for (partition <- partitionState.keys) responseMap.put(partition.topicPartition, Errors.NONE.code)
//note: 统计 follower 的集合 val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()
try {
// TODO: Delete leaders from LeaderAndIsrRequest partitionState.foreach{ case (partition, partitionStateInfo) => val newLeaderBrokerId = partitionStateInfo.leader metadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match { //note: leader 是可用的 // Only change partition state when the leader is available caseSome(_) => //note: partition 的本地副本设置为 follower if (partition.makeFollower(controllerId, partitionStateInfo, correlationId)) partitionsToMakeFollower += partition else//note: 这个 partition 的本地副本已经是 follower 了 stateChangeLogger.info(("Broker %d skipped the become-follower state change after marking its partition as follower with correlation id %d from " + "controller %d epoch %d for partition %s since the new leader %d is the same as the old leader") .format(localBrokerId, correlationId, controllerId, partitionStateInfo.controllerEpoch, partition.topicPartition, newLeaderBrokerId)) caseNone => // The leader broker should always be present in the metadata cache. // If not, we should record the error message and abort the transition process for this partition stateChangeLogger.error(("Broker %d received LeaderAndIsrRequest with correlation id %d from controller" + " %d epoch %d for partition %s but cannot become follower since the new leader %d is unavailable.") .format(localBrokerId, correlationId, controllerId, partitionStateInfo.controllerEpoch, partition.topicPartition, newLeaderBrokerId)) // Create the local replica even if the leader is unavailable. This is required to ensure that we include // the partition's high watermark in the checkpoint file (see KAFKA-1647) partition.getOrCreateReplica() } }
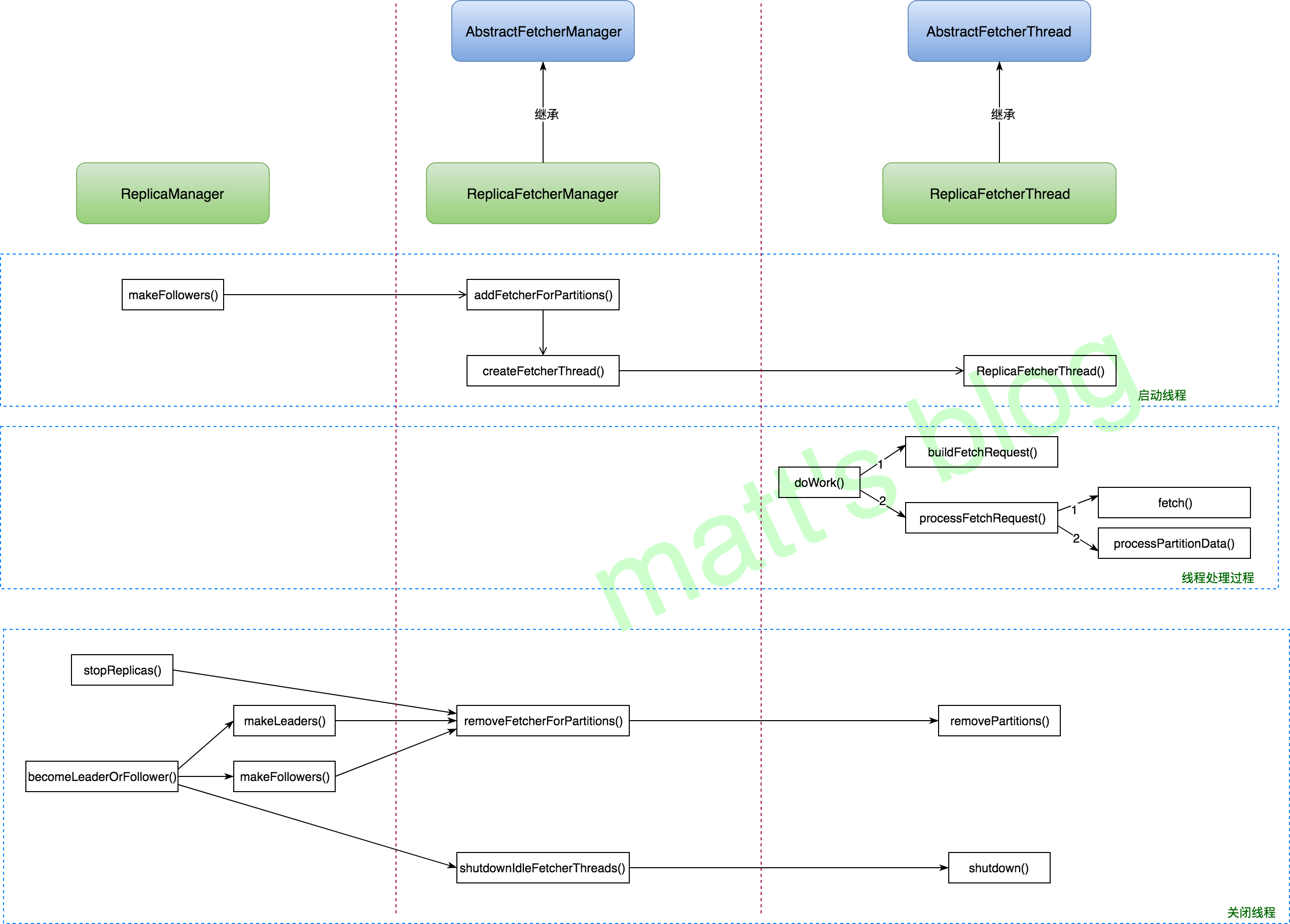
//note: 删除对这些 partition 的副本同步线程 replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition)) partitionsToMakeFollower.foreach { partition => stateChangeLogger.trace(("Broker %d stopped fetchers as part of become-follower request from controller " + "%d epoch %d with correlation id %d for partition %s") .format(localBrokerId, controllerId, epoch, correlationId, partition.topicPartition)) }
//note: Truncate the partition logs to the specified offsets and checkpoint the recovery point to this offset logManager.truncateTo(partitionsToMakeFollower.map { partition => (partition.topicPartition, partition.getOrCreateReplica().highWatermark.messageOffset) }.toMap) //note: 完成那些延迟请求的处理 partitionsToMakeFollower.foreach { partition => val topicPartitionOperationKey = newTopicPartitionOperationKey(partition.topicPartition) tryCompleteDelayedProduce(topicPartitionOperationKey) tryCompleteDelayedFetch(topicPartitionOperationKey) }
partitionsToMakeFollower.foreach { partition => stateChangeLogger.trace(("Broker %d truncated logs and checkpointed recovery boundaries for partition %s as part of " + "become-follower request with correlation id %d from controller %d epoch %d").format(localBrokerId, partition.topicPartition, correlationId, controllerId, epoch)) }
if (isShuttingDown.get()) { partitionsToMakeFollower.foreach { partition => stateChangeLogger.trace(("Broker %d skipped the adding-fetcher step of the become-follower state change with correlation id %d from " + "controller %d epoch %d for partition %s since it is shutting down").format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition)) } } else { // we do not need to check if the leader exists again since this has been done at the beginning of this process //note: 启动副本同步线程 val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map(partition => partition.topicPartition -> BrokerAndInitialOffset( metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get.getBrokerEndPoint(config.interBrokerListenerName), partition.getReplica().get.logEndOffset.messageOffset)).toMap //note: leader 信息+本地 replica 的 offset replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)
partitionsToMakeFollower.foreach { partition => stateChangeLogger.trace(("Broker %d started fetcher to new leader as part of become-follower request from controller " + "%d epoch %d with correlation id %d for partition %s") .format(localBrokerId, controllerId, epoch, correlationId, partition.topicPartition)) } } } catch { case e: Throwable => val errorMsg = ("Error on broker %d while processing LeaderAndIsr request with correlationId %d received from controller %d " + "epoch %d").format(localBrokerId, correlationId, controllerId, epoch) stateChangeLogger.error(errorMsg, e) // Re-throw the exception for it to be caught in KafkaApis throw e }
overridedefrun(): Unit = { info("Starting ") try{ while(isRunning.get()){ doWork() } } catch{ case e: Throwable => if(isRunning.get()) error("Error due to ", e) } shutdownLatch.countDown() info("Stopped ") }
overridedefdoWork() { //note: 构造 fetch request val fetchRequest = inLock(partitionMapLock) { val fetchRequest = buildFetchRequest(partitionStates.partitionStates.asScala.map { state => state.topicPartition -> state.value }) if (fetchRequest.isEmpty) { //note: 如果没有活跃的 partition,在下次调用之前,sleep fetchBackOffMs 时间 trace("There are no active partitions. Back off for %d ms before sending a fetch request".format(fetchBackOffMs)) partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS) } fetchRequest } if (!fetchRequest.isEmpty) processFetchRequest(fetchRequest) //note: 发送 fetch 请求,处理 fetch 的结果 }
//note: 构造 Fetch 请求 protecteddefbuildFetchRequest(partitionMap: Seq[(TopicPartition, PartitionFetchState)]): FetchRequest = { val requestMap = new util.LinkedHashMap[TopicPartition, JFetchRequest.PartitionData]
partitionMap.foreach { case (topicPartition, partitionFetchState) => // We will not include a replica in the fetch request if it should be throttled. if (partitionFetchState.isActive && !shouldFollowerThrottle(quota, topicPartition)) requestMap.put(topicPartition, newJFetchRequest.PartitionData(partitionFetchState.offset, fetchSize)) } //note: 关键在于 setReplicaId 方法,设置了 replicaId, 对于 consumer, 该值为 CONSUMER_REPLICA_ID(-1) val requestBuilder = newJFetchRequest.Builder(maxWait, minBytes, requestMap). setReplicaId(replicaId).setMaxBytes(maxBytes) requestBuilder.setVersion(fetchRequestVersion) newFetchRequest(requestBuilder) }
privatedefprocessFetchRequest(fetchRequest: REQ) { val partitionsWithError = mutable.Set[TopicPartition]()
defupdatePartitionsWithError(partition: TopicPartition): Unit = { partitionsWithError += partition partitionStates.moveToEnd(partition) }
var responseData: Seq[(TopicPartition, PD)] = Seq.empty
try { trace("Issuing to broker %d of fetch request %s".format(sourceBroker.id, fetchRequest)) responseData = fetch(fetchRequest) //note: 发送 fetch 请求,获取 fetch 结果 } catch { case t: Throwable => if (isRunning.get) { warn(s"Error in fetch $fetchRequest", t) inLock(partitionMapLock) { //note: fetch 时发生错误,sleep 一会 partitionStates.partitionSet.asScala.foreach(updatePartitionsWithError) // there is an error occurred while fetching partitions, sleep a while // note that `ReplicaFetcherThread.handlePartitionsWithError` will also introduce the same delay for every // partition with error effectively doubling the delay. It would be good to improve this. partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS) } } } fetcherStats.requestRate.mark()
if (responseData.nonEmpty) { //note: fetch 结果不为空 // process fetched data inLock(partitionMapLock) {
responseData.foreach { case (topicPartition, partitionData) => val topic = topicPartition.topic val partitionId = topicPartition.partition Option(partitionStates.stateValue(topicPartition)).foreach(currentPartitionFetchState => // we append to the log if the current offset is defined and it is the same as the offset requested during fetch //note: 如果 fetch 的 offset 与返回结果的 offset 相同,并且返回没有异常,那么就将拉取的数据追加到对应的 partition 上 if (fetchRequest.offset(topicPartition) == currentPartitionFetchState.offset) { Errors.forCode(partitionData.errorCode) match { caseErrors.NONE => try { val records = partitionData.toRecords val newOffset = records.shallowEntries.asScala.lastOption.map(_.nextOffset).getOrElse( currentPartitionFetchState.offset)
fetcherLagStats.getAndMaybePut(topic, partitionId).lag = Math.max(0L, partitionData.highWatermark - newOffset) // Once we hand off the partition data to the subclass, we can't mess with it any more in this thread //note: 将 fetch 的数据追加到日志文件中 processPartitionData(topicPartition, currentPartitionFetchState.offset, partitionData)
val validBytes = records.validBytes if (validBytes > 0) { // Update partitionStates only if there is no exception during processPartitionData //note: 更新 fetch 的 offset 位置 partitionStates.updateAndMoveToEnd(topicPartition, newPartitionFetchState(newOffset)) fetcherStats.byteRate.mark(validBytes) //note: 更新 metrics } } catch { case ime: CorruptRecordException => // we log the error and continue. This ensures two things // 1. If there is a corrupt message in a topic partition, it does not bring the fetcher thread down and cause other topic partition to also lag // 2. If the message is corrupt due to a transient state in the log (truncation, partial writes can cause this), we simply continue and // should get fixed in the subsequent fetches //note: CRC 验证失败时,打印日志,并继续进行(这个线程还会有其他的 tp 拉取,防止影响其他副本同步) logger.error("Found invalid messages during fetch for partition [" + topic + "," + partitionId + "] offset " + currentPartitionFetchState.offset + " error " + ime.getMessage) updatePartitionsWithError(topicPartition); case e: Throwable => //note: 这里还会抛出异常,是 RUNTimeException thrownewKafkaException("error processing data for partition [%s,%d] offset %d" .format(topic, partitionId, currentPartitionFetchState.offset), e) } caseErrors.OFFSET_OUT_OF_RANGE => //note: Out-of-range 的情况处理 try { val newOffset = handleOffsetOutOfRange(topicPartition) partitionStates.updateAndMoveToEnd(topicPartition, newPartitionFetchState(newOffset)) error("Current offset %d for partition [%s,%d] out of range; reset offset to %d" .format(currentPartitionFetchState.offset, topic, partitionId, newOffset)) } catch { //note: 处理 out-of-range 是抛出的异常 case e: Throwable => error("Error getting offset for partition [%s,%d] to broker %d".format(topic, partitionId, sourceBroker.id), e) updatePartitionsWithError(topicPartition) } case _ => //note: 其他的异常情况 if (isRunning.get) { error("Error for partition [%s,%d] to broker %d:%s".format(topic, partitionId, sourceBroker.id, partitionData.exception.get)) updatePartitionsWithError(topicPartition) } } }) } } }
//note: 处理拉取遇到的错误读的 tp if (partitionsWithError.nonEmpty) { debug("handling partitions with error for %s".format(partitionsWithError)) handlePartitionsWithErrors(partitionsWithError) } }
// process fetched data //note: 处理 fetch 的数据,将 fetch 的数据追加的日志文件中 defprocessPartitionData(topicPartition: TopicPartition, fetchOffset: Long, partitionData: PartitionData) { try { val replica = replicaMgr.getReplica(topicPartition).get val records = partitionData.toRecords
//note: 检查 records maybeWarnIfOversizedRecords(records, topicPartition)
if (fetchOffset != replica.logEndOffset.messageOffset) thrownewRuntimeException("Offset mismatch for partition %s: fetched offset = %d, log end offset = %d.".format(topicPartition, fetchOffset, replica.logEndOffset.messageOffset)) if (logger.isTraceEnabled) trace("Follower %d has replica log end offset %d for partition %s. Received %d messages and leader hw %d" .format(replica.brokerId, replica.logEndOffset.messageOffset, topicPartition, records.sizeInBytes, partitionData.highWatermark)) replica.log.get.append(records, assignOffsets = false) //note: 将 fetch 的数据追加到 log 中 if (logger.isTraceEnabled) trace("Follower %d has replica log end offset %d after appending %d bytes of messages for partition %s" .format(replica.brokerId, replica.logEndOffset.messageOffset, records.sizeInBytes, topicPartition)) //note: 更新 replica 的 hw(logEndOffset 在追加数据后也会立马进行修改) val followerHighWatermark = replica.logEndOffset.messageOffset.min(partitionData.highWatermark) // for the follower replica, we do not need to keep // its segment base offset the physical position, // these values will be computed upon making the leader //note: 这个值主要是用在 leader replica 上的 replica.highWatermark = newLogOffsetMetadata(followerHighWatermark) if (logger.isTraceEnabled) trace(s"Follower ${replica.brokerId} set replica high watermark for partition $topicPartition to $followerHighWatermark") if (quota.isThrottled(topicPartition)) quota.record(records.sizeInBytes) } catch { case e: KafkaStorageException => fatal(s"Disk error while replicating data for $topicPartition", e) Runtime.getRuntime.halt(1) } }
/** * Unclean leader election: A follower goes down, in the meanwhile the leader keeps appending messages. The follower comes back up * and before it has completely caught up with the leader's logs, all replicas in the ISR go down. The follower is now uncleanly * elected as the new leader, and it starts appending messages from the client. The old leader comes back up, becomes a follower * and it may discover that the current leader's end offset is behind its own end offset. * * In such a case, truncate the current follower's log to the current leader's end offset and continue fetching. * * There is a potential for a mismatch between the logs of the two replicas here. We don't fix this mismatch as of now. */ //note: 脏选举的发生 //note: 获取最新的 offset val leaderEndOffset: Long = earliestOrLatestOffset(topicPartition, ListOffsetRequest.LATEST_TIMESTAMP, brokerConfig.brokerId)
if (leaderEndOffset < replica.logEndOffset.messageOffset) { //note: leaderEndOffset 小于 副本 LEO 的情况 // Prior to truncating the follower's log, ensure that doing so is not disallowed by the configuration for unclean leader election. // This situation could only happen if the unclean election configuration for a topic changes while a replica is down. Otherwise, // we should never encounter this situation since a non-ISR leader cannot be elected if disallowed by the broker configuration. //note: 这种情况只是发生在 unclear election 的情况下 if (!LogConfig.fromProps(brokerConfig.originals, AdminUtils.fetchEntityConfig(replicaMgr.zkUtils, ConfigType.Topic, topicPartition.topic)).uncleanLeaderElectionEnable) { //note: 不允许 unclear elect 时,直接退出进程 // Log a fatal error and shutdown the broker to ensure that data loss does not unexpectedly occur. fatal("Exiting because log truncation is not allowed for partition %s,".format(topicPartition) + " Current leader %d's latest offset %d is less than replica %d's latest offset %d" .format(sourceBroker.id, leaderEndOffset, brokerConfig.brokerId, replica.logEndOffset.messageOffset)) System.exit(1) }
//note: warn 日志信息 warn("Replica %d for partition %s reset its fetch offset from %d to current leader %d's latest offset %d" .format(brokerConfig.brokerId, topicPartition, replica.logEndOffset.messageOffset, sourceBroker.id, leaderEndOffset)) //note: 进行截断操作,将offset 大于等于targetOffset 的数据和索引删除 replicaMgr.logManager.truncateTo(Map(topicPartition -> leaderEndOffset)) leaderEndOffset } else { //note: leader 的 LEO 大于 follower 的 LEO 的情况下,还发生了 OutOfRange //note: 1. follower 下线了很久,其 LEO 已经小于了 leader 的 StartOffset; //note: 2. 脏选举发生时, 如果 old leader 的 HW 大于 new leader 的 LEO,此时 old leader 回溯到 HW,并且这个位置开始拉取数据发生了 Out of range //note: 当这个方法调用时,随着 produce 持续产生数据,可能出现 leader LEO 大于 Follower LEO 的情况(不做任何处理,重试即可解决,但 //note: 无法保证数据的一致性)。 /** * If the leader's log end offset is greater than the follower's log end offset, there are two possibilities: * 1. The follower could have been down for a long time and when it starts up, its end offset could be smaller than the leader's * start offset because the leader has deleted old logs (log.logEndOffset < leaderStartOffset). * 2. When unclean leader election occurs, it is possible that the old leader's high watermark is greater than * the new leader's log end offset. So when the old leader truncates its offset to its high watermark and starts * to fetch from the new leader, an OffsetOutOfRangeException will be thrown. After that some more messages are * produced to the new leader. While the old leader is trying to handle the OffsetOutOfRangeException and query * the log end offset of the new leader, the new leader's log end offset becomes higher than the follower's log end offset. * * In the first case, the follower's current log end offset is smaller than the leader's log start offset. So the * follower should truncate all its logs, roll out a new segment and start to fetch from the current leader's log * start offset. * In the second case, the follower should just keep the current log segments and retry the fetch. In the second * case, there will be some inconsistency of data between old and new leader. We are not solving it here. * If users want to have strong consistency guarantees, appropriate configurations needs to be set for both * brokers and producers. * * Putting the two cases together, the follower should fetch from the higher one of its replica log end offset * and the current leader's log start offset. * */ val leaderStartOffset: Long = earliestOrLatestOffset(topicPartition, ListOffsetRequest.EARLIEST_TIMESTAMP, brokerConfig.brokerId) warn("Replica %d for partition %s reset its fetch offset from %d to current leader %d's start offset %d" .format(brokerConfig.brokerId, topicPartition, replica.logEndOffset.messageOffset, sourceBroker.id, leaderStartOffset)) val offsetToFetch = Math.max(leaderStartOffset, replica.logEndOffset.messageOffset) // Only truncate log when current leader's log start offset is greater than follower's log end offset. if (leaderStartOffset > replica.logEndOffset.messageOffset) //note: 如果 leader 的 startOffset 大于副本的最大 offset //note: 将这个 log 的数据全部清空,并且从 leaderStartOffset 开始拉取数据 replicaMgr.logManager.truncateFullyAndStartAt(topicPartition, leaderStartOffset) offsetToFetch } }
/* * Make the current broker to become leader for a given set of partitions by: * * 1. Stop fetchers for these partitions * 2. Update the partition metadata in cache * 3. Add these partitions to the leader partitions set * * If an unexpected error is thrown in this function, it will be propagated to KafkaApis where * the error message will be set on each partition since we do not know which partition caused it. Otherwise, * return the set of partitions that are made leader due to this method * * TODO: the above may need to be fixed later */ //note: 选举当前副本作为 partition 的 leader,处理过程: //note: 1. 停止这些 partition 的 副本同步请求; //note: 2. 更新缓存中的 partition metadata; //note: 3. 将这些 partition 添加到 leader partition 集合中。 privatedefmakeLeaders(controllerId: Int, epoch: Int, partitionState: Map[Partition, PartitionState], correlationId: Int, responseMap: mutable.Map[TopicPartition, Short]): Set[Partition] = { partitionState.keys.foreach { partition => stateChangeLogger.trace(("Broker %d handling LeaderAndIsr request correlationId %d from controller %d epoch %d " + "starting the become-leader transition for partition %s") .format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition)) }
for (partition <- partitionState.keys) responseMap.put(partition.topicPartition, Errors.NONE.code)
val partitionsToMakeLeaders: mutable.Set[Partition] = mutable.Set()
try { // First stop fetchers for all the partitions //note: 停止这些副本同步请求 replicaFetcherManager.removeFetcherForPartitions(partitionState.keySet.map(_.topicPartition)) // Update the partition information to be the leader //note: 更新这些 partition 的信息(这些 partition 成为 leader 了) partitionState.foreach{ case (partition, partitionStateInfo) => //note: 在 partition 对象将本地副本设置为 leader if (partition.makeLeader(controllerId, partitionStateInfo, correlationId)) partitionsToMakeLeaders += partition //note: 成功选为 leader 的 partition 集合 else //note: 本地 replica 已经是 leader replica,可能是接收了重试的请求 stateChangeLogger.info(("Broker %d skipped the become-leader state change after marking its partition as leader with correlation id %d from " + "controller %d epoch %d for partition %s since it is already the leader for the partition.") .format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition)) } partitionsToMakeLeaders.foreach { partition => stateChangeLogger.trace(("Broker %d stopped fetchers as part of become-leader request from controller " + "%d epoch %d with correlation id %d for partition %s") .format(localBrokerId, controllerId, epoch, correlationId, partition.topicPartition)) } } catch { case e: Throwable => partitionState.keys.foreach { partition => val errorMsg = ("Error on broker %d while processing LeaderAndIsr request correlationId %d received from controller %d" + " epoch %d for partition %s").format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition) stateChangeLogger.error(errorMsg, e) } // Re-throw the exception for it to be caught in KafkaApis throw e }