leaderId = getControllerID /* * We can get here during the initial startup and the handleDeleted ZK callback. Because of the potential race condition, * it's possible that the controller has already been elected when we get here. This check will prevent the following * createEphemeralPath method from getting into an infinite loop if this broker is already the controller. */ if(leaderId != -1) { debug("Broker %d has been elected as leader, so stopping the election process.".format(leaderId)) return amILeader }
try { val zkCheckedEphemeral = newZKCheckedEphemeral(electionPath, electString, controllerContext.zkUtils.zkConnection.getZookeeper, JaasUtils.isZkSecurityEnabled()) zkCheckedEphemeral.create() //note: 没有异常的话就是创建成功了 info(brokerId + " successfully elected as leader") leaderId = brokerId onBecomingLeader() //note: 成为了 controller } catch { case _: ZkNodeExistsException => //note: 在创建时,发现已经有 broker 提前注册成功 // If someone else has written the path, then leaderId = getControllerID
if (leaderId != -1) debug("Broker %d was elected as leader instead of broker %d".format(leaderId, brokerId)) else warn("A leader has been elected but just resigned, this will result in another round of election")
case e2: Throwable => //note: 抛出了其他异常,那么重新选举 controller error("Error while electing or becoming leader on broker %d".format(brokerId), e2) resign() } amILeader }
//note: 监控 controller 内容的变化 classLeaderChangeListenerextendsIZkDataListenerwithLogging{ /** * Called when the leader information stored in zookeeper has changed. Record the new leader in memory * @throws Exception On any error. */ @throws[Exception] defhandleDataChange(dataPath: String, data: Object) { val shouldResign = inLock(controllerContext.controllerLock) { val amILeaderBeforeDataChange = amILeader leaderId = KafkaController.parseControllerId(data.toString) info("New leader is %d".format(leaderId)) // The old leader needs to resign leadership if it is no longer the leader amILeaderBeforeDataChange && !amILeader }
/** * Called when the leader information stored in zookeeper has been delete. Try to elect as the leader * @throws Exception * On any error. */ //note: 如果之前是 controller,现在这个节点被删除了,那么首先退出 controller 进程,然后开始重新选举 controller @throws[Exception] defhandleDataDeleted(dataPath: String) { val shouldResign = inLock(controllerContext.controllerLock) { debug("%s leader change listener fired for path %s to handle data deleted: trying to elect as a leader" .format(brokerId, dataPath)) amILeader }
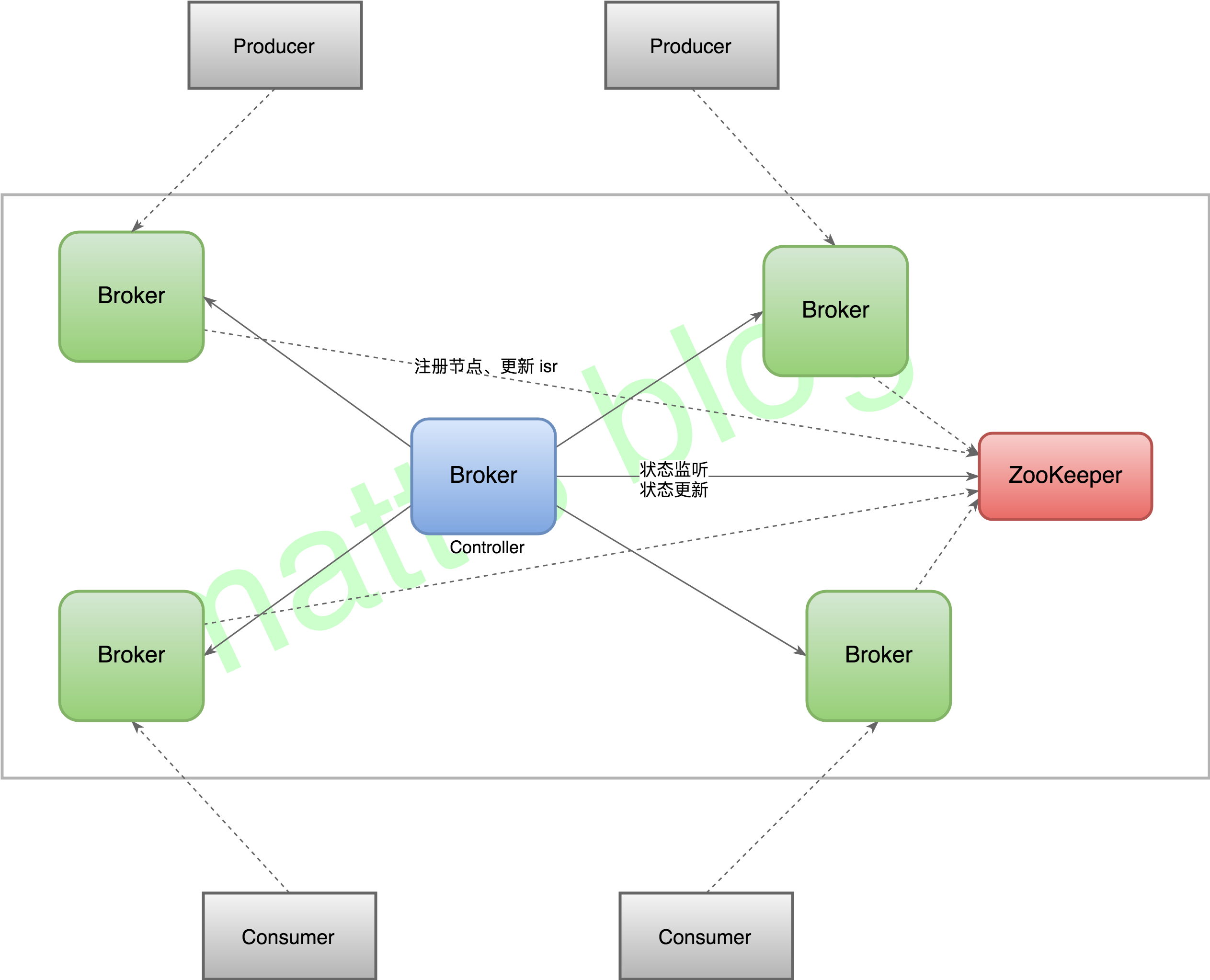
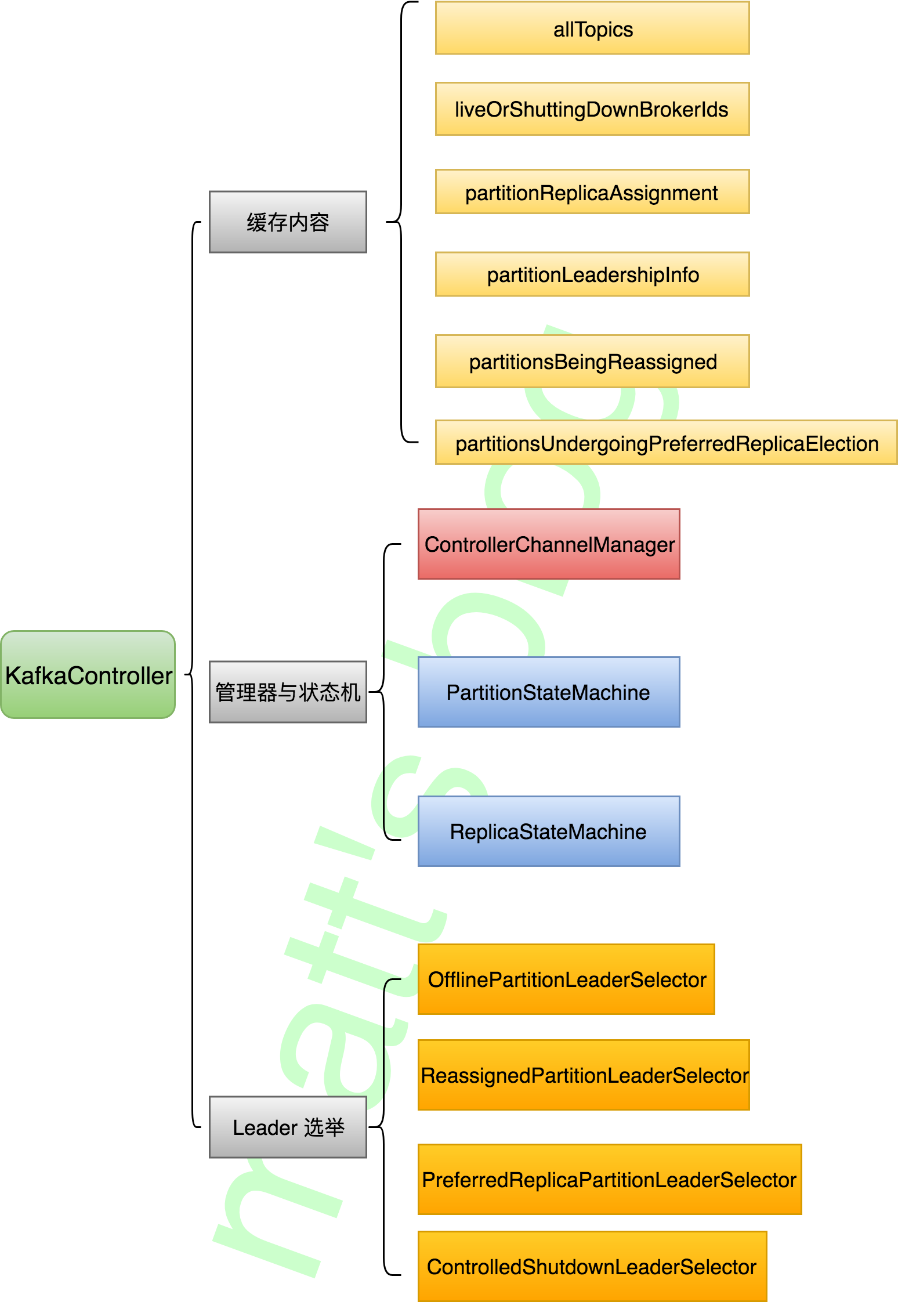
// We need to send UpdateMetadataRequest after the controller context is initialized and before the state machines // are started. The is because brokers need to receive the list of live brokers from UpdateMetadataRequest before // they can process the LeaderAndIsrRequests that are generated by replicaStateMachine.startup() and // partitionStateMachine.startup(). //note: 在 controller contest 初始化之后,我们需要发送 UpdateMetadata 请求在状态机启动之前,这是因为 broker 需要从 UpdateMetadata 请求 //note: 获取当前存活的 broker list, 因为它们需要处理来自副本状态机或分区状态机启动发送的 LeaderAndIsr 请求 sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
/** * The reassigned replicas are already in the ISR when selectLeader is called. */ //note: 当这个方法被调用时,要求新分配的副本已经在 isr 中了 defselectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = { //note: 新分配的 replica 列表 val reassignedInSyncReplicas = controllerContext.partitionsBeingReassigned(topicAndPartition).newReplicas val currentLeaderEpoch = currentLeaderAndIsr.leaderEpoch //note: 当前的 zk version val currentLeaderIsrZkPathVersion = currentLeaderAndIsr.zkVersion //note: 新分配的 replica 列表,并且其 broker 存活、且在 isr 中 val aliveReassignedInSyncReplicas = reassignedInSyncReplicas.filter(r => controllerContext.liveBrokerIds.contains(r) && currentLeaderAndIsr.isr.contains(r)) //note: 选择第一个作为新的 leader val newLeaderOpt = aliveReassignedInSyncReplicas.headOption newLeaderOpt match { caseSome(newLeader) => (newLeaderAndIsr(newLeader, currentLeaderEpoch + 1, currentLeaderAndIsr.isr, currentLeaderIsrZkPathVersion + 1), reassignedInSyncReplicas) caseNone => reassignedInSyncReplicas.size match { case0 => thrownewNoReplicaOnlineException("List of reassigned replicas for partition " + " %s is empty. Current leader and ISR: [%s]".format(topicAndPartition, currentLeaderAndIsr)) case _ => thrownewNoReplicaOnlineException("None of the reassigned replicas for partition " + "%s are in-sync with the leader. Current leader and ISR: [%s]".format(topicAndPartition, currentLeaderAndIsr)) } } } }
//note: 最优的 leader 选举策略(主要用于自动 leader 均衡,选择 AR 中第一个为 leader,前提是它在 isr 中,这样整个集群的 leader 是均衡的,否则抛出异常) //note: new leader = 第一个 replica(alive and in isr) //note: new isr = 当前 isr //note: 接收 LeaderAndIsr request 的 replica = AR classPreferredReplicaPartitionLeaderSelector(controllerContext: ControllerContext) extendsPartitionLeaderSelector withLogging{ this.logIdent = "[PreferredReplicaPartitionLeaderSelector]: "
defselectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = { //note: Partition 的 AR val assignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition) //note: preferredReplica,第一个 replica val preferredReplica = assignedReplicas.head // check if preferred replica is the current leader //note: 当前的 leader val currentLeader = controllerContext.partitionLeadershipInfo(topicAndPartition).leaderAndIsr.leader if (currentLeader == preferredReplica) { thrownewLeaderElectionNotNeededException("Preferred replica %d is already the current leader for partition %s" .format(preferredReplica, topicAndPartition)) } else { //note: 当前 leader 不是 preferredReplica 的情况 info("Current leader %d for partition %s is not the preferred replica.".format(currentLeader, topicAndPartition) + " Triggering preferred replica leader election") // check if preferred replica is not the current leader and is alive and in the isr //note: preferredReplica 是 alive 并且在 isr 中 if (controllerContext.liveBrokerIds.contains(preferredReplica) && currentLeaderAndIsr.isr.contains(preferredReplica)) { (newLeaderAndIsr(preferredReplica, currentLeaderAndIsr.leaderEpoch + 1, currentLeaderAndIsr.isr, currentLeaderAndIsr.zkVersion + 1), assignedReplicas) } else { thrownewStateChangeFailedException("Preferred replica %d for partition ".format(preferredReplica) + "%s is either not alive or not in the isr. Current leader and ISR: [%s]".format(topicAndPartition, currentLeaderAndIsr)) } } } }
defselectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = { val currentLeaderEpoch = currentLeaderAndIsr.leaderEpoch val currentLeaderIsrZkPathVersion = currentLeaderAndIsr.zkVersion
val currentLeader = currentLeaderAndIsr.leader
val assignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition) val liveOrShuttingDownBrokerIds = controllerContext.liveOrShuttingDownBrokerIds //note: 存活的 AR val liveAssignedReplicas = assignedReplicas.filter(r => liveOrShuttingDownBrokerIds.contains(r))
//note: 从当前 isr 中过滤掉正在 shutdown 的 broker val newIsr = currentLeaderAndIsr.isr.filter(brokerId => !controllerContext.shuttingDownBrokerIds.contains(brokerId)) liveAssignedReplicas.find(newIsr.contains) match { //note: find 方法返回的是第一满足条件的元素,AR 中第一个在 newIsr 集合中的元素被选为 leader caseSome(newLeader) => debug("Partition %s : current leader = %d, new leader = %d".format(topicAndPartition, currentLeader, newLeader)) (LeaderAndIsr(newLeader, currentLeaderEpoch + 1, newIsr, currentLeaderIsrZkPathVersion + 1), liveAssignedReplicas) caseNone => thrownewStateChangeFailedException(("No other replicas in ISR %s for %s besides" + " shutting down brokers %s").format(currentLeaderAndIsr.isr.mkString(","), topicAndPartition, controllerContext.shuttingDownBrokerIds.mkString(","))) } } }