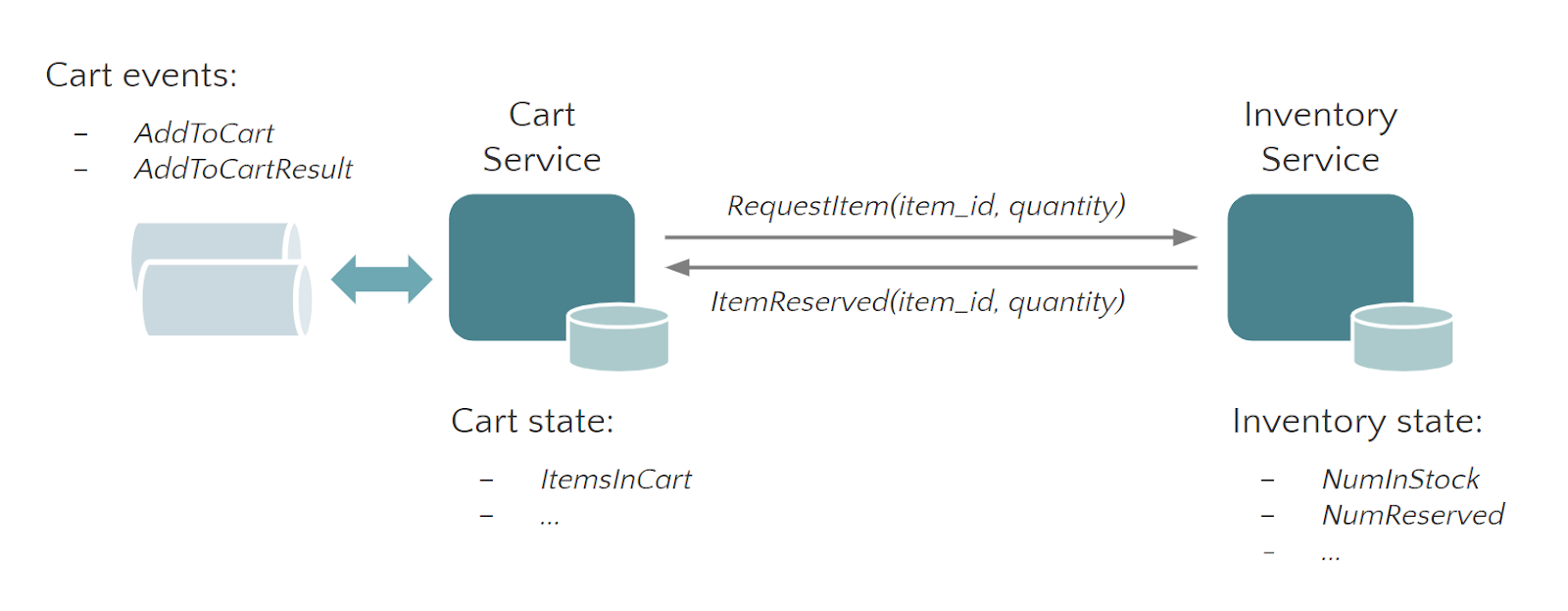
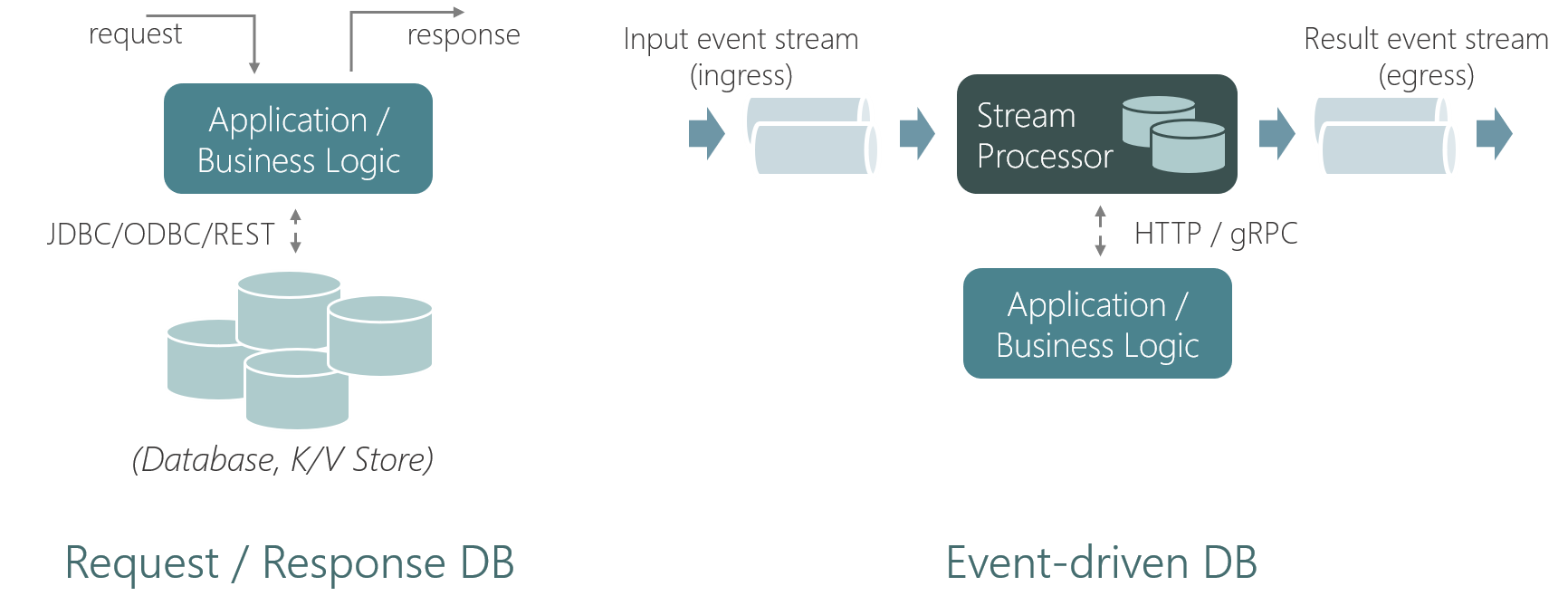
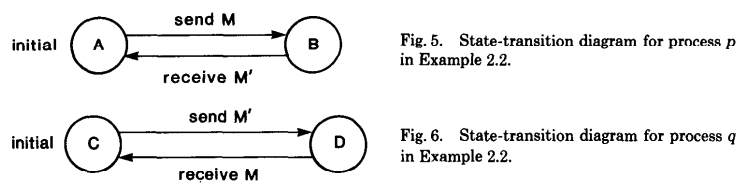
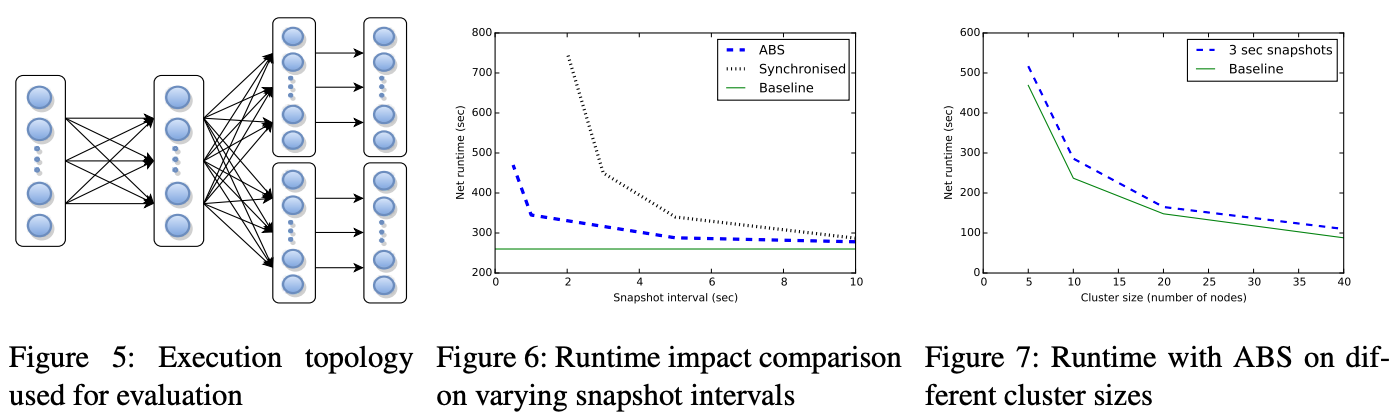
应用中的所有 Msg 都是通过逻辑地址发往相应的 Function 实例,这个逻辑地址会包含 Function Type 及 Intance ID 信息(如:cart:Kim、inventory:socks)。本应用中发送到 Ingress 的数据类型是 AddToCart,它表示是一个将相应的商品加到用户的购物车中的操作,发送给 Egress 的类型是 AddToCartResult,它表示的是这个将商品添加到用户购物车中操作的结果(可能会因为库存情况加入失败)。
Type type = 1; string item_id = 2; int32 quantity = 3; }
// --------------------------------------------------------------------- // Shopping cart state type // ---------------------------------------------------------------------
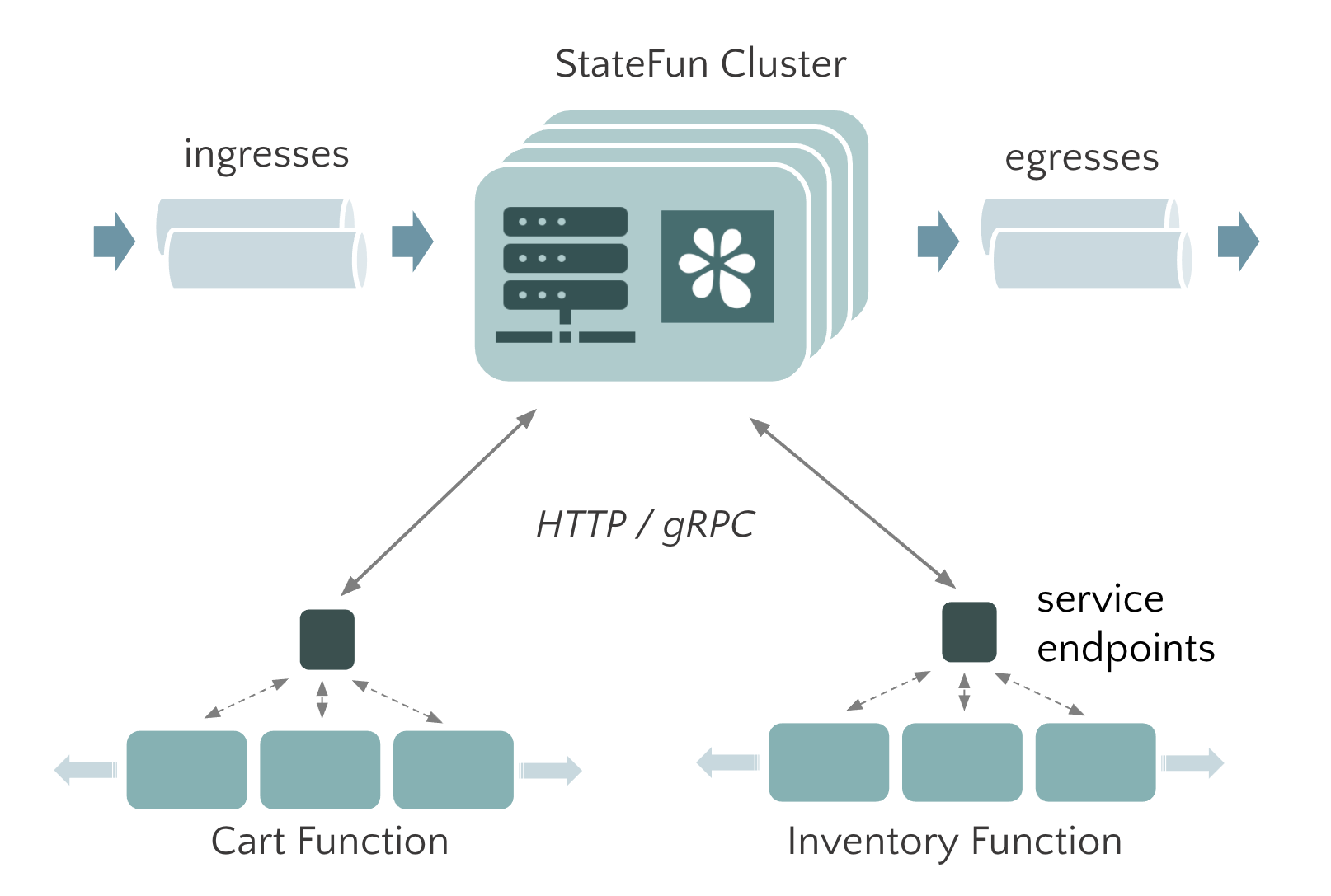
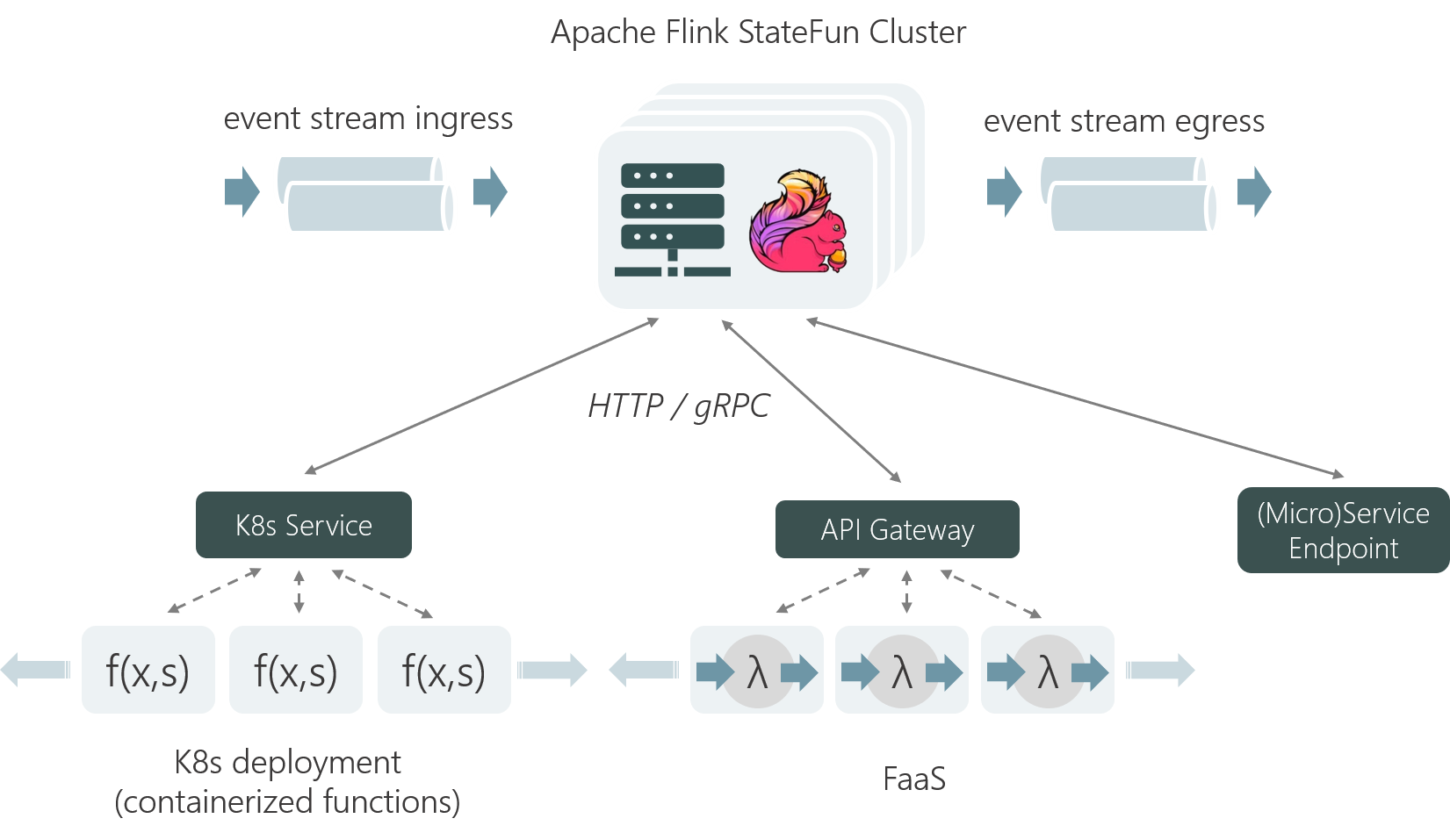
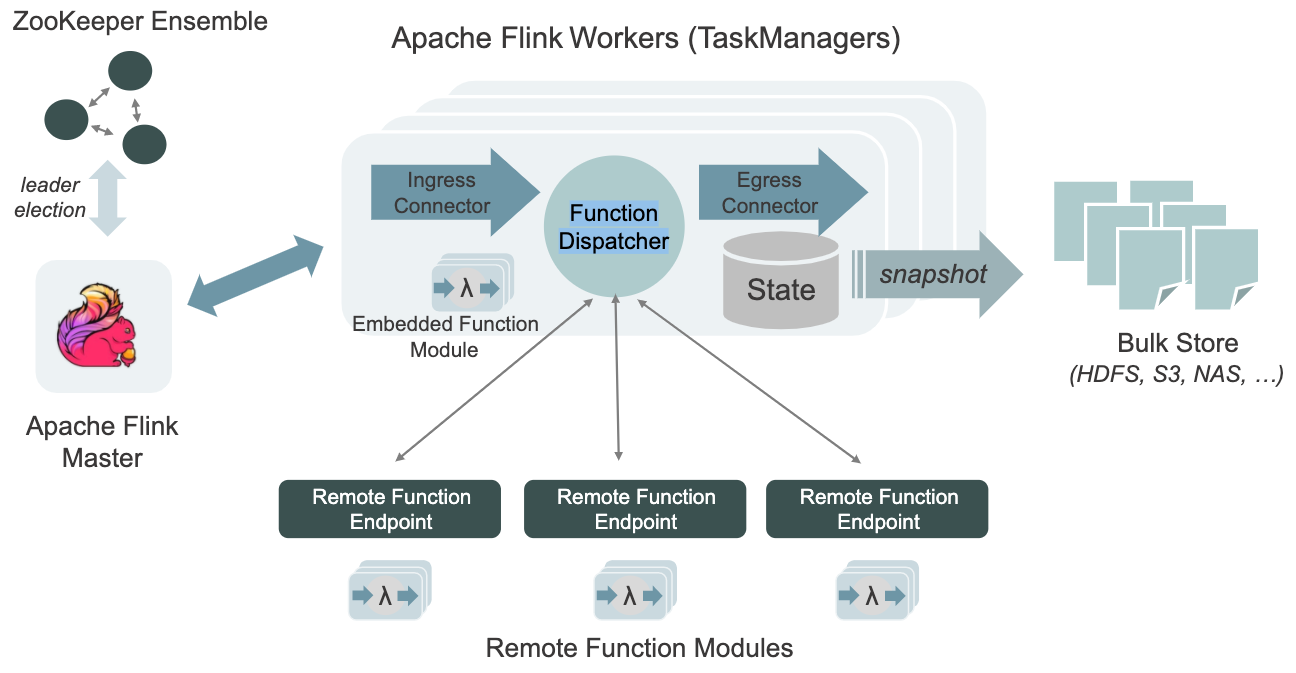
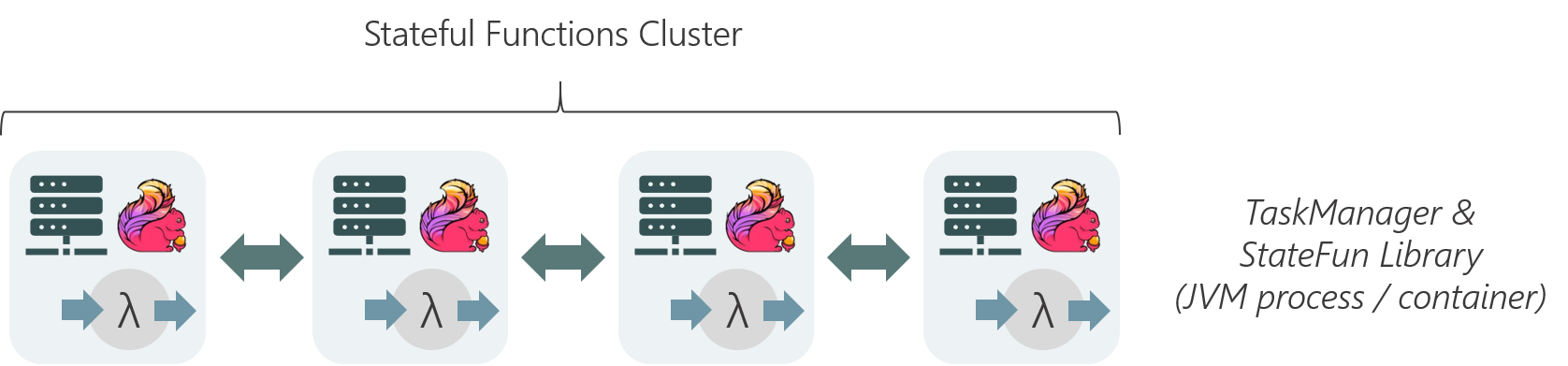
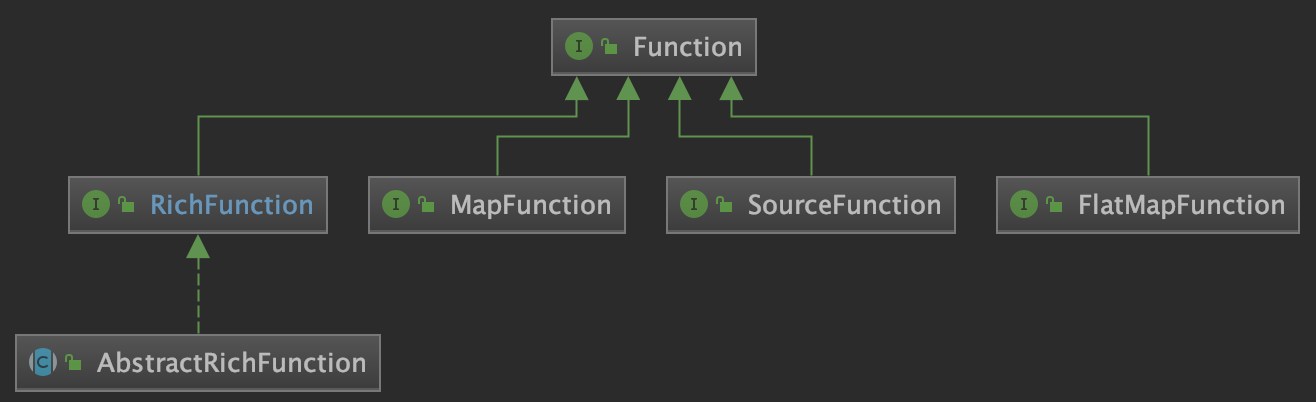
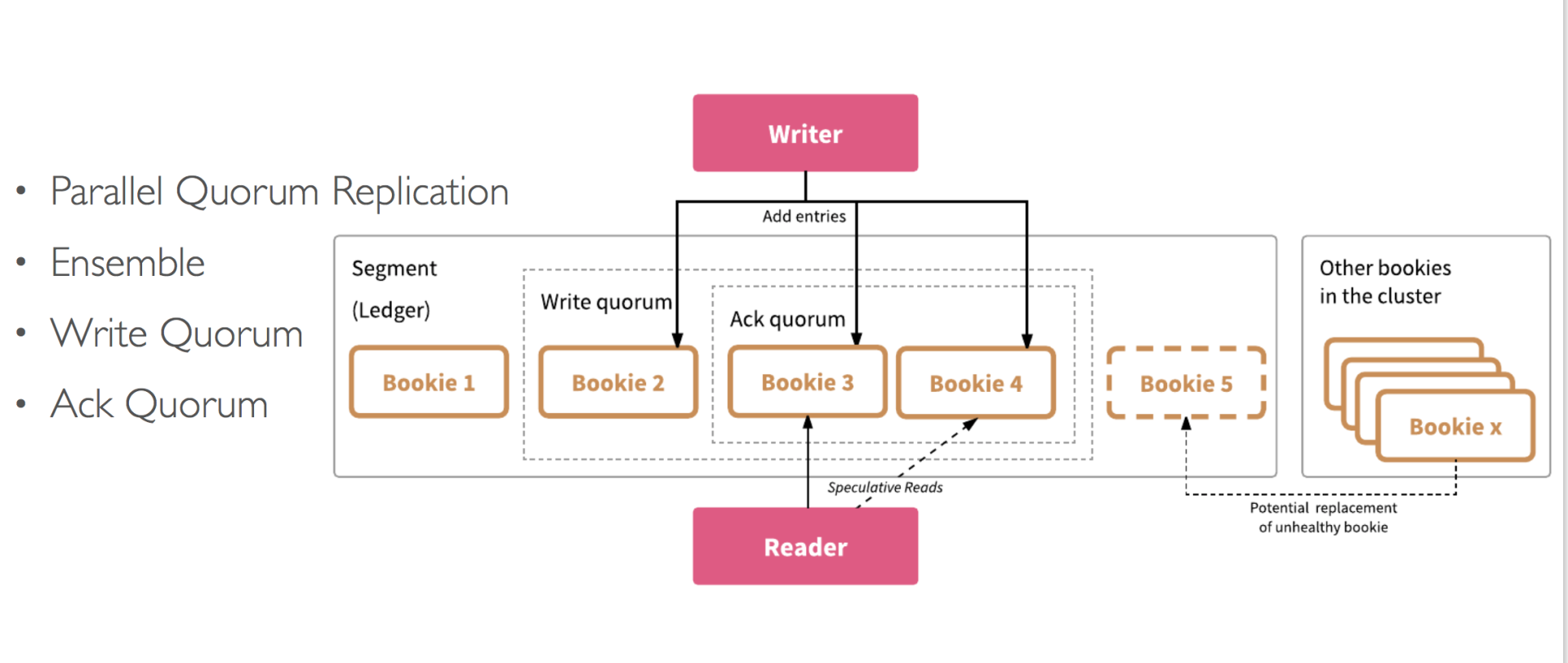
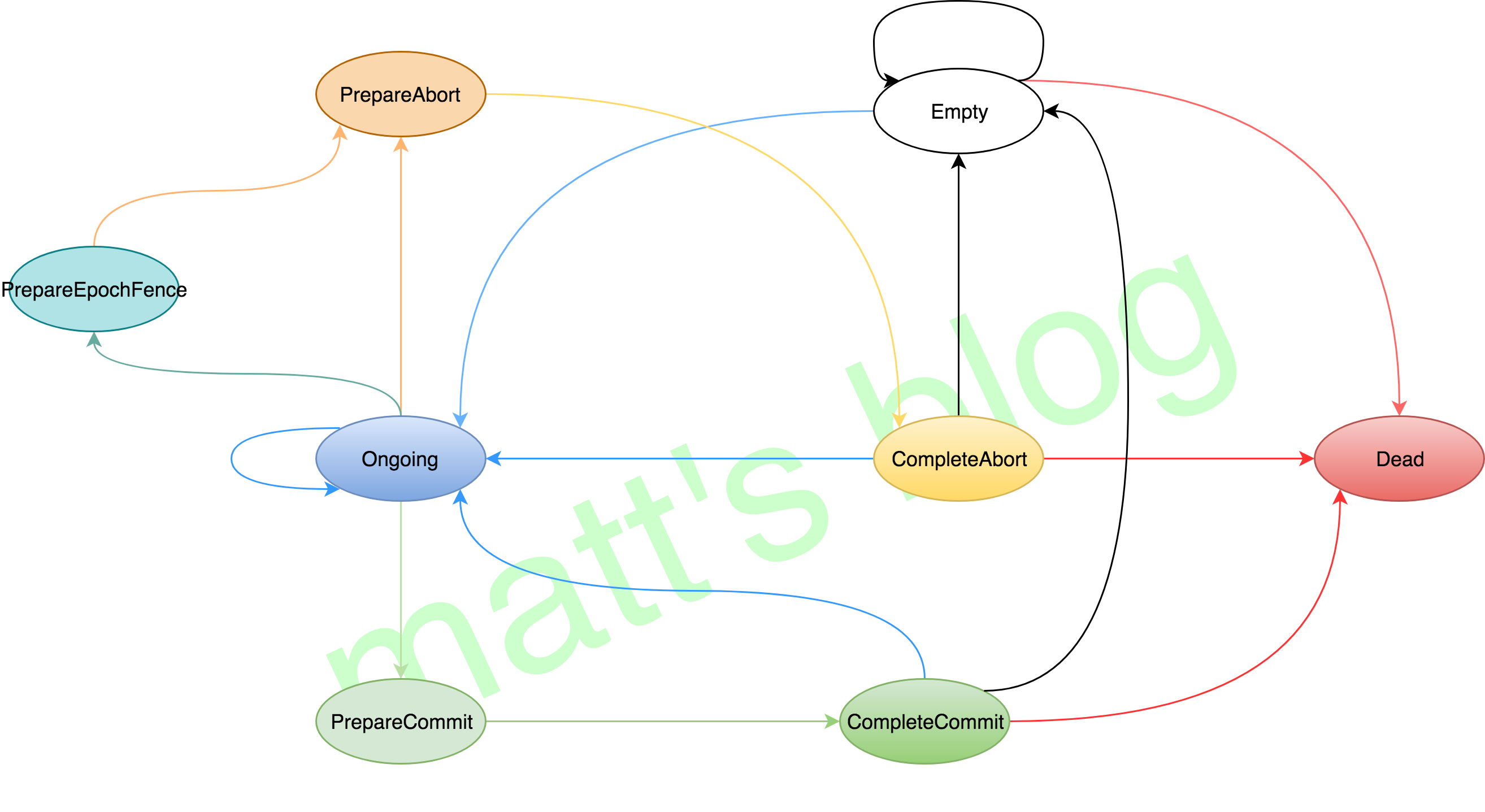
StateFun Runtime 是构建在 Apache Flink 之上,并且基于 Flink 的底层机制 —— co-location of state and messaging 来保证一致性和容错性。在一个 StateFun 应用中,所有 messages 的路由转发都是经过 StateFun Cluster 的,包括从 Ingress 中发送的数据、Functions 之间传输的数据以及 Function 发往 Egress 的数据。而且,Function 的 state 都是在 StateFun Cluster 中维护的,如同 Flink 应用一样,StateFun Cluster 中 messages 与 Function State 是 co-partitioned 的,所以计算都是本地 state 访问,而且都是没有任何负作用的原子操作。
这里举个例子,假设一条 target 逻辑地址为 (cart, "Kim") 的 message 经过 StateFun Cluster 路由转发,这个逻辑地址将被用做数据传输和 state 的 partition key(对应的 Flink 作业中就是 keyby 操作中的 key 值),这样的话,StateFun Cluster 接收到的数据都具有本地 state 可用性。与 Flink 相比,StateFun 的区别在于实际的计算逻辑不会发生在 StateFun Cluster Partitions 中,而是由远程 Function Service 来触发。那么 StateFun 是如何做到将 message 路由转发到远程 Function Service、并且提供【如同 state 和计算都在一起的一致性保证的】 state 访问的呢?
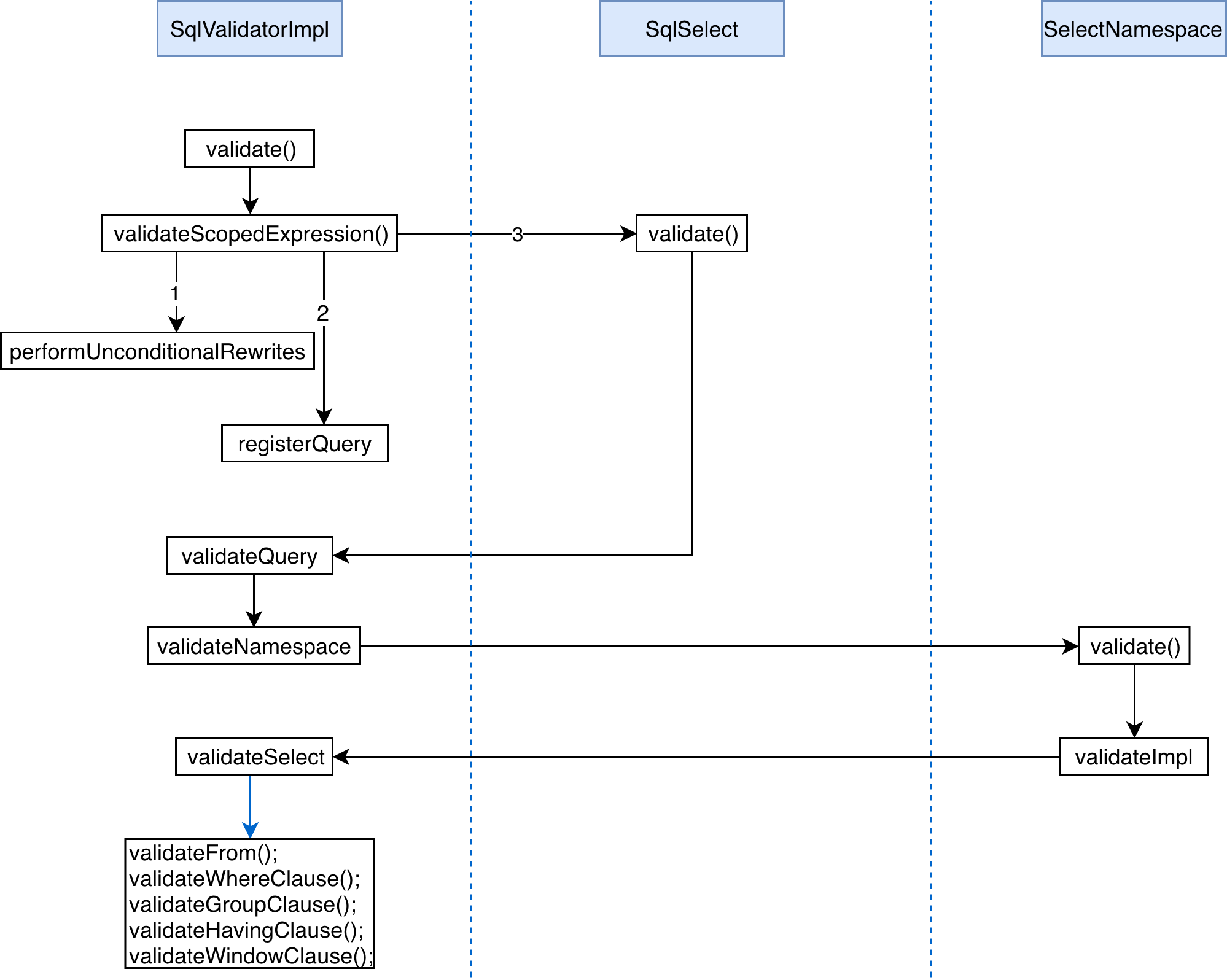
Remote Invocation Request-Reply Protocol
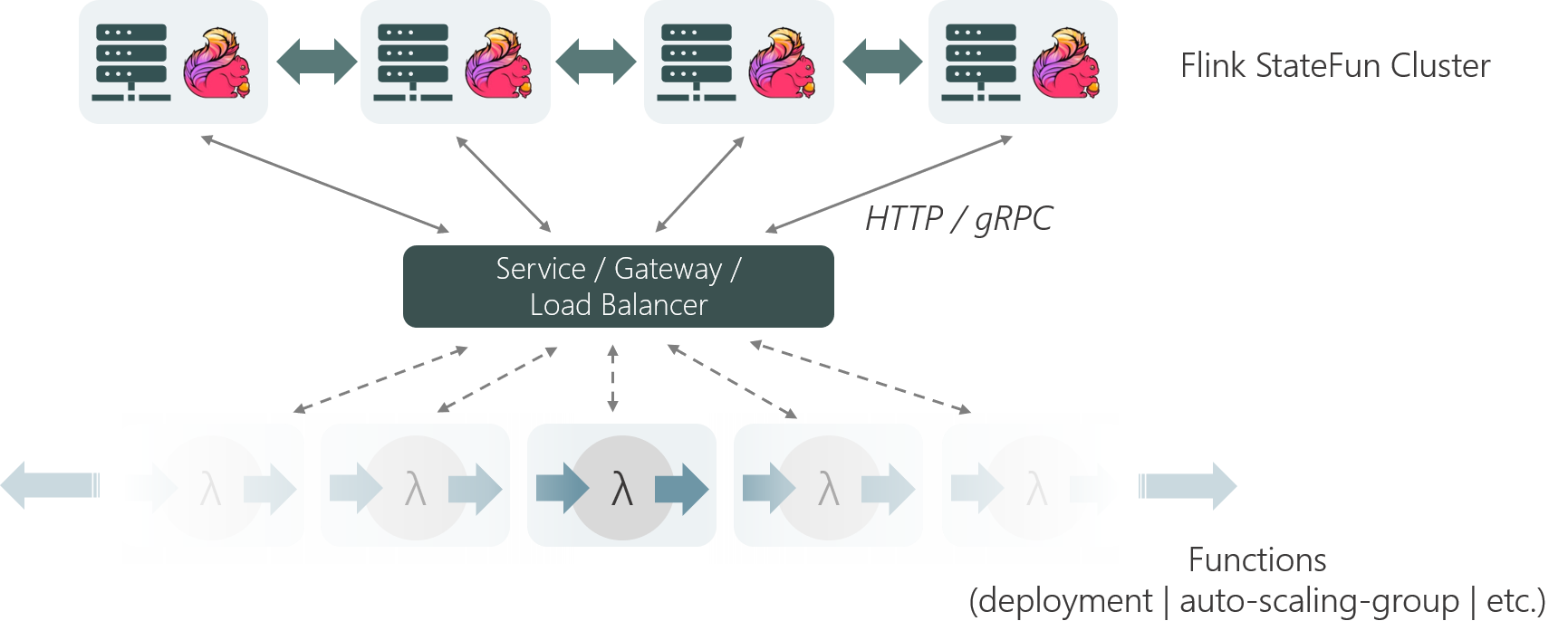
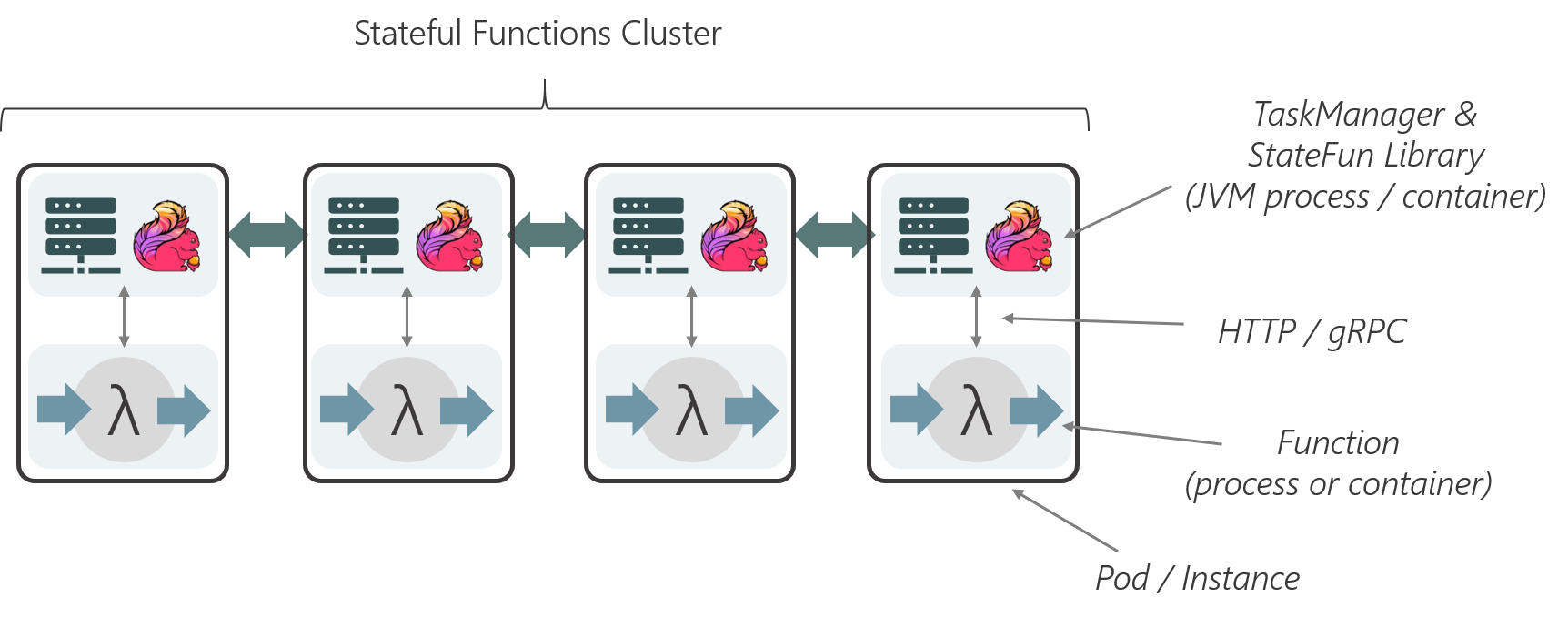
StateFun Cluster Partition 与 Function 的交互使用的是一个简洁、定义优雅的 request-reply 协议,如下图所示。一旦 Cluster Partition 接收到相应的 message,就会通过 HTTP 请求根据 target 逻辑地址将其发送到相应的 target Function Service 中。请求的 body 中会包含 input events 和这个 Function 计算需要的状态信息(从本地获取),在 Function 处理完请求后,会将需要返回的结果集合及所有变化的 state 作为 Service Response 都发送回 StateFun Cluster。当 StateFun Cluster Partition 接收到 Response 后,所有的 state 变化都会被写会到本地 State 中,message 会根据 target 逻辑地址路由转发到其他 Cluster Partition 中,触发其他的 Function 调用。
StateFun Runtime 端会保证在任何时刻,每条 event(如 (cart, "Kim"))只会进行一次触发调用,并且每个实体的触发都是串行进行的(可以理解为一个 StateFun Cluster Partition 上一个 Function 的触发操作都是串行的),如果对于一个实体来说,一个 Function 正在触发,那么新到的数据将会被缓存在 state 中,只有正在进行的触发结束后才能处理后面的请求。另外,因为请求是串行发送,它保证了每个请求都是完全隔离的,并且由于一个请求会将需要的所有信息都放在请求中,所以 Function 的触发是完全幂等的操作(这可以原生地避免 Function 在调用故障时可能会出现的一致性问题)。
关于容错机制,所有由 StateFun Cluster 管理的 Function state 会利用 Flink 原生的分布式快照机制周期性、异步地产生 Checkpoint,并且存储到 HDFS/GCS 这类的远程文件系统。这些 Checkpoint 会包含这个应用所有 Function 的全局一致性状态快照,并且包括 Ingress 中的 offset 信息和 Egress 中正在进行的事务状态信息。如果应用因为某些异常而挂掉,系统会从最新一次成功的 Checkpoint 中恢复,所有 Function 的状态信息都会被恢复、在 Checkpoint 与系统 Crash 之间的 event 也都会按照之前同样的逻辑进行处理,就好像失败从未发生一样。
Step-by-step walkthrough of function invocations
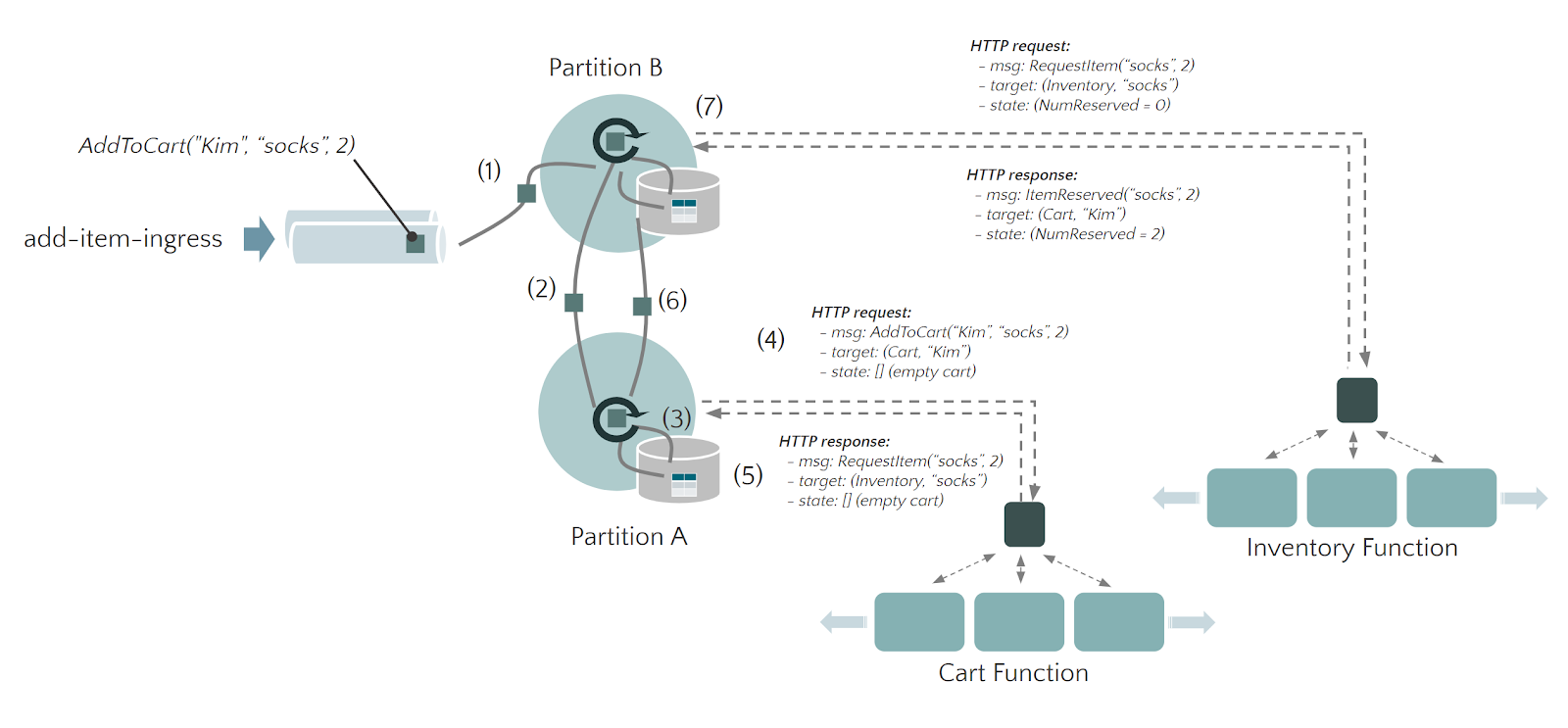
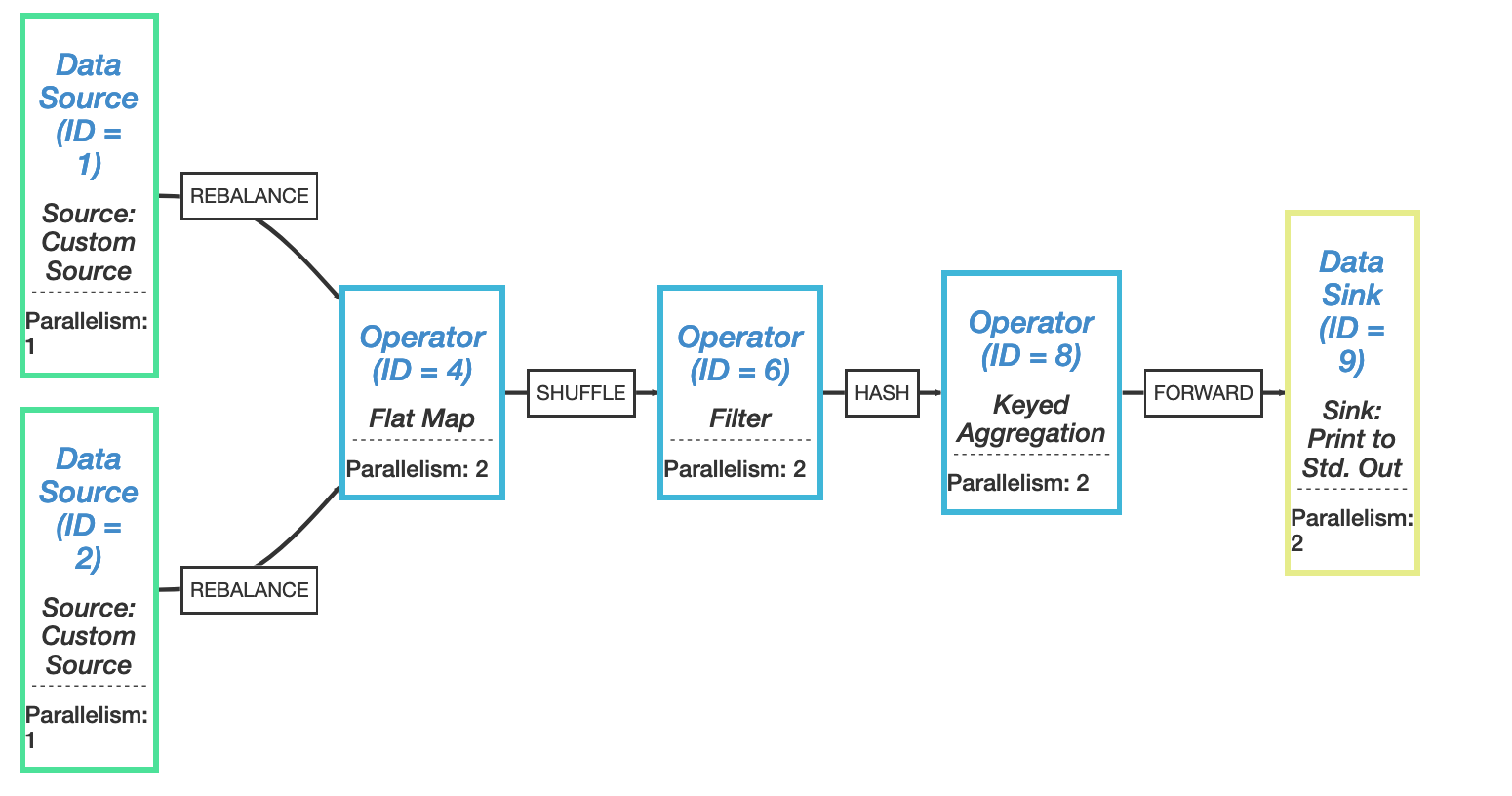
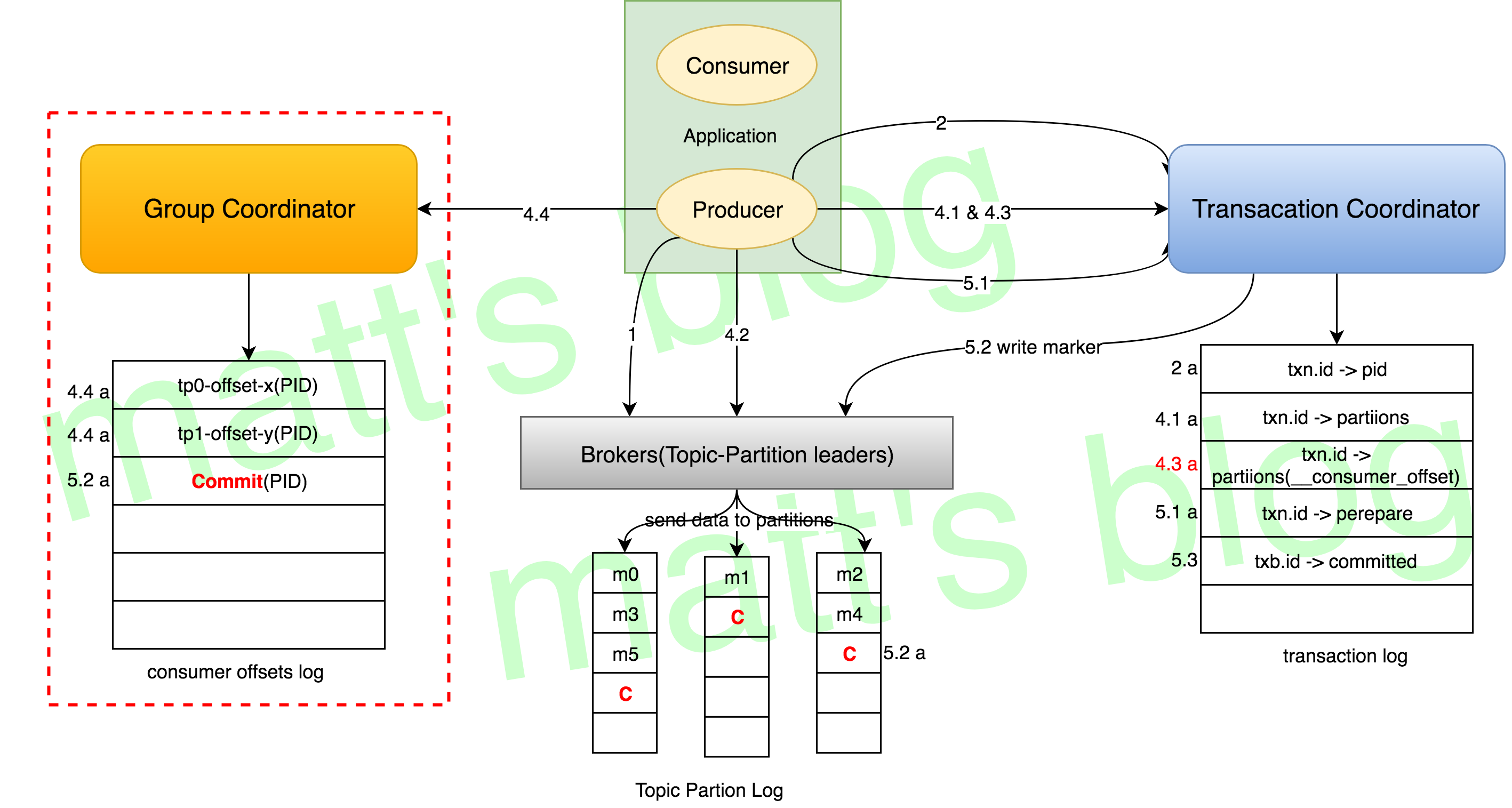
在这一小节,通过上面那个购物车的示例,来看下一条真实的 event 是如何在 StateFun Cluster 与 Function 之间传递的。顾客 Kim 想将 2 双袜子(sock)添加到其购物车中,这条 event 触发的一系列操作如下图所示:
结合上图,下面一步步来看下这条 event 的处理过程:
一条 Event AddToCart("Kim", "socks", 2) 从 Ingress Partition 中发送出来 (1),在这个应用中,Ingress event router 配置的 Function Type 是 Cart Function,并且使用 user ID Kim 作为 Instance ID。Function Type 和 Instance ID 它们会确定这个 event 的 target 逻辑地址((cart:Kim));
这里假设这条 event 是被 StateFun partition B 读取到的,但是 (cart:Kim) 的地址实际上应该路由到 partition A,因此,这条 event 会先被路由到 partition A 中 (2);
StateFun partition A 接收到这条 event 后开始做相应的处理:
首先,先从本地状态中获取 (cart:Kim) 的状态信息 —— Kim 购物车中已经存在商品列表 (3);
StateFun Runtime 会通过一个 HTTP Client 向 Cart Function Service 发送请求 (4),这个请求会包含 AddToCart("Kim", "socks", 2) 数据及当前 (cart:Kim) 的状态信息(这里要注意的是,每个请求的路由转发,都会将这个状态信息作为请求的一部分发送到 Function Service 中,这是一个比较有意思的设计);
远程 Cart Function Service 在接收到数据后,会尝试查询一下库存状态(通过 Inventory Function Service 来查询),因此,它会返回一个 target 逻辑地址为 (inventory:socks) 的 RequestItem("socks", 2) 请求。在这里,经过 Cart Function Service 处理后的任何状态变化都会随着请求返回给 StateFun Cluster 中 (5);
// forward 的方法说明 /** * Forwards the message as an input to a downstream function, addressed by a specified {@link * FunctionType} and the functions unique id within its type. * * @param functionType the target function's type. * @param id the target function's unique id. * @param message the message being forwarded. */ defaultvoidforward(FunctionType functionType, String id, T message){ forward(new Address(functionType, id), message); }
// pull the configured kafka broker address, or default if none was passed. String kafkaAddress = globalConfiguration.getOrDefault(KAFKA_KEY, DEFAULT_KAFKA_ADDRESS); GreetingIO ioModule = new GreetingIO(kafkaAddress);
// bind an ingress to the system along with the router binder.bindIngress(ioModule.getIngressSpec()); binder.bindIngressRouter(GreetingIO.GREETING_INGRESS_ID, new GreetRouter());
// bind an egress to the system binder.bindEgress(ioModule.getEgressSpec());
// bind a function provider to a function type // note: provider 可以决定这个 function 交互方式,可以使 HTTP 或 GRPC 的形式 binder.bindFunctionProvider(GreetStatefulFunction.TYPE, unused -> new GreetStatefulFunction()); } }
// IO 模块的初始化,这里初始化了 Ingree 和 Egress 部分 // pull the configured kafka broker address, or default if none was passed. String kafkaAddress = globalConfiguration.getOrDefault(KAFKA_KEY, DEFAULT_KAFKA_ADDRESS); GreetingIO ioModule = new GreetingIO(kafkaAddress);
// 绑定 Ingress 模块,并设置相应的 Router,为 Ingress 数据源指定下游 Function 信息 // bind an ingress to the system along with the router binder.bindIngress(ioModule.getIngressSpec()); binder.bindIngressRouter(GreetingIO.GREETING_INGRESS_ID, new GreetRouter());
// 绑定一个 Egress // bind an egress to the system binder.bindEgress(ioModule.getEgressSpec());
// 绑定相应的 Function,并指明这个 Function 的交互方式 // bind a function provider to a function type binder.bindFunctionProvider(GreetStatefulFunction.TYPE, unused -> new GreetStatefulFunction()); } }
StateFun 中比较核心的地方是 State 的使用,下面来看下这个示例中 Function 的实现:
/** * The function type is the unique identifier that identifies this type of function. The type, in * conjunction with an identifier, is how routers and other functions can use to reference a * particular instance of a greeter function. * * <p>If this was a multi-module application, the function type could be in different package so * functions in other modules could message the greeter without a direct dependency on this class. */ // 定义这个 Function 的 FunctionType staticfinal FunctionType TYPE = new FunctionType("apache", "greeter");
/** * The persisted value for maintaining state about a particular user. The value returned by this * field is always scoped to the current user. seenCount is the number of times the user has been * greeted. */ // 声明持久化状态信息 @Persisted privatefinal PersistedValue<Integer> seenCount = PersistedValue.of("seen-count", Integer.class);
privatestatic String greetText(String name, int seen){ switch (seen) { case0: return String.format("Hello %s ! \uD83D\uDE0E", name); case1: return String.format("Hello again %s ! \uD83E\uDD17", name); case2: return String.format("Third time is a charm! %s! \uD83E\uDD73", name); case3: return String.format("Happy to see you once again %s ! \uD83D\uDE32", name); default: return String.format("Hello at the %d-th time %s \uD83D\uDE4C", seen + 1, name); } } }
StateFun API 是非常简洁的,在使用 State 时,只需要通过 Persisted 注解修饰即可,否则不会保存到 Flink State 中,也就不会进行容错,在底层的实现上,它通过反射来找到一个 Function 中声明的变量信息,并将其注册到 Flink State 中,如果不通过注解修饰,就无法获取这个 State 变量。
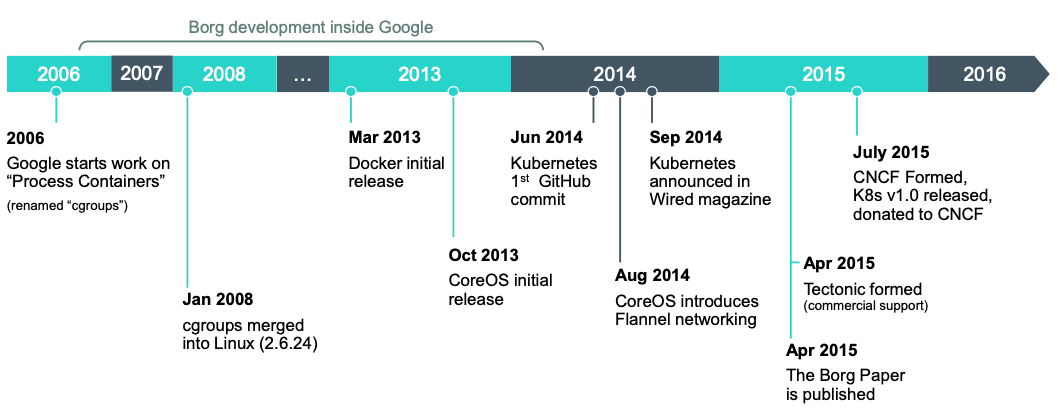
Kubernetes(来自希腊语,意为 “舵手” 或 “飞行员”)是由 Joe Beda、Brendan Burns 和 Craig McLuckie 创立,而后 Google 的其他几位工程师,包括 Brian Grant 和 Tim Hockin 等加盟共同研发,并由 Google 在 2014 年首次对外宣布。Kubernetes 的开发和设计都深受 Google 内部系统 Borg 的影响,事实上,它的许多顶级贡献者之前也是 Borg 系统的开发者。
水平扩展(可扩展):支持通过简单命令或 UI 手动水平扩展,以及基于 CPU 等资源负载率的自动水平扩展机制;
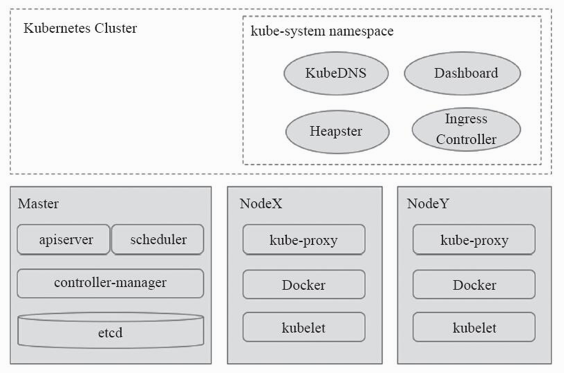
服务发现和负载均衡:Kubernetes 通过其附加组件之一的 KubeDNS(或 CoreDNS)为系统内置了服务发现功能,它会为每个 Service 配置 DNS 名称,并允许集群内的客户端直接使用此名称发出访问请求,而 Service 则通过 iptables 或 ipvs 内建了负载均衡机制;
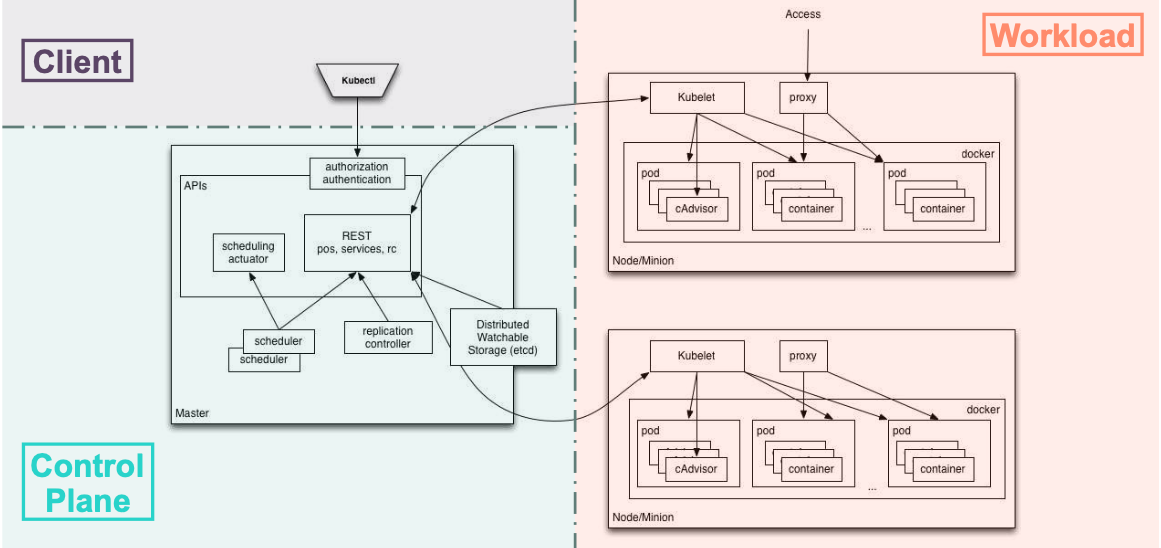
kubelet: 它是运行于工作节点之上的守护进程,负责容器的生命周期,也负责 Volume 和 网络的管理,它从 API Server 接收关于 Pod 对象的配置信息并确保它们处于期望的状态,kubelet 会在 API Server 上注册当前工作节点,定期向 Master 汇报节点资源使用情况,并通过 cAdvisor 监控容器和节点的资源占用状况;
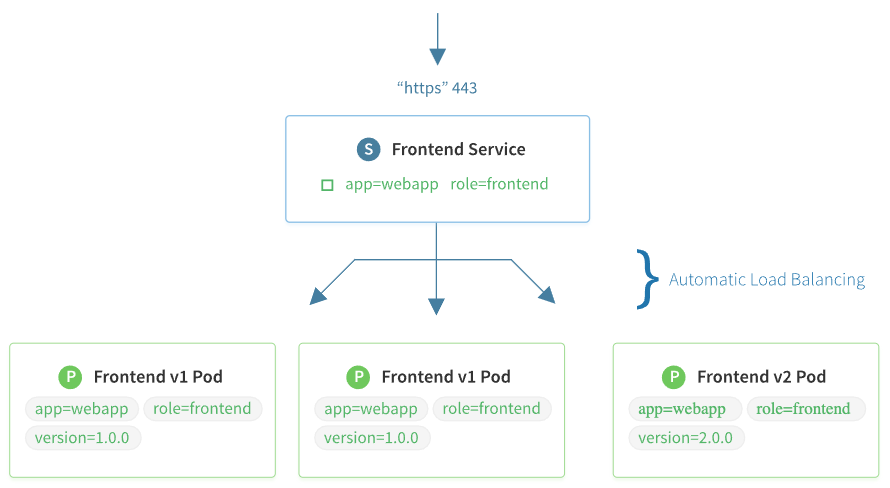
Service 是对一组提供相同功能的 Pods 的抽象,并为它们提供一个统一的入口,借助 Service,应用可以方便的实现服务发现与负载均衡,并实现应用的零宕机升级,Service 通过标签来选取服务后端,一般配合 ReplicaSet(简称 RS)或者 Deployment 来保证后端容器的正常运行。这些匹配标签的 Pod IP 和端口列表组成 endpoints,由 kube-proxy 负责将服务 IP 负载均衡到这些 endpoints 上,如下图所示(图片来自 Overview of a Service):
关于 Service,个人的理解是,它只是一种抽象,通过 label(资源标签)绑定到对应的 RC 和 Deployment 上,它是不会创建 Pod 的,Pod 还是由 RS 或 Deployment 创建的。下面是一个示例,这个 Service 将服务的 80 端口转发到 default namespace 中带有标签 run=nginx 的 Pod 的 80 端口上。
动态分支预测:根据指令的不同及历史信息(存储在一张分支历史表中 —— Branch History Table)作出相应的预测,常见的有 1-bit/n-bit 动态预测;
协同分支预测:利用代码中分支跳转指令之间的关联关系,提高分支预测的准确率。
Java 中的虚函数调用
Java 本身没有虚函数的概念,它在 C++ 中是最常见的。在 C++ 中,虚函数通过 virtual 关键字定义,实现在类的继承当中,编译器通过判断对象的类型,在调用函数时,执行对应的函数。Java 中并没有显式去定义虚函数的概念,Java 中实际上每个函数都默认是一个虚函数(声明 final 关键字的函数除外),比如下面示例中 eat() 方法。
publicclassAnimal{ publicvoideat(){ System.out.println("I eat like a generic Animal."); } publicclassDogextendsAnimal{ publicvoideat(){ System.out.println("I eat like a dog!"); } } publicclassCatextendsAnimal{ publicvoideat(){ System.out.println("I eat like a cat!"); } } publicstaticvoidmain(String[] args){ List<Animal> animals = new LinkedList<Animal>();
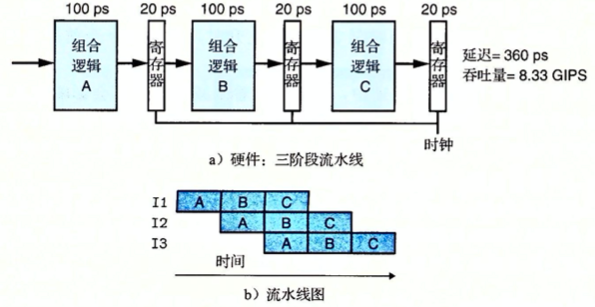
到这里,相信大家已经对 CPU 的流水线机制及 CPU 的分支预测技术有了一定的了解。回到 code 上,如果代码里充满着各种不可预知的条件跳转指令,将会极大影响 CPU 的执行效率,数据库中采用的 Volcano-style execution engine(火山执行引擎)在代码中充满着各种虚函数调用(详细机制在后面内容中再介绍),在编译器中,虚函数需要调用查找虚函数表,并且虚函数调用是一个非直接跳转逻辑,在这个逻辑中,最大的代价是可能导致错误的 CPU 分支预测,一次错误的分支预测会导致需要 10 几个周期的系统开销。
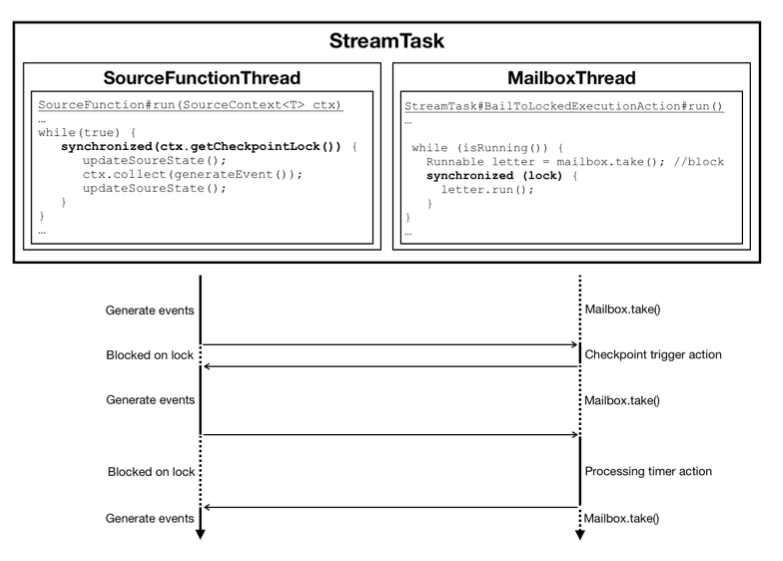
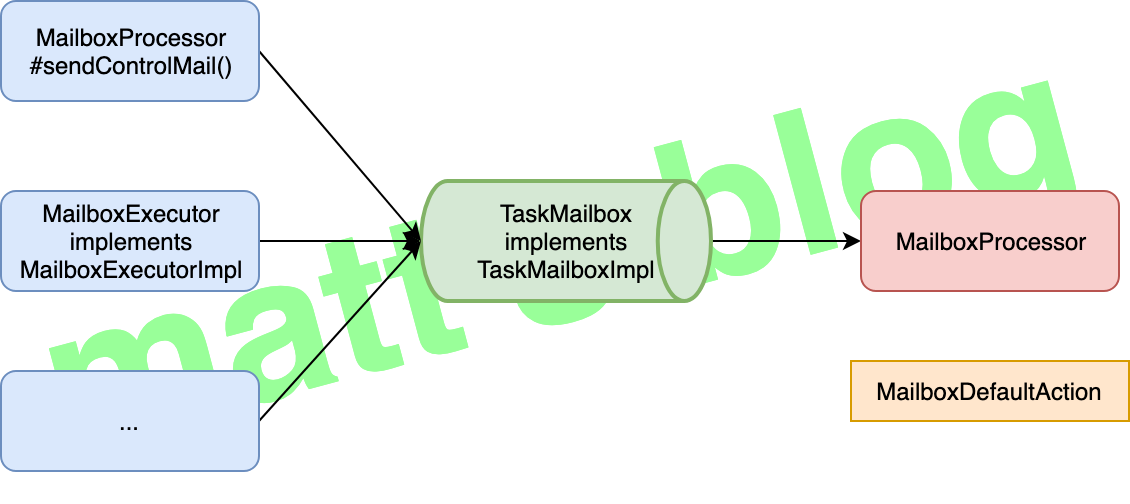
BlockingQueue<Runnable> mailbox = ... voidrunMailboxProcessing(){ //TODO: can become a cancel-event through mailbox eventually Runnable letter; while (isRunning()) { while ((letter = mailbox.poll()) != null) { letter.run(); letter.run(); } defaultAction(); } } voiddefaultAction(){ // e.g. event-processing from an input }
// final check to exit early before starting to run if (canceled) { thrownew CancelTaskException(); }
// let the task do its work isRunning = true; runMailboxLoop();
// if this left the run() method cleanly despite the fact that this was canceled, // make sure the "clean shutdown" is not attempted if (canceled) { thrownew CancelTaskException(); }
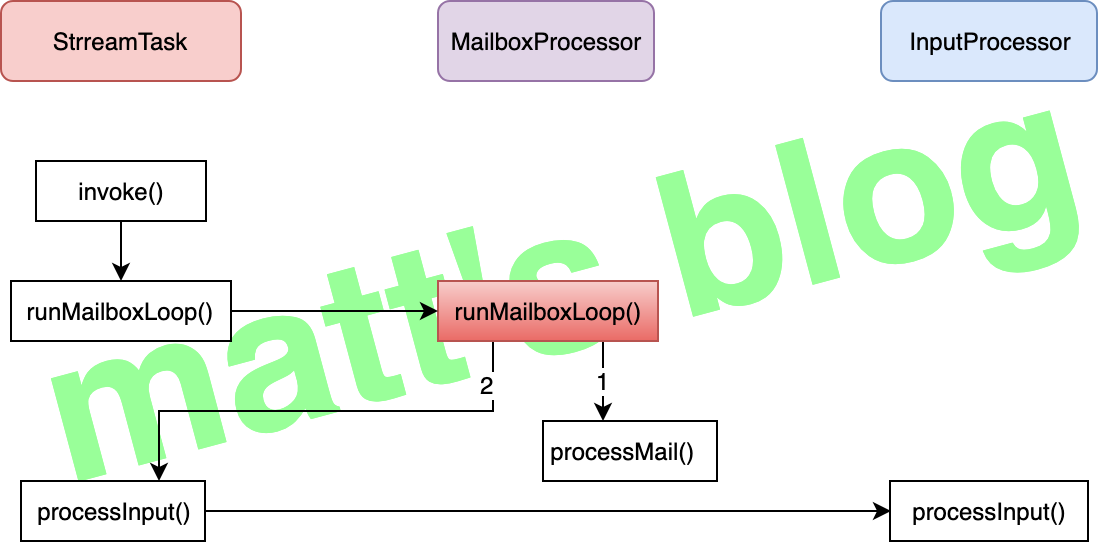
//org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor /** * Runs the mailbox processing loop. This is where the main work is done. * note: mailbox 处理核心流程 */ publicvoidrunMailboxLoop()throws Exception {
final TaskMailbox localMailbox = mailbox;
Preconditions.checkState( localMailbox.isMailboxThread(), "Method must be executed by declared mailbox thread!");
//note: MailBox 的状态必须是 OPEN,才能继续循环 assert localMailbox.getState() == TaskMailbox.State.OPEN : "Mailbox must be opened!";
final MailboxController defaultActionContext = new MailboxController(this);
while (processMail(localMailbox)) { //note: 如果有 mail 需要处理,这里会进行相应的处理,处理完才会进行下面的 event processing //note: 进行 task 的 default action,也就是调用 processInput() mailboxDefaultAction.runDefaultAction(defaultActionContext); // lock is acquired inside default action as needed } }
上面的方法中,最关键的有两个地方:
processMail(): 它会检测 MailBox 中是否有 mail 需要处理,如果有的话,就做相应的处理,一直将全部的 mail 处理完才会返回,只要 loop 还在进行,这里就会返回 true,否则会返回 false;
// Against the usual contract of this method, this implementation is not step-wise but blocking instead for // compatibility reasons with the current source interface (source functions run as a loop, not in steps). sourceThread.setTaskDescription(getName()); sourceThread.start(); sourceThread.getCompletionFuture().whenComplete((Void ignore, Throwable sourceThreadThrowable) -> { if (sourceThreadThrowable == null || isFinished) { //note: sourceThread 完成后,没有抛出异常或 task 完成的情况下 mailboxProcessor.allActionsCompleted(); } else { //note: 没有完成但结束了或者抛出异常的情况下 mailboxProcessor.reportThrowable(sourceThreadThrowable); } }); }
/** * Runnable that executes the the source function in the head operator. * note: source 产生 data 的一个线程 */ privateclassLegacySourceFunctionThreadextendsThread{
LegacySourceFunctionThread() { this.completionFuture = new CompletableFuture<>(); }
@Override publicvoidrun(){ try { //note: 调用 source Operator 的 run headOperator.run(getCheckpointLock(), getStreamStatusMaintainer(), operatorChain); completionFuture.complete(null); } catch (Throwable t) { // Note, t can be also an InterruptedException completionFuture.completeExceptionally(t); } }
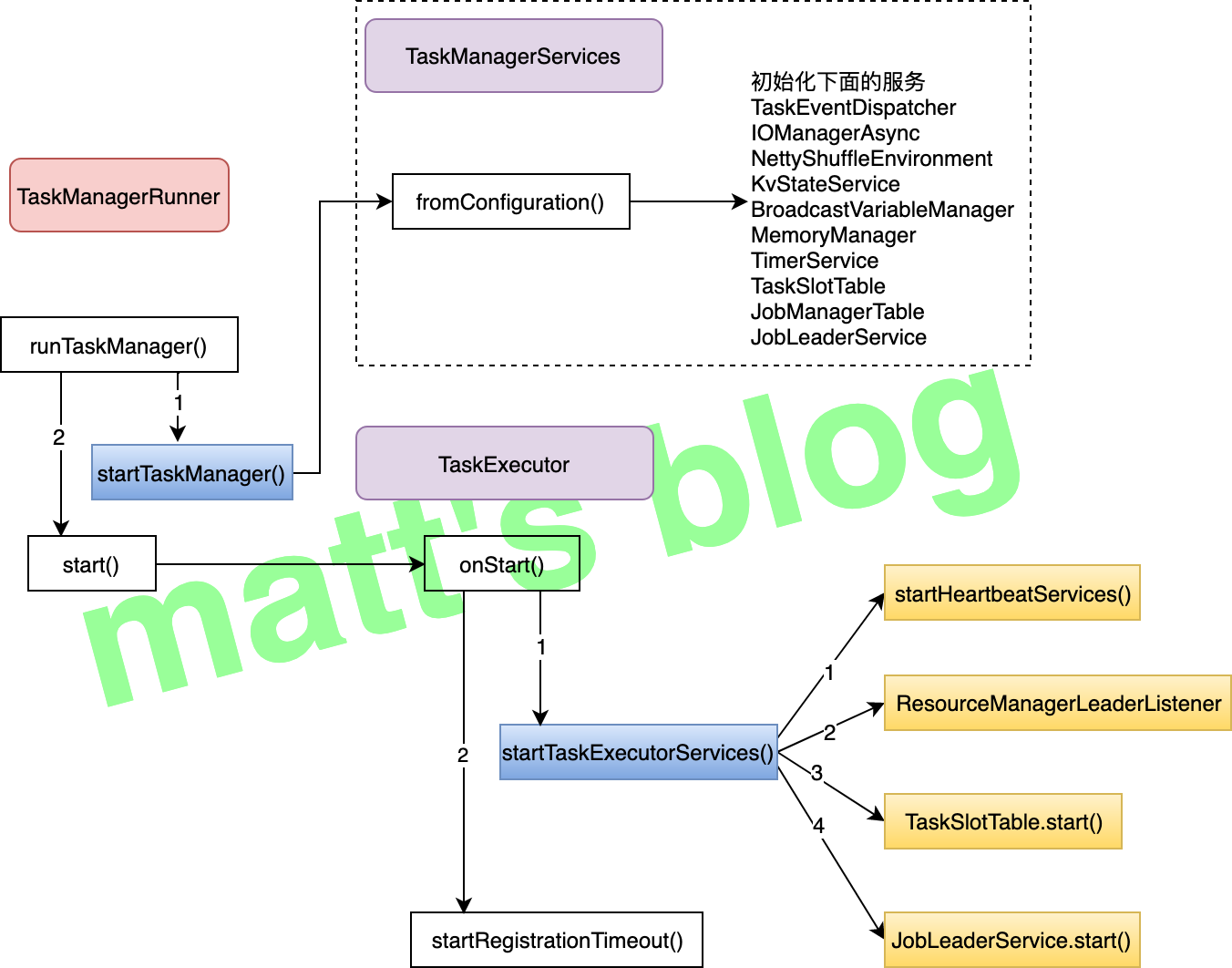
//note: 初始化 TaskManagerServices(TM 相关服务的初始化都在这里) TaskManagerServices taskManagerServices = TaskManagerServices.fromConfiguration( taskManagerServicesConfiguration, taskManagerMetricGroup.f1, rpcService.getExecutor()); // TODO replace this later with some dedicated executor for io.
//note: 创建 taskEventDispatcher final TaskEventDispatcher taskEventDispatcher = new TaskEventDispatcher();
// start the I/O manager, it will create some temp directories. //note: 创建 IO 管理器 final IOManager ioManager = new IOManagerAsync(taskManagerServicesConfiguration.getTmpDirPaths());
//note: 创建 KvStateService 实例并启动 final KvStateService kvStateService = KvStateService.fromConfiguration(taskManagerServicesConfiguration); kvStateService.start();
//note: 初始化 taskManagerLocation,记录 connection 信息 final TaskManagerLocation taskManagerLocation = new TaskManagerLocation( taskManagerServicesConfiguration.getResourceID(), taskManagerServicesConfiguration.getTaskManagerAddress(), dataPort);
// this call has to happen strictly after the network stack has been initialized //note: 初始化 MemoryManager final MemoryManager memoryManager = createMemoryManager(taskManagerServicesConfiguration); finallong managedMemorySize = memoryManager.getMemorySize();
//note: 初始化 BroadcastVariableManager 对象 final BroadcastVariableManager broadcastVariableManager = new BroadcastVariableManager();
//note: 注册一个超时(AKKA 超时设置)服务(在 TaskSlotTable 用于监控 slot 分配是否超时) final TimerService<AllocationID> timerService = new TimerService<>( new ScheduledThreadPoolExecutor(1), taskManagerServicesConfiguration.getTimerServiceShutdownTimeout());
//note: 这里会维护 slot 相关列表 final TaskSlotTable taskSlotTable = new TaskSlotTable(resourceProfiles, timerService);
//note: 维护 jobId 与 JobManager connection 之间的关系 final JobManagerTable jobManagerTable = new JobManagerTable();
//note: 监控注册的 job 的 JobManger leader 信息 final JobLeaderService jobLeaderService = new JobLeaderService(taskManagerLocation, taskManagerServicesConfiguration.getRetryingRegistrationConfiguration());
final String[] stateRootDirectoryStrings = taskManagerServicesConfiguration.getLocalRecoveryStateRootDirectories();
final File[] stateRootDirectoryFiles = new File[stateRootDirectoryStrings.length];
for (int i = 0; i < stateRootDirectoryStrings.length; ++i) { stateRootDirectoryFiles[i] = new File(stateRootDirectoryStrings[i], LOCAL_STATE_SUB_DIRECTORY_ROOT); }
//note: 创建 TaskExecutorLocalStateStoresManager 对象:维护状态信息 final TaskExecutorLocalStateStoresManager taskStateManager = new TaskExecutorLocalStateStoresManager( taskManagerServicesConfiguration.isLocalRecoveryEnabled(), stateRootDirectoryFiles, taskIOExecutor);
//note: 与集群的 ResourceManager 建立连接(并创建一个 listener) // start by connecting to the ResourceManager resourceManagerLeaderRetriever.start(new ResourceManagerLeaderListener());
// tell the task slot table who's responsible for the task slot actions //note: taskSlotTable 启动 taskSlotTable.start(new SlotActionsImpl());
// start the job leader service //note: 启动 job leader 服务 jobLeaderService.start(getAddress(), getRpcService(), haServices, new JobLeaderListenerImpl());
@Override publicvoidjobManagerGainedLeadership( final JobID jobId, final JobMasterGateway jobManagerGateway, final JMTMRegistrationSuccess registrationMessage){ //note: 建立与 JobManager 的连接 runAsync( () -> establishJobManagerConnection( jobId, jobManagerGateway, registrationMessage)); }
@Override publicvoidjobManagerLostLeadership(final JobID jobId, final JobMasterId jobMasterId){ log.info("JobManager for job {} with leader id {} lost leadership.", jobId, jobMasterId);
runAsync(() -> closeJobManagerConnection( jobId, new Exception("Job leader for job id " + jobId + " lost leadership."))); }
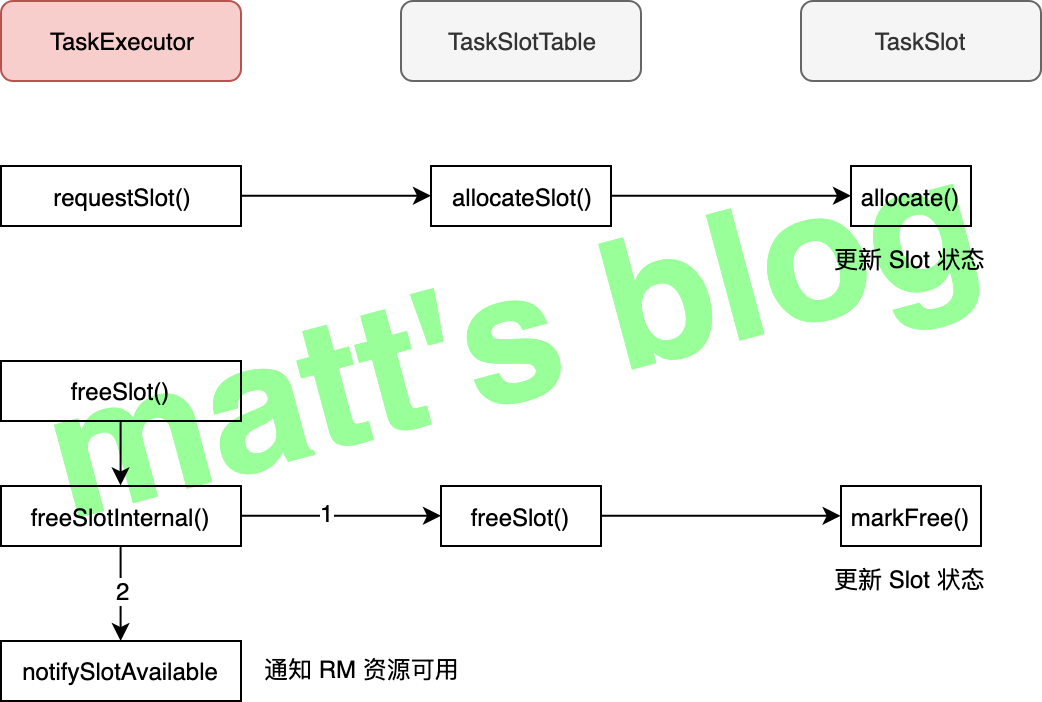
//note: slot 请求 @Override public CompletableFuture<Acknowledge> requestSlot( final SlotID slotId, final JobID jobId, final AllocationID allocationId, final String targetAddress, final ResourceManagerId resourceManagerId, final Time timeout){ // TODO: Filter invalid requests from the resource manager by using the instance/registration Id
log.info("Receive slot request {} for job {} from resource manager with leader id {}.", allocationId, jobId, resourceManagerId);
try { if (!isConnectedToResourceManager(resourceManagerId)) { //note: 如果 TM 并没有跟这个 RM 通信,就抛出异常 final String message = String.format("TaskManager is not connected to the resource manager %s.", resourceManagerId); log.debug(message); thrownew TaskManagerException(message); }
if (taskSlotTable.isSlotFree(slotId.getSlotNumber())) { //note: Slot 状态是 free,还未分配出去 if (taskSlotTable.allocateSlot(slotId.getSlotNumber(), jobId, allocationId, taskManagerConfiguration.getTimeout())) { log.info("Allocated slot for {}.", allocationId); //note: allcate 成功 } else { log.info("Could not allocate slot for {}.", allocationId); thrownew SlotAllocationException("Could not allocate slot."); } } elseif (!taskSlotTable.isAllocated(slotId.getSlotNumber(), jobId, allocationId)) { //note: slot 已经分配出去,但分配的并不是当前这个作业 final String message = "The slot " + slotId + " has already been allocated for a different job.";
log.info(message);
final AllocationID allocationID = taskSlotTable.getCurrentAllocation(slotId.getSlotNumber()); thrownew SlotOccupiedException(message, allocationID, taskSlotTable.getOwningJob(allocationID)); }
if (jobManagerTable.contains(jobId)) { //note: 如果 TM 已经有这个 JobManager 的 meta,这里会将这个 job 的 slot 分配再汇报给 JobManager 一次 offerSlotsToJobManager(jobId); } else { try { //note: 监控这个作业 JobManager 的 leader 变化 jobLeaderService.addJob(jobId, targetAddress); } catch (Exception e) { // free the allocated slot try { taskSlotTable.freeSlot(allocationId); } catch (SlotNotFoundException slotNotFoundException) { // slot no longer existent, this should actually never happen, because we've // just allocated the slot. So let's fail hard in this case! onFatalError(slotNotFoundException); }
// release local state under the allocation id. localStateStoresManager.releaseLocalStateForAllocationId(allocationId);
// sanity check if (!taskSlotTable.isSlotFree(slotId.getSlotNumber())) { onFatalError(new Exception("Could not free slot " + slotId)); }
thrownew SlotAllocationException("Could not add job to job leader service.", e); } } } catch (TaskManagerException taskManagerException) { return FutureUtils.completedExceptionally(taskManagerException); }
//note: 分配这个 TaskSlot boolean result = taskSlot.allocate(jobId, allocationId);
if (result) { //note: 分配成功,记录到缓存中 // update the allocation id to task slot map allocationIDTaskSlotMap.put(allocationId, taskSlot);
// register a timeout for this slot since it's in state allocated timerService.registerTimeout(allocationId, slotTimeout.getSize(), slotTimeout.getUnit());
// add this slot to the set of job slots Set<AllocationID> slots = slotsPerJob.get(jobId);
if (slots == null) { slots = new HashSet<>(4); slotsPerJob.put(jobId, slots); }
if (isConnectedToResourceManager()) { //note: 通知 ResourceManager 这个 slot 因为被释放了,所以可以变可用了 // the slot was freed. Tell the RM about it ResourceManagerGateway resourceManagerGateway = establishedResourceManagerConnection.getResourceManagerGateway();
resourceManagerGateway.notifySlotAvailable( establishedResourceManagerConnection.getTaskExecutorRegistrationId(), new SlotID(getResourceID(), slotIndex), allocationId); }
if (jobId != null) { closeJobManagerConnectionIfNoAllocatedResources(jobId); } } } catch (SlotNotFoundException e) { log.debug("Could not free slot for allocation id {}.", allocationId, e); }
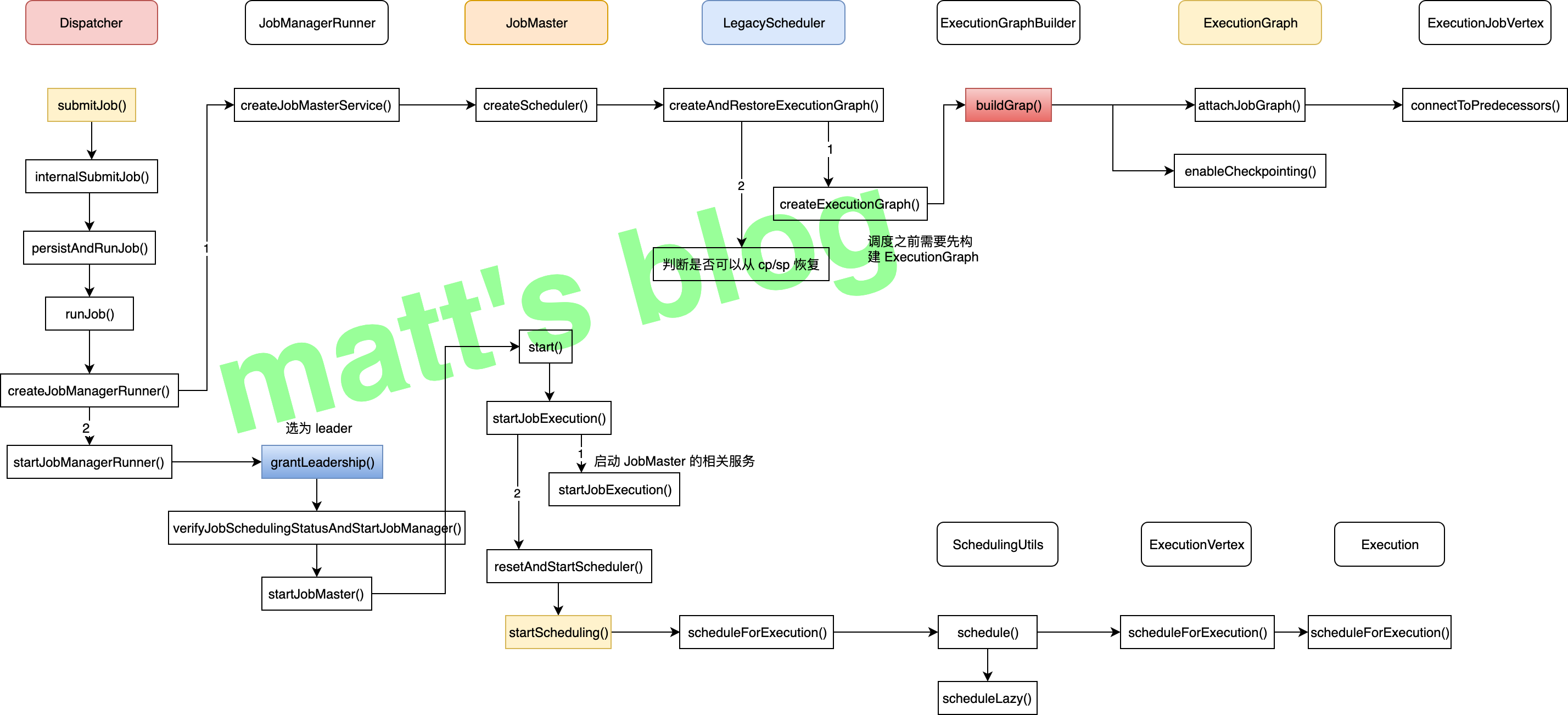
if (!(strippedThrowable instanceof CancellationException)) { // only fail if the scheduling future was not canceled failGlobal(strippedThrowable); } } }); } else { newSchedulingFuture.cancel(false); } } else { thrownew IllegalStateException("Job may only be scheduled from state " + JobStatus.CREATED); } }
// SchedulingUtils.java publicstatic CompletableFuture<Void> schedule( ScheduleMode scheduleMode, final Iterable<ExecutionVertex> vertices, final ExecutionGraph executionGraph){
switch (scheduleMode) { // LAZY 的意思是:是有上游数据就绪后,下游的 task 才能调度,这个主要是批场景会用到,流不能走这个模式 case LAZY_FROM_SOURCES: case LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST: return scheduleLazy(vertices, executionGraph);
// 流默认的是这个调度模式 case EAGER: return scheduleEager(vertices, executionGraph);
default: thrownew IllegalStateException(String.format("Schedule mode %s is invalid.", scheduleMode)); } }
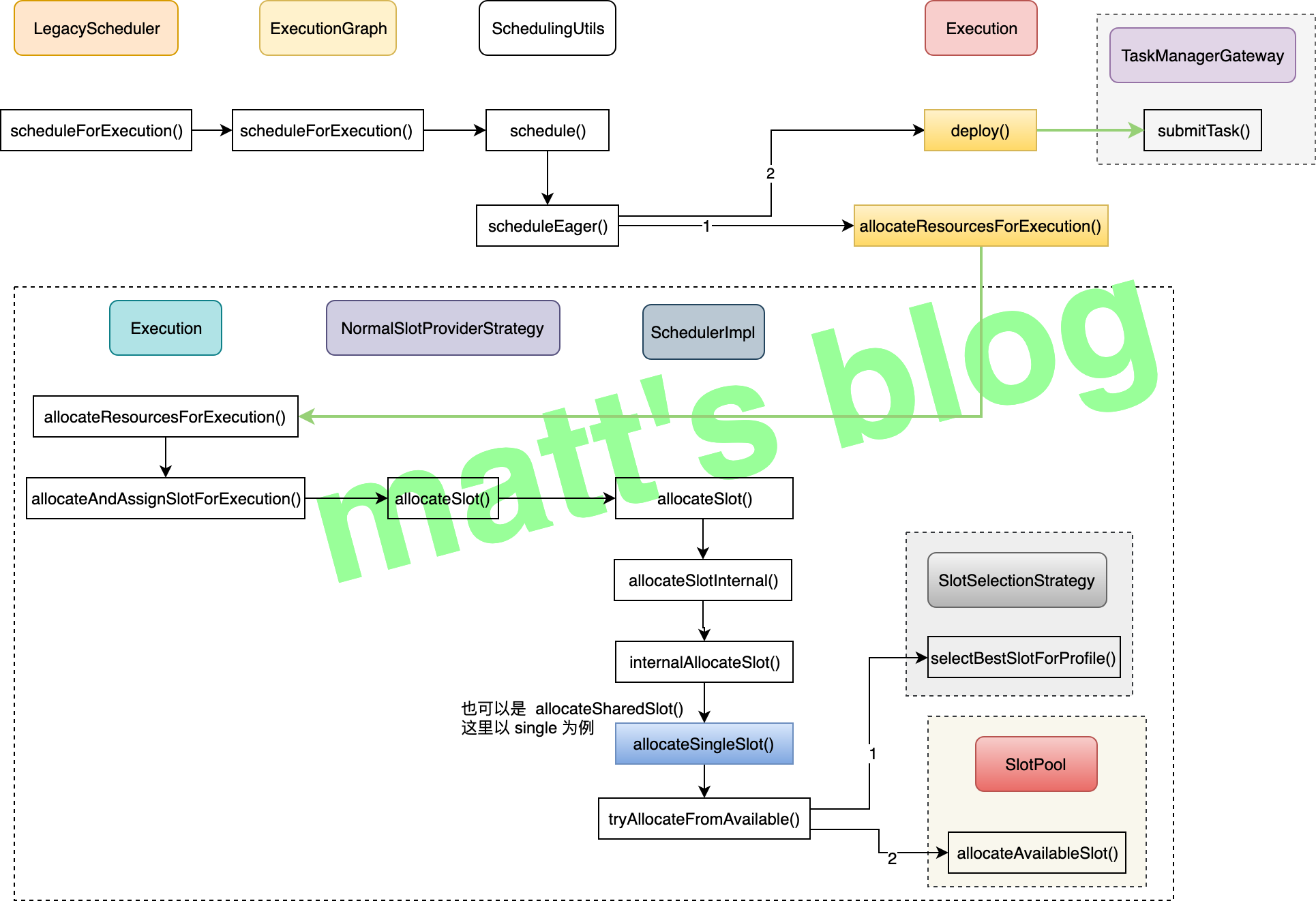
/** * Schedule vertices eagerly. That means all vertices will be scheduled at once. * note: 所有的节点会被同时调度 * * @param vertices Topologically sorted vertices to schedule. * @param executionGraph The graph the given vertices belong to. */ publicstatic CompletableFuture<Void> scheduleEager( final Iterable<ExecutionVertex> vertices, final ExecutionGraph executionGraph){
checkState(executionGraph.getState() == JobStatus.RUNNING, "job is not running currently");
// Important: reserve all the space we need up front. // that way we do not have any operation that can fail between allocating the slots // and adding them to the list. If we had a failure in between there, that would // cause the slots to get lost
// collecting all the slots may resize and fail in that operation without slots getting lost final ArrayList<CompletableFuture<Execution>> allAllocationFutures = new ArrayList<>();
final SlotProviderStrategy slotProviderStrategy = executionGraph.getSlotProviderStrategy(); final Set<AllocationID> allPreviousAllocationIds = Collections.unmodifiableSet( computePriorAllocationIdsIfRequiredByScheduling(vertices, slotProviderStrategy.asSlotProvider()));
// allocate the slots (obtain all their futures) for (ExecutionVertex ev : vertices) { // these calls are not blocking, they only return futures //note: 给每个 Execution 分配相应的资源 CompletableFuture<Execution> allocationFuture = ev.getCurrentExecutionAttempt().allocateResourcesForExecution( slotProviderStrategy, LocationPreferenceConstraint.ALL, allPreviousAllocationIds);
allAllocationFutures.add(allocationFuture); }
// this future is complete once all slot futures are complete. // the future fails once one slot future fails. final ConjunctFuture<Collection<Execution>> allAllocationsFuture = FutureUtils.combineAll(allAllocationFutures);
return allAllocationsFuture.thenAccept( (Collection<Execution> executionsToDeploy) -> { for (Execution execution : executionsToDeploy) { try { //note: 部署每个 Execution execution.deploy(); } catch (Throwable t) { thrownew CompletionException( new FlinkException( String.format("Could not deploy execution %s.", execution), t)); } } }) // Generate a more specific failure message for the eager scheduling .exceptionally( //... ); }
/** * Allocates and assigns a slot obtained from the slot provider to the execution. * note: 从 slot provider 获取一个 slot,将任务分配到这个 slot 上 * * @param slotProviderStrategy to obtain a new slot from * @param locationPreferenceConstraint constraint for the location preferences * @param allPreviousExecutionGraphAllocationIds set with all previous allocation ids in the job graph. * Can be empty if the allocation ids are not required for scheduling. * @return Future which is completed with the allocated slot once it has been assigned * or with an exception if an error occurred. */ private CompletableFuture<LogicalSlot> allocateAndAssignSlotForExecution( SlotProviderStrategy slotProviderStrategy, LocationPreferenceConstraint locationPreferenceConstraint, @Nonnull Set<AllocationID> allPreviousExecutionGraphAllocationIds){
checkNotNull(slotProviderStrategy);
assertRunningInJobMasterMainThread();
//note: 获取这个 vertex 的相关信息 final SlotSharingGroup sharingGroup = vertex.getJobVertex().getSlotSharingGroup(); final CoLocationConstraint locationConstraint = vertex.getLocationConstraint();
// sanity check //note: 做相应的检查 if (locationConstraint != null && sharingGroup == null) { thrownew IllegalStateException( "Trying to schedule with co-location constraint but without slot sharing allowed."); }
// this method only works if the execution is in the state 'CREATED' //note: 这个只会在 CREATED 下工作 if (transitionState(CREATED, SCHEDULED)) {
// try to extract previous allocation ids, if applicable, so that we can reschedule to the same slot //note: 如果能找到之前调度的 AllocationID,会尽量先重新调度在同一个 slot 上 ExecutionVertex executionVertex = getVertex(); AllocationID lastAllocation = executionVertex.getLatestPriorAllocation();
// calculate the preferred locations //note: 这里先根据 state 和上游数据的输入节点获取这个 Task Execution 的最佳 TM location final CompletableFuture<Collection<TaskManagerLocation>> preferredLocationsFuture = calculatePreferredLocations(locationPreferenceConstraint);
final SlotRequestId slotRequestId = new SlotRequestId();
//note: 根据指定的需求分配这个 slot final CompletableFuture<LogicalSlot> logicalSlotFuture = preferredLocationsFuture.thenCompose( (Collection<TaskManagerLocation> preferredLocations) -> slotProviderStrategy.allocateSlot( slotRequestId, toSchedule, new SlotProfile( vertex.getResourceProfile(), preferredLocations, previousAllocationIDs, allPreviousExecutionGraphAllocationIds)));
// register call back to cancel slot request in case that the execution gets canceled releaseFuture.whenComplete( (Object ignored, Throwable throwable) -> { if (logicalSlotFuture.cancel(false)) { slotProviderStrategy.cancelSlotRequest( slotRequestId, slotSharingGroupId, new FlinkException("Execution " + this + " was released.")); } });
// This forces calls to the slot pool back into the main thread, for normal and exceptional completion //note: 返回 LogicalSlot return logicalSlotFuture.handle( (LogicalSlot logicalSlot, Throwable failure) -> {
if (failure != null) { thrownew CompletionException(failure); }
if (tryAssignResource(logicalSlot)) { return logicalSlot; } else { // release the slot logicalSlot.releaseSlot(new FlinkException("Could not assign logical slot to execution " + this + '.')); thrownew CompletionException( new FlinkException( "Could not assign slot " + logicalSlot + " to execution " + this + " because it has already been assigned ")); } }); } else { // call race, already deployed, or already done thrownew IllegalExecutionStateException(this, CREATED, state); } }
这里,简单总结一下上面这个方法的流程:
状态转换,将这个 Execution 的状态(ExecutionState)从 CREATED 转为 SCHEDULED 状态;
// Execution.java /** * Calculates the preferred locations based on the location preference constraint. * note: 根据 LocationPreferenceConstraint 策略计算前置输入节点的 TaskManagerLocation * * @param locationPreferenceConstraint constraint for the location preference * @return Future containing the collection of preferred locations. This might not be completed if not all inputs * have been a resource assigned. */ @VisibleForTesting public CompletableFuture<Collection<TaskManagerLocation>> calculatePreferredLocations(LocationPreferenceConstraint locationPreferenceConstraint) { //note: 获取一个最佳分配的 TM location 集合 final Collection<CompletableFuture<TaskManagerLocation>> preferredLocationFutures = getVertex().getPreferredLocations(); final CompletableFuture<Collection<TaskManagerLocation>> preferredLocationsFuture;
switch(locationPreferenceConstraint) { case ALL: //note: 默认是 ALL,就是前面拿到的列表,这里都可以使用 preferredLocationsFuture = FutureUtils.combineAll(preferredLocationFutures); break; case ANY: //note: 遍历所有 input,先获取已经完成 assign 的 input 列表 final ArrayList<TaskManagerLocation> completedTaskManagerLocations = new ArrayList<>(preferredLocationFutures.size());
for (CompletableFuture<TaskManagerLocation> preferredLocationFuture : preferredLocationFutures) { if (preferredLocationFuture.isDone() && !preferredLocationFuture.isCompletedExceptionally()) { //note: 在这个 future 完成(没有异常的情况下),这里会使用这个 taskManagerLocation 对象 final TaskManagerLocation taskManagerLocation = preferredLocationFuture.getNow(null);
if (taskManagerLocation == null) { thrownew FlinkRuntimeException("TaskManagerLocationFuture was completed with null. This indicates a programming bug."); }
// ExecutionVertex.java /** * Gets the overall preferred execution location for this vertex's current execution. * The preference is determined as follows: * * <ol> * <li>If the task execution has state to load (from a checkpoint), then the location preference * is the location of the previous execution (if there is a previous execution attempt). * <li>If the task execution has no state or no previous location, then the location preference * is based on the task's inputs. * </ol> * note: 如果这个 task Execution 是从 checkpoint 加载的状态,那么这个 location preference 就是之前执行的状态; * note: 如果这个 task Execution 没有状态信息或之前的 location 记录,这个 location preference 依赖于 task 的输入; * * <p>These rules should result in the following behavior: * * note: 1. 无状态 task 总是基于与输入共享的方式调度; * note: 2. 有状态 task 基于与输入共享的方式来初始化他们最开始的调度; * note: 3. 有状态 task 的重复执行会尽量与他们的 state 共享执行; * <ul> * <li>Stateless tasks are always scheduled based on co-location with inputs. * <li>Stateful tasks are on their initial attempt executed based on co-location with inputs. * <li>Repeated executions of stateful tasks try to co-locate the execution with its state. * </ul> */ public Collection<CompletableFuture<TaskManagerLocation>> getPreferredLocations() { Collection<CompletableFuture<TaskManagerLocation>> basedOnState = getPreferredLocationsBasedOnState(); return basedOnState != null ? basedOnState : getPreferredLocationsBasedOnInputs(); }
/** * Gets the preferred location to execute the current task execution attempt, based on the state that the execution attempt will resume. * note: 根据这个 Execution 试图恢复的状态来获取当前 task execution 的首选位置 */ public Collection<CompletableFuture<TaskManagerLocation>> getPreferredLocationsBasedOnState() { TaskManagerLocation priorLocation; if (currentExecution.getTaskRestore() != null && (priorLocation = getLatestPriorLocation()) != null) { return Collections.singleton(CompletableFuture.completedFuture(priorLocation)); } else { returnnull; } }
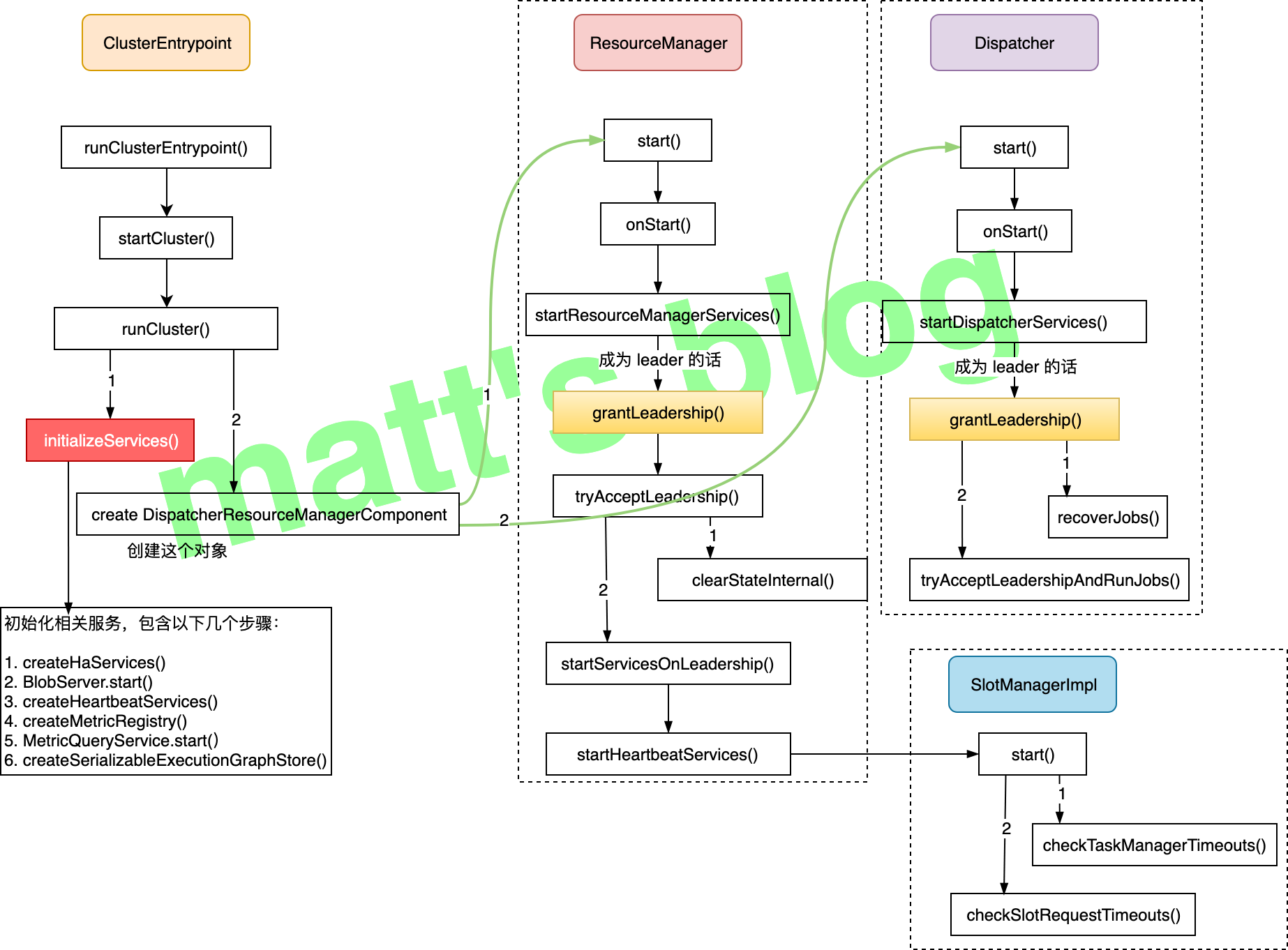
// ClusterEntrypoint.java //note: run cluster real start-point privatevoidrunCluster(Configuration configuration)throws Exception { synchronized (lock) { //note: 首先会初始化相关的服务(这里会涉及到一系列的服务) initializeServices(configuration);
// write host information into configuration configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress()); configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
final DispatcherResourceManagerComponentFactory<?> dispatcherResourceManagerComponentFactory = createDispatcherResourceManagerComponentFactory(configuration);
clusterComponent.getShutDownFuture().whenComplete( (ApplicationStatus applicationStatus, Throwable throwable) -> { if (throwable != null) { //note: 抛出异常的情况下 shutDownAsync( ApplicationStatus.UNKNOWN, ExceptionUtils.stringifyException(throwable), false); } else { // This is the general shutdown path. If a separate more specific shutdown was // already triggered, this will do nothing shutDownAsync( applicationStatus, null, true); } }); } }
// update the configuration used to create the high availability services //note: 根据当前创建的 RPC 服务信息做相关的配置(之前设置的端口可能是一个 range) configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress()); configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
//note: 用于 IO 的线程池 ioExecutor = Executors.newFixedThreadPool( Hardware.getNumberCPUCores(), new ExecutorThreadFactory("cluster-io")); //note: HA service(跟用户配置有关,可以是 NONE、ZooKeeper 也可以自定义的类) haServices = createHaServices(configuration, ioExecutor); //note: 初始化 Blob Server blobServer = new BlobServer(configuration, haServices.createBlobStore()); blobServer.start(); //note: heartbeat service heartbeatServices = createHeartbeatServices(configuration); //note: metrics reporter metricRegistry = createMetricRegistry(configuration);
//note: 创建了一个 Flink 内部的 metrics rpc service final RpcService metricQueryServiceRpcService = MetricUtils.startMetricsRpcService(configuration, bindAddress); //note: start MetricQueryService metricRegistry.startQueryService(metricQueryServiceRpcService, null);
final CompletableFuture<Void> confirmationFuture = fencingTokenFuture.thenCombineAsync( recoveredJobsFuture, BiFunctionWithException.unchecked((Boolean confirmLeadership, Collection<JobGraph> recoveredJobs) -> { if (confirmLeadership) { //note: 如果是 leader,并且前面两步都完成的话,就会走到这里 leaderElectionService.confirmLeaderSessionID(newLeaderSessionID); } else { for (JobGraph recoveredJob : recoveredJobs) { //note: 从 job graph store 中删除这些作业相关的 state submittedJobGraphStore.releaseJobGraph(recoveredJob.getJobID()); } } returnnull; }), getRpcService().getExecutor());
confirmationFuture.whenComplete( (Void ignored, Throwable throwable) -> { if (throwable != null) { onFatalError( new DispatcherException( String.format("Failed to take leadership with session id %s.", newLeaderSessionID), (ExceptionUtils.stripCompletionException(throwable)))); } });
recoveryOperation = confirmationFuture; }); }
Dispatcher 被选举为 leader 后,它主要的操作步骤如下:
recoverJobs(): 先从 job graph store 恢复所有作业的 JobGraph;
tryAcceptLeadershipAndRunJobs(): 启动前面恢复的每个作业,这里要说明的是,目前看到的 1.9 的实现,这里会将前面所有的作业都会重启,我在看的时候是有点懵逼的,这个 HA 有点伪 HA,相当于 leader 切换之后,作业就必须要得重启恢复,这个代价是有点大的,不过也看到社区有改进的计划(FLINK-10333 这个进度有点慢);
我们这里再详细看下 Dispatcher 对外提供了哪些 API 实现(这些接口主要还是 DispatcherGateway 中必须要实现的接口),通过这些 API,其实就很容易看出它到底对外提供了哪些功能,提供的 API 有:
final CompletableFuture<Void> confirmationFuture = acceptLeadershipFuture.thenAcceptAsync( (acceptLeadership) -> { if (acceptLeadership) { // confirming the leader session ID might be blocking, leaderElectionService.confirmLeaderSessionID(newLeaderSessionID); } }, getRpcService().getExecutor());
//note: 决定什么时候释放 IntermediateResultPartitions 的策略 final PartitionReleaseStrategy.Factory partitionReleaseStrategyFactory = PartitionReleaseStrategyFactoryLoader.loadPartitionReleaseStrategyFactory(jobManagerConfig);
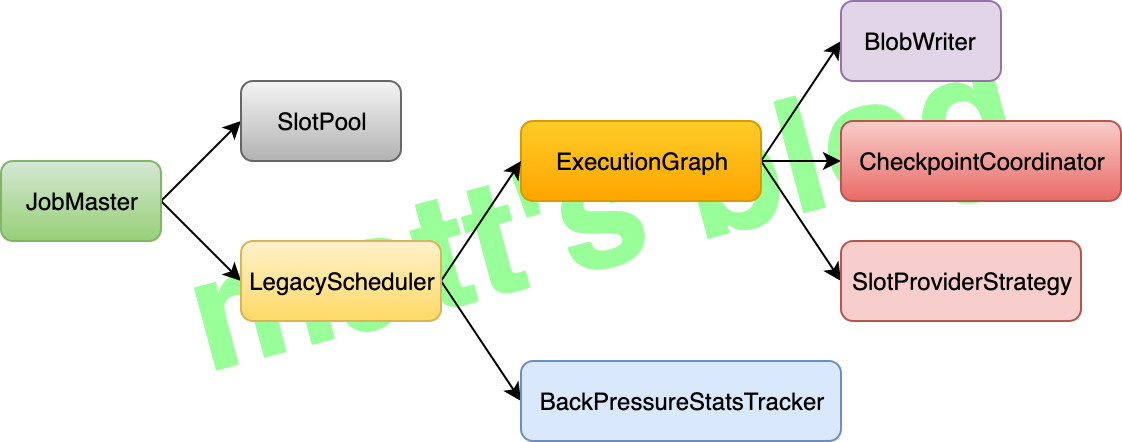
// create a new execution graph, if none exists so far //note: 如果 executionGraph 还不存在,就创建一个新的对象 final ExecutionGraph executionGraph; try { executionGraph = (prior != null) ? prior : new ExecutionGraph( jobInformation, futureExecutor, ioExecutor, rpcTimeout, restartStrategy, maxPriorAttemptsHistoryLength, failoverStrategyFactory, slotProvider, classLoader, blobWriter, allocationTimeout, partitionReleaseStrategyFactory, shuffleMaster, partitionTracker, jobGraph.getScheduleMode(), jobGraph.getAllowQueuedScheduling()); } catch (IOException e) { thrownew JobException("Could not create the ExecutionGraph.", e); }
// set the basic properties
try { //note: 以 json 的形式记录 JobGraph executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph)); } catch (Throwable t) { log.warn("Cannot create JSON plan for job", t); // give the graph an empty plan executionGraph.setJsonPlan("{}"); }
// initialize the vertices that have a master initialization hook // file output formats create directories here, input formats create splits
finallong initMasterStart = System.nanoTime(); log.info("Running initialization on master for job {} ({}).", jobName, jobId);
for (JobVertex vertex : jobGraph.getVertices()) { String executableClass = vertex.getInvokableClassName(); if (executableClass == null || executableClass.isEmpty()) { thrownew JobSubmissionException(jobId, "The vertex " + vertex.getID() + " (" + vertex.getName() + ") has no invokable class."); }
log.info("Successfully ran initialization on master in {} ms.", (System.nanoTime() - initMasterStart) / 1_000_000);
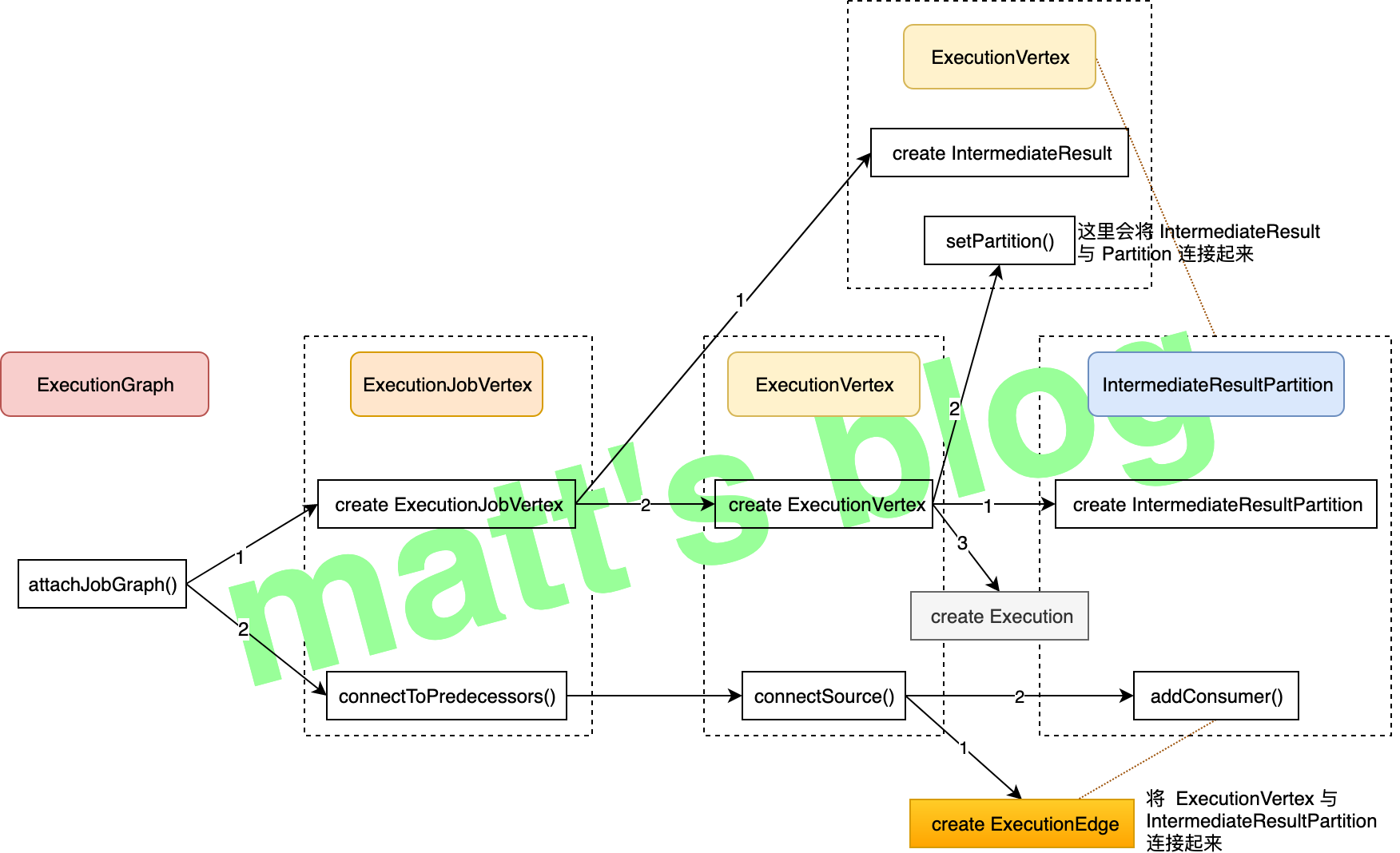
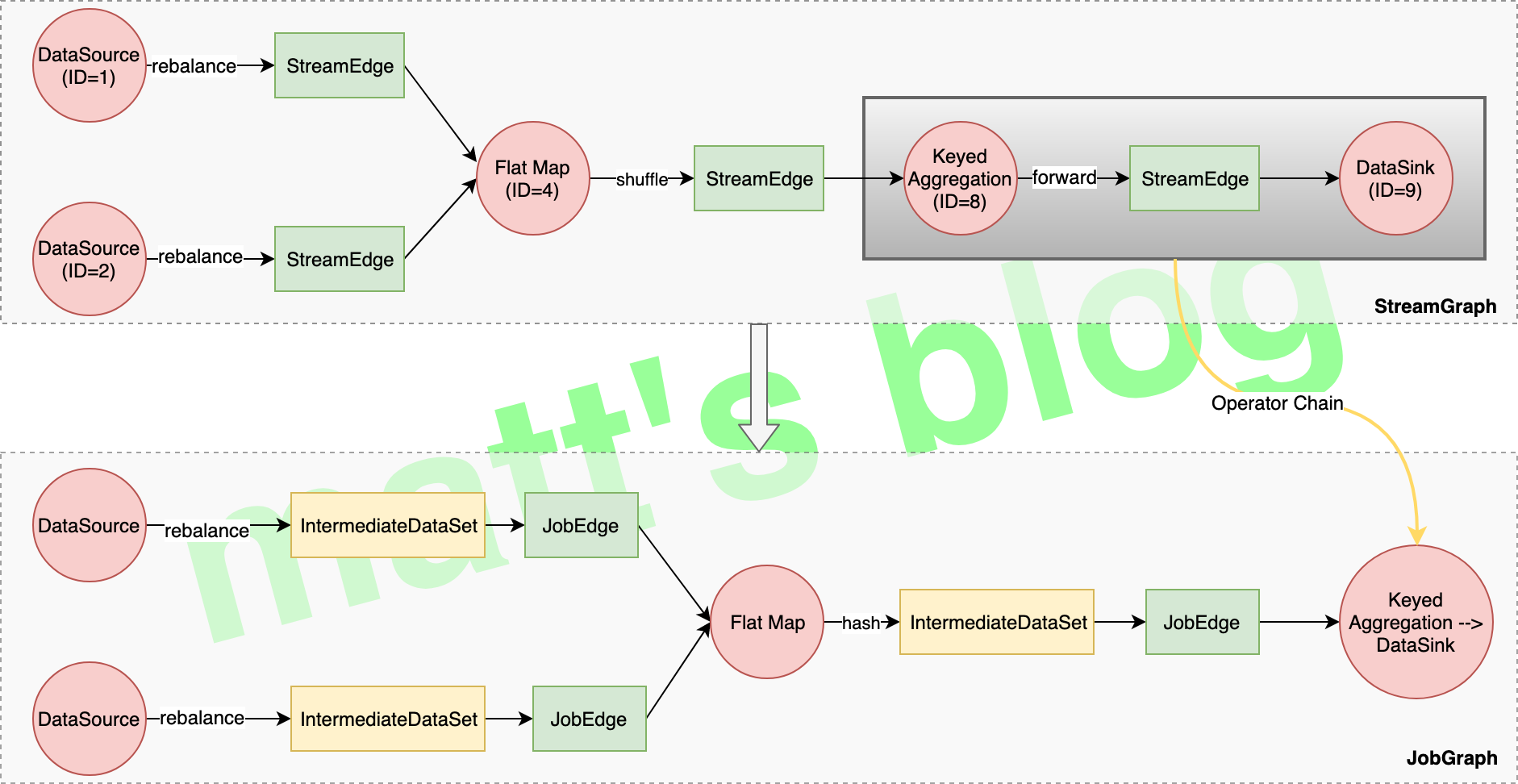
// topologically sort the job vertices and attach the graph to the existing one //note: 这里会先做一个排序,source 会放在最前面,接着开始遍历,必须保证当前添加到集合的节点的前置节点都已经添加进去了 List<JobVertex> sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources(); if (log.isDebugEnabled()) { log.debug("Adding {} vertices from job graph {} ({}).", sortedTopology.size(), jobName, jobId); } //note: 处理的重点:生成具体的 Execution Plan executionGraph.attachJobGraph(sortedTopology);
if (log.isDebugEnabled()) { log.debug("Successfully created execution graph from job graph {} ({}).", jobName, jobId); }
//note: cp 相关的配置 // configure the state CheckPointing JobCheckpointingSettings snapshotSettings = jobGraph.getCheckpointingSettings(); if (snapshotSettings != null) { //note: cp 时,需要 trigger(插入 barrier)的 JobVertex,这里指的是 source 节点 List<ExecutionJobVertex> triggerVertices = idToVertex(snapshotSettings.getVerticesToTrigger(), executionGraph);
if (maxNumberOfCheckpointsToRetain <= 0) { // warning and use 1 as the default value if the setting in // state.checkpoints.max-retained-checkpoints is not greater than 0. log.warn("The setting for '{} : {}' is invalid. Using default value of {}", CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.key(), maxNumberOfCheckpointsToRetain, CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.defaultValue());
// Maximum number of remembered checkpoints //note: cp 保存的最多数量 int historySize = jobManagerConfig.getInteger(WebOptions.CHECKPOINTS_HISTORY_SIZE);
CheckpointStatsTracker checkpointStatsTracker = new CheckpointStatsTracker( historySize, ackVertices, snapshotSettings.getCheckpointCoordinatorConfiguration(), metrics);
// load the state backend from the application settings final StateBackend applicationConfiguredBackend; final SerializedValue<StateBackend> serializedAppConfigured = snapshotSettings.getDefaultStateBackend();
metrics.gauge(RestartTimeGauge.METRIC_NAME, new RestartTimeGauge(executionGraph)); metrics.gauge(DownTimeGauge.METRIC_NAME, new DownTimeGauge(executionGraph)); metrics.gauge(UpTimeGauge.METRIC_NAME, new UpTimeGauge(executionGraph)); metrics.gauge(NumberOfFullRestartsGauge.METRIC_NAME, new NumberOfFullRestartsGauge(executionGraph));
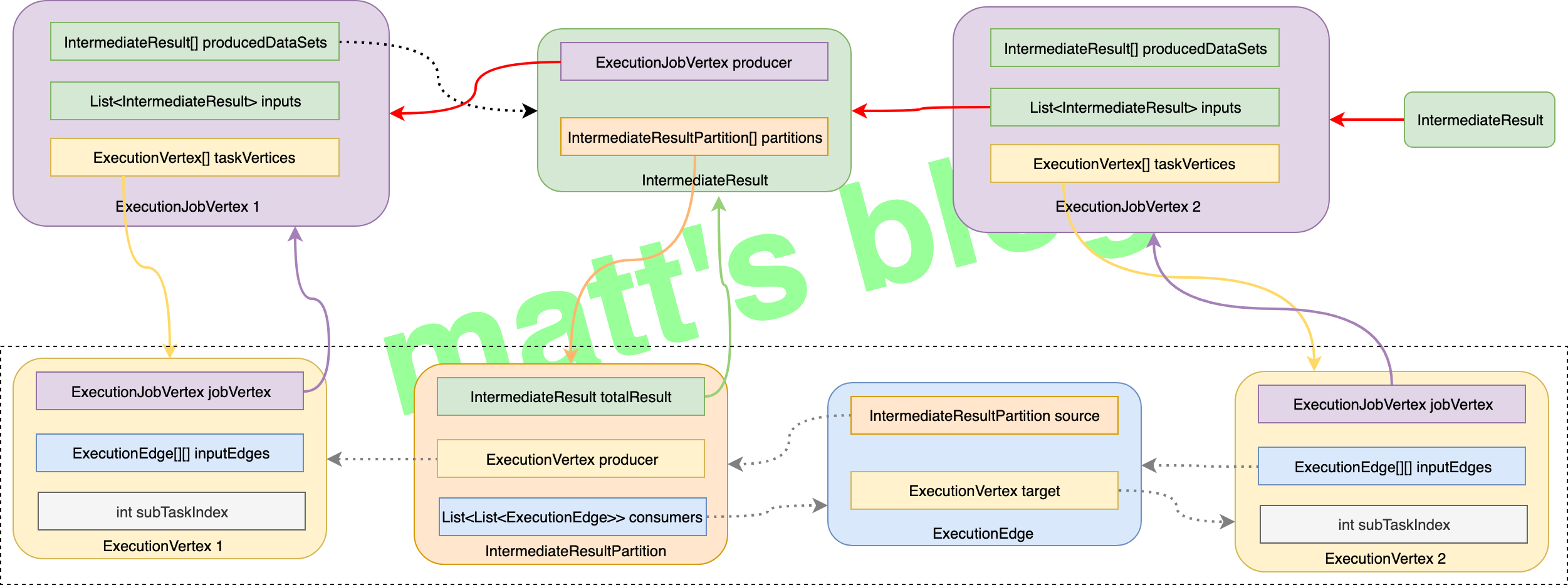
publicExecutionJobVertex( ExecutionGraph graph, JobVertex jobVertex, int defaultParallelism, int maxPriorAttemptsHistoryLength, Time timeout, long initialGlobalModVersion, long createTimestamp)throws JobException {
// if no max parallelism was configured by the user, we calculate and set a default setMaxParallelismInternal(maxParallelismConfigured ? configuredMaxParallelism : KeyGroupRangeAssignment.computeDefaultMaxParallelism(numTaskVertices));
// verify that our parallelism is not higher than the maximum parallelism if (numTaskVertices > maxParallelism) { thrownew JobException( String.format("Vertex %s's parallelism (%s) is higher than the max parallelism (%s). Please lower the parallelism or increase the max parallelism.", jobVertex.getName(), numTaskVertices, maxParallelism)); }
//note: 记录输入的 IntermediateResult 列表 this.inputs = new ArrayList<>(jobVertex.getInputs().size());
// take the sharing group this.slotSharingGroup = jobVertex.getSlotSharingGroup(); this.coLocationGroup = jobVertex.getCoLocationGroup();
// setup the coLocation group if (coLocationGroup != null && slotSharingGroup == null) { thrownew JobException("Vertex uses a co-location constraint without using slot sharing"); }
// create the intermediate results //note: 创建 IntermediateResult 对象数组(根据 JobVertex 的 targets 来确定) this.producedDataSets = new IntermediateResult[jobVertex.getNumberOfProducedIntermediateDataSets()];
for (int i = 0; i < jobVertex.getProducedDataSets().size(); i++) { //note: JobGraph 中 IntermediateDataSet 这里会转换为 IntermediateResult 对象 final IntermediateDataSet result = jobVertex.getProducedDataSets().get(i);
// create all task vertices //note: task vertices 创建 //note: 一个 JobVertex/ExecutionJobVertex 代表的是一个operator chain,而具体的 ExecutionVertex 则代表了每一个 Task for (int i = 0; i < numTaskVertices; i++) { ExecutionVertex vertex = new ExecutionVertex( this, i, producedDataSets, timeout, initialGlobalModVersion, createTimestamp, maxPriorAttemptsHistoryLength);
this.taskVertices[i] = vertex; }
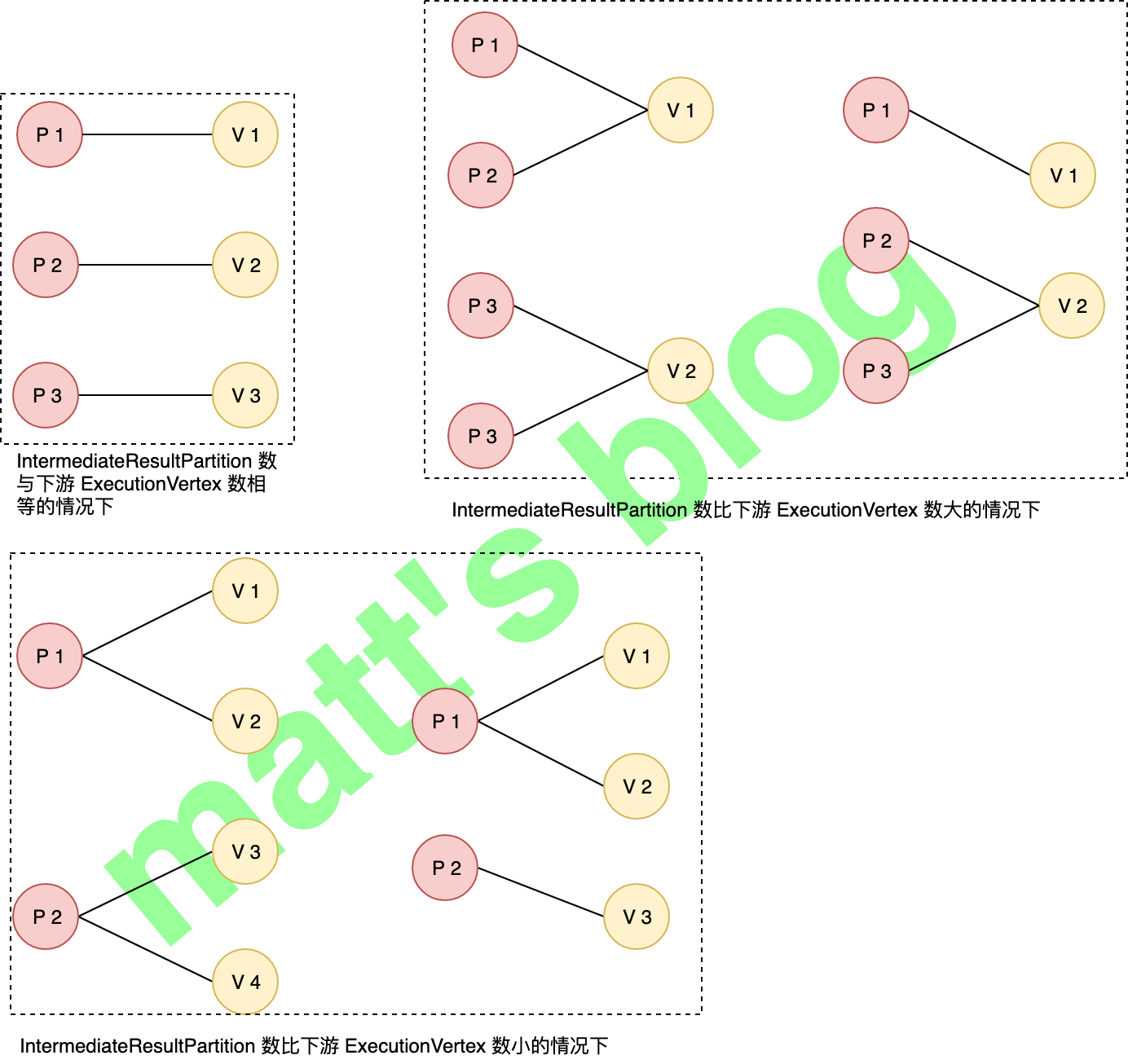
// sanity check for the double referencing between intermediate result partitions and execution vertices for (IntermediateResult ir : this.producedDataSets) { if (ir.getNumberOfAssignedPartitions() != parallelism) { thrownew RuntimeException("The intermediate result's partitions were not correctly assigned."); } } // ... }
publicExecutionVertex( ExecutionJobVertex jobVertex, int subTaskIndex, IntermediateResult[] producedDataSets, Time timeout, long initialGlobalModVersion, long createTimestamp, int maxPriorExecutionHistoryLength){
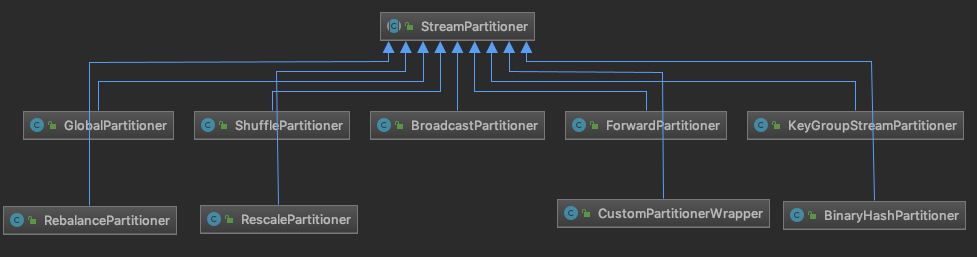
case ALL_TO_ALL: //note: 它会连接上游所有的 IntermediateResultPartition edges = connectAllToAll(sourcePartitions, inputNumber); break;
default: thrownew RuntimeException("Unrecognized distribution pattern.");
}
inputEdges[inputNumber] = edges;
// add the consumers to the source // for now (until the receiver initiated handshake is in place), we need to register the // edges as the execution graph //note: 之前已经为 IntermediateResult 添加了 consumer,这里为 IntermediateResultPartition 添加 consumer,即关联到 ExecutionEdge 上 for (ExecutionEdge ee : edges) { ee.getSource().addConsumer(ee, consumerNumber); } }
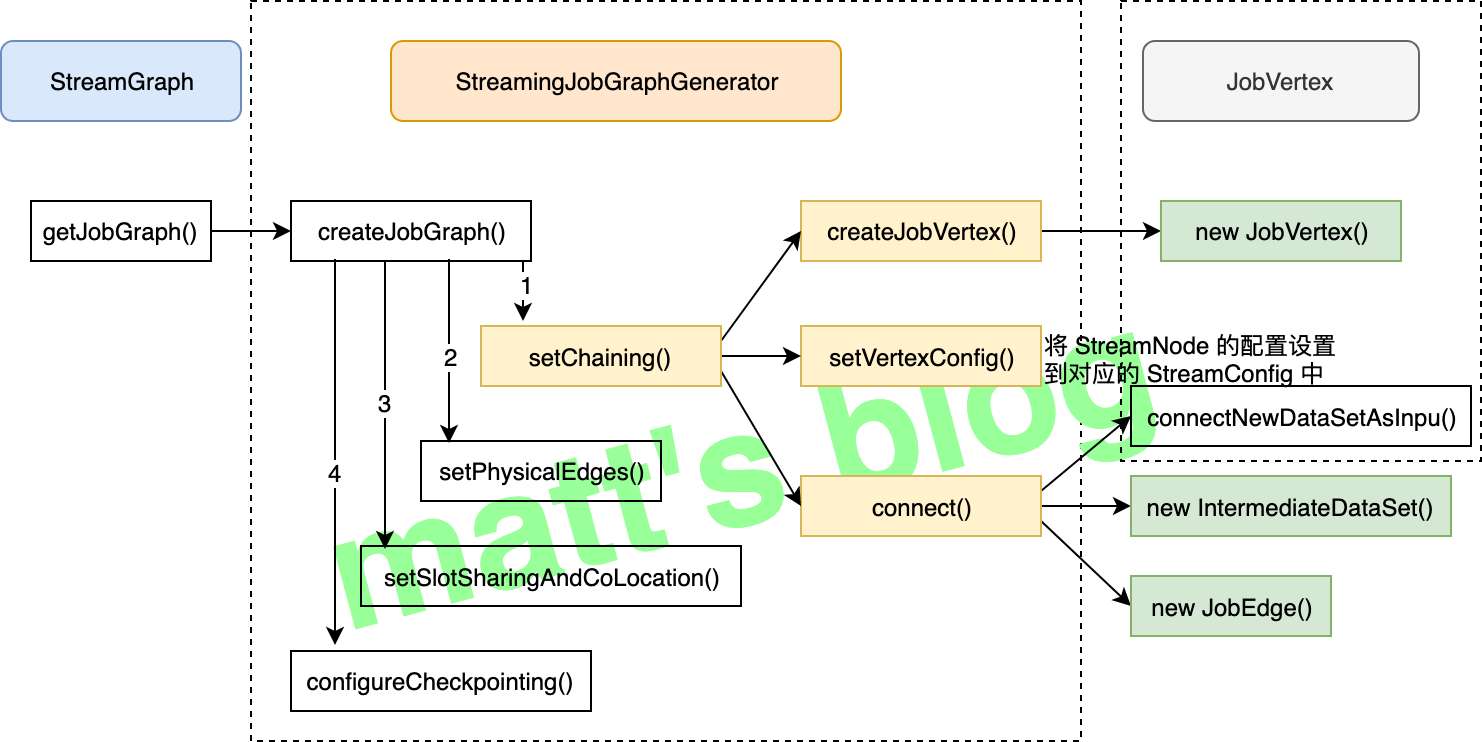
// set the ExecutionConfig last when it has been finalized try { //note: 将 StreamGraph 的 ExecutionConfig 序列化到 JobGraph 的配置中 jobGraph.setExecutionConfig(streamGraph.getExecutionConfig()); } catch (IOException e) { thrownew IllegalConfigurationException("Could not serialize the ExecutionConfig." + "This indicates that non-serializable types (like custom serializers) were registered"); }
/** * Determines the slot sharing group for an operation based on the slot sharing group set by * the user and the slot sharing groups of the inputs. * note: 根据这个 operation 设置的 slot sharing group 和 inputs 的 slot sharing group 来确定其 slot sharing group * note:1. 如果用户指定了 group name,直接使用这个 name; * note:2. 如果所有的 input 都是同一个 group name,使用这个即可; * note:3. 否则使用 default group; * * <p>If the user specifies a group name, this is taken as is. If nothing is specified and * the input operations all have the same group name then this name is taken. Otherwise the * default group is chosen. * * @param specifiedGroup The group specified by the user. note: 用户指定的 group name * @param inputIds The IDs of the input operations. note: 输入 operation 的 id 集合 */ private String determineSlotSharingGroup(String specifiedGroup, Collection<Integer> inputIds){ if (!isSlotSharingEnabled) { returnnull; }
long interval = cfg.getCheckpointInterval(); if (interval < MINIMAL_CHECKPOINT_TIME) { // interval of max value means disable periodic checkpoint interval = Long.MAX_VALUE; }
// --- configure the participating vertices ---
//note: 配置 checkpoint 中要参与的 vertices 节点信息 // collect the vertices that receive "trigger checkpoint" messages. // currently, these are all the sources //note: 记录接收 trigger checkpoint msg 的 vertices,当前都是 source 的情况 List<JobVertexID> triggerVertices = new ArrayList<>();
// collect the vertices that need to acknowledge the checkpoint // currently, these are all vertices //note: 记录当前需要向 checkpoint coordinator 发送 ack 的 vertices,当前指的是所有的 vertices List<JobVertexID> ackVertices = new ArrayList<>(jobVertices.size());
// collect the vertices that receive "commit checkpoint" messages // currently, these are all vertices //note: 记录接收 'commit checkpoint' 的 vertices,当前也指的是所有 vertices List<JobVertexID> commitVertices = new ArrayList<>(jobVertices.size());
for (JobVertex vertex : jobVertices.values()) { if (vertex.isInputVertex()) { triggerVertices.add(vertex.getID()); } commitVertices.add(vertex.getID()); ackVertices.add(vertex.getID()); }
boolean isExactlyOnce; if (mode == CheckpointingMode.EXACTLY_ONCE) { isExactlyOnce = true; } elseif (mode == CheckpointingMode.AT_LEAST_ONCE) { isExactlyOnce = false; } else { thrownew IllegalStateException("Unexpected checkpointing mode. " + "Did not expect there to be another checkpointing mode besides " + "exactly-once or at-least-once."); }
// --- configure the master-side checkpoint hooks ---
final ArrayList<MasterTriggerRestoreHook.Factory> hooks = new ArrayList<>();
for (StreamNode node : streamGraph.getStreamNodes()) { if (node.getOperatorFactory() instanceof UdfStreamOperatorFactory) { Function f = ((UdfStreamOperatorFactory) node.getOperatorFactory()).getUserFunction();
// because the hooks can have user-defined code, they need to be stored as // eagerly serialized values //note: 这里对 hooks 做一下序列化 final SerializedValue<MasterTriggerRestoreHook.Factory[]> serializedHooks; if (hooks.isEmpty()) { serializedHooks = null; } else { try { MasterTriggerRestoreHook.Factory[] asArray = hooks.toArray(new MasterTriggerRestoreHook.Factory[hooks.size()]); serializedHooks = new SerializedValue<>(asArray); } catch (IOException e) { thrownew FlinkRuntimeException("Trigger/restore hook is not serializable", e); } }
// because the state backend can have user-defined code, it needs to be stored as // eagerly serialized value //note: 对 state backend 类做下序列化 final SerializedValue<StateBackend> serializedStateBackend; if (streamGraph.getStateBackend() == null) { serializedStateBackend = null; } else { try { serializedStateBackend = new SerializedValue<StateBackend>(streamGraph.getStateBackend()); } catch (IOException e) { thrownew FlinkRuntimeException("State backend is not serializable", e); } }
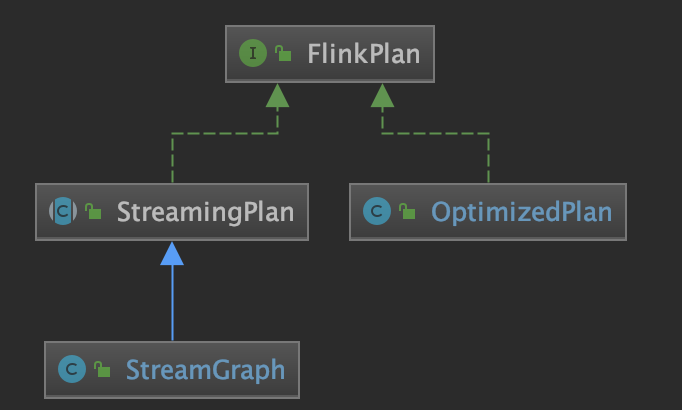
// StreamExecutionEnvironment /** * Getter of the {@link org.apache.flink.streaming.api.graph.StreamGraph} of the streaming job. * * @return The streamgraph representing the transformations */ @Internal public StreamGraph getStreamGraph(){ return getStreamGraphGenerator().generate(); }
/** * Transforms one {@code Transformation}. * note:对具体的一个 transformation 进行转换,转换成 StreamGraph 中的 StreamNode 和 StreamEdge * note:返回值为该 transform 的 id 集合,通常大小为1个(除 FeedbackTransformation) * * <p>This checks whether we already transformed it and exits early in that case. If not it * delegates to one of the transformation specific methods. */ private Collection<Integer> transform(Transformation<?> transform){
// if the max parallelism hasn't been set, then first use the job wide max parallelism // from the ExecutionConfig. //note: 如果 MaxParallelism 没有设置,使用 job 的 MaxParallelism 设置 int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism(); if (globalMaxParallelismFromConfig > 0) { transform.setMaxParallelism(globalMaxParallelismFromConfig); } }
// call at least once to trigger exceptions about MissingTypeInfo //note: 如果是 MissingTypeInfo 类型(类型不确定),将会触发异常 transform.getOutputType();
// need this check because the iterate transformation adds itself before // transforming the feedback edges if (!alreadyTransformed.containsKey(transform)) { alreadyTransformed.put(transform, transformedIds); }
if (transform.getUid() != null) { streamGraph.setTransformationUID(transform.getId(), transform.getUid()); } if (transform.getUserProvidedNodeHash() != null) { streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash()); }
if (!streamGraph.getExecutionConfig().hasAutoGeneratedUIDsEnabled()) { if (transform.getUserProvidedNodeHash() == null && transform.getUid() == null) { thrownew IllegalStateException("Auto generated UIDs have been disabled " + "but no UID or hash has been assigned to operator " + transform.getName()); } }
publicclassRandomWordCount{ publicstaticvoidmain(String[] args)throws Exception { // get the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
]]>
<p>本篇文章是 <strong>Flink 系列</strong> 的第一篇,最近计划花个一到两个月的时间以最新的 Flink-1.9 代码为例把 Flink 的主要内容梳理一遍,这个系列文章的主要内容见 <a href="https://github.com/wangzzu/
Paper 阅读: Distributed Snapshots: Determining Global States of Distributed Systemshttp://matt33.com/2019/10/27/paper-chandy-lamport/2019-10-27T15:12:51.000Z2020-06-23T14:13:17.223Z今天对分布式系统领域的一篇经典论文 —— Chandy-Lamport 算法做了一下总结,这篇论文对于分布式快照算法产生了非常巨大的影响,比如:Apache Flink、Apache Spark 的 Structured Streaming、Ray 等分布式计算引擎都是使用的这个算法做快照。这篇论文的其中一位作者 —— Lamport,他也是 Paxos 算法的提出者,2013 年图领奖得主(图领奖是计算机领域的诺贝尔奖,目前只有一位华裔 —— 姚期智院士获得过这个殊荣,没错,就是清华交叉学院姚班的姚院士)。这篇论文发表于 1985 年,算法的由来可以参考下面的小段子:
The distributed snapshot algorithm described here came about when I visited Chandy, who was then at the University of Texas in Austin. He posed the problem to me over dinner, but we had both had too much wine to think about it right then. The next morning, in the shower, I came up with the solution. When I arrived at Chandy’s office, he was waiting for me with the same solution.
stable property detection(系统的一些稳定特性检测),一个 stable property 是不可变的,如:计算停止或完成了(不会自己恢复的)、系统死锁了(不会自己恢复),通过 global states,就可以检测到这些 stable property;
用于 checkpoint。
但是获取一个系统的 global states 并不是一件容易的事情,对于一个分布式系统而言,我们需要在同一个时间点记录下这个系统的全局状态,它包括每个 process 的状态以及相关 channel 的状态(一个计算是由有限的 process 和 channel 组成的一个 graph)。这就好比:在一个满是候鸟的天空大场景下,这个场景大到一张照片无法全部覆盖,摄影师不得不拍摄多张照片,然后把它们合并成一张全景,因为多张照片不能同时拍摄、在拍摄过程中候鸟也不会静止不动,所以如何保证合成的全景照片是有意义的(它可能少拍了某些鸟或者多拍了某些鸟)?这个就是分布式快照算法要解决的问题,因为没有全局统一的一把锁,所以不可能保证所有 process 能在同一时刻记录他们的状态信息。
分布式系统模型
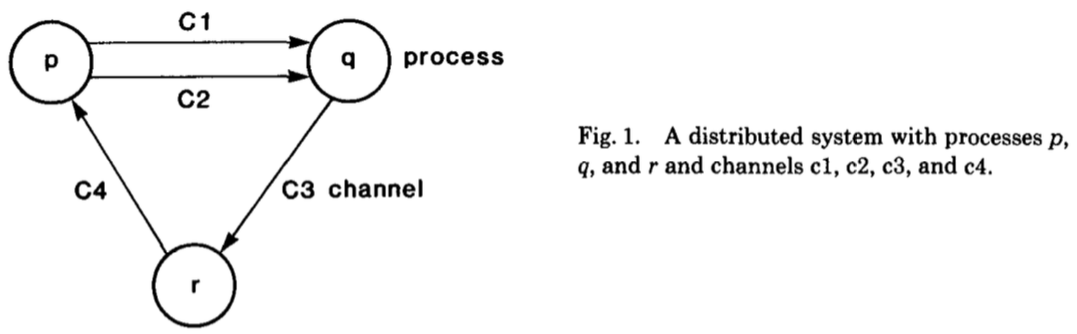
一个分布式系统包含一个有限的 process 集合和有限的 channel 集合,它可以通过一个有向的 graph(顶点代表process、边代表 channel)来描述,如下图所示:
Channel:这里为了便于解释,文章会假设一个 channel 有一个无限、零错误、有序传输的 buffer(否者还要考虑 buffer 是否 full 的情况),channel 中数据的延迟是任意的并且有限的。一个 channel 的 state 就是它从上游收到的 msg list 减去下游已经接收到的 msg list;
Process:它是由一组状态、一个初始状态和一组 event 来定义。process p 中的一个 event e 代表一个可能改变 p 本身状态和对应 channel c 状态(c 发送或接收数据都可能会改变其状态)的原子操作。
一个 event e 被定义为 $<p, s, s’, M, c>$,其中:
Process p 是 event 产生的地方;
在处理 e 之前 p 的状态是 s;
在处理 e 之后 p 的状态是 $s’$;
Channel c 它的状态会被 e 所改变;
M 是发向或发离 c 的 msg;
如果 event 没有改变任何 channel 的状态,那么 M 和 c 则为 null,可能只改变了 p 的状态(这个概念很重要,需要好好理解,是后面论证的基础)。
global state 模型
有了前面的模型抽象,这里我们可以认为一个分布式系统的 global state 就是这批 process state 和 channel state 的集合。初始的 global state 就是每个 process 都是其对应的初始状态以及每个 channel 都是 empty 集合。
一个 event e 可能会改变 global state(这里记为 S),这里定义另外一个函数:$next(S, e)$,它指的是 event e 发生在 global state S 之后的 global state,根据前面介绍的,e 处理后的 global state 变化是:p 的状态由 s 变为 s',Channel c 的状态是在原来的基础上加上(数据是发向 Channel c 的)或删除(数据是发离 Channel c 的) msg M。
这里再定义一个 $seq = (e_i: 0 \leq i \leq n)$,它代表的是这个分布式系统将要处理的 event 序列,这个 $seq$ 实际上就是 a computation of the system(这个 event 序列就代表了这个分布式计算),假设在 $e_i$ 处理前,系统的 global state 是 $S_i$(系统的初始状态时 $S_0$),那么可以得到下面公式:
$S_{i+1} = next(S_i, e_i)$, for $0 \leq i \leq n$
示例
论文中举了两个示例,这里也介绍一下,对于理解后面的论证是有帮助的。
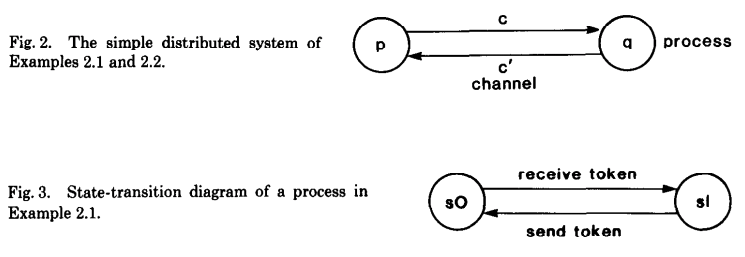
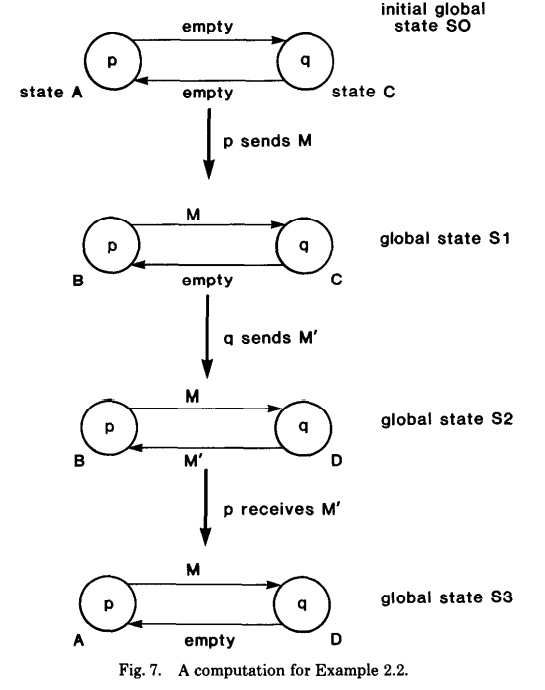
Exmaple 1:Single-token Conservation
先看一个最简单的计算系统,这个系统有两个 process p 和 q,有两个 Channel c 和 c'(下面第二个示例也是这种基本模型),如下图所示:
在这个系统中,有一个 token 它在两个 process 之间传输处理,每个 process 都有两种状态:$s_0$ 和 $s_1$,如果这个 process 不包含 token,它的状态就是 $s_0$,如果包含 token 的话,它的状态就是 $s_1$,p 的初始状态是 $s_1$,q 的初始状态是 $s_0$。而对每个 process 而言,都会有两种 event 类型(这里根据这个例子理解前面 event 的概念,如上面的图中所示):
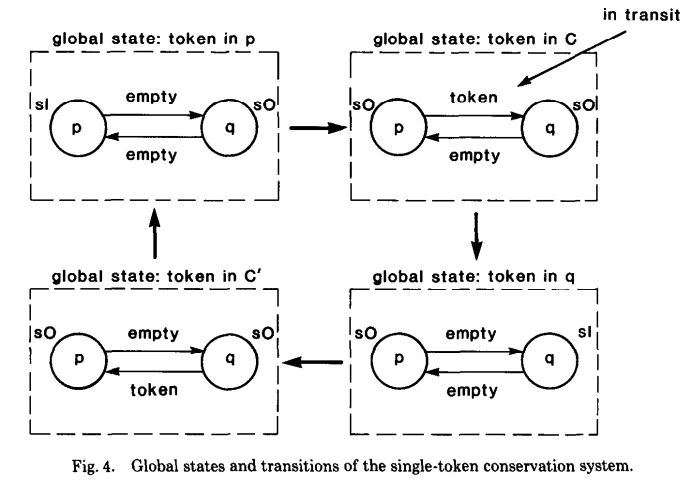
Example 1 的示例比较比较简单,在每个 global state 中正好只有一个 event(一个状态转换),但是在真实的系统中,很多情况下是一些非确定性计算(nondeterministic computation),可能同时会有多个 event 一起转换,比如:p 发送 M 和 q 发送 M' 这两个 event 同时发生(下面就是这两个 event 同时发生的情况,如下图的 global state $S_2$),那么得到的 global state 就会与预期的不同。下图是这个系统可能的一个 global state 转移情况:
Notice: 这个示例,我在看的时候,最开始一直没有搞明白,主要在 $S_2$ 这一步没有明白,后来仔细想了几次,算是明白了,这个示例举得的是一个非确定计算的示例,上面也只是系统可能出现中的一种状态,比如:p 在发送 M 之后,M 在 Channel c 中还没有被 q 接收到,q 就发送了 M'。或者换成另一种理解方式,p 发送 M 和 q 发送 M' 同时发送,上图只是把两个拆开了一下展示,于是就有了 global state S1 和 S2,再接着有可能发生的就是 S3 的情况,p 接收到了 M',状态发生了变化。这里,把这个示例当作一种在现实系统中的非确定性计算就好理解了。
Chandy-Lamport 算法
下面开始进入到算法的核心部分,这里作者介绍了一下算法的由来,以及在数学上的证明。
算法的动机/由来
Global state recording 算法工作过程如下:
每个 process 记录自己的 state;
process 之间的通道 Channel 也会记录自己的状态;
因为没有一个全局的锁,所以我们无法保证,所有的 process 和 Channel 都是在同一时刻记录的。因此,我们需要保证记录的 process 和 Channel 状态能够组成 一个有意义的 global state。
这个算法是与跟底层计算嵌套在一起,但是不会对计算产生改变、也不会影响底层的计算。这里通过一个示例来逐步引出我们的算法,假设我们是可以很自然地记录 Channel 的状态,Channel c 是 process p 和 q 的之间的传输通道,下面来分析一下它们之间的状态关系。
p 与 c 状态之间的关系
这里以前面 Single-token Conservation 的示例来分析,假设 process p 的状态记录在 global state in-p 中,p 记录的状态显示 token 是在 p 中。现在假设 Channels c 和 c' 以及 process q 的状态时记录在 global state in-c 中的,同样 c 中记录的状态也显示 token 在 c 中(因为无法保证它们在同一时刻记录,所以每个组件是有可能在不同的时刻记录)。组成的 global state 显示系统中有两个 token,一个是在 p 中、一个是在 c中。但是由于这个系统是 single-token,它是不可能同时出现两个 token 的,所以一定是哪里有问题了,这样组成的 global state 不是有意义的。先定义两个变量:
$n$:在 p 的状态记录前,p 发往 Channel c 的 msg 数;
$n’$:在 c 的状态记录前,p 发往 Channel c 的 msg 数;
上面出现的情况就是 $n < n’$.
假设另一种情况,c 的状态记录在 in-p 中,而 p、q、c' 的状态记录在 in-c,那么这样组成的 global state 会显示系统没有 token,这个组成的 global state 同样也是没有意义的,这就是 $n > n’$ 的情况。
从前面的分析中,可以得到:这里有个一致的全局状态要求
$n = n’$
q 与 c 状态之间的关系
这里,再定义另外两个变量:
$m$:在 q 的状态记录前,q 从 Channel c 中接收到的 msg 数;
$m’$:在 c 的状态记录前,q 从 Channel c 中接收到的 msg 数;
跟前面的分析类似,这里也会有一个一致性的要求:
$m = m’$
分析
在任何一种状态下,都要求 Channel c 下游接收到的 msg 数不能超过 p 发送给 Channel 的 msg 条数,即:
现在我们证明: 这个 $seq’$ 序列中所有 preEvent 处理完之后的 global state 就是 $S_*$ ,只需要证明下面两点即可:
$S_*$ 中的每个 p 的状态是与 p 处理完所有 preEvent 之后的状态相同的,这个并不用证明,因为 perEvent 的概念就是这样来的,它指的就是那些在 snapshot 前要处理的 event 列表;
$S_*$ 中的每个 Channel c 的状态:所有 preEvent 发往 c 的数据列表,减去所有 preEvent 从 c 接收到数据列表。
这里看下上面的第二点:假设 c 是 process p 和 q 之前的 Channel,$S_*$ 中关于 Channel c 的状态指的是,q 在记录自己的状态后在收到 marker 前从 c 收到的数据列表。而 c 在收到 marker 前接收到的数据列表都是 preEvent 发送过去的,所以上面第二点也就是完全得证了。
它们在当前 Operator State 中会把未处理和正在传输过程中的 record 做为 snapshot 的一部分持久化,这会导致 snapshot 非常大,记录了很多其实并不需要的数据。
本篇论文中提出了一个新的 global consistent snapshot 算法 —— Asynchronous Barrier Snapshot(ABS),它是一个轻量级的算法,非常适合现代 dataflow 系统,数据存储空间占用也非常小(论文原话是 Our solution provides asynchronous state snapshots with low space costs that contain only operator states in acyclic execution topologies.)。另外,这个算法不会影响作业计算,性能开销比较小。
]]>
<p>本篇文章是对 <a href="https://arxiv.org/pdf/1506.08603.pdf" target="_blank" rel="external">Lightweight Asynchronous Snapshots for Distributed D
Paper 阅读: Real-Time Machine Learning: The Missing Pieceshttp://matt33.com/2019/10/19/paper-ray1/2019-10-19T14:26:20.000Z2020-06-23T14:13:17.223Z这周抽空看了关于 ray 的一篇论文,论文是 2017 年发表的(见:Real-Time Machine Learning: The Missing Pieces,他们比较新的论文是 18 年发表的,见:Ray: A Distributed Framework for Emerging AI Applications),虽然论文描述的架构与现在 ray 真正的构架实现已经有了较大的不同,主要也是 ray 这两年发展比较快,架构做了很多的优化,不过本篇论文依然值得仔细阅读学习 一下的,这篇论文也展示了 ray 最初设计实现的出发点。
本章不会严格按照论文翻译,整体会按照下面的思路来叙述:
遇到的问题什么?
当前业内的方案是什么?
论文提出了什么样的解决方案?达到了什么效果?
问题
现在有越来越多的 ML 应用,不仅仅使用静态模型进行训练预测,它们会使用动态、实时决策的反馈来实时调整应用,这种场景就给计算模型提出了一些新的要求:
Other Systems 像 Open MPI 和基于 actor 模型变体的系统(Orleans 和 Erlang)提供了低延迟(R1)和高吞吐(R2)的分布式计算。尽管这些系统也可以支持我们执行模型的需要(R3-R5,并且已经在 ML 中应用了),但是很多系统 level 的逻辑需求却需要应用程序自己去实现,比如:容错和 task 调度的本地感知。
综上,业内并没有一套可以完全符合我们的需求的系统,所以最好的办法就是重新造轮子,从头开始设计和写一套系统,业内对这块也有了很多的实践,虽然是重头开始设计,但还是可以从业内现有的系统中借鉴很多的经验(毕竟这套系统设计的出发点,也考虑到了通用性,而不仅仅用在 ML 领域)。
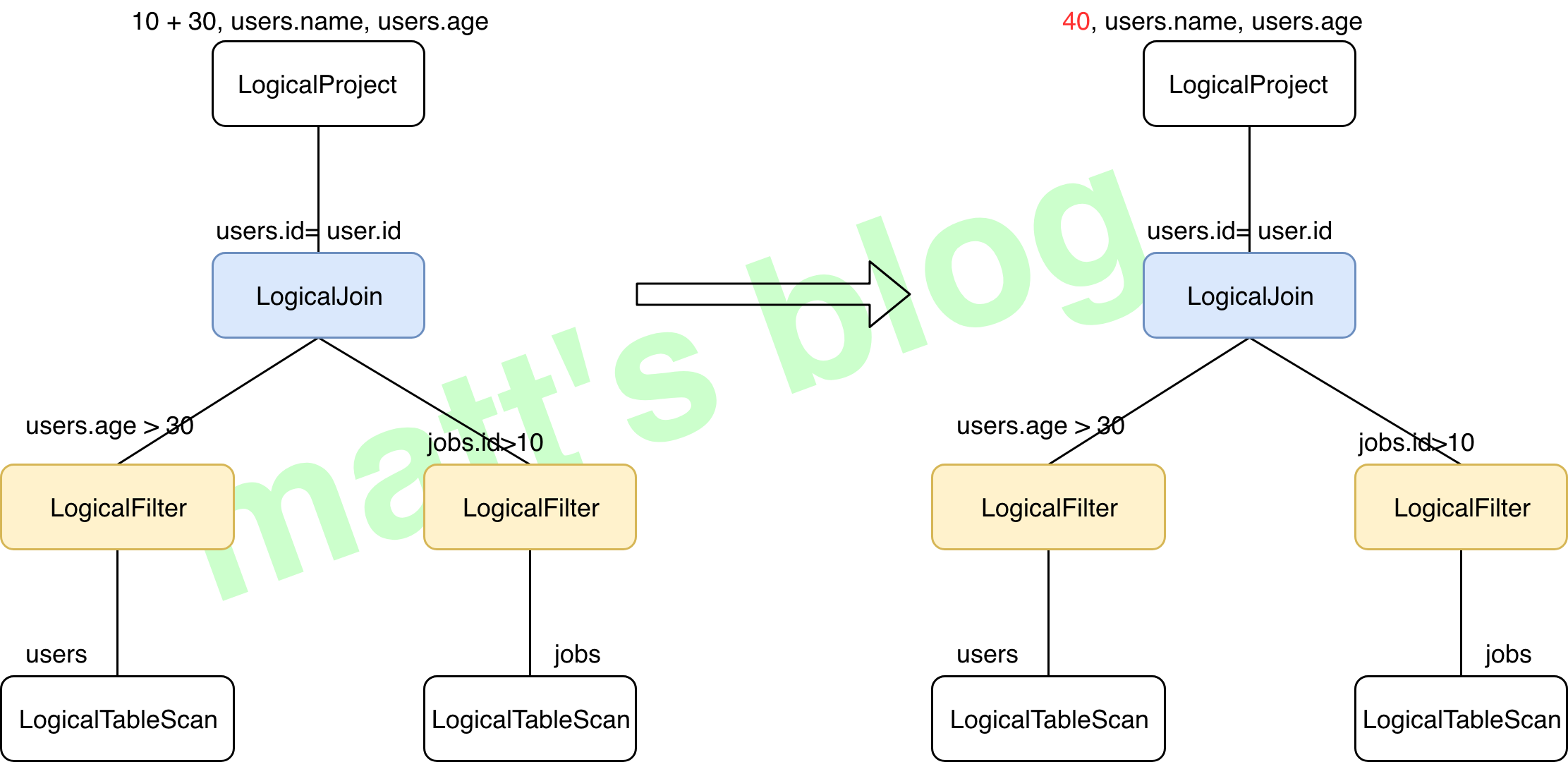
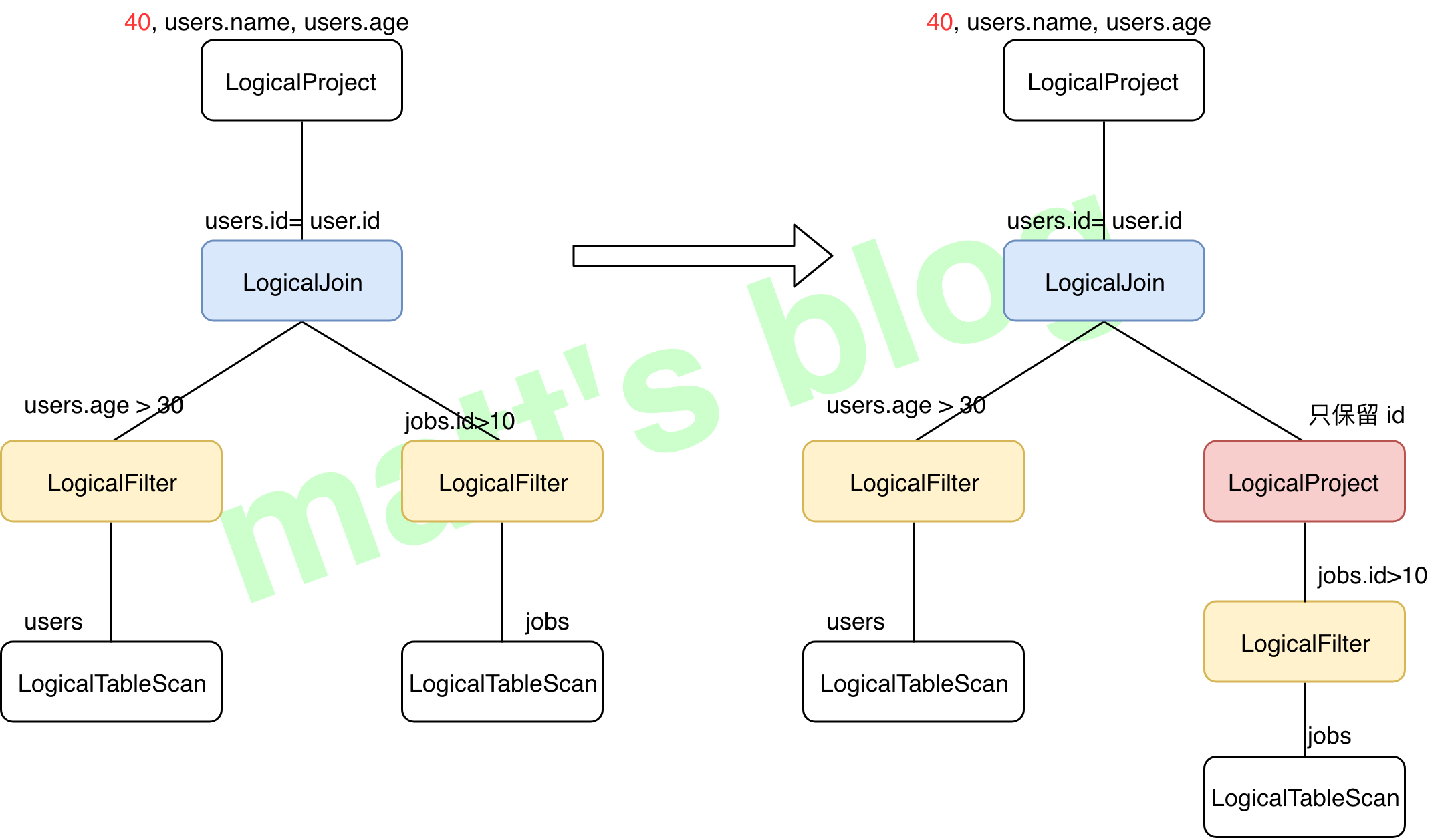
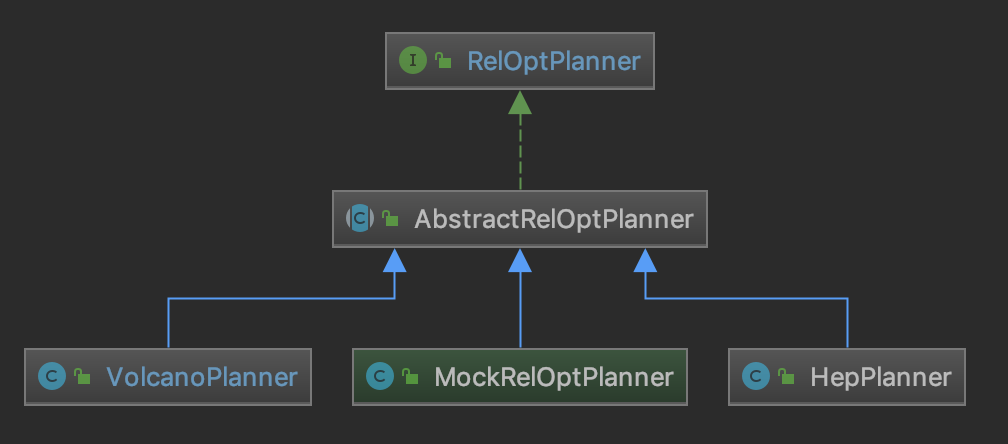
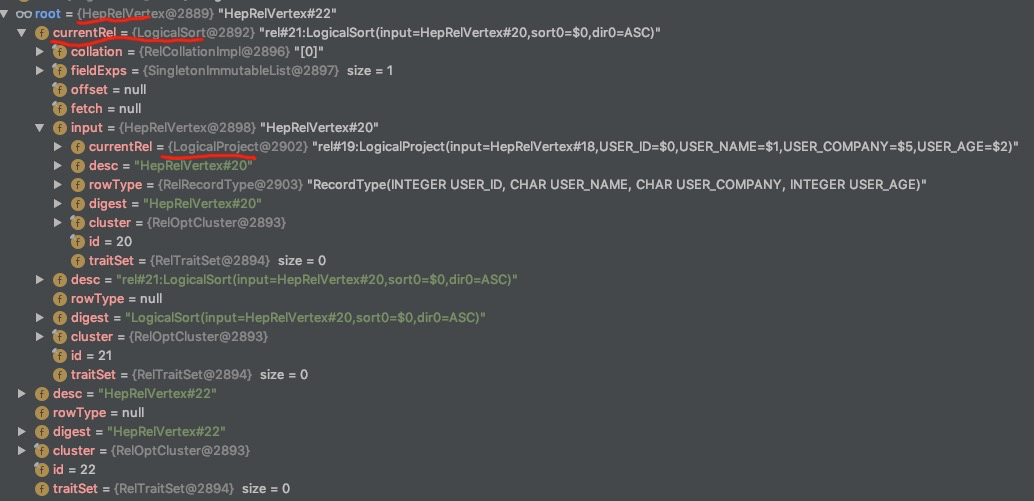
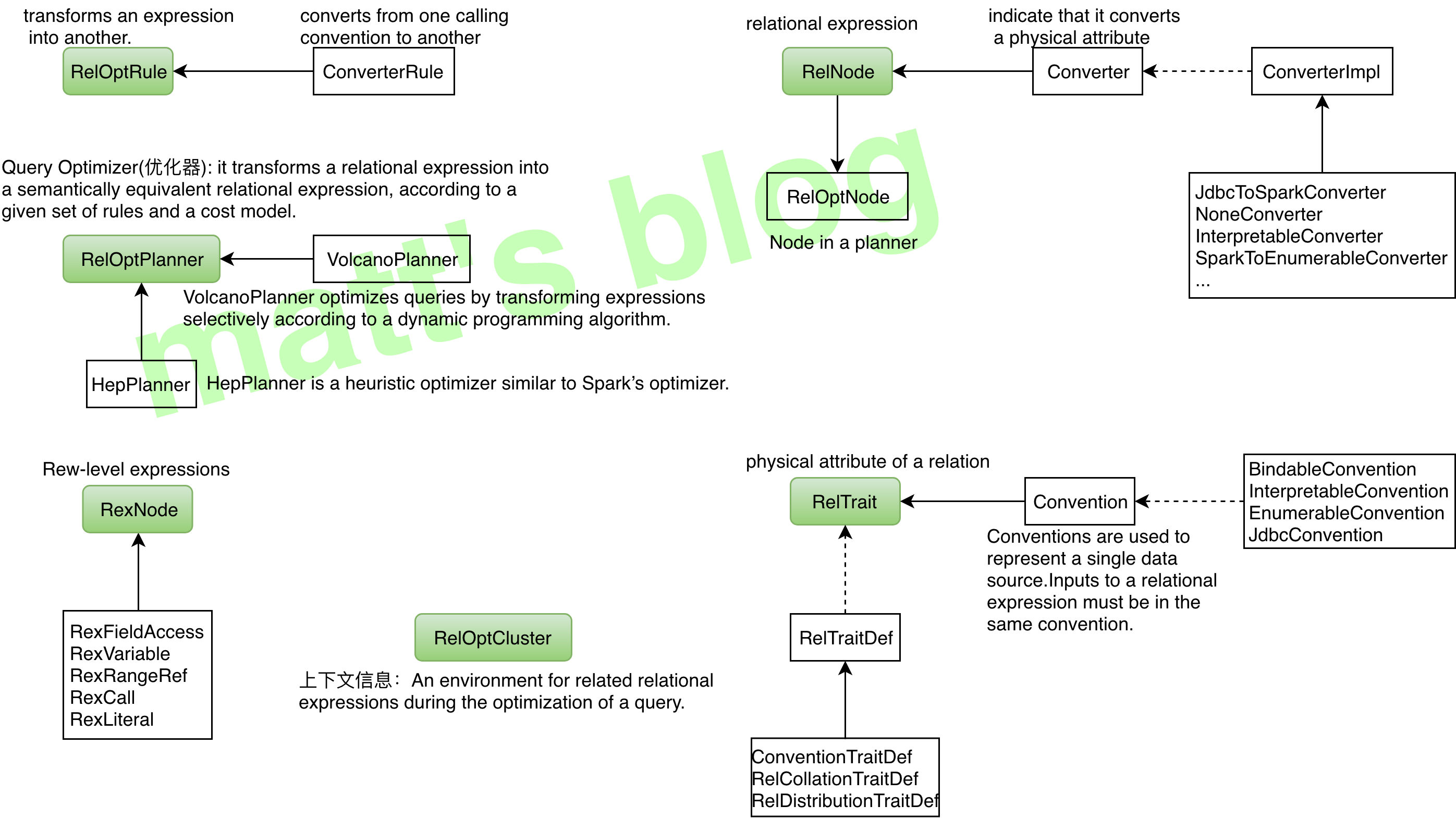
// org.apache.calcite.plan.hep.HepRelVertex /** * HepRelVertex wraps a real {@link RelNode} as a vertex in a DAG representing * the entire query expression. * note:HepRelVertex 将一个 RelNode 封装为一个 DAG 中的 vertex(DAG 代表整个 query expression) */ publicclassHepRelVertexextendsAbstractRelNode{ //~ Instance fields --------------------------------------------------------
/** * Wrapped rel currently chosen for implementation of expression. */ private RelNode currentRel; }
//org.apache.calcite.plan.hep.HepInstruction /** Instruction that executes a given rule. */ //note: 执行指定 rule 的 Instruction staticclassRuleInstanceextendsHepInstruction{ /** * Description to look for, or null if rule specified explicitly. */ String ruleDescription;
/** * Explicitly specified rule, or rule looked up by planner from * description. * note:设置其 Rule */ RelOptRule rule;
voidinitialize(boolean clearCache){ if (!clearCache) { return; }
if (ruleDescription != null) { // Look up anew each run. rule = null; } }
//org.apache.calcite.plan.hep.HepPlanner //note: 根据 RelNode 构建一个 Graph private HepRelVertex addRelToGraph( RelNode rel){ // Check if a transformation already produced a reference // to an existing vertex. //note: 检查这个 rel 是否在 graph 中转换了 if (graph.vertexSet().contains(rel)) { return (HepRelVertex) rel; }
// Recursively add children, replacing this rel's inputs // with corresponding child vertices. //note: 递归地增加子节点,使用子节点相关的 vertices 代替 rel 的 input final List<RelNode> inputs = rel.getInputs(); final List<RelNode> newInputs = new ArrayList<>(); for (RelNode input1 : inputs) { HepRelVertex childVertex = addRelToGraph(input1); //note: 递归进行转换 newInputs.add(childVertex); //note: 每个 HepRelVertex 只记录其 Input }
if (!Util.equalShallow(inputs, newInputs)) { //note: 不相等的情况下 RelNode oldRel = rel; rel = rel.copy(rel.getTraitSet(), newInputs); onCopy(oldRel, rel); } // Compute digest first time we add to DAG, // otherwise can't get equivVertex for common sub-expression //note: 计算 relNode 的 digest //note: Digest 的意思是: //note: A short description of this relational expression's type, inputs, and //note: other properties. The string uniquely identifies the node; another node //note: is equivalent if and only if it has the same value. rel.recomputeDigest();
// try to find equivalent rel only if DAG is allowed //note: 如果允许 DAG 的话,检查是否有一个等价的 HepRelVertex,有的话直接返回 if (!noDag) { // Now, check if an equivalent vertex already exists in graph. String digest = rel.getDigest(); HepRelVertex equivVertex = mapDigestToVertex.get(digest); if (equivVertex != null) { //note: 已经存在 // Use existing vertex. return equivVertex; } }
// No equivalence: create a new vertex to represent this rel. //note: 创建一个 vertex 代替 rel HepRelVertex newVertex = new HepRelVertex(rel); graph.addVertex(newVertex); //note: 记录 Vertex updateVertex(newVertex, rel);//note: 更新相关的缓存,比如 mapDigestToVertex map
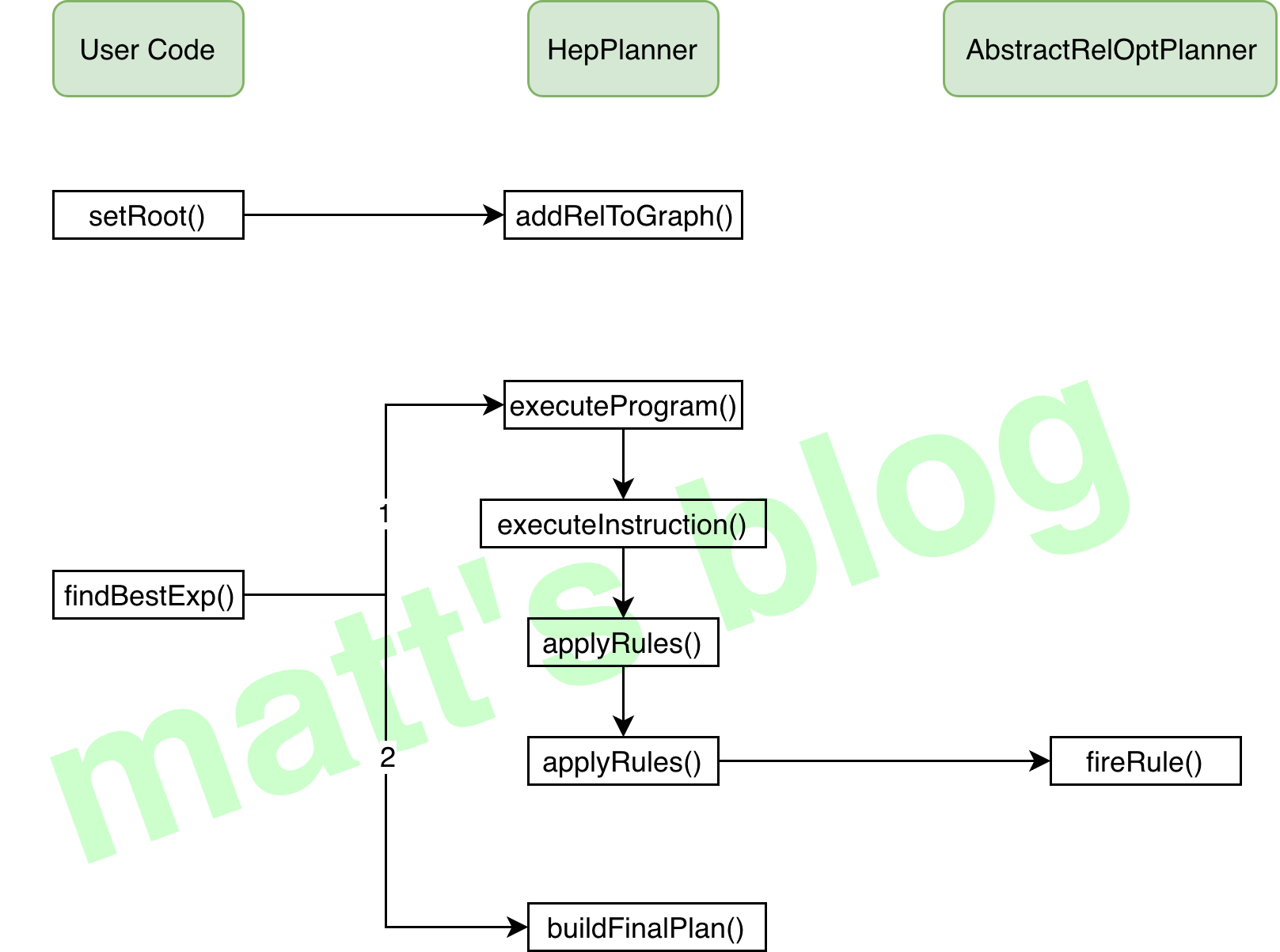
//org.apache.calcite.plan.hep.HepPlanner privatevoidexecuteProgram(HepProgram program){ HepProgram savedProgram = currentProgram; //note: 保留当前的 Program currentProgram = program; currentProgram.initialize(program == mainProgram);//note: 如果是在同一个 Program 的话,保留上次 cache for (HepInstruction instruction : currentProgram.instructions) { instruction.execute(this); //note: 按 Rule 进行优化(会调用 executeInstruction 方法) int delta = nTransformations - nTransformationsLastGC; if (delta > graphSizeLastGC) { // The number of transformations performed since the last // garbage collection is greater than the number of vertices in // the graph at that time. That means there should be a // reasonable amount of garbage to collect now. We do it this // way to amortize garbage collection cost over multiple // instructions, while keeping the highwater memory usage // proportional to the graph size. //note: 进行转换的次数已经大于 DAG Graph 中的顶点数,这就意味着已经产生大量垃圾需要进行清理 collectGarbage(); } } currentProgram = savedProgram; }
boolean fixedPoint; //note: 两种情况会跳出循环,一种是达到 matchLimit 限制,一种是遍历一遍不会再有新的 transform 产生 do { //note: 按照遍历规则获取迭代器 Iterator<HepRelVertex> iter = getGraphIterator(root); fixedPoint = true; while (iter.hasNext()) { HepRelVertex vertex = iter.next();//note: 遍历每个 HepRelVertex for (RelOptRule rule : rules) {//note: 遍历每个 rules //note: 进行规制匹配,也是真正进行相关操作的地方 HepRelVertex newVertex = applyRule(rule, vertex, forceConversions); if (newVertex == null || newVertex == vertex) { continue; } ++nMatches; //note: 超过 MatchLimit 的限制 if (nMatches >= currentProgram.matchLimit) { return; } if (fullRestartAfterTransformation) { //note: 发生 transformation 后,从 root 节点再次开始 iter = getGraphIterator(root); } else { // To the extent possible, pick up where we left // off; have to create a new iterator because old // one was invalidated by transformation. //note: 尽可能从上次进行后的节点开始 iter = getGraphIterator(newVertex); if (currentProgram.matchOrder == HepMatchOrder.DEPTH_FIRST) { //note: 这样做的原因就是为了防止有些 HepRelVertex 遗漏了 rule 的匹配(每次从 root 开始是最简单的算法),因为可能出现下推 nMatches = depthFirstApply(iter, rules, forceConversions, nMatches); if (nMatches >= currentProgram.matchLimit) { return; } } // Remember to go around again since we're // skipping some stuff. //note: 再来一遍,因为前面有跳过一些节点 fixedPoint = false; } break; } } } while (!fixedPoint); }
Add Rule matches to Queue:向 Rule Match Queue 中添加相应的 Rule Match;
Apply Rule match transformations to plan gragh:应用 Rule Match 对 plan graph 做 transformation 优化(Rule specifies an Operator sub-graph to match and logic to generate equivalent better sub-graph);
Iterate for fixed iterations or until cost doesn’t change:进行相应的迭代,直到 cost 不再变化或者 Rule Match Queue 中 rule match 已经全部应用完成;
Match importance based on cost of RelNode and height:Rule Match 的 importance 依赖于 RelNode 的 cost 和深度。
RelSet is an equivalence-set of expressions that is, a set of expressions which have identical semantics. We are generally interested in using the expression which has the lowest cost. All of the expressions in an RelSet have the same calling convention.
classRelSet{ // 记录属于这个 RelSet 的所有 RelNode final List<RelNode> rels = new ArrayList<>(); /** * Relational expressions that have a subset in this set as a child. This * is a multi-set. If multiple relational expressions in this set have the * same parent, there will be multiple entries. */ final List<RelNode> parents = new ArrayList<>(); //note: 具体相同物理属性的子集合(本质上 RelSubset 并不记录 RelNode,也是通过 RelSet 按物理属性过滤得到其 RelNode 子集合,见下面的 RelSubset 部分) final List<RelSubset> subsets = new ArrayList<>();
/** * List of {@link AbstractConverter} objects which have not yet been * satisfied. */ final List<AbstractConverter> abstractConverters = new ArrayList<>();
/** * Set to the superseding set when this is found to be equivalent to another * set. * note:当发现与另一个 RelSet 有相同的语义时,设置为替代集合 */ RelSet equivalentSet; RelNode rel;
/** * Variables that are set by relational expressions in this set and available for use by parent and child expressions. * note:在这个集合中 relational expression 设置的变量,父类和子类 expression 可用的变量 */ final Set<CorrelationId> variablesPropagated;
/** * Variables that are used by relational expressions in this set. * note:在这个集合中被 relational expression 使用的变量 */ final Set<CorrelationId> variablesUsed; finalint id;
publicclassRelSubsetextendsAbstractRelNode{ /** * cost of best known plan (it may have improved since) * note: 已知最佳 plan 的 cost */ RelOptCost bestCost;
/** * The set this subset belongs to. * RelSubset 所属的 RelSet,在 RelSubset 中并不记录具体的 RelNode,直接记录在 RelSet 的 rels 中 */ final RelSet set;
/** * best known plan * note: 已知的最佳 plan */ RelNode best;
/** * Flag indicating whether this RelSubset's importance was artificially * boosted. * note: 标志这个 RelSubset 的 importance 是否是人为地提高了 */ boolean boosted;
//org.apache.calcite.plan.volcano.RuleQueue /** * Recomputes the importance of the given RelSubset. * note:重新计算指定的 RelSubset 的 importance * note:如果为 true,即使 subset 没有注册,也会强制 importance 更新 * * @param subset RelSubset whose importance is to be recomputed * @param force if true, forces an importance update even if the subset has * not been registered */ publicvoidrecompute(RelSubset subset, boolean force){ Double previousImportance = subsetImportances.get(subset); if (previousImportance == null) { //note: subset 还没有注册的情况下 if (!force) { //note: 如果不是强制,可以直接先返回 // Subset has not been registered yet. Don't worry about it. return; }
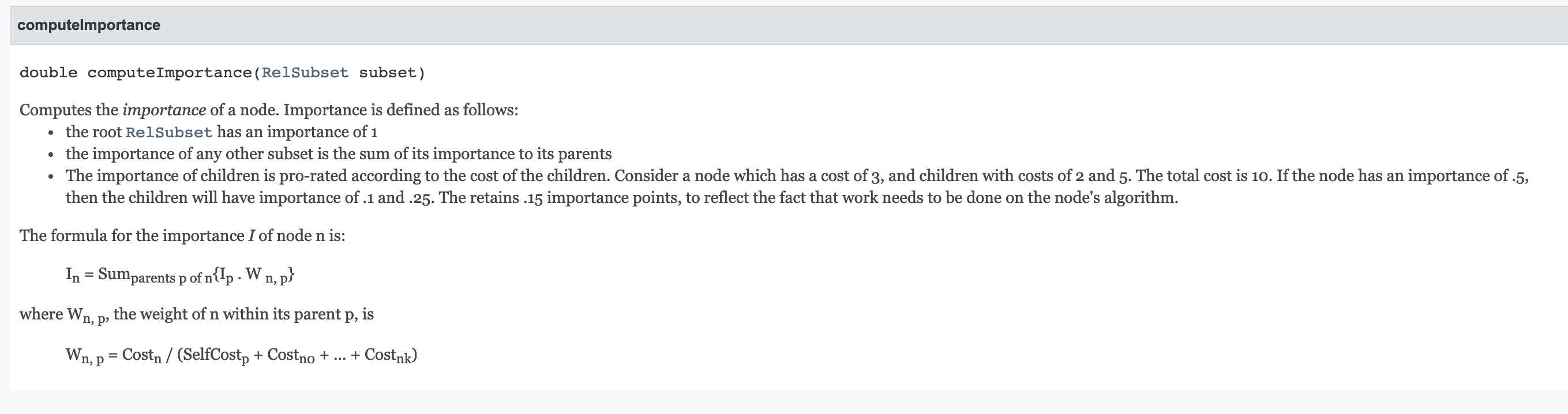
// 计算一个节点的 importance doublecomputeImportance(RelSubset subset){ double importance; if (subset == planner.root) { // The root always has importance = 1 //note: root RelSubset 的 importance 为1 importance = 1.0; } else { final RelMetadataQuery mq = subset.getCluster().getMetadataQuery();
// The importance of a subset is the max of its importance to its // parents //note: 计算其相对于 parent 的最大 importance,多个 parent 的情况下,选择一个最大值 importance = 0.0; for (RelSubset parent : subset.getParentSubsets(planner)) { //note: 计算这个 RelSubset 相对于 parent 的 importance finaldouble childImportance = computeImportanceOfChild(mq, subset, parent); //note: 选择最大的 importance importance = Math.max(importance, childImportance); } } LOGGER.trace("Importance of [{}] is {}", subset, importance); return importance; }
//org.apache.calcite.plan.volcano.VolcanoRuleMatch /** * Computes the importance of this rule match. * note:计算 rule match 的 importance * * @return importance of this rule match */ doublecomputeImportance(){ assert rels[0] != null; //note: rels[0] 这个 Rule Match 对应的 RelSubset RelSubset subset = volcanoPlanner.getSubset(rels[0]); double importance = 0; if (subset != null) { //note: 获取 RelSubset 的 importance importance = volcanoPlanner.ruleQueue.getImportance(subset); } //note: Returns a guess as to which subset the result of this rule will belong to. final RelSubset targetSubset = guessSubset(); if ((targetSubset != null) && (targetSubset != subset)) { // If this rule will generate a member of an equivalence class // which is more important, use that importance. //note: 获取 targetSubset 的 importance finaldouble targetImportance = volcanoPlanner.ruleQueue.getImportance(targetSubset); if (targetImportance > importance) { importance = targetImportance;
// If the equivalence class is cheaper than the target, bump up // the importance of the rule. A converter is an easy way to // make the plan cheaper, so we'd hate to miss this opportunity. // // REVIEW: jhyde, 2007/12/21: This rule seems to make sense, but // is disabled until it has been proven. // // CHECKSTYLE: IGNORE 3 if ((subset != null) && subset.bestCost.isLt(targetSubset.bestCost) && false) { //note: 肯定不会进入 importance *= targetSubset.bestCost.divideBy(subset.bestCost); importance = Math.min(importance, 0.99); } } }
//org.apache.calcite.plan.volcano.VolcanoPlanner /** * Creates a uninitialized <code>VolcanoPlanner</code>. To fully initialize it, the caller must register the desired set of relations, rules, and calling conventions. * note: 创建一个没有初始化的 VolcanoPlanner,如果要进行初始化,调用者必须注册 set of relations、rules、calling conventions. */ publicVolcanoPlanner(){ this(null, null); }
/** * Creates a {@code VolcanoPlanner} with a given cost factory. * note: 创建 VolcanoPlanner 实例,并制定 costFactory(默认为 VolcanoCost.FACTORY) */ publicVolcanoPlanner(RelOptCostFactory costFactory, // Context externalContext){ super(costFactory == null ? VolcanoCost.FACTORY : costFactory, // externalContext); this.zeroCost = this.costFactory.makeZeroCost(); }
// Each of this rule's operands is an 'entry point' for a rule call. Register each operand against all concrete sub-classes that could match it. //note: 记录每个 sub-classes 与 operand 的关系(如果能 match 的话,就记录一次)。一个 RelOptRuleOperand 只会有一个 class 与之对应,这里找的是 subclass for (RelOptRuleOperand operand : rule.getOperands()) { for (Class<? extends RelNode> subClass : subClasses(operand.getMatchedClass())) { classOperands.put(subClass, operand); } }
// If this is a converter rule, check that it operates on one of the // kinds of trait we are interested in, and if so, register the rule // with the trait. //note: 对于 ConverterRule 的操作,如果其 ruleTraitDef 类型包含在我们初始化的 traitDefs 中, //note: 就注册这个 converterRule 到 ruleTraitDef 中 //note: 如果不包含 ruleTraitDef,这个 ConverterRule 在本次优化的过程中是用不到的 if (rule instanceof ConverterRule) { ConverterRule converterRule = (ConverterRule) rule;
final RelTrait ruleTrait = converterRule.getInTrait(); final RelTraitDef ruleTraitDef = ruleTrait.getTraitDef(); if (traitDefs.contains(ruleTraitDef)) { //note: 这里注册好像也没有用到 ruleTraitDef.registerConverterRule(this, converterRule); } }
这一步简单来说就是:Changes a relational expression to an equivalent one with a different set of traits,对相应的 RelNode 做 converter 操作,这里实际上也会做很多的内容,这部分会放在第三步讲解,主要是 registerImpl() 方法的实现。
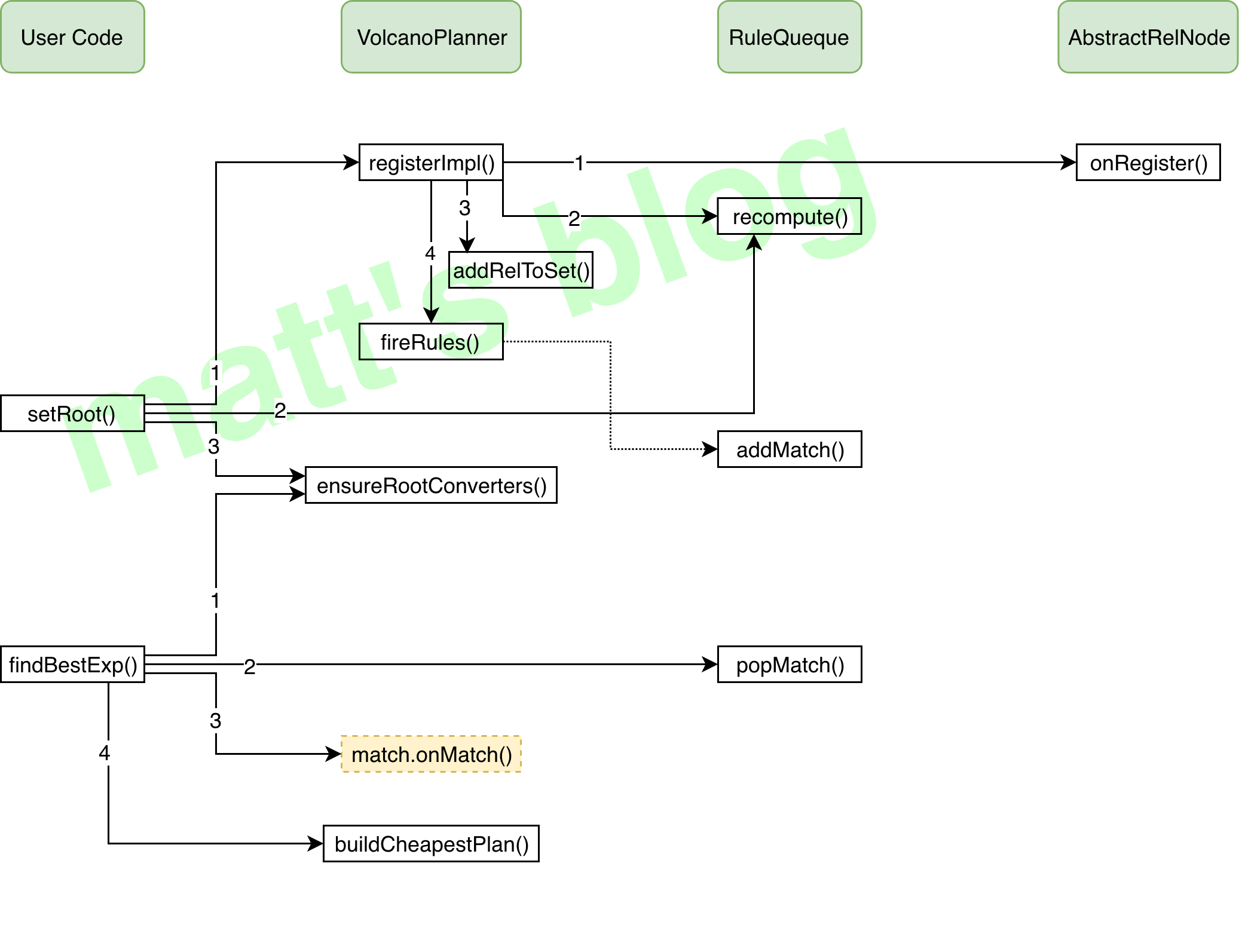
//org.apache.calcite.plan.volcano.VolcanoPlanner publicvoidsetRoot(RelNode rel){ // We're registered all the rules, and therefore RelNode classes, // we're interested in, and have not yet started calling metadata providers. // So now is a good time to tell the metadata layer what to expect. registerMetadataRels();
// Making a node the root changes its importance. //note: 重新计算 root subset 的 importance this.ruleQueue.recompute(this.root); //Ensures that the subset that is the root relational expression contains converters to all other subsets in its equivalence set. ensureRootConverters(); }
//org.apache.calcite.plan.volcano.VolcanoPlanner /** * Registers a new expression <code>exp</code> and queues up rule matches. * If <code>set</code> is not null, makes the expression part of that * equivalence set. If an identical expression is already registered, we * don't need to register this one and nor should we queue up rule matches. * * note:注册一个新的 expression;对 rule match 进行排队; * note:如果 set 不为 null,那么就使 expression 成为等价集合(RelSet)的一部分 * note:rel:必须是 RelSubset 或者未注册的 RelNode * @param rel relational expression to register. Must be either a * {@link RelSubset}, or an unregistered {@link RelNode} * @param set set that rel belongs to, or <code>null</code> * @return the equivalence-set */ private RelSubset registerImpl( RelNode rel, RelSet set){ if (rel instanceof RelSubset) { //note: 如果是 RelSubset 类型,已经注册过了 return registerSubset(set, (RelSubset) rel); //note: 做相应的 merge }
assert !isRegistered(rel) : "already been registered: " + rel; if (rel.getCluster().getPlanner() != this) { //note: cluster 中 planner 与这里不同 thrownew AssertionError("Relational expression " + rel + " belongs to a different planner than is currently being used."); }
// Now is a good time to ensure that the relational expression // implements the interface required by its calling convention. //note: 确保 relational expression 可以实施其 calling convention 所需的接口 //note: 获取 RelNode 的 RelTraitSet final RelTraitSet traits = rel.getTraitSet(); //note: 获取其 ConventionTraitDef final Convention convention = traits.getTrait(ConventionTraitDef.INSTANCE); assert convention != null; if (!convention.getInterface().isInstance(rel) && !(rel instanceof Converter)) { thrownew AssertionError("Relational expression " + rel + " has calling-convention " + convention + " but does not implement the required interface '" + convention.getInterface() + "' of that convention"); } if (traits.size() != traitDefs.size()) { thrownew AssertionError("Relational expression " + rel + " does not have the correct number of traits: " + traits.size() + " != " + traitDefs.size()); }
// Record its provenance. (Rule call may be null.) //note: 记录 RelNode 的来源 if (ruleCallStack.isEmpty()) { //note: 不知道来源时 provenanceMap.put(rel, Provenance.EMPTY); } else { //note: 来自 rule 触发的情况 final VolcanoRuleCall ruleCall = ruleCallStack.peek(); provenanceMap.put( rel, new RuleProvenance( ruleCall.rule, ImmutableList.copyOf(ruleCall.rels), ruleCall.id)); }
// If it is equivalent to an existing expression, return the set that // the equivalent expression belongs to. //note: 根据 RelNode 的 digest(摘要,全局唯一)判断其是否已经有对应的 RelSubset,有的话直接放回 String key = rel.getDigest(); RelNode equivExp = mapDigestToRel.get(key); if (equivExp == null) { //note: 还没注册的情况 // do nothing } elseif (equivExp == rel) {//note: 已经有其缓存信息 return getSubset(rel); } else { assert RelOptUtil.equal( "left", equivExp.getRowType(), "right", rel.getRowType(), Litmus.THROW); RelSet equivSet = getSet(equivExp); //note: 有 RelSubset 但对应的 RelNode 不同时,这里对其 RelSet 做下 merge if (equivSet != null) { LOGGER.trace( "Register: rel#{} is equivalent to {}", rel.getId(), equivExp.getDescription()); return registerSubset(set, getSubset(equivExp)); } }
//note: Converters are in the same set as their children. if (rel instanceof Converter) { final RelNode input = ((Converter) rel).getInput(); final RelSet childSet = getSet(input); if ((set != null) && (set != childSet) && (set.equivalentSet == null)) { LOGGER.trace( "Register #{} {} (and merge sets, because it is a conversion)", rel.getId(), rel.getDigest()); merge(set, childSet); registerCount++;
// During the mergers, the child set may have changed, and since // we're not registered yet, we won't have been informed. So // check whether we are now equivalent to an existing // expression. if (fixUpInputs(rel)) { rel.recomputeDigest(); key = rel.getDigest(); RelNode equivRel = mapDigestToRel.get(key); if ((equivRel != rel) && (equivRel != null)) { assert RelOptUtil.equal( "rel rowtype", rel.getRowType(), "equivRel rowtype", equivRel.getRowType(), Litmus.THROW);
// make sure this bad rel didn't get into the // set in any way (fixupInputs will do this but it // doesn't know if it should so it does it anyway) set.obliterateRelNode(rel);
// There is already an equivalent expression. Use that // one, and forget about this one. return getSubset(equivRel); } } } else { set = childSet; } }
// Place the expression in the appropriate equivalence set. //note: 把 expression 放到合适的 等价集 中 //note: 如果 RelSet 不存在,这里会初始化一个 RelSet if (set == null) { set = new RelSet( nextSetId++, Util.minus( RelOptUtil.getVariablesSet(rel), rel.getVariablesSet()), RelOptUtil.getVariablesUsed(rel)); this.allSets.add(set); }
// Chain to find 'live' equivalent set, just in case several sets are // merging at the same time. //note: 递归查询,一直找到最开始的 语义相等的集合,防止不同集合同时被 merge while (set.equivalentSet != null) { set = set.equivalentSet; }
// Allow each rel to register its own rules. registerClass(rel);
//note: 缓存相关信息,返回的 key 之前对应的 value final RelNode xx = mapDigestToRel.put(key, rel); assert xx == null || xx == rel : rel.getDigest();
LOGGER.trace("Register {} in {}", rel.getDescription(), subset.getDescription());
// This relational expression may have been registered while we // recursively registered its children. If this is the case, we're done. if (xx != null) { return subset; }
// Create back-links from its children, which makes children more // important. //note: 如果是 root,初始化其 importance 为 1.0 if (rel == this.root) { ruleQueue.subsetImportances.put( subset, 1.0); // todo: remove } //note: 将 Rel 的 input 对应的 RelSubset 的 parents 设置为当前的 Rel //note: 也就是说,一个 RelNode 的 input 为其对应 RelSubset 的 children 节点 for (RelNode input : rel.getInputs()) { RelSubset childSubset = (RelSubset) input; childSubset.set.parents.add(rel);
// Child subset is more important now a new parent uses it. //note: 重新计算 RelSubset 的 importance ruleQueue.recompute(childSubset); } if (rel == this.root) {// TODO: 2019-03-11 这里为什么要删除呢? ruleQueue.subsetImportances.remove(subset); }
//org.apache.calcite.plan.volcano.VolcanoPlanner /** * Fires all rules matched by a relational expression. * note: 触发满足这个 relational expression 的所有 rules * * @param rel Relational expression which has just been created (or maybe * from the queue) * @param deferred If true, each time a rule matches, just add an entry to * the queue. */ voidfireRules( RelNode rel, boolean deferred){ for (RelOptRuleOperand operand : classOperands.get(rel.getClass())) { if (operand.matches(rel)) { //note: rule 匹配的情况 final VolcanoRuleCall ruleCall; if (deferred) { //note: 这里默认都是 true,会把 RuleMatch 添加到 queue 中 ruleCall = new DeferringRuleCall(this, operand); } else { ruleCall = new VolcanoRuleCall(this, operand); } ruleCall.match(rel); } } }
/** * A rule call which defers its actions. Whereas {@link RelOptRuleCall} * invokes the rule when it finds a match, a <code>DeferringRuleCall</code> * creates a {@link VolcanoRuleMatch} which can be invoked later. */ privatestaticclassDeferringRuleCallextendsVolcanoRuleCall{ DeferringRuleCall( VolcanoPlanner planner, RelOptRuleOperand operand) { super(planner, operand); }
/** * Rather than invoking the rule (as the base method does), creates a * {@link VolcanoRuleMatch} which can be invoked later. * note:不是直接触发 rule,而是创建一个后续可以被触发的 VolcanoRuleMatch */ protectedvoidonMatch(){ final VolcanoRuleMatch match = new VolcanoRuleMatch( volcanoPlanner, getOperand0(), //note: 其实就是 operand rels, nodeInputs); volcanoPlanner.ruleQueue.addMatch(match); } }
//org.apache.calcite.plan.volcano.RuleQueue /** * Adds a rule match. The rule-matches are automatically added to all * existing {@link PhaseMatchList per-phase rule-match lists} which allow * the rule referenced by the match. * note:添加一个 rule match(添加到所有现存的 match phase 中) */ voidaddMatch(VolcanoRuleMatch match){ final String matchName = match.toString(); for (PhaseMatchList matchList : matchListMap.values()) { if (!matchList.names.add(matchName)) { // Identical match has already been added. continue; }
//org.apache.calcite.plan.volcano.VolcanoPlanner /** * Finds the most efficient expression to implement the query given via * {@link org.apache.calcite.plan.RelOptPlanner#setRoot(org.apache.calcite.rel.RelNode)}. * * note:找到最有效率的 relational expression,这个算法包含一系列阶段,每个阶段被触发的 rules 可能不同 * <p>The algorithm executes repeatedly in a series of phases. In each phase * the exact rules that may be fired varies. The mapping of phases to rule * sets is maintained in the {@link #ruleQueue}. * * note:在每个阶段,planner 都会初始化这个 RelSubset 的 importance,planner 会遍历 rule queue 中 rules 直到: * note:1. rule queue 变为空; * note:2. 对于 ambitious planner,最近 cost 不再提高时(具体来说,第一次找到一个可执行计划时,需要达到需要迭代总数的10%或更大); * note:3. 对于 non-ambitious planner,当找到一个可执行的计划就行; * <p>In each phase, the planner sets the initial importance of the existing * RelSubSets ({@link #setInitialImportance()}). The planner then iterates * over the rule matches presented by the rule queue until: * * <ol> * <li>The rule queue becomes empty.</li> * <li>For ambitious planners: No improvements to the plan have been made * recently (specifically within a number of iterations that is 10% of the * number of iterations necessary to first reach an implementable plan or 25 * iterations whichever is larger).</li> * <li>For non-ambitious planners: When an implementable plan is found.</li> * </ol> * * note:此外,如果每10次迭代之后,没有一个可实现的计划,包含 logical RelNode 的 RelSubSets 将会通过 injectImportanceBoost 给一个 importance; * <p>Furthermore, after every 10 iterations without an implementable plan, * RelSubSets that contain only logical RelNodes are given an importance * boost via {@link #injectImportanceBoost()}. Once an implementable plan is * found, the artificially raised importance values are cleared (see * {@link #clearImportanceBoost()}). * * @return the most efficient RelNode tree found for implementing the given * query */ public RelNode findBestExp(){ //note: 确保 root relational expression 的 subset(RelSubset)在它的等价集(RelSet)中包含所有 RelSubset 的 converter //note: 来保证 planner 从其他的 subsets 找到的实现方案可以转换为 root,否则可能因为 convention 不同,无法实施 ensureRootConverters(); //note: materialized views 相关,这里可以先忽略~ registerMaterializations(); int cumulativeTicks = 0; //note: 四个阶段通用的变量 //note: 不同的阶段,总共四个阶段,实际上只有 OPTIMIZE 这个阶段有效,因为其他阶段不会有 RuleMatch for (VolcanoPlannerPhase phase : VolcanoPlannerPhase.values()) { //note: 在不同的阶段,初始化 RelSubSets 相应的 importance //note: root 节点往下子节点的 importance 都会被初始化 setInitialImportance();
//note: 默认是 VolcanoCost RelOptCost targetCost = costFactory.makeHugeCost(); int tick = 0; int firstFiniteTick = -1; int splitCount = 0; int giveUpTick = Integer.MAX_VALUE;
//note: 对于那些手动提高 importance 的 RelSubset 进行重新计算 clearImportanceBoost(); } if (ambitious) { // Choose a slightly more ambitious target cost, and // try again. If it took us 1000 iterations to find our // first finite plan, give ourselves another 100 // iterations to reduce the cost by 10%. //note: 设置 target 为当前 best cost 的 0.9,调整相应的目标,再进行优化 targetCost = root.bestCost.multiplyBy(0.9); ++splitCount; if (impatient) { if (firstFiniteTick < 10) { // It's possible pre-processing can create // an implementable plan -- give us some time // to actually optimize it. //note: 有可能在 pre-processing 阶段就实现一个 implementable plan,所以先设置一个值,后面再去优化 giveUpTick = cumulativeTicks + 25; } else { giveUpTick = cumulativeTicks + Math.max(firstFiniteTick / 10, 25); } } } else { break; } //note: 最近没有任何进步(超过 giveUpTick 限制,还没达到目标值),直接采用当前的 best plan } elseif (cumulativeTicks > giveUpTick) { // We haven't made progress recently. Take the current best. break; } elseif (root.bestCost.isInfinite() && ((tick % 10) == 0)) { injectImportanceBoost(); }
//org.apache.calcite.plan.volcano.RuleQueue /** * Removes the rule match with the highest importance, and returns it. * * note:返回最高 importance 的 rule,并从 Rule Match 中移除(处理过后的就移除) * note:如果集合为空,就返回 null * <p>Returns {@code null} if there are no more matches.</p> * * <p>Note that the VolcanoPlanner may still decide to reject rule matches * which have become invalid, say if one of their operands belongs to an * obsolete set or has importance=0. * * @throws java.lang.AssertionError if this method is called with a phase * previously marked as completed via * {@link #phaseCompleted(VolcanoPlannerPhase)}. */ VolcanoRuleMatch popMatch(VolcanoPlannerPhase phase){ dump();
//note: 选择当前阶段对应的 PhaseMatchList PhaseMatchList phaseMatchList = matchListMap.get(phase); if (phaseMatchList == null) { thrownew AssertionError("Used match list for phase " + phase + " after phase complete"); }
final List<VolcanoRuleMatch> matchList = phaseMatchList.list; VolcanoRuleMatch match; for (;;) { //note: 按照前面的逻辑只有在 OPTIMIZE 阶段,PhaseMatchList 才不为空,其他阶段都是空 // 参考 addMatch 方法 if (matchList.isEmpty()) { returnnull; } if (LOGGER.isTraceEnabled()) { matchList.sort(MATCH_COMPARATOR); match = matchList.remove(0);
StringBuilder b = new StringBuilder(); b.append("Sorted rule queue:"); for (VolcanoRuleMatch match2 : matchList) { finaldouble importance = match2.computeImportance(); b.append("\n"); b.append(match2); b.append(" importance "); b.append(importance); }
LOGGER.trace(b.toString()); } else { //note: 直接遍历找到 importance 最大的 match(上面先做排序,是为了输出日志) // If we're not tracing, it's not worth the effort of sorting the // list to find the minimum. match = null; int bestPos = -1; int i = -1; for (VolcanoRuleMatch match2 : matchList) { ++i; if (match == null || MATCH_COMPARATOR.compare(match2, match) < 0) { bestPos = i; match = match2; } } match = matchList.remove(bestPos); }
// A rule match's digest is composed of the operand RelNodes' digests, // which may have changed if sets have merged since the rule match was // enqueued. //note: 重新计算一下这个 RuleMatch 的 digest match.recomputeDigest();
protected VolcanoPlannerPhaseRuleMappingInitializer getPhaseRuleMappingInitializer() { return phaseRuleMap -> { // Disable all phases except OPTIMIZE by adding one useless rule name. //note: 通过添加一个无用的 rule name 来 disable 优化器的其他三个阶段 phaseRuleMap.get(VolcanoPlannerPhase.PRE_PROCESS_MDR).add("xxx"); phaseRuleMap.get(VolcanoPlannerPhase.PRE_PROCESS).add("xxx"); phaseRuleMap.get(VolcanoPlannerPhase.CLEANUP).add("xxx"); }; }
开始时还困惑这个什么用?后来看到下面的代码基本就明白了
1 2 3 4 5 6 7 8
for (VolcanoPlannerPhase phase : VolcanoPlannerPhase.values()) { // empty phases get converted to "all rules" //note: 如果阶段对应的 rule set 为空,那么就给这个阶段对应的 rule set 添加一个 【ALL_RULES】 //也就是只有 OPTIMIZE 这个阶段对应的会添加 ALL_RULES if (phaseRuleMapping.get(phase).isEmpty()) { phaseRuleMapping.put(phase, ALL_RULES); } }
]]>
<p>紧接上篇文章<a href="http://matt33.com/2019/03/07/apache-calcite-process-flow/">Apache Calcite 处理流程详解(一)</a>,这里是 Calcite 系列文章的第二篇,后面还会有文章讲述 Cal
Apache Calcite 处理流程详解(一)http://matt33.com/2019/03/07/apache-calcite-process-flow/2019-03-07T12:40:38.000Z2020-06-23T14:13:17.222Z关于 Apache Calcite 的简单介绍可以参考 Apache Calcite:Hadoop 中新型大数据查询引擎 这篇文章,Calcite 一开始设计的目标就是 one size fits all,它希望能为不同计算存储引擎提供统一的 SQL 查询引擎,当然 Calcite 并不仅仅是一个简单的 SQL 查询引擎,在论文 Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources 的摘要(摘要见下面)部分,关于 Calcite 的核心点有简单的介绍,Calcite 的架构有三个特点:flexible, embeddable, and extensible,就是灵活性、组件可插拔、可扩展,它的 SQL Parser 层、Optimizer 层等都可以单独使用,这也是 Calcite 受总多开源框架欢迎的原因之一。
Apache Calcite is a foundational software framework that provides query processing, optimization, and query language support to many popular open-source data processing systems such as Apache Hive, Apache Storm, Apache Flink, Druid, and MapD. Calcite’s architecture consists of
a modular and extensible query optimizer with hundreds of built-in optimization rules,
a query processor capable of processing a variety of query languages,
an adapter architecture designed for extensibility,
and support for heterogeneous data models and stores (relational, semi-structured, streaming, and geospatial). This flexible, embeddable, and extensible architecture is what makes Calcite an attractive choice for adoption in bigdata frameworks. It is an active project that continues to introduce support for the new types of data sources, query languages, and approaches to query processing and optimization.
A relational expression implements the interface Converter to indicate that it converts a physical attribute, or RelTrait of a relational expression from one value to another.
An environment for related relational expressions during the optimization of a query.
palnner 运行时的环境,保存上下文信息;
RelOptPlanner
A RelOptPlanner is a query optimizer: it transforms a relational expression into a semantically equivalent relational expression, according to a given set of rules and a cost model.
select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age fromusers u join jobs j on u.name=j.name where u.age > 30and j.id>10 orderby user_id
//note: 二、sql validate(会先通过Catalog读取获取相应的metadata和namespace) //note: get metadata and namespace SqlTypeFactoryImpl factory = new SqlTypeFactoryImpl(RelDataTypeSystem.DEFAULT); CalciteCatalogReader calciteCatalogReader = new CalciteCatalogReader( CalciteSchema.from(rootScheme), CalciteSchema.from(rootScheme).path(null), factory, new CalciteConnectionConfigImpl(new Properties()));
//org.apache.calcite.schema.impl.AbstractSchema /** * Returns a map of tables in this schema by name. * * <p>The implementations of {@link #getTableNames()} * and {@link #getTable(String)} depend on this map. * The default implementation of this method returns the empty map. * Override this method to change their behavior.</p> * * @return Map of tables in this schema by name */ protected Map<String, Table> getTableMap(){ return ImmutableMap.of(); }
org.apache.calcite.runtime.CalciteContextException: From line 1, column 156 to line 1, column 158: Column 'IDS' not found in table 'J' at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.calcite.runtime.Resources$ExInstWithCause.ex(Resources.java:463) at org.apache.calcite.sql.SqlUtil.newContextException(SqlUtil.java:787) at org.apache.calcite.sql.SqlUtil.newContextException(SqlUtil.java:772) at org.apache.calcite.sql.validate.SqlValidatorImpl.newValidationError(SqlValidatorImpl.java:4788) at org.apache.calcite.sql.validate.DelegatingScope.fullyQualify(DelegatingScope.java:439) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visit(SqlValidatorImpl.java:5683) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visit(SqlValidatorImpl.java:5665) at org.apache.calcite.sql.SqlIdentifier.accept(SqlIdentifier.java:334) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:134) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:101) at org.apache.calcite.sql.SqlOperator.acceptCall(SqlOperator.java:865) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visitScoped(SqlValidatorImpl.java:5701) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:50) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:33) at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:138) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:134) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:101) at org.apache.calcite.sql.SqlOperator.acceptCall(SqlOperator.java:865) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visitScoped(SqlValidatorImpl.java:5701) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:50) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:33) at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:138) at org.apache.calcite.sql.validate.SqlValidatorImpl.expand(SqlValidatorImpl.java:5272) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateWhereClause(SqlValidatorImpl.java:3977) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelect(SqlValidatorImpl.java:3305) at org.apache.calcite.sql.validate.SelectNamespace.validateImpl(SelectNamespace.java:60) at org.apache.calcite.sql.validate.AbstractNamespace.validate(AbstractNamespace.java:84) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateNamespace(SqlValidatorImpl.java:977) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateQuery(SqlValidatorImpl.java:953) at org.apache.calcite.sql.SqlSelect.validate(SqlSelect.java:216) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateScopedExpression(SqlValidatorImpl.java:928) at org.apache.calcite.sql.validate.SqlValidatorImpl.validate(SqlValidatorImpl.java:632) at com.matt.test.calcite.test.SqlTest3.sqlToRelNode(SqlTest3.java:200) at com.matt.test.calcite.test.SqlTest3.main(SqlTest3.java:117) Caused by: org.apache.calcite.sql.validate.SqlValidatorException: Column 'IDS' not found in table 'J' at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.calcite.runtime.Resources$ExInstWithCause.ex(Resources.java:463) at org.apache.calcite.runtime.Resources$ExInst.ex(Resources.java:572) ... 33 more java.lang.NullPointerException at org.apache.calcite.plan.hep.HepPlanner.addRelToGraph(HepPlanner.java:806) at org.apache.calcite.plan.hep.HepPlanner.setRoot(HepPlanner.java:152) at com.matt.test.calcite.test.SqlTest3.main(SqlTest3.java:124)
private SqlNode validateScopedExpression( SqlNode topNode, SqlValidatorScope scope){ //note: 1. rewrite expression,将其标准化,便于后面的逻辑计划优化 SqlNode outermostNode = performUnconditionalRewrites(topNode, false); cursorSet.add(outermostNode); top = outermostNode; TRACER.trace("After unconditional rewrite: {}", outermostNode); //note: 2. Registers a query in a parent scope. //note: register scopes and namespaces implied a relational expression if (outermostNode.isA(SqlKind.TOP_LEVEL)) { registerQuery(scope, null, outermostNode, outermostNode, null, false); } //note: 3. catalog 验证,调用 SqlNode 的 validate 方法, outermostNode.validate(this, scope); if (!outermostNode.isA(SqlKind.TOP_LEVEL)) { // force type derivation so that we can provide it to the // caller later without needing the scope deriveType(scope, outermostNode); } TRACER.trace("After validation: {}", outermostNode); return outermostNode; }
/** * Parse tree node that represents an {@code ORDER BY} on a query other than a * {@code SELECT} (e.g. {@code VALUES} or {@code UNION}). * * <p>It is a purely syntactic operator, and is eliminated by * {@link org.apache.calcite.sql.validate.SqlValidatorImpl#performUnconditionalRewrites} * and replaced with the ORDER_OPERAND of SqlSelect.</p> */ publicclassSqlOrderByextendsSqlCall{
/** * <h3>Scopes</h3> * * <p>In the query</p> * * <blockquote> * <pre> * SELECT expr1 * FROM t1, * t2, * (SELECT expr2 FROM t3) AS q3 * WHERE c1 IN (SELECT expr3 FROM t4) * ORDER BY expr4</pre> * </blockquote> * * <p>The scopes available at various points of the query are as follows:</p> * * <ul> * <li>expr1 can see t1, t2, q3</li> * <li>expr2 can see t3</li> * <li>expr3 can see t4, t1, t2</li> * <li>expr4 can see t1, t2, q3, plus (depending upon the dialect) any aliases * defined in the SELECT clause</li> * </ul> * * <h3>Namespaces</h3> * * <p>In the above query, there are 4 namespaces:</p> * * <ul> * <li>t1</li> * <li>t2</li> * <li>(SELECT expr2 FROM t3) AS q3</li> * <li>(SELECT expr3 FROM t4)</li> */
validateNamespace(ns, targetRowType);//note: 检查 switch (node.getKind()) { case EXTEND: // Until we have a dedicated namespace for EXTEND deriveType(scope, node); } if (node == top) { validateModality(node); } validateAccess( node, ns.getTable(), SqlAccessEnum.SELECT); }
/** * Validates a namespace. * * @param namespace Namespace * @param targetRowType Desired row type, must not be null, may be the data * type 'unknown'. */ protectedvoidvalidateNamespace(final SqlValidatorNamespace namespace, RelDataType targetRowType){ namespace.validate(targetRowType);//note: 验证 if (namespace.getNode() != null) { setValidatedNodeType(namespace.getNode(), namespace.getType()); } }
// create the rexBuilder final RexBuilder rexBuilder = new RexBuilder(factory); // init the planner // 这里也可以注册 VolcanoPlanner,这一步 planner 并没有使用 HepProgramBuilder builder = new HepProgramBuilder(); RelOptPlanner planner = new HepPlanner(builder.build());
//note: init cluster: An environment for related relational expressions during the optimization of a query. final RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder); //note: init SqlToRelConverter final SqlToRelConverter.Config config = SqlToRelConverter.configBuilder() .withConfig(frameworkConfig.getSqlToRelConverterConfig()) .withTrimUnusedFields(false) .withConvertTableAccess(false) .build(); //note: config // 创建 SqlToRelConverter 实例,cluster、calciteCatalogReader、validator 都传进去了,SqlToRelConverter 会缓存这些对象 final SqlToRelConverter sqlToRelConverter = new SqlToRelConverter(new DogView(), validator, calciteCatalogReader, cluster, StandardConvertletTable.INSTANCE, config); // convert to RelNode RelRoot root = sqlToRelConverter.convertQuery(validateSqlNode, false, true);
/** * Converts an unvalidated query's parse tree into a relational expression. * note:把一个 parser tree 转换为 relational expression * @param query Query to convert * @param needsValidation Whether to validate the query before converting; * <code>false</code> if the query has already been * validated. * @param top Whether the query is top-level, say if its result * will become a JDBC result set; <code>false</code> if * the query will be part of a view. */ public RelRoot convertQuery( SqlNode query, finalboolean needsValidation, finalboolean top){ if (needsValidation) { //note: 是否需要做相应的校验(如果校验过了,这里就不需要了) query = validator.validate(query); }
//note: 设置 MetadataProvider RelMetadataQuery.THREAD_PROVIDERS.set( JaninoRelMetadataProvider.of(cluster.getMetadataProvider())); //note: 得到 RelNode(relational expression) RelNode result = convertQueryRecursive(query, top, null).rel; if (top) { if (isStream(query)) {//note: 如果 stream 的话 result = new LogicalDelta(cluster, result.getTraitSet(), result); } } RelCollation collation = RelCollations.EMPTY; if (!query.isA(SqlKind.DML)) { //note: 如果是 DML 语句 if (isOrdered(query)) { //note: 如果需要做排序的话 collation = requiredCollation(result); } } //note: 对转换前后的 RelDataType 做验证 checkConvertedType(query, result);
if (SQL2REL_LOGGER.isDebugEnabled()) { SQL2REL_LOGGER.debug( RelOptUtil.dumpPlan("Plan after converting SqlNode to RelNode", result, SqlExplainFormat.TEXT, SqlExplainLevel.EXPPLAN_ATTRIBUTES)); }
/** * Implementation of {@link #convertSelect(SqlSelect, boolean)}; * derived class may override. */ protectedvoidconvertSelectImpl( final Blackboard bb, SqlSelect select){ //note: convertFrom convertFrom( bb, select.getFrom()); //note: convertWhere convertWhere( bb, select.getWhere());
final List<SqlNode> orderExprList = new ArrayList<>(); final List<RelFieldCollation> collationList = new ArrayList<>(); //note: 有 order by 操作时 gatherOrderExprs( bb, select, select.getOrderList(), orderExprList, collationList); final RelCollation collation = cluster.traitSet().canonize(RelCollations.of(collationList));
if (validator.isAggregate(select)) { //note: 当有聚合操作时,也就是含有 group by、having 或者 Select 和 order by 中含有聚合函数 convertAgg( bb, select, orderExprList); } else { //note: 对 select list 部分的处理 convertSelectList( bb, select, orderExprList); }
if (select.isDistinct()) { //note: select 后面含有 DISTINCT 关键字时(去重) distinctify(bb, true); } //note: Converts a query's ORDER BY clause, if any. convertOrder( select, bb, collation, orderExprList, select.getOffset(), select.getFetch()); bb.setRoot(bb.root, true); }
这里以示例中的 From 部分为例介绍 SqlNode 到 RelNode 的逻辑,按照示例 DEUBG 后的结果如下图所示,因为 form 部分是一个 join 操作,会进入 join 相关的处理中。
大部分人都认为自己热爱学习,但是有多少能真正付出实践、并一直坚持下去,能做到实践和坚持的人,一般运气都不会太差。如果我们去研究一下古今中外的成功人士,就会发现,他们基本上都是非常自律的,也都是非常热爱学习的,他们可以沉得下心来不断学习,在学习中不断地思考、探索和实践。懒,是人类的天性,如果不能克服自己 DNA 中的弱点,不能端正自己的态度,不能自律,不能坚持,不能举一反三,不能不断追问等,那么,无论多好的方法,你都不可能学好。所以,有正确的态度非常重要。
//note: producer 启用事务性的情况下,检测此时事务的状态信息 privatedefprepareInitProduceIdTransit(transactionalId: String, transactionTimeoutMs: Int, coordinatorEpoch: Int, txnMetadata: TransactionMetadata): ApiResult[(Int, TxnTransitMetadata)] = { if (txnMetadata.pendingTransitionInProgress) { // return a retriable exception to let the client backoff and retry Left(Errors.CONCURRENT_TRANSACTIONS) } else { // caller should have synchronized on txnMetadata already txnMetadata.state match { casePrepareAbort | PrepareCommit => // reply to client and let it backoff and retry Left(Errors.CONCURRENT_TRANSACTIONS)
caseOngoing => //note: abort 当前的事务,并返回一个 CONCURRENT_TRANSACTIONS 异常,强制 client 去重试 // indicate to abort the current ongoing txn first. Note that this epoch is never returned to the // user. We will abort the ongoing transaction and return CONCURRENT_TRANSACTIONS to the client. // This forces the client to retry, which will ensure that the epoch is bumped a second time. In // particular, if fencing the current producer exhausts the available epochs for the current producerId, // then when the client retries, we will generate a new producerId. Right(coordinatorEpoch, txnMetadata.prepareFenceProducerEpoch())
caseDead | PrepareEpochFence => //note: 返回错误 val errorMsg = s"Found transactionalId $transactionalId with state ${txnMetadata.state}. " + s"This is illegal as we should never have transitioned to this state." fatal(errorMsg) thrownewIllegalStateException(errorMsg)
// class TransactionManager //note: 发送 AddOffsetsToTxRequest publicsynchronized TransactionalRequestResult sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId){ ensureTransactional(); maybeFailWithError(); if (currentState != State.IN_TRANSACTION) thrownew KafkaException("Cannot send offsets to transaction either because the producer is not in an " + "active transaction");
log.debug("Begin adding offsets {} for consumer group {} to transaction", offsets, consumerGroupId); AddOffsetsToTxnRequest.Builder builder = new AddOffsetsToTxnRequest.Builder(transactionalId, producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, consumerGroupId); AddOffsetsToTxnHandler handler = new AddOffsetsToTxnHandler(builder, offsets); enqueueRequest(handler); return handler.result; }
// class TransactionManager publicsynchronized TransactionalRequestResult beginAbort(){ ensureTransactional(); if (currentState != State.ABORTABLE_ERROR) maybeFailWithError(); transitionTo(State.ABORTING_TRANSACTION);
// We're aborting the transaction, so there should be no need to add new partitions newPartitionsInTransaction.clear(); return beginCompletingTransaction(TransactionResult.ABORT); }
org.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error state at org.apache.kafka.clients.producer.internals.TransactionManager.maybeFailWithError(TransactionManager.java:784) at org.apache.kafka.clients.producer.internals.TransactionManager.beginTransaction(TransactionManager.java:215) at org.apache.kafka.clients.producer.KafkaProducer.beginTransaction(KafkaProducer.java:606) at com.matt.test.kafka.producer.ProducerTransactionExample.main(ProducerTransactionExample.java:68) Caused by: org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer's transaction has been expired by the broker.
[2018-11-03 12:48:52,495] DEBUG [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Transition from state COMMITTING_TRANSACTION to error state FATAL_ERROR (org.apache.kafka.clients.producer.internals.TransactionManager) org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer's transaction has been expired by the broker. [2018-11-03 12:48:52,498] ERROR [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Aborting producer batches due to fatal error (org.apache.kafka.clients.producer.internals.Sender) org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer's transaction has been expired by the broker. [2018-11-03 12:48:52,599] INFO [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms. (org.apache.kafka.clients.producer.KafkaProducer) [2018-11-03 12:48:52,599] DEBUG [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Beginning shutdown of Kafka producer I/O thread, sending remaining records. (org.apache.kafka.clients.producer.internals.Sender) [2018-11-03 12:48:52,601] DEBUG Removed sensor with name connections-closed: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,601] DEBUG Removed sensor with name connections-created: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,602] DEBUG Removed sensor with name successful-authentication: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,602] DEBUG Removed sensor with name failed-authentication: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,602] DEBUG Removed sensor with name bytes-sent-received: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,603] DEBUG Removed sensor with name bytes-sent: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,603] DEBUG Removed sensor with name bytes-received: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,604] DEBUG Removed sensor with name select-time: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,604] DEBUG Removed sensor with name io-time: (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,604] DEBUG Removed sensor with name node--1.bytes-sent (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,605] DEBUG Removed sensor with name node--1.bytes-received (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,605] DEBUG Removed sensor with name node--1.latency (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,605] DEBUG Removed sensor with name node-33.bytes-sent (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,606] DEBUG Removed sensor with name node-33.bytes-received (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,606] DEBUG Removed sensor with name node-33.latency (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,606] DEBUG Removed sensor with name node-35.bytes-sent (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,606] DEBUG Removed sensor with name node-35.bytes-received (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,606] DEBUG Removed sensor with name node-35.latency (org.apache.kafka.common.metrics.Metrics) [2018-11-03 12:48:52,607] DEBUG [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Shutdown of Kafka producer I/O thread has completed. (org.apache.kafka.clients.producer.internals.Sender) [2018-11-03 12:48:52,607] DEBUG [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Kafka producer has been closed (org.apache.kafka.clients.producer.KafkaProducer) [2018-11-03 12:48:52,808] ERROR Forcing producer close! (com.matt.test.kafka.producer.ProducerTransactionExample) [2018-11-03 12:48:52,808] INFO [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms. (org.apache.kafka.clients.producer.KafkaProducer) [2018-11-03 12:48:52,808] DEBUG [Producer clientId=ProducerTransactionExample, transactionalId=test-transactional-matt] Kafka producer has been closed (org.apache.kafka.clients.producer.KafkaProducer)
The LSO is defined as the latest offset such that the status of all transactional messages at lower offsets have been determined (i.e. committed or aborted).
如果不允许读未完成的事务:相当于还是在 Server 端处理,与前面的区别是,这里需要先把示例中的 txn1、txn2 的数据发送给 Consumer,这样的设计会带来什么问题呢?
假设这个 long transaction commit 了,其 end offset 是 2000,这时候有两种方案:第一种是把 1000-2000 的数据全部读出来(可能是磁盘读),把这个 long transaction 的数据过滤出来返回给 Consumer;第二种是随机读,只读这个 long transaction 的数据,无论哪种都有多触发一次磁盘读的风险,可能影响影响 Server 端的性能;
Server 端需要维护每个 consumer group 有哪些事务读了、哪些事务没读的 meta 信息,因为 consumer 是随机可能挂掉,需要接上次消费的,这样实现就复杂很多了;
从这些分析来看,个人认为 LSO 机制还是一种相当来说 实现起来比较简单、而且不影响原来 server 端性能、还能保证顺序性的一种设计方案,它不一定是最好的,但也不会差太多。在实际的生产场景中,尽量避免 long transaction 这种操作,而且 long transaction可能也会容易触发事务超时。
private Record nextFetchedRecord(){ while (true) { if (records == null || !records.hasNext()) { //note: records 为空(数据全部丢掉了),records 没有数据(是 control msg) maybeCloseRecordStream();
if (!batches.hasNext()) { // Message format v2 preserves the last offset in a batch even if the last record is removed // through compaction. By using the next offset computed from the last offset in the batch, // we ensure that the offset of the next fetch will point to the next batch, which avoids // unnecessary re-fetching of the same batch (in the worst case, the consumer could get stuck // fetching the same batch repeatedly). if (currentBatch != null) nextFetchOffset = currentBatch.nextOffset(); drain(); returnnull; }
if (isolationLevel == IsolationLevel.READ_COMMITTED && currentBatch.hasProducerId()) { //note: 需要做相应的判断 // remove from the aborted transaction queue all aborted transactions which have begun // before the current batch's last offset and add the associated producerIds to the // aborted producer set //note: 如果这个 batch 的 offset 已经大于等于 abortedTransactions 中第一事务的 first offset //note: 那就证明下个 abort transaction 的数据已经开始到来,将 PID 添加到 abortedProducerIds 中 consumeAbortedTransactionsUpTo(currentBatch.lastOffset());
long producerId = currentBatch.producerId(); if (containsAbortMarker(currentBatch)) { abortedProducerIds.remove(producerId); //note: 这个 PID(当前事务)涉及到的数据已经处理完 } elseif (isBatchAborted(currentBatch)) { //note: 丢弃这个数据 log.debug("Skipping aborted record batch from partition {} with producerId {} and " + "offsets {} to {}", partition, producerId, currentBatch.baseOffset(), currentBatch.lastOffset()); nextFetchOffset = currentBatch.nextOffset(); continue; } }
records = currentBatch.streamingIterator(decompressionBufferSupplier); } else { Record record = records.next(); // skip any records out of range if (record.offset() >= nextFetchOffset) { // we only do validation when the message should not be skipped. maybeEnsureValid(record);
// control records are not returned to the user if (!currentBatch.isControlBatch()) { //note: 过滤掉 marker 数据 return record; } else { // Increment the next fetch offset when we skip a control batch. nextFetchOffset = record.offset() + 1; } } } } }