.nonEmpty) debug("Lagging replicas for partition %s are %s".format(topicPartition, laggingReplicas.map(_.brokerId).mkString(",")))
// for producer requests with ack > 1, we need to check // if they can be unblocked after some follower's log end offsets have moved tryCompleteDelayedProduce(newTopicPartitionOperationKey(topicPartition)) caseNone => warn("While recording the replica LEO, the partition %s hasn't been created.".format(topicPartition)) } } }
这个方法的作用就是找到本节点这个 Partition 对象,然后调用其 updateReplicaLogReadResult() 方法更新副本的 LEO 信息和拉取时间信息。
//note: 更新这个 partition replica 的 the end offset defupdateReplicaLogReadResult(replicaId: Int, logReadResult: LogReadResult) { getReplica(replicaId) match { caseSome(replica) => //note: 更新副本的信息 replica.updateLogReadResult(logReadResult) // check if we need to expand ISR to include this replica // if it is not in the ISR yet //note: 如果该副本不在 isr 中,检查是否需要进行更新 maybeExpandIsr(replicaId, logReadResult)
debug("Recorded replica %d log end offset (LEO) position %d for partition %s." .format(replicaId, logReadResult.info.fetchOffsetMetadata.messageOffset, topicPartition)) caseNone => thrownewNotAssignedReplicaException(("Leader %d failed to record follower %d's position %d since the replica" + " is not recognized to be one of the assigned replicas %s for partition %s.") .format(localBrokerId, replicaId, logReadResult.info.fetchOffsetMetadata.messageOffset, assignedReplicas.map(_.brokerId).mkString(","), topicPartition)) } }
//note: 检查当前 Partition 是否需要扩充 ISR, 副本的 LEO 大于等于 hw 的副本将会被添加到 isr 中 defmaybeExpandIsr(replicaId: Int, logReadResult: LogReadResult) { val leaderHWIncremented = inWriteLock(leaderIsrUpdateLock) { // check if this replica needs to be added to the ISR leaderReplicaIfLocal match { caseSome(leaderReplica) => val replica = getReplica(replicaId).get val leaderHW = leaderReplica.highWatermark if(!inSyncReplicas.contains(replica) && assignedReplicas.map(_.brokerId).contains(replicaId) && replica.logEndOffset.offsetDiff(leaderHW) >= 0) { //note: replica LEO 大于 HW 的情况下,加入 isr 列表 val newInSyncReplicas = inSyncReplicas + replica info(s"Expanding ISR for partition $topicPartition from ${inSyncReplicas.map(_.brokerId).mkString(",")} " + s"to ${newInSyncReplicas.map(_.brokerId).mkString(",")}") // update ISR in ZK and cache updateIsr(newInSyncReplicas) //note: 更新到 zk replicaManager.isrExpandRate.mark() }
// check if the HW of the partition can now be incremented // since the replica may already be in the ISR and its LEO has just incremented //note: 检查 HW 是否需要更新 maybeIncrementLeaderHW(leaderReplica, logReadResult.fetchTimeMs)
caseNone => false// nothing to do if no longer leader } }
// some delayed operations may be unblocked after HW changed if (leaderHWIncremented) tryCompleteDelayedRequests() }
//note: 更新本地的 meta,并返回要删除的 topic-partition defupdateCache(correlationId: Int, updateMetadataRequest: UpdateMetadataRequest): Seq[TopicPartition] = { inWriteLock(partitionMetadataLock) { controllerId = updateMetadataRequest.controllerId match { case id if id < 0 => None case id => Some(id) } //note: 清空 aliveNodes 和 aliveBrokers 记录,并更新成最新的记录 aliveNodes.clear() aliveBrokers.clear() updateMetadataRequest.liveBrokers.asScala.foreach { broker => // `aliveNodes` is a hot path for metadata requests for large clusters, so we use java.util.HashMap which // is a bit faster than scala.collection.mutable.HashMap. When we drop support for Scala 2.10, we could // move to `AnyRefMap`, which has comparable performance. val nodes = new java.util.HashMap[ListenerName, Node] val endPoints = new mutable.ArrayBuffer[EndPoint] broker.endPoints.asScala.foreach { ep => endPoints += EndPoint(ep.host, ep.port, ep.listenerName, ep.securityProtocol) nodes.put(ep.listenerName, newNode(broker.id, ep.host, ep.port)) } aliveBrokers(broker.id) = Broker(broker.id, endPoints, Option(broker.rack)) aliveNodes(broker.id) = nodes.asScala }
val deletedPartitions = new mutable.ArrayBuffer[TopicPartition] //note: updateMetadataRequest.partitionStates.asScala.foreach { case (tp, info) => val controllerId = updateMetadataRequest.controllerId val controllerEpoch = updateMetadataRequest.controllerEpoch if (info.leader == LeaderAndIsr.LeaderDuringDelete) { //note: partition 被标记为了删除 removePartitionInfo(tp.topic, tp.partition) //note: 从 cache 中删除 stateChangeLogger.trace(s"Broker $brokerId deleted partition $tp from metadata cache in response to UpdateMetadata " + s"request sent by controller $controllerId epoch $controllerEpoch with correlation id $correlationId") deletedPartitions += tp } else {//note: 更新 val partitionInfo = partitionStateToPartitionStateInfo(info) addOrUpdatePartitionInfo(tp.topic, tp.partition, partitionInfo) //note: 更新 topic-partition meta stateChangeLogger.trace(s"Broker $brokerId cached leader info $partitionInfo for partition $tp in response to " + s"UpdateMetadata request sent by controller $controllerId epoch $controllerEpoch with correlation id $correlationId") } } deletedPartitions } }