Flink 如何生成 ExecutionGraph
本篇文章是 Flink 系列 的第四篇,紧接着前面两篇文章,在前两篇文章中介绍的 StreamGraph 和 JobGraph 都是在 client 端生成的,本文将会讲述 JobGraph 是如何转换成 ExecutionGraph 的。当 JobGraph 从 client 端提交到 JobManager 端后,JobManager 会根据 JobGraph 生成对应的 ExecutionGraph,ExecutionGraph 是 Flink 作业调度时使用到的核心数据结构,它包含每一个并行的 task、每一个 intermediate stream 以及它们之间的关系,本篇将会详细分析一下 JobGraph 转换为 ExecutionGraph 的流程。
Create ExecutionGraph 的整体流程
当用户向一个 Flink 集群提交一个作业后,JobManager 会接收到 Client 相应的请求,JobManager 会先做一些初始化相关的操作(也就是 JobGraph 到 ExecutionGraph 的转化),当这个转换完成后,才会根据 ExecutionGraph 真正在分布式环境中调度当前这个作业,而 JobManager 端处理的整体流程如下:
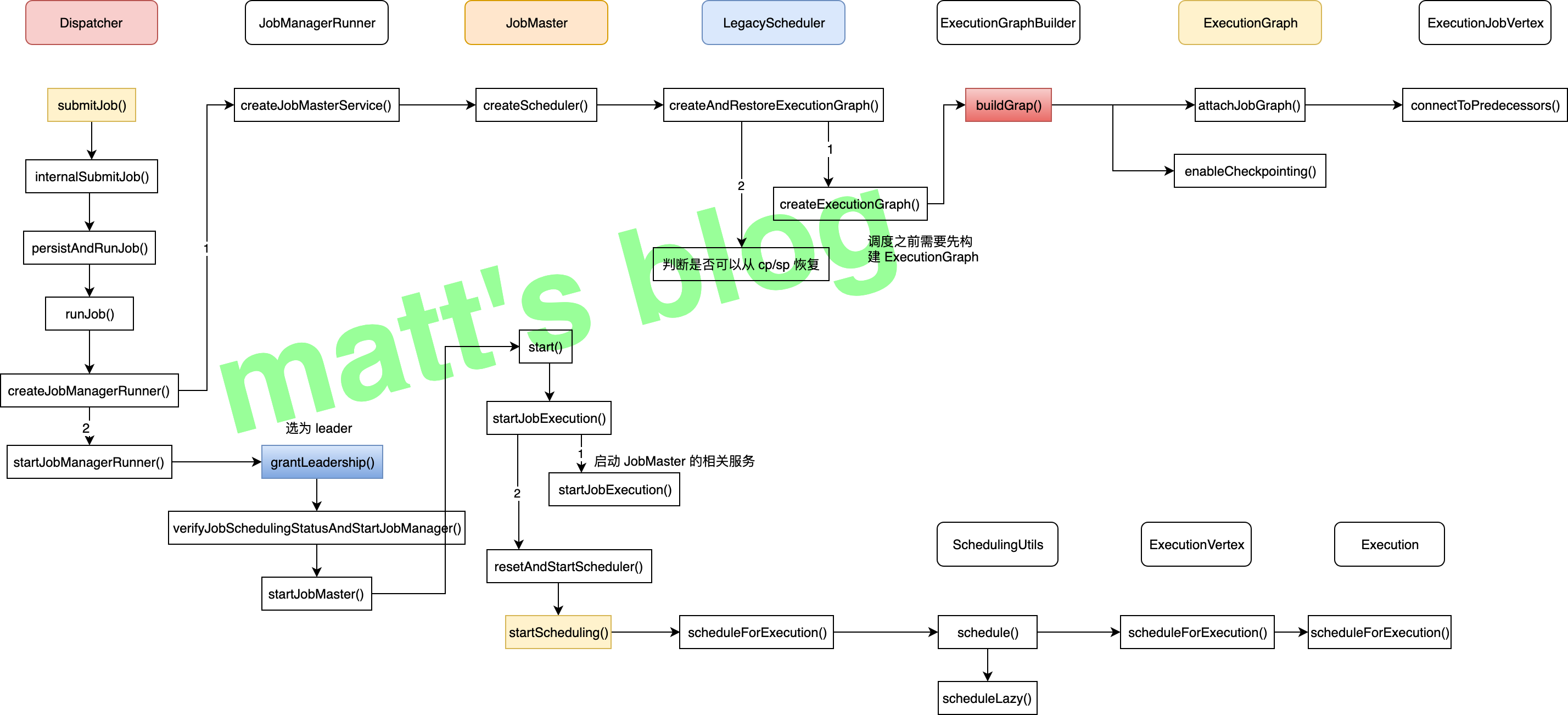
上图是一个作业提交后,在 JobManager 端的处理流程,本篇文章主要聚焦于 ExecutionGraph 的生成过程,也就是图中的红色节点,即 ExecutionGraphBuilder 的 buildGraph() 方法,这个方法就是根据 JobGraph 及相关的配置来创建 ExecutionGraph 对象的核心方法。
具体实现逻辑
这里将会详细来讲述 ExecutionGraphBuilder buildGraph() 方法的详细实现。
基本概念
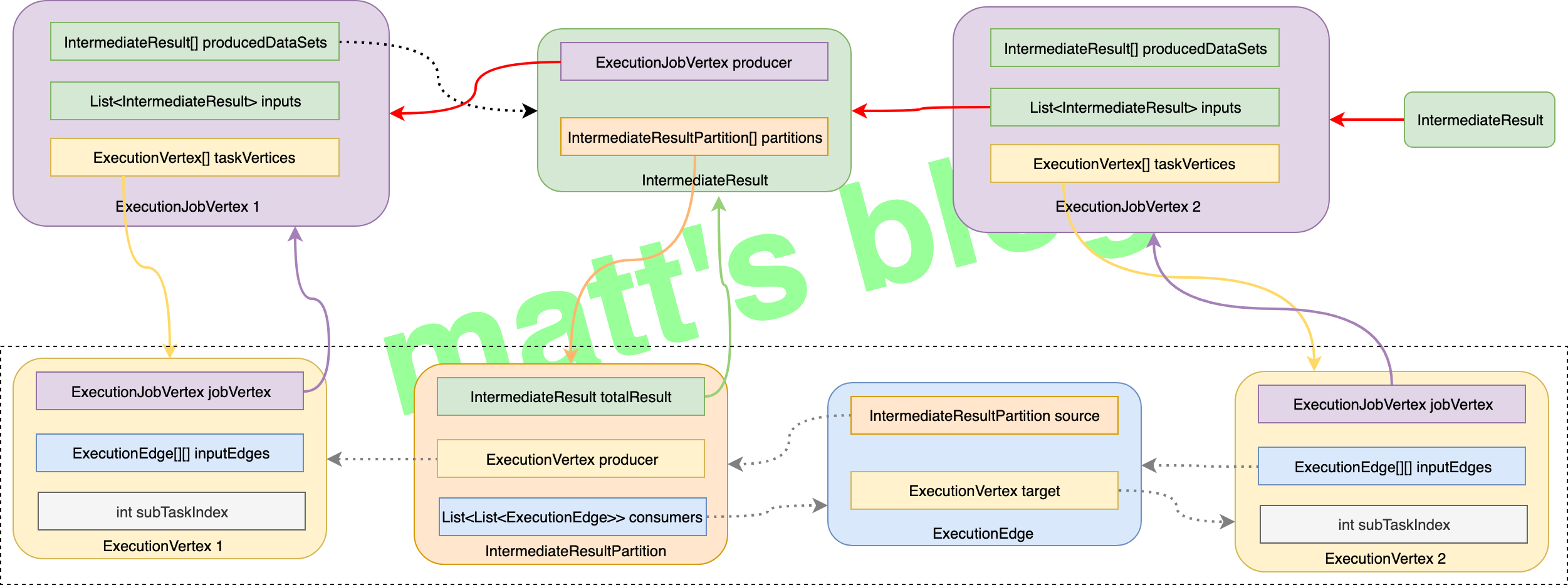
ExecutionGraph 引入了几个基本概念,先简单介绍一下这些概念,对于理解 ExecutionGraph 有较大帮助:
- ExecutionJobVertex: 在 ExecutionGraph 中,节点对应的是 ExecutionJobVertex,它是与 JobGraph 中的 JobVertex 一一对应,实际上每个 ExexutionJobVertex 也都是由一个 JobVertex 生成;
- ExecutionVertex: 在 ExecutionJobVertex 中有一个
taskVertices变量,它是 ExecutionVertex 类型的数组,数组的大小就是这个 JobVertex 的并发度,在创建 ExecutionJobVertex 对象时,会创建相同并发度梳理的 ExecutionVertex 对象,在真正调度时,一个 ExecutionVertex 实际就是一个 task,它是 ExecutionJobVertex 并行执行的一个子任务; - Execution: Execution 是对 ExecutionVertex 的一次执行,通过 ExecutionAttemptId 来唯一标识,一个 ExecutionVertex 在某些情况下可能会执行多次,比如遇到失败的情况或者该 task 的数据需要重新计算时;
- IntermediateResult: 在 JobGraph 中用 IntermediateDataSet 表示 JobVertex 的输出 stream,一个 JobGraph 可能会有多个输出 stream,在 ExecutionGraph 中,与之对应的就是 IntermediateResult 对象;
- IntermediateResultPartition: 由于 ExecutionJobVertex 可能有多个并行的子任务,所以每个 IntermediateResult 可能就有多个生产者,每个生产者的在相应的 IntermediateResult 上的输出对应一个 IntermediateResultPartition 对象,IntermediateResultPartition 表示的是 ExecutionVertex 的一个输出分区;
- ExecutionEdge: ExecutionEdge 表示 ExecutionVertex 的输入,通过 ExecutionEdge 将 ExecutionVertex 和 IntermediateResultPartition 连接起来,进而在 ExecutionVertex 和 IntermediateResultPartition 之间建立联系。
从这些基本概念中,也可以看出以下几点:
- 由于每个 JobVertex 可能有多个 IntermediateDataSet,所以每个 ExecutionJobVertex 可能有多个 IntermediateResult,因此,每个 ExecutionVertex 也可能会包含多个 IntermediateResultPartition;
- ExecutionEdge 这里主要的作用是把
ExecutionVertex和IntermediateResultPartition连接起来,表示它们之间的连接关系。
这里先放一张 ExecutionGraph 粗略图,它展示上面这些类之间的关系:
实现细节
ExecutionGraph 的生成是在 ExecutionGraphBuilder 的 buildGraph() 方法中实现的:
1 | // ExecutionGraphBuilder.java |
在这个方法里,会先创建一个 ExecutionGraph 对象,然后对 JobGraph 中的 JobVertex 列表做一下排序(先把有 source 节点的 JobVertex 放在最前面,然后开始遍历,只有当前 JobVertex 的前置节点都已经添加到集合后才能把当前 JobVertex 节点添加到集合中),最后通过 attachJobGraph() 方法生成具体的 Execution Plan。
ExecutionGraph 的 attachJobGraph() 方法会将这个作业的 ExecutionGraph 构建出来,它会根据 JobGraph 创建相应的 ExecutionJobVertex、IntermediateResult、ExecutionVertex、ExecutionEdge、IntermediateResultPartition,其详细的执行逻辑如下图所示:
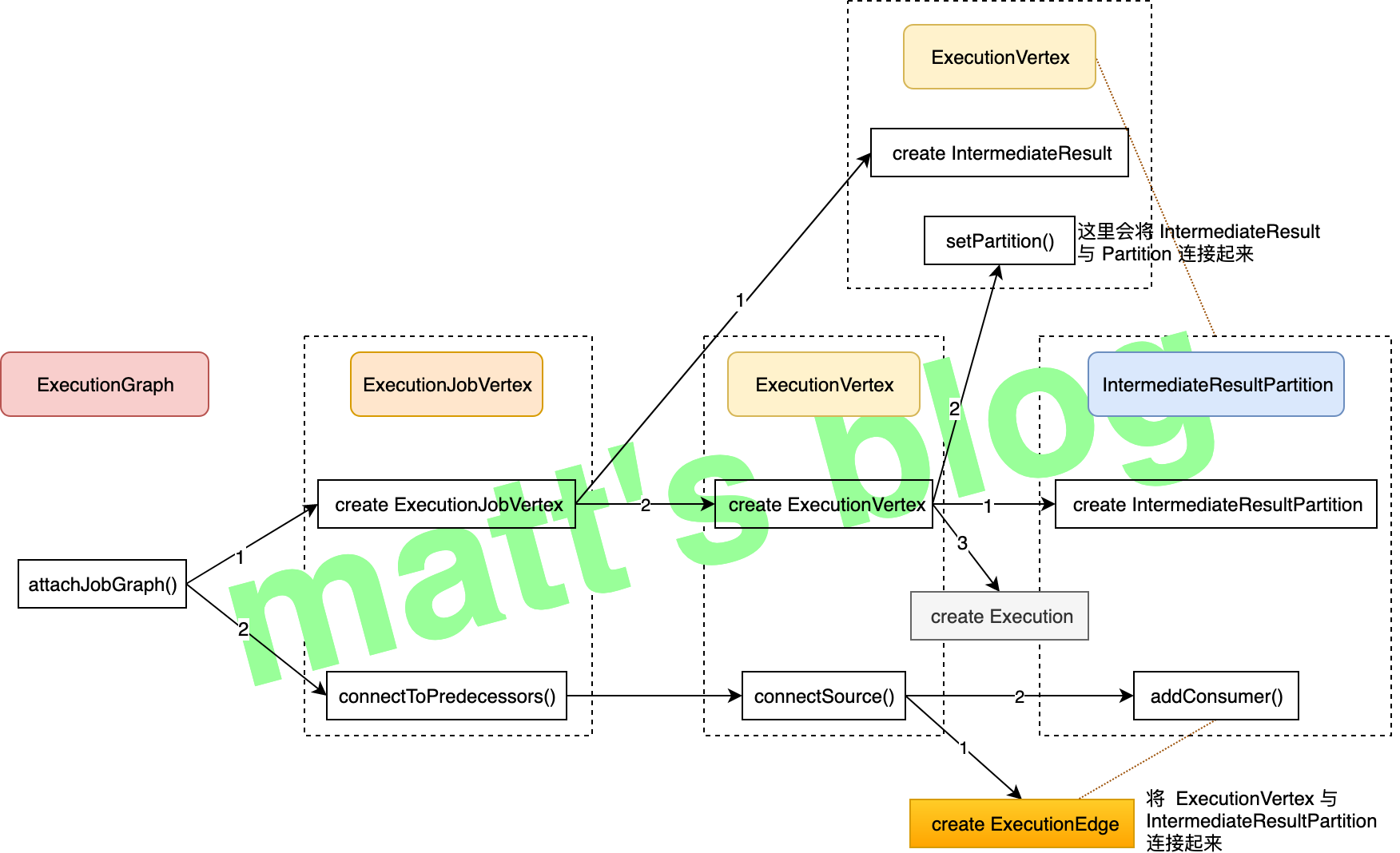
上面的图还是有些凌乱,要配合本文的第二张图来看,接下来看下具体的方法实现。
创建 ExecutionJobVertex 对象
先来看下创建 ExecutionJobVertex 对象的实现:
1 | public ExecutionJobVertex( |
它主要做了一下工作:
- 根据这个 JobVertex 的
results(IntermediateDataSet列表)来创建相应的IntermediateResult对象,每个IntermediateDataSet都会对应的一个IntermediateResult; - 再根据这个 JobVertex 的并发度,来创建相同数量的
ExecutionVertex对象,每个ExecutionVertex对象在调度时实际上就是一个 task 任务; - 在创建
IntermediateResult和ExecutionVertex对象时都会记录它们之间的关系,它们之间的关系可以参考本文的图二。
创建 ExecutionVertex 对象
创建 ExecutionVertex 对象的实现如下:
1 | public ExecutionVertex( |
ExecutionVertex 创建时,主要做了下面这三件事:
- 根据这个 ExecutionJobVertex 的
producedDataSets(IntermediateResult 类型的数组),给每个 ExecutionVertex 创建相应的 IntermediateResultPartition 对象,它代表了一个 IntermediateResult 分区; - 调用 IntermediateResult 的
setPartition()方法,记录 IntermediateResult 与 IntermediateResultPartition 之间的关系; - 给这个 ExecutionVertex 创建一个 Execution 对象,如果这个 ExecutionVertex 重新调度(失败重新恢复等情况),那么 Execution 对应的
attemptNumber将会自增加 1,这里初始化的时候其值为 0。
创建 ExecutionEdge
根据前面的流程图,接下来,看下 ExecutionJobVertex 的 connectToPredecessors() 方法。在这个方法中,主要做的工作是创建对应的 ExecutionEdge 对象,并使用这个对象将 ExecutionVertex 与 IntermediateResultPartition 连接起来,ExecutionEdge 的成员变量比较简单,如下所示:
1 | // ExecutionEdge.java |
ExecutionEdge 的创建是在 ExecutionVertex 中 connectSource() 方法中实现的,代码实现如下:
1 | // ExecutionVertex.java |
在创建 ExecutionEdge 时,会根据这个 JobEdge 的 DistributionPattern 选择不同的实现,这里主要分两种情况,DistributionPattern 是跟 Partitioner 的配置有关(Partitioner 详解):
1 | // StreamingJobGraphGenerator.java |
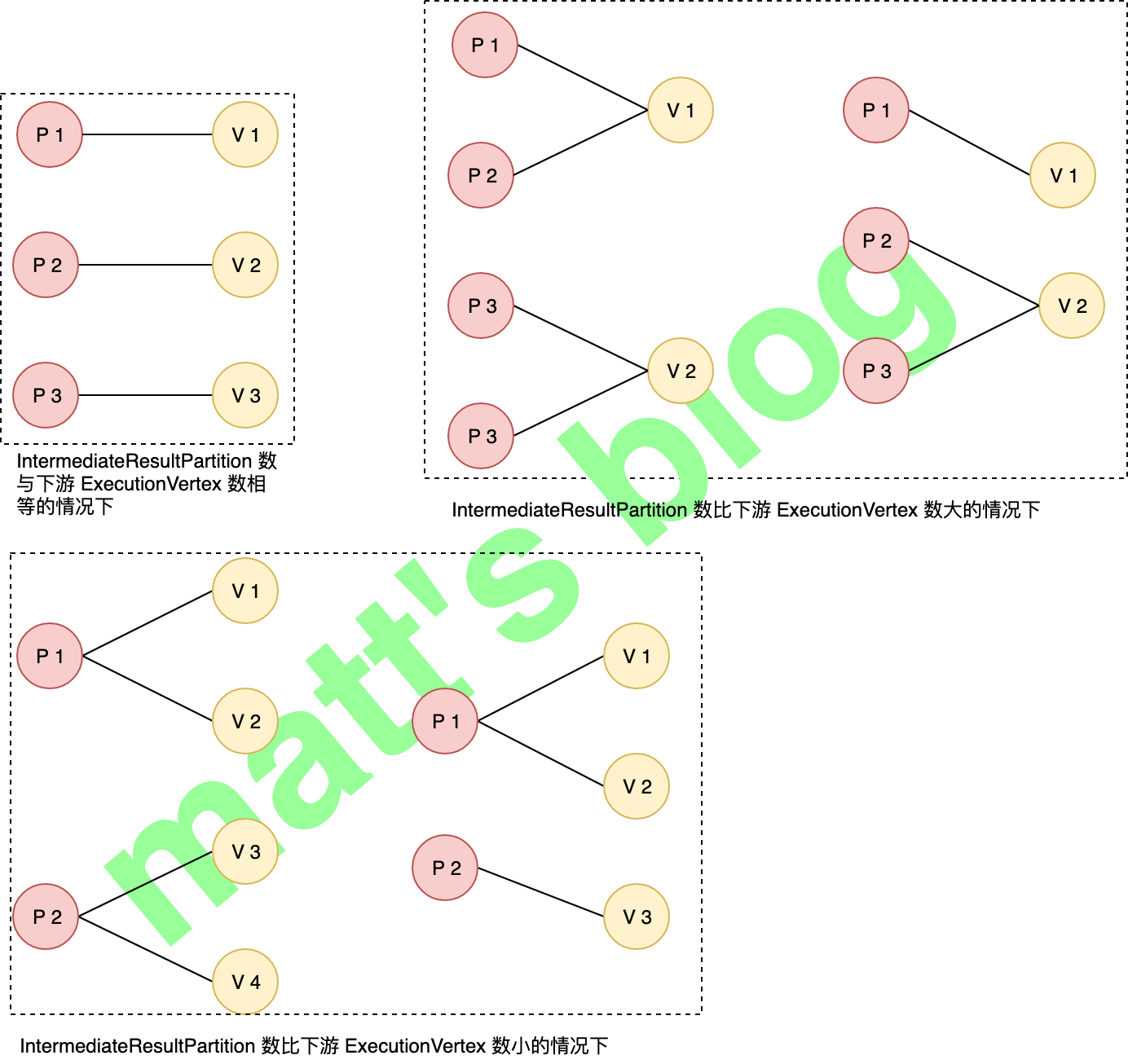
如果 DistributionPattern 是 ALL_TO_ALL 模式,这个 ExecutionVertex 会与 IntermediateResult 对应的所有 IntermediateResultPartition 连接起来,而如果是 POINTWISE 模式,ExecutionVertex 只会与部分的 IntermediateResultPartition 连接起来。POINTWISE 模式下 IntermediateResultPartition 与 ExecutionVertex 之间的分配关系如下图所示,具体的分配机制是跟 IntermediateResultPartition 数与 ExecutionVertex 数有很大关系的,具体细节实现可以看下相应代码,这里只是举了几个示例。
到这里,这个作业的 ExecutionGraph 就创建完成了,有了 ExecutionGraph,JobManager 才能对这个作业做相应的调度。
总结
本文详细介绍了 JobGraph 如何转换为 ExecutionGraph 的过程。到这里,StreamGraph、 JobGraph 和 ExecutionGraph 的生成过程,在最近的三篇文章中已经详细讲述完了,后面将会给大家逐步介绍 runtime 的其他内容。
简单总结一下:
- streamGraph 是最原始的用户逻辑,是一个没有做任何优化的 DataFlow;
- JobGraph 对 StreamGraph 做了一些优化,主要是将能够 Chain 在一起的算子 Chain 在一起,这一样可以减少网络 shuffle 的开销;
- ExecutionGraph 则是作业运行是用来调度的执行图,可以看作是并行化版本的 JobGraph,将 DAG 拆分到基本的调度单元。
参考
