Kafka 源码解析之副本状态机与分区状态机(十七)
上篇讲述了 KafkaController 的启动流程,但是关于分区状态机和副本状态机的初始化并没有触及,分区状态机和副本状态机的内容将在本篇文章深入讲述。分区状态机记录着当前集群所有 Partition 的状态信息以及如何对 Partition 状态转移进行相应的处理;副本状态机则是记录着当前集群所有 Replica 的状态信息以及如何对 Replica 状态转变进行相应的处理。
ReplicaStateMachine
ReplicaStateMachine 记录着集群所有 Replica 的状态信息,它决定着一个 replica 处在什么状态以及它在什么状态下可以转变为什么状态,Kafka 中副本的状态总共有以下七种类型:
- NewReplica:这种状态下 Controller 可以创建这个 Replica,这种状态下该 Replica 只能作为 follower,它可以是 Replica 删除后的一个临时状态,它有效的前置状态是 NonExistentReplica;
- OnlineReplica:一旦这个 Replica 被分配到指定的 Partition 上,并且 Replica 创建完成,那么它将会被置为这个状态,在这个状态下,这个 Replica 既可以作为 leader 也可以作为 follower,它有效的前置状态是 NewReplica、OnlineReplica 或 OfflineReplica;
- OfflineReplica:如果一个 Replica 挂掉(所在的节点宕机或者其他情况),该 Replica 将会被转换到这个状态,它有的效前置状态是 NewReplica、OfflineReplica 或者 OnlineReplica;
- ReplicaDeletionStarted:Replica 开始删除时被置为的状态,它有效的前置状态是 OfflineReplica;
- ReplicaDeletionSuccessful:如果 Replica 在删除时没有遇到任何错误信息,它将被置为这个状态,这个状态代表该 Replica 的数据已经从节点上清除了,它有效的前置状态是 ReplicaDeletionStarted;
- ReplicaDeletionIneligible:如果 Replica 删除失败,它将会转移到这个状态,这个状态意思是非法删除,也就是删除是无法成功的,它有效的前置状态是 ReplicaDeletionStarted;
- NonExistentReplica:如果 Replica 删除成功,它将被转移到这个状态,它有效的前置状态是:ReplicaDeletionSuccessful。
上面的状态中其中后面4是专门为 Replica 删除而服务的,副本状态机转移图如下所示:
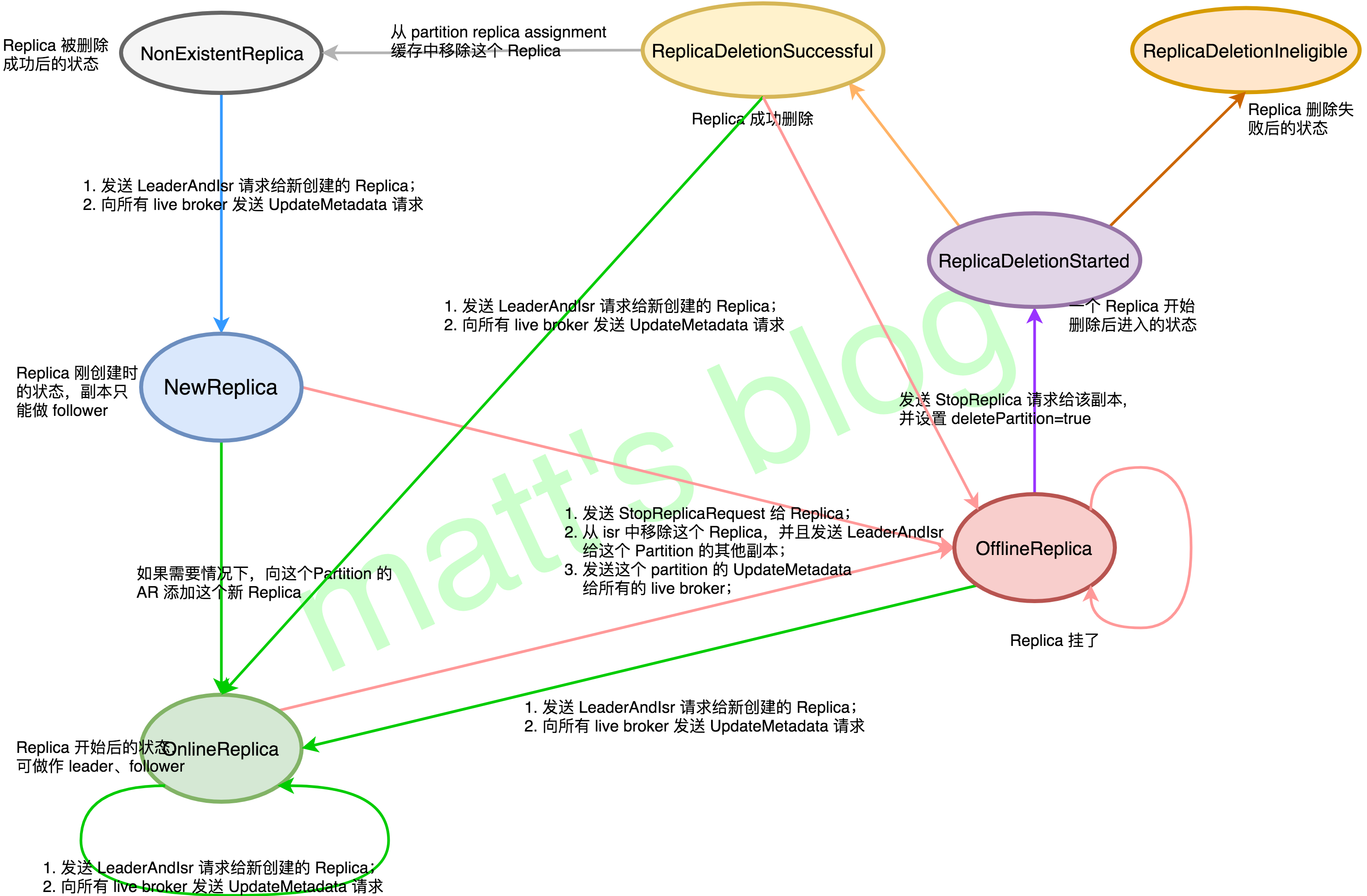
这张图是副本状态机的核心,在下面会详细讲述,接下来先看下 KafkaController 在启动时,调用 ReplicaStateMachine 的 startup() 方法初始化的处理过程。
ReplicaStateMachine 初始化
副本状态机初始化的过程如下:
1 | //note: Controller 重新选举后触发的操作 |
在这个方法中,ReplicaStateMachine 先调用 initializeReplicaState() 方法初始化集群中所有 Replica 的状态信息,如果 Replica 所在机器是 alive 的,那么将其状态设置为 OnlineReplica,否则设置为 ReplicaDeletionIneligible 状态,这里只是将 Replica 的状态信息更新副本状态机的缓存 replicaState 中,并没有真正进行状态转移的操作。
1 | //note: 初始化所有副本的状态信息 |
接着第二步调用 handleStateChanges() 将所有存活的副本状态转移为 OnlineReplica 状态,这里才是真正进行状态转移的地方,其具体实现如下:
1 | //note: 用于处理 Replica 状态的变化 |
这里是副本状态机 startup() 方法的最后一步,它的目的是将所有 alive 的 Replica 状态转移到 OnlineReplica 状态,由于前面已经这些 alive replica 的状态设置成了 OnlineReplica,所以这里 Replica 的状态转移情况是:OnlineReplica –> OnlineReplica,这个方法主要是做了两件事:
- 状态转移(这个在下面详细讲述);
- 发送相应的请求。
副本的状态转移
这里以要转移的 TargetState 区分做详细详细讲解,当 TargetState 分别是 NewReplica、ReplicaDeletionStarted、ReplicaDeletionIneligible、ReplicaDeletionSuccessful、NonExistentReplica、OnlineReplica 或者 OfflineReplica 时,副本状态机所做的事情。
TargetState: NewReplica
NewReplica 这个状态是 Replica 准备开始创建是的一个状态,其实现逻辑如下:
1 | val currState = replicaState.getOrElseUpdate(partitionAndReplica, NonExistentReplica)//note: Replica 不存在的话,状态初始化为 NonExistentReplica |
当想要把 Replica 的状态转移为 NewReplica 时,副本状态机的处理逻辑如下:
- 校验 Replica 的前置状态,只有处于 NonExistentReplica 状态的副本才能转移到 NewReplica 状态;
- 从 zk 中获取该 Topic-Partition 的 LeaderIsrAndControllerEpoch 信息;
- 如果获取不到上述信息,直接将该 Replica 的状态转移成 NewReplica,然后结束流程(对与新建的 Partition,处于这个状态时,该 Partition 是没有相应的 LeaderAndIsr 信息的);
- 获取到 Partition 的 LeaderIsrAndControllerEpoch 信息,如果发现该 Partition 的 leader 是当前副本,那么就抛出 StateChangeFailedException 异常,因为处在这个状态的 Replica 是不能被选举为 leader 的;
- 获取到了 Partition 的 LeaderIsrAndControllerEpoch 信息,并且该 Partition 的 leader 不是当前 replica,那么向该 Partition 的所有 Replica 添加一个 LeaderAndIsr 请求(添加 LeaderAndIsr 请求时,实际上也会向所有的 Broker 都添加一个 Update-Metadata 请求);
- 最后将该 Replica 的状态转移成 NewReplica,然后结束流程。
TargetState: ReplicaDeletionStarted
这是 Replica 开始删除时的状态,Replica 转移到这种状态的处理实现如下:
1 | assertValidPreviousStates(partitionAndReplica, List(OfflineReplica), targetState) |
这部分的实现逻辑:
- 校验其前置状态,Replica 只能是在 OfflineReplica 的情况下才能转移到这种状态;
- 更新向该 Replica 的状态为 ReplicaDeletionStarted;
- 向该 replica 发送 StopReplica 请求(deletePartition = true),收到这请求后,broker 会从物理存储上删除这个 Replica 的数据内容;
- 如果请求返回的话会触发其回调函数(这部分会在 topic 删除部分讲解)。
TargetState: ReplicaDeletionIneligible
ReplicaDeletionIneligible 是副本删除失败时的状态,Replica 转移到这种状态的处理实现如下:
1 | assertValidPreviousStates(partitionAndReplica, List(ReplicaDeletionStarted), targetState) |
实现逻辑:
- 校验其前置状态,Replica 只能是在 ReplicaDeletionStarted 下才能转移这种状态;
- 更新该 Replica 的状态为 ReplicaDeletionIneligible。
TargetState: ReplicaDeletionSuccessful
ReplicaDeletionSuccessful 是副本删除成功时的状态,Replica 转移到这种状态的处理实现如下:
1 | assertValidPreviousStates(partitionAndReplica, List(ReplicaDeletionStarted), targetState) |
实现逻辑:
- 检验其前置状态,Replica 只能是在 ReplicaDeletionStarted 下才能转移这种状态;
- 更新该 Replica 的状态为 ReplicaDeletionSuccessful。
TargetState: NonExistentReplica
NonExistentReplica 是副本完全删除、不存在这个副本的状态,Replica 转移到这种状态的处理实现如下:
1 | assertValidPreviousStates(partitionAndReplica, List(ReplicaDeletionSuccessful), targetState) |
实现逻辑:
- 检验其前置状态,Replica 只能是在 ReplicaDeletionSuccessful 下才能转移这种状态;
- 在 controller 的 partitionReplicaAssignment 删除这个 Partition 对应的 replica 信息;
- 从 Controller 和副本状态机中将这个 Topic 从缓存中删除。
TargetState: OnlineReplica
OnlineReplica 是副本正常工作时的状态,此时的 Replica 既可以作为 leader 也可以作为 follower,Replica 转移到这种状态的处理实现如下:
1 | assertValidPreviousStates(partitionAndReplica, |
从前面的状态转移图中可以看出,当 Replica 处在 NewReplica、OnlineReplica、OfflineReplica 或者 ReplicaDeletionIneligible 状态时,Replica 是可以转移到 OnlineReplica 状态的,下面分两种情况讲述:
NewReplica –> OnlineReplica 的处理逻辑如下:
- 从 Controller 的 partitionReplicaAssignment 中获取这个 Partition 的 AR;
- 如果 Replica 不在 AR 中的话,那么就将其添加到 Partition 的 AR 中;
- 最后将 Replica 的状态设置为 OnlineReplica 状态。
OnlineReplica/OfflineReplica/ReplicaDeletionIneligible –> OnlineReplica 的处理逻辑如下:
- 从 Controller 的 partitionLeadershipInfo 中获取 Partition 的 LeaderAndIsr 信息;
- 如果该信息存在,那么就向这个 Replica 所在 broker 添加这个 Partition 的 LeaderAndIsr 请求,并将 Replica 的状态设置为 OnlineReplica 状态;
- 否则不做任务处理;
- 最后更新R Replica 的状态为 OnlineReplica。
TargetState: OfflineReplica
OfflineReplica 是 Replica 所在 Broker 掉线时 Replica 的状态,转移到这种状态的处理逻辑如下:
1 | assertValidPreviousStates(partitionAndReplica, |
处理逻辑如下:
- 校验其前置状态,只有 Replica 在 NewReplica、OnlineReplica、OfflineReplica 或者 ReplicaDeletionIneligible 状态时,才能转移到这种状态;
- 向该 Replica 所在节点发送 StopReplica 请求(deletePartition = false);
- 调用 Controller 的
removeReplicaFromIsr()方法将该 replica 从 Partition 的 isr 移除这个 replica(前提 isr 中还有其他有效副本),然后向该 Partition 的其他副本发送 LeaderAndIsr 请求; - 更新这个 Replica 的状态为 OfflineReplica。
状态转移触发的条件
这里主要是看一下上面 Replica 各种转移的触发的条件,整理的结果如下表所示,部分内容会在后续文章讲解。
| TargetState | 触发方法 | 作用 |
|---|---|---|
| OnlineReplica | KafkaController 的 onBrokerStartup() | Broker 启动时,目的是将在该节点的 Replica 状态设置为 OnlineReplica |
| OnlineReplica | KafkaController 的 onNewPartitionCreation() | 新建 Partition 时,Replica 初始化及 Partition 状态变成 OnlinePartition 后,新创建的 Replica 状态也变为 OnlineReplica; |
| OnlineReplica | KafkaController 的 onPartitionReassignment() | 副本迁移完成后,RAR 中的副本设置为 OnlineReplica 状态 |
| OnlineReplica | ReplicaStateMachine 的 startup() | 副本状态机刚初始化启动时,将存活的副本状态设置为 OnlineReplica |
| OfflineReplica | TopicDeletionManager 的 markTopicForDeletionRetry() | 将删除失败的 Replica 设置为 OfflineReplica,重新进行删除 |
| OfflineReplica | TopicDeletionManager 的 startReplicaDeletion() | 开始副本删除时,先将副本设置为 OfflineReplica |
| OfflineReplica | KafkaController 的 shutdownBroker() 方法 | 优雅关闭 broker 时,目的是把下线节点上的副本状态设置为 OfflineReplica |
| OfflineReplica | KafkaController 的 onBrokerFailure() | broker 掉线时,目的是把下线节点上的副本状态设置为 OfflineReplica |
| NewReplica | KafkaController 的 onNewPartitionCreation() | Partition 新建时,当 Partition 状态变为 NewPartition 后,副本的状态变为 NewReplica |
| NewReplica | KafkaController 的 startNewReplicasForReassignedPartition() | Partition 副本迁移时,将新分配的副本状态设置为 NewReplica; |
| ReplicaDeletionStarted | TopicDeletionManager 的 startReplicaDeletion() | 下线副本时,将成功设置为 OfflineReplica 的 Replica 设置为 ReplicaDeletionStarted 状态,开始物理上删除副本数据(也是发送 StopReplica) |
| ReplicaDeletionStarted | KafkaController 的 stopOldReplicasOfReassignedPartition() | Partition 的副本迁移时,目的是下线那些 old replica,新的 replica 已经迁移到新分配的副本上了 |
| ReplicaDeletionSuccessful | TopicDeletionManager 的 completeReplicaDeletion() | 物理将数据成功删除的 Replica 状态会变为这个 |
| ReplicaDeletionSuccessful | KafkaController 的 stopOldReplicasOfReassignedPartition() | Partition 的副本迁移时,在下线那些旧 Replica 时的一个状态,删除成功 |
| ReplicaDeletionIneligible | TopicDeletionManager 的 startReplicaDeletion() | 开始副本删除时,删除失败的副本会设置成这个状态 |
| ReplicaDeletionIneligible | KafkaController 的 stopOldReplicasOfReassignedPartition() | Partition 副本迁移时,在下线那些旧的 Replica 时的一个状态,删除失败 |
| NonExistentReplica | TopicDeletionManager 的 completeReplicaDeletion() | 副本删除成功后(状态为 ReplicaDeletionSuccessful),从状态机和 Controller 的缓存中清除该副本的记录; |
| NonExistentReplica | KafkaController 的 stopOldReplicasOfReassignedPartition() | Partition 的副本成功迁移、旧副本成功删除后,从状态机和 Controller 的缓存中清除旧副本的记录 |
PartitionStateMachine
PartitionStateMachine 记录着集群所有 Partition 的状态信息,它决定着一个 Partition 处在什么状态以及它在什么状态下可以转变为什么状态,Kafka 中 Partition 的状态总共有以下四种类型:
- NonExistentPartition:这个代表着这个 Partition 之前没有被创建过或者之前创建了现在又被删除了,它有效的前置状态是 OfflinePartition;
- NewPartition:Partition 创建后,它将处于这个状态,这个状态的 Partition 还没有 leader 和 isr,它有效的前置状态是 NonExistentPartition;
- OnlinePartition:一旦这个 Partition 的 leader 被选举出来了,它将处于这个状态,它有效的前置状态是 NewPartition、OnlinePartition、OfflinePartition;
- OfflinePartition:如果这个 Partition 的 leader 掉线,这个 Partition 将被转移到这个状态,它有效的前置状态是 NewPartition、OnlinePartition、OfflinePartition。
分区状态机转移图如下所示:
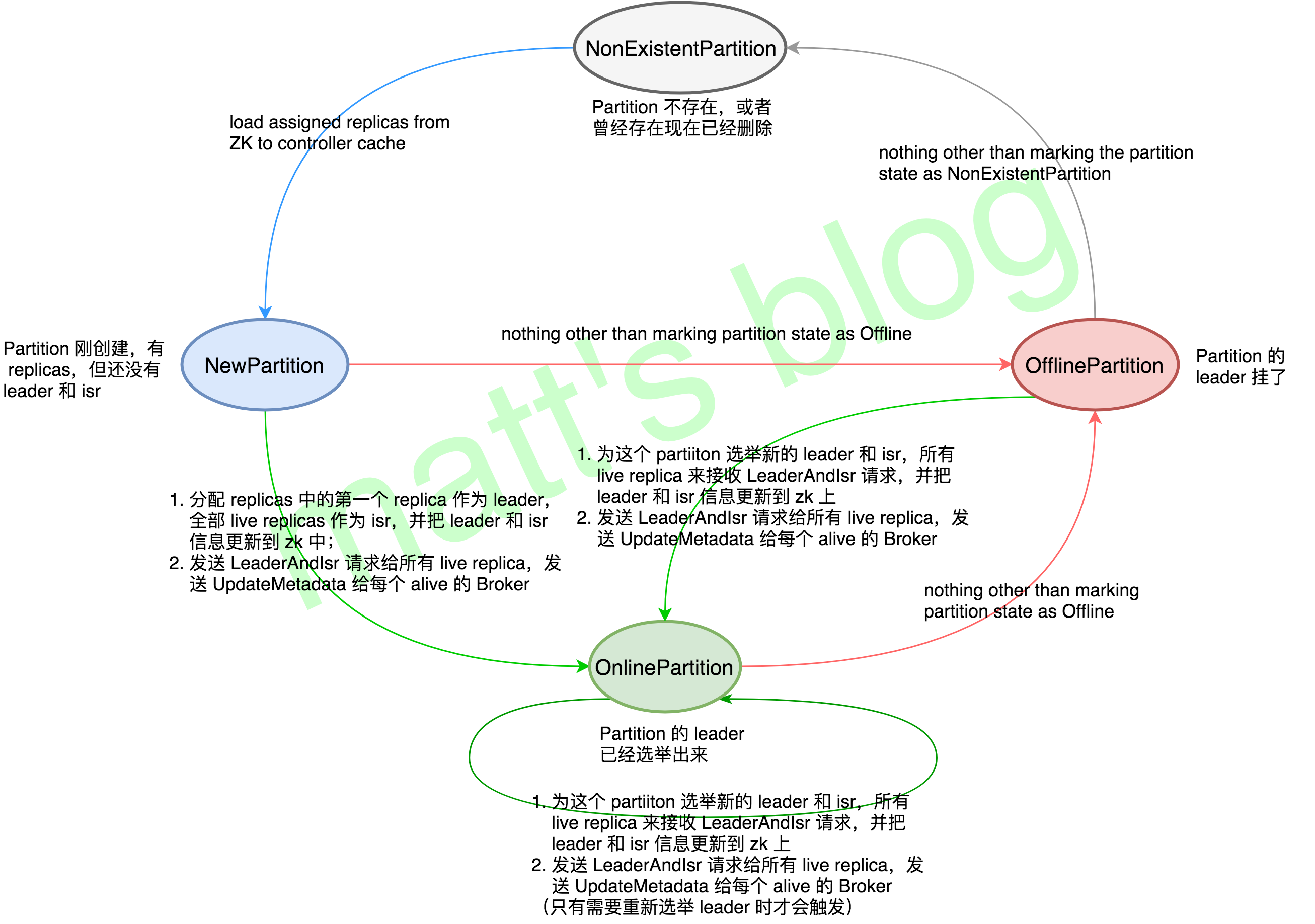
这张图是分区状态机的核心,在下面会详细讲述,接下来先看下 KafkaController 在启动时,调用 PartitionStateMachine 的 startup() 方法初始化的处理过程。
PartitionStateMachine 初始化
PartitionStateMachine 的初始化方法如下所示:
1 | //note: Controller 启动时触发 |
在这个方法中,PartitionStateMachine 先调用 initializePartitionState() 方法初始化集群中所有 Partition 的状态信息:
- 如果该 Partition 有 LeaderAndIsr 信息,那么如果 Partition leader 所在的机器是 alive 的,那么将其状态设置为 OnlinePartition,否则设置为 OfflinePartition 状态;
- 如果该 Partition 没有 LeaderAndIsr 信息,那么将其状态设置为 NewPartition。
这里只是将 Partition 的状态信息更新分区状态机的缓存 partitionState 中,并没有真正进行状态的转移。
1 | //note: 根据从 zk 获取的所有 Partition,进行状态初始化 |
在初始化的第二步,将会调用 triggerOnlinePartitionStateChange() 方法,为所有的状态为 NewPartition/OnlinePartition 的 Partition 进行 leader 选举,选举成功后的话,其状态将会设置为 OnlinePartition,调用的 Leader 选举方法是 OfflinePartitionLeaderSelector(具体实现参考链接)。
1 | //note: 这个方法是在 controller 选举后或 broker 上线或下线时时触发的 |
上面方法的目的是为尝试将所有的状态为 NewPartition/OnlinePartition 的 Partition 状态转移到 OnlinePartition,这个方法主要是做了两件事:
- 状态转移(这个在下面详细讲述);
- 发送相应的请求。
分区的状态转移
这里以要转移的 TargetState 区分做详细详细讲解,当 TargetState 分别是 NewPartition、OfflinePartition、NonExistentPartition 或者 OnlinePartition 时,副本状态机所做的事情。
TargetState: NewPartition
NewPartition 是 Partition 刚创建时的一个状态,其处理逻辑如下:
1 | //note: 如果该 Partition 的状态不存在,默认为 NonExistentPartition |
实现逻辑:
- 校验其前置状态,它有效的前置状态为 NonExistentPartition;
- 将该 Partition 的状态转移为 NewPartition 状态,并且更新到缓存中。
TargetState: OnlinePartition
OnlinePartition 是一个 Partition 正常工作时的状态,这个状态下的 Partition 已经成功选举出了 leader 和 isr 信息,其实现逻辑如下:
1 | //note: 判断 Partition 之前的状态是否可以转换为目的状态 |
实现逻辑:
- 校验这个 Partition 的前置状态,有效的前置状态是:NewPartition、OnlinePartition 或者 OfflinePartition;
- 如果前置状态是 NewPartition,那么为该 Partition 选举 leader 和 isr,更新到 zk 和 controller 的缓存中,如果副本没有处于 alive 状态的话,就抛出异常;
- 如果前置状态是 OnlinePartition,那么只是触发 leader 选举,在 OnlinePartition –> OnlinePartition 这种状态转移时,需要传入 leader 选举的方法,触发该 Partition 的 leader 选举;
- 如果前置状态是 OfflinePartition,同上,也是触发 leader 选举。
- 更新 Partition 的状态为 OnlinePartition。
对于以上这几种情况,无论前置状态是什么,最后都会触发这个 Partition 的 leader 选举,leader 成功后,都会触发向这个 Partition 的所有 replica 发送 LeaderAndIsr 请求。
TargetState: OfflinePartition
OfflinePartition 是这个 Partition 的 leader 挂掉时转移的一个状态,如果 Partition 转移到这个状态,那么就意味着这个 Partition 没有了可用 leader。
1 | // pre: partition should be in New or Online state |
实现逻辑:
- 校验其前置状态,它有效的前置状态为 NewPartition、OnlinePartition 或者 OfflinePartition;
- 将该 Partition 的状态转移为 OfflinePartition 状态,并且更新到缓存中。
TargetState: NonExistentPartition
NonExistentPartition 代表了已经处于 OfflinePartition 状态的 Partition 已经从 metadata 和 zk 中删除后进入的状态。
1 | // pre: partition should be in Offline state |
实现逻辑:
- 校验其前置状态,它有效的前置状态为 OfflinePartition;
- 将该 Partition 的状态转移为 NonExistentPartition 状态,并且更新到缓存中。
状态转移触发的条件
这里主要是看一下上面 Partition 各种转移的触发的条件,整理的结果如下表所示,部分内容会在后续文章讲解。
| TargetState | 触发方法 | 作用 |
|---|---|---|
| OnlinePartition | Controller 的 shutdownBroker() | 优雅关闭 Broker 时调用,因为要下线的节点是 leader,所以需要触发 leader 选举 |
| OnlinePartition | Controller 的 onNewPartitionCreation() | Partition 新建时,这个是在 Replica 已经变为 NewPartition 状态后进行的,为新建的 Partition 初始化 leader 和 isr |
| OnlinePartition | controller 的 onPreferredReplicaElection() | 对 Partition 进行最优 leader 选举,目的是触发 leader 选举 |
| OnlinePartition | controller 的 moveReassignedPartitionLeaderIfRequired() | 分区副本迁移完成后,1. 当前的 leader 不在 RAR 中,需要触发 leader 选举;2. 当前 leader 在 RAR 但是掉线了,也需要触发 leader 选举 |
| OnlinePartition | PartitionStateMachine 的 triggerOnlinePartitionStateChange() | 当 Controller 重新选举出来或 broker 有变化时,目的为了那些状态为 NewPartition/OfflinePartition 的 Partition 重新选举 leader,选举成功后状态变为 OnlinePartition |
| OnlinePartition | PartitionStateMachine 的 initializePartitionState() | Controller 初始化时,遍历 zk 的所有的分区,如果有 LeaderAndIsr 信息并且 leader 在 alive broker 上,那么就将状态转为 OnlinePartition。 |
| OfflinePartition | controller 的 onBrokerFailure() | 当有 broker 掉线时,将 leader 在这个机器上的 Partition 设置为 OfflinePartition |
| OfflinePartition | TopicDeletionManager 的 completeDeleteTopic() | Topic 删除成功后,中间会将该 Partition 的状态先转变为 OfflinePartition |
| NonExistentPartition | TopicDeletionManager 的 completeDeleteTopic() | Topic 删除成功后,最后会将该 Partition 的状态转移为 NonExistentPartition |
| NewPartition | Controller 的 onNewPartitionCreation() | Partition 刚创建时的一个中间状态 ,此时还没选举 leader 和设置 isr 信息 |
上面就是副本状态机与分区状态机的所有内容,这里只是单纯地讲述了一下这两种状态机,后续文章会开始介绍 Controller 一些其他内容,包括 Partition 迁移、Topic 新建、Topic 下线等,这些内容都会用到这篇文章讲述的内容。
