Kafka 之 Group 状态变化分析及 Rebalance 过程
前段时间看一下 Kafka 的部分源码(0.10.1.0 版),对一些地方做了一些相应的总结。本文主要就 Kafka Group 方面的内容做一下详细的讲述,重点讲述 Consumer Client 如何进行初始化、Server 端对应的 Consumer Group 状态如何进行变化以及对一些 Kafka 的新设计(与旧版不同之处)简单介绍一下。
Group 状态机
在 0.9.0.0 之后的 Kafka,出现了几个新变动,一个是在 Server 端增加了 GroupCoordinator 这个角色,另一个较大的变动是将 topic 的 offset 信息由之前存储在 zookeeper 上改为存储到一个特殊的 topic 中(__consumer_offsets)。
offset 那些事
在 Kafka 中,无论是写入 topic,还是从 topic 读取数据,都免不了与 offset 打交道,关于 Kafka 的 offset 主要有以下几个概念,如下图。
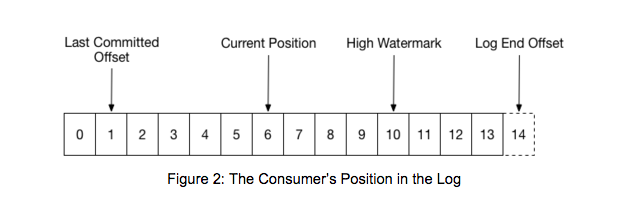
其中,Last Committed Offset 和 Current Position 是与 Consumer Client 有关,High Watermark 和 Log End Offset 与 Producer Client 数据写入和 replica 之间的数据同步有关。
- Last Committed Offset:这是 group 最新一次 commit 的 offset,表示这个 group 已经把 Last Committed Offset 之前的数据都消费成功了;
- Current Position:group 当前消费数据的 offset,也就是说,Last Committed Offset 到 Current Position 之间的数据已经拉取成功,可能正在处理,但是还未 commit;
- Log End Offset:Producer 写入到 Kafka 中的最新一条数据的 offset;
- High Watermark:已经成功备份到其他 replicas 中的最新一条数据的 offset,也就是说 Log End Offset 与 High Watermark 之间的数据已经写入到该 partition 的 leader 中,但是还未成功备份到其他的 replicas 中,这部分数据被认为是不安全的,是不允许 Consumer 消费的(这里说得不是很准确,可以参考:Kafka水位(high watermark)与leader epoch的讨论 这篇文章)。
Topic __consumer_offsets
__consumer_offsets 是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 三副本,而具体 group 的消费情况要存储到哪一个 partition 上,是根据 abs(GroupId.hashCode()) % NumPartitions 来计算(其中,NumPartitions 是__consumer_offsets 的 partition 数,默认是50个)的。
GroupCoordinator
根据上面所述,一个具体的 group,是根据其 group 名进行 hash 并计算得到其具对应的 partition 值,该 partition leader 所在 Broker 即为该 Group 所对应的 GroupCoordinator,GroupCoordinator 会存储与该 group 相关的所有的 Meta 信息。
在 Broker 启动时,每个 Broker 都会启动一个 GroupCoordinator 服务,但只有 __consumer_offsets 的 partition 的 leader 才会直接与 Consumer Client 进行交互,也就是其 group 的 GroupCoordinator,其他的 GroupCoordinator 只是作为备份,一旦作为 leader 的 Broker 挂掉之后及时进行替代。
状态转移图
Server 端,Consumer 的 Group 共定义了五个状态
- Empty:Group 没有任何成员,如果所有的 offsets 都过期的话就会变成 Dead,一般当 Group 新创建时是这个状态,也有可能这个 Group 仅仅用于 offset commits 并没有任何成员(Group has no more members, but lingers until all offsets have expired. This state also represents groups which use Kafka only for offset commits and have no members.);
- PreparingRebalance:Group 正在准备进行 Rebalance(Group is preparing to rebalance);
- AwaitingSync:Group 正在等待来 group leader 的 assignment(Group is awaiting state assignment from the leader);
- Stable:稳定的状态(Group is stable);
- Dead:Group 内已经没有成员,并且它的 Meta 已经被移除(Group has no more members and its metadata is being removed)。
其各个状态的定义及转换都在 GroupMetadata 中定义,根据状态转移的条件和转移的结果做一个状态转移图如下所示
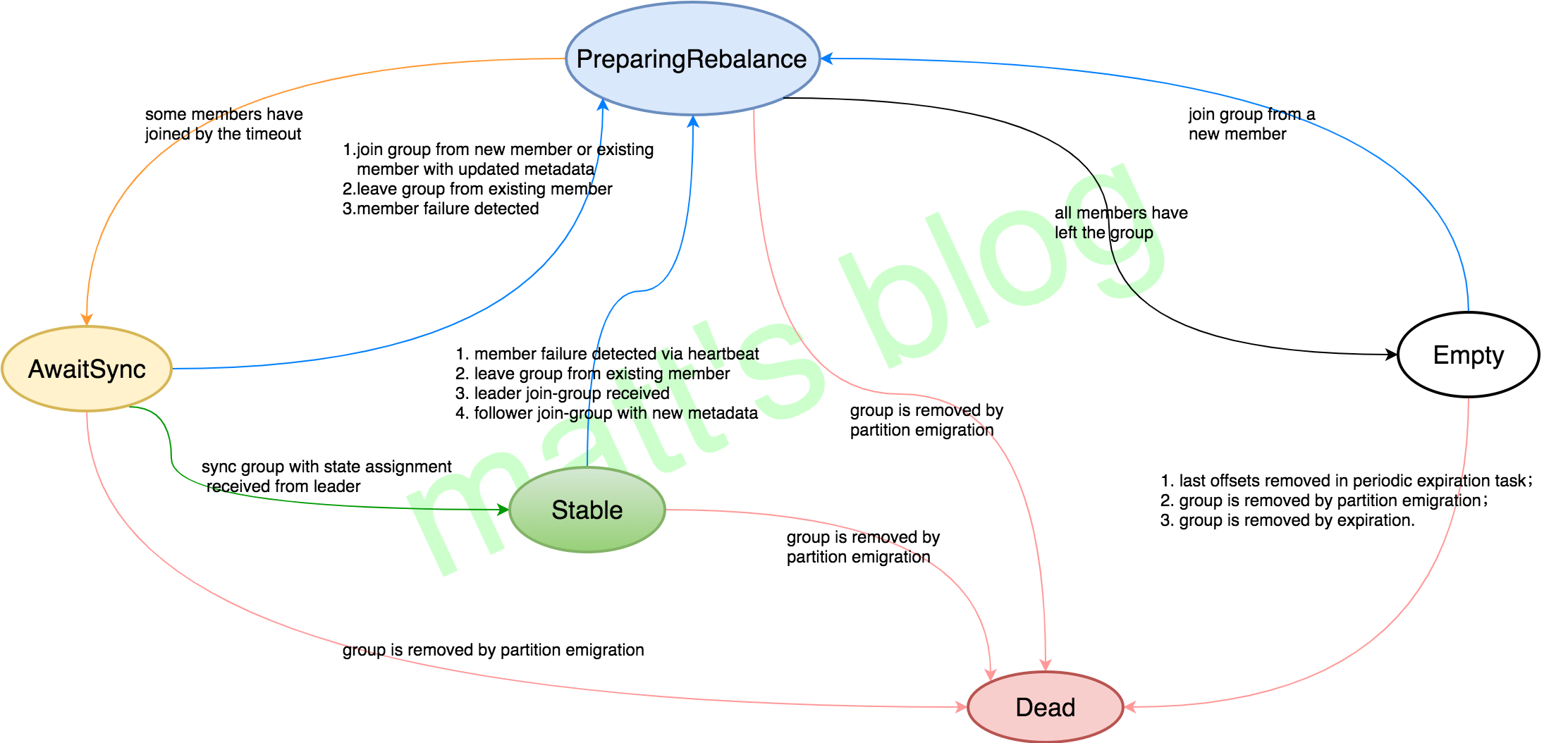
各个状态转化的情况,只有有对应箭头才能进行转移,比如 Empty 到 PreparingRebalance 是可以转移的,而 Dead 到 PreparingRebalance 是不可以的。后面会根据一个 Consumer Client 启动的过程,讲述一下其 Group 状态变化情况。
Consumer 初始化
Server 端 Group 状态的变化,其实更多的时候是由 Client 端触发的,一个 group 在最初初始化的过程总其实就是该 Group 第一个 Consumer Client 初始化的过程。
Consumer poll 过程解析
对 Consumer 的初始化,正如 Apache Kafka 0.9 Consumer Client 介绍 这篇文章所述,Consumer 的核心逻辑部分主要在其 poll 模型。而其源码的实现上,主要的逻辑实现也是在 pollOnce 方法,如下所示。
1 | //NOTE: 一次 poll 过程 |
与 Server 进行交互,尤其初始化 Group 这一部分,主要是在 coordinator.poll() 方法,源码如下
1 | public void poll(long now) { |
ensureCoordinatorReady() 方法是获取该 group 对应的 GroupCoordinator 地址,并建立连接,然后再进行判断,如果当前的这个 Consumer Client 需要加入一个 group,将进行以下操作(向 Server 端发送 join-group 请求以加入 group,然后再发送 sync-group 请求,获取 client 的 assignment)
1 | //NOTE: 确保 Group 是 active,并且加入该 group |
Consumer 初始化时 group 状态变化
这里详述一下 Client 进行以上操作时,Server 端 Group 状态的变化情况。当 Consumer Client 首次进行拉取数据,如果该其所属 Group 并不存在时,Group 的状态变化过程如下:
- Consumer Client 发送 join-group 请求,如果 Group 不存在,创建该 Group,Group 的状态为 Empty;
- 由于 Group 的 member 为空,将该 member 加入到 Group 中,并将当前 member (client)设置为 Group 的 leader,进行 rebalance 操作,Group 的状态变为 preparingRebalance,等待
rebalance.timeout.ms之后(为了等待其他 member 重新发送 join-group,如果 Group 的状态变为preparingRebalance,Consumer Client 在进行 poll 操作时,needRejoin()方法结果就会返回 true,也就意味着当前 Consumer Client 需要重新加入 Group),Group 的 member 更新已经完成,此时 Group 的状态变为 AwaitingSync,并向 Group 的所有 member 返回 join-group 响应; - client 在收到 join-group 结果之后,如果发现自己的角色是 Group 的 leader,就进行 assignment,该 leader 将 assignment 的结果通过 sync-group 请求发送给 GroupCoordinator,而 follower 也会向 GroupCoordinator 发送一个 sync-group 请求(只不过对应的字段为空);
- 当 GroupCoordinator 收到这个 Group leader 的请求之后,获取 assignment 的结果,将各个 member 对应的 assignment 发送给各个 member,而如果该 Client 是 follower 的话就不做任何处理,此时 group 的状态变为 Stable(也就是说,只有当收到的 Leader 的请求之后,才会向所有 member 返回 sync-group 的结果,这个是只发送一次的,由 leader 请求来触发)。
Consumer Rebalance
根据上图,当 group 在 Empty、AwaitSync 或 Stable 状态时,group 可能会进行 rebalance;
rebalance 的过程就是:等待所有 member 发送 join-group(上述过程的第2步),然后设置 Group 的 leader,进行 reassignment,各个 client 发送 sync-group 来同步 server 的 assignment 结果。
