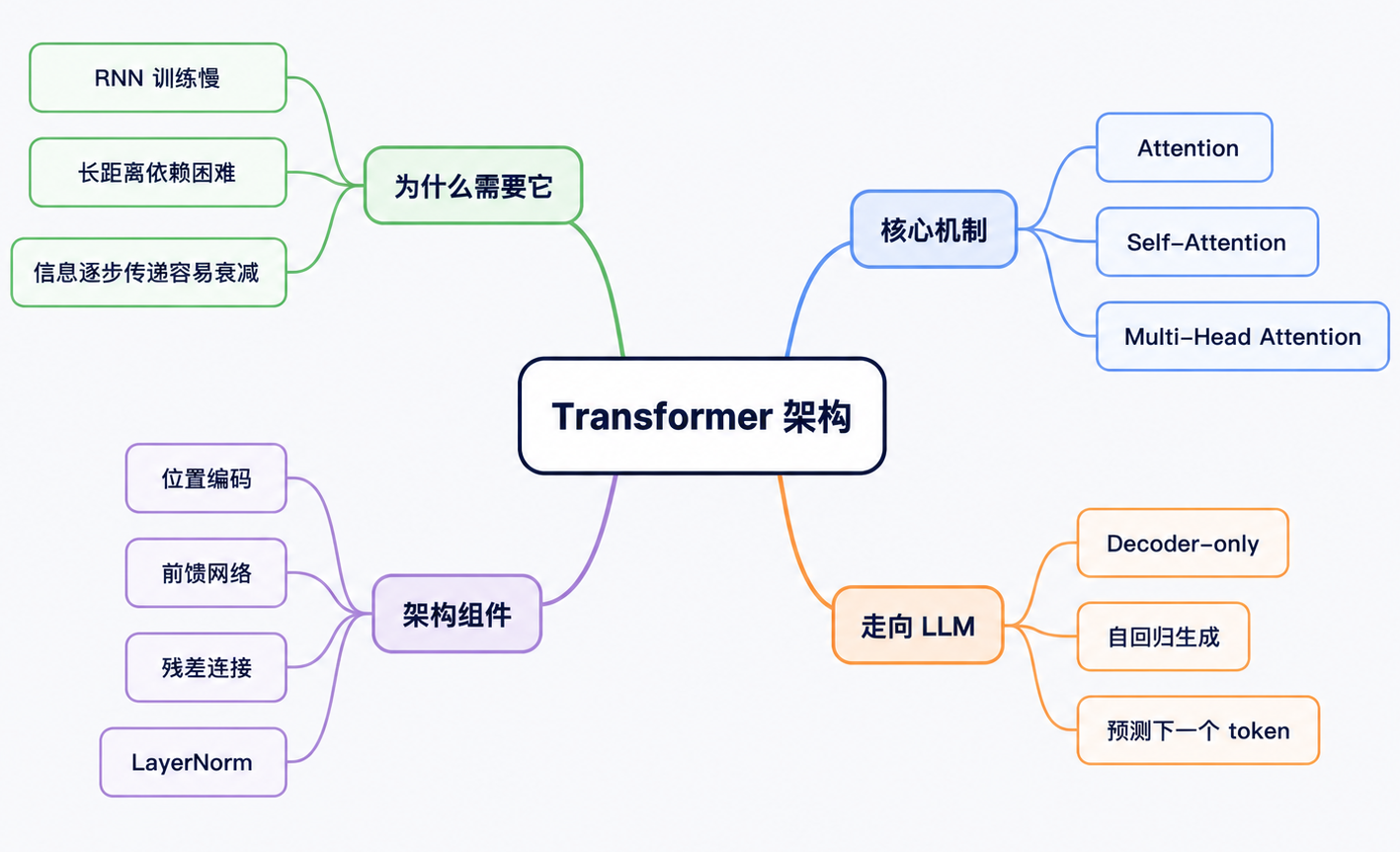
LLM 系列 (四):Transformer 架构篇:大模型为什么选择了 Transformer
前三篇文章里,我们已经分别从三个角度为理解大语言模型打了基础:第一篇看发展脉络,知道 LLM 是怎么一步步演进出来的;第二篇看数学基础,理解向量、概率、损失函数、梯度这些底层工具;第三篇看算法基础,从 NLP、词向量、感知机、神经网络,一路讲到 CNN、RNN 和双向 RNN。到了第四篇,我们终于可以进入现代大语言模型最核心的一块内容:Transformer。
如果说前几篇是在回答“机器如何把语言变成可以计算的问题”,那么这一篇要回答的是另一个更关键的问题:为什么后来的主流大语言模型,几乎都选择了 Transformer 作为核心架构?
这篇文章仍然不是论文精读,也不会一上来就推公式。我们会继续站在普通开发者的视角,把 Transformer 拆成几个容易理解的部分:它想解决什么问题,Attention 到底在做什么,Self-Attention 为什么能理解上下文,Multi-Head Attention 为什么要从多个角度看文本,位置编码解决了什么问题,Transformer Block 又是如何一层层堆出大模型能力的。
先不用急着记住每个概念的细节,可以先把下面这张表当成本文的地图:
| 概念 | 它解决什么问题 | 直觉理解 | 和 LLM 的关系 |
|---|---|---|---|
| Transformer | 重新设计序列建模方式 | 不再一个词一个词慢慢传,而是让 token 直接建立关系 | 现代 LLM 的核心架构 |
| Attention | 找到当前 token 应该关注谁 | 读一句话时,自动把注意力放到相关词上 | Transformer 的核心机制 |
| Self-Attention | 让一句话内部 token 互相关注 | 每个 token 都能参考其他 token | 理解上下文的关键 |
| Multi-Head Attention | 从多个角度看关系 | 有的头看语法,有的头看指代,有的头看语义 | 提升表达能力 |
| Positional Encoding | 补充位置信息 | 告诉模型 token 的顺序 | 让模型知道“狗咬人”和“人咬狗”不同 |
| Transformer Block | 把注意力、前馈网络、残差连接组合起来 | 一个可重复堆叠的计算单元 | LLM 就是很多层 block 堆起来 |
| Decoder-only | 只根据前文预测后文 | 不能偷看未来,只能一步步生成 | GPT 类模型的主流结构 |
整体路线可以理解成这样:
为什么需要 Transformer?
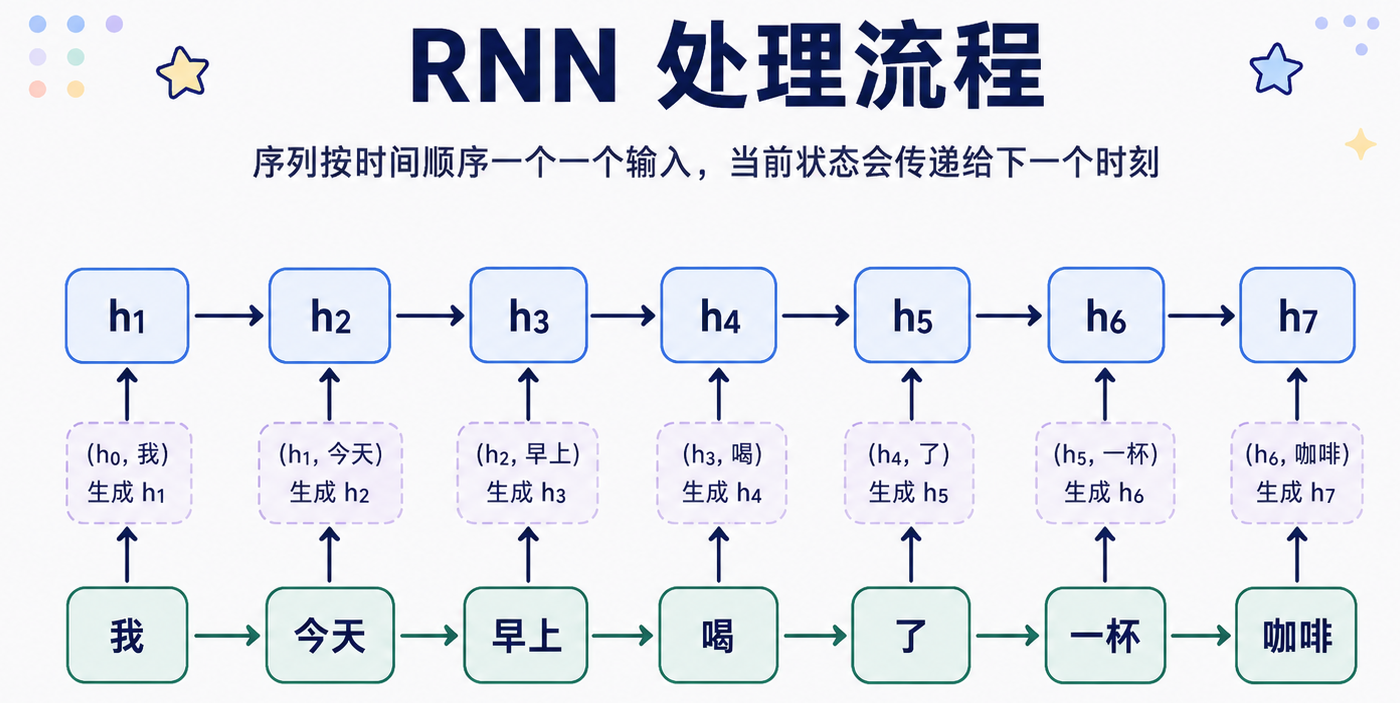
在第三篇文章里,我们讲过 RNN、LSTM、GRU、双向 RNN 这些经典序列模型。它们的共同特点是:按顺序处理文本。
比如一句话:我 今天 早上 喝 了 一杯 咖啡
RNN 会从左到右一个 token 一个 token 地读,每一步都把前面读到的信息压缩进一个隐藏状态。
这种方式很符合人类阅读的直觉,但对机器学习来说有几个明显问题:
- 信息传递路径太长:如果后面的词需要参考很前面的内容,信息要经过很多步传递。传得越远,越容易变弱。LSTM 和 GRU 虽然通过“门”机制缓解了这个问题,但没有彻底解决;
- 训练不易并行:RNN 的后一步依赖前一步。要算第 10 个 token,必须先算完前 9 个 token。这对大规模训练很不友好;
- 所有历史信息都被压缩进状态里:一段长文本里有很多细节,如果都压进一个隐藏状态,模型很容易丢失重要信息。
Transformer 的思路完全不同:不要让信息一步步传递,而是让每个 token 都可以直接看见其他 token。
可以把 RNN 和 Transformer 的区别理解成这样:
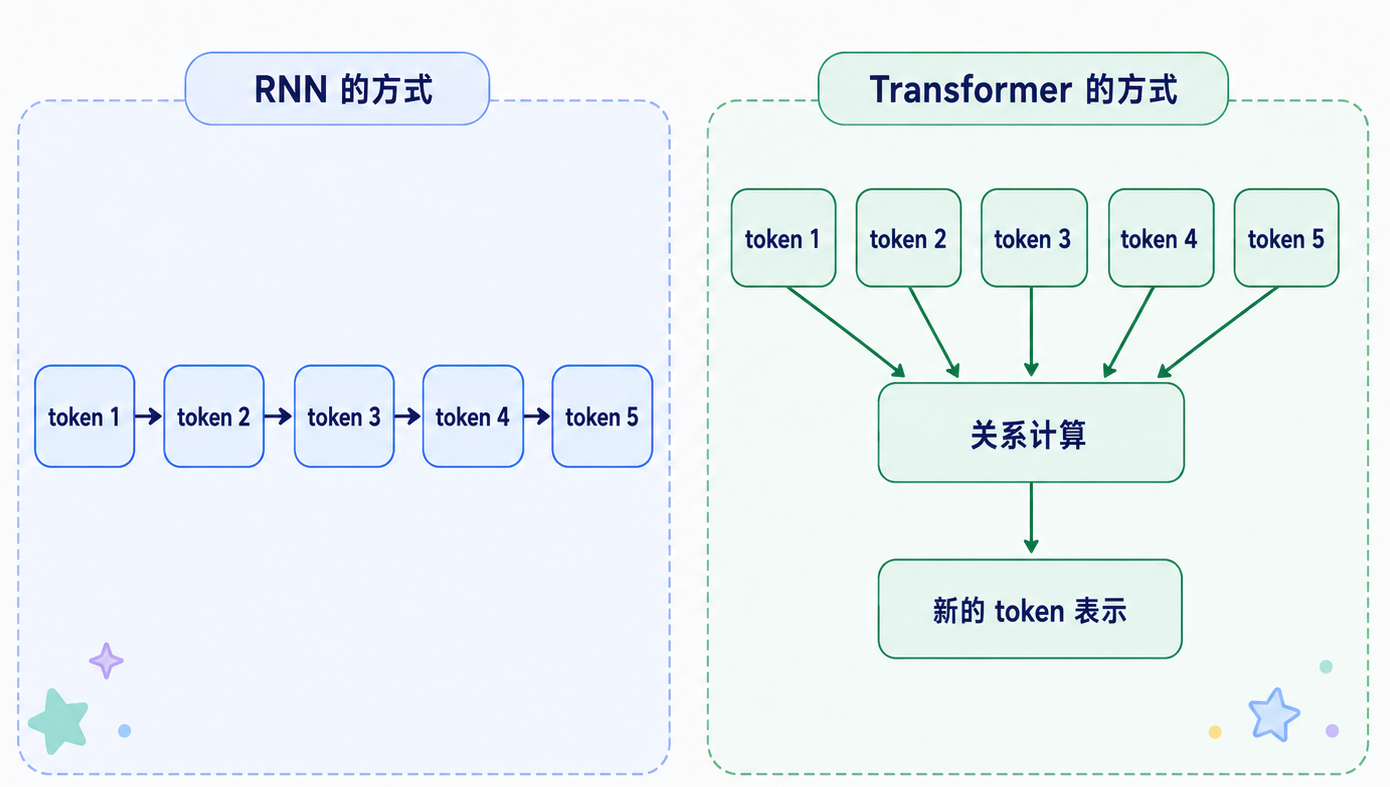
这就是 Transformer 的核心变化:
- 它把“顺序传递信息”,改成了“直接计算 token 与 token 之间的关系”。
这件事看起来简单,但非常关键。因为语言理解的本质,很多时候不是看单个词,而是看词和词之间的关系。
比如:苹果 发布 了 新产品
如果模型要理解“苹果”,就不能只看这个词本身,还要看后面的“发布”“新产品”。这些上下文会告诉模型,这里的“苹果”更可能是公司,而不是水果。
Transformer 之所以重要,就是因为它提供了一种更直接、更高效的方式,让模型在文本内部建立这种关系。
Attention:关注相关信息
Attention,中文通常翻译为注意力机制。
它的直觉很简单:当模型处理某个 token 时,不是平均看所有信息,而是自动判断哪些 token 更重要,然后重点参考它们。
比如这句话:
苹果 发布 了 新产品- 当模型处理“苹果”时,它应该更多关注
发布新产品,而不是只看苹果两个字。
- 当模型处理“苹果”时,它应该更多关注
再比如:
这家店 服务 真好,等了 两个小时 都没人 理我- 如果模型只看
服务真好,可能会判断成正面评价。但如果它注意到后面的等了两个小时没人理我,就更容易理解这里其实是在表达不满。
- 如果模型只看
Attention 的作用就是:给不同 token 分配不同权重,让模型知道当前应该重点看哪里。
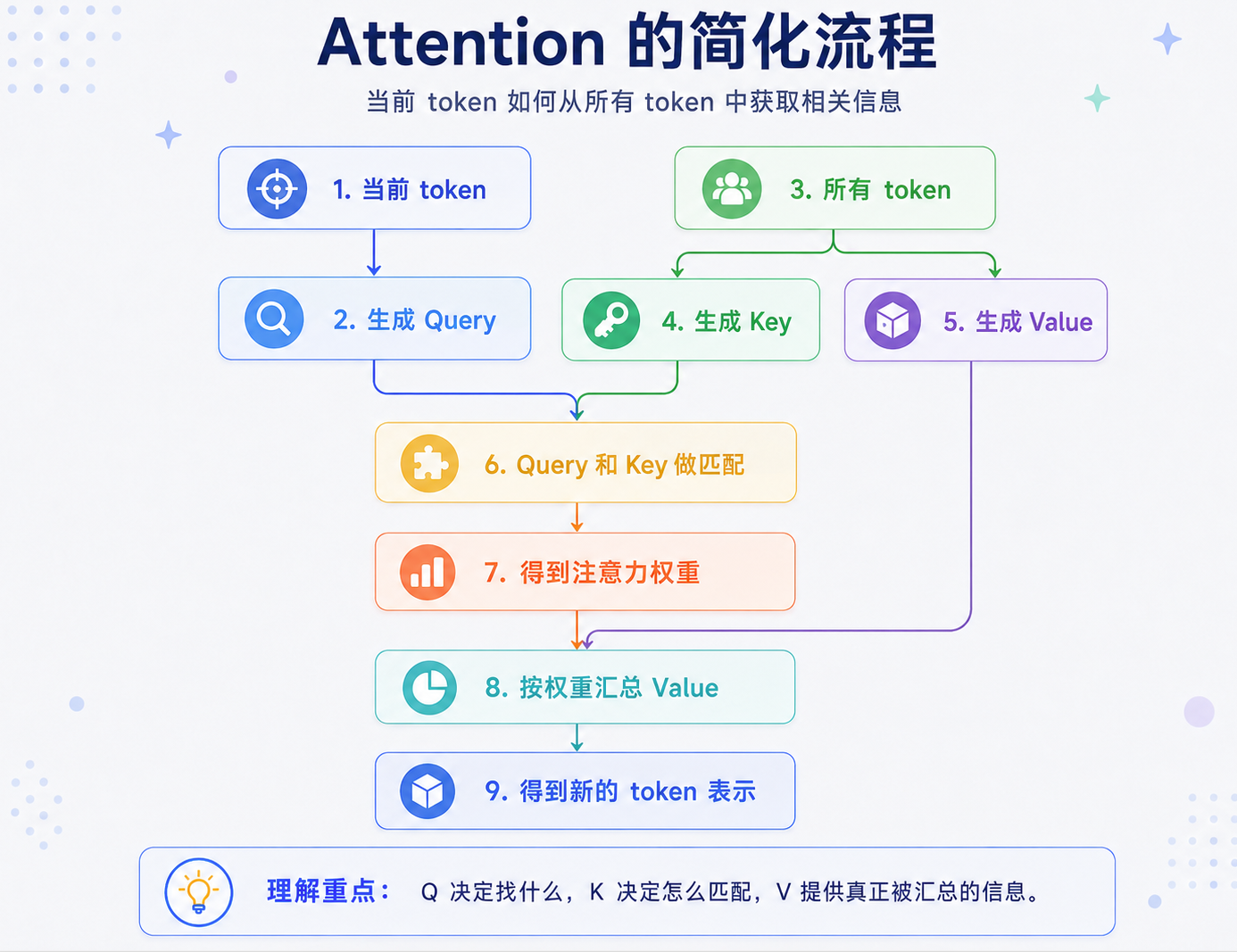
可以把 Attention 理解成一个信息检索过程。模型面对一句话时,每个 token 都会做三件事:
| 名称 | 英文 | 直觉理解 |
|---|---|---|
| Query | Q | 当前 token 想找什么信息 |
| Key | K | 每个 token 可以被匹配的标签 |
| Value | V | 每个 token 真正携带的信息内容 |
用更通俗的话说:
- Query 像是“我现在想问什么问题”;
- Key 像是“我这里有什么信息可以被你匹配”;
- Value 像是“如果你觉得我重要,就从我这里取走的信息”;
每个 token 的 embedding 会分别经过三组不同的参数变换,得到 Q、K、V。当前 token 会用自己的 Q 去和所有 token 的 K 做匹配,得到注意力分数;再经过 softmax 变成权重;最后用这些权重对所有 token 的 V 做加权求和,得到当前 token 的新表示。流程可以简化成这样:
举个例子:句子:苹果 发布 了 新产品
当模型处理 苹果 这个 token 时,它不能只看苹果本身,还需要结合上下文判断它到底指什么。在这句话里,发布 新产品 这些 token 对理解 苹果 更重要,所以模型会给它们更高的关注权重:
| token | 可能的关注程度 |
|---|---|
| 苹果 | 中 |
| 发布 | 高 |
| 了 | 低 |
| 新产品 | 高 |
经过 Attention 计算之后,苹果 的表示就不再只是一个孤立的词向量,而是融合了上下文信息的新表示。
这也是 Attention 很关键的地方:同一个 token,在不同语境下可以得到不同的表示
- 在
苹果很好吃里,苹果的表示会靠近水果。 - 在
苹果发布了新产品里,苹果的表示会靠近公司。
这一步,是从传统词向量走向现代语言模型的关键。
Self-Attention:理解上下文
前面讲的 Attention,本质上是在说:当前 token 可以关注其他信息。那 Self-Attention 又是什么?
Self-Attention 的意思是:一句话内部的 token 之间,互相计算注意力。
这里的 Self,指的是 Query、Key、Value 都来自同一段输入文本。
比如输入:我 喜欢 机器 学习
在 Self-Attention 里,每个 token 都会和其他 token 建立关系:
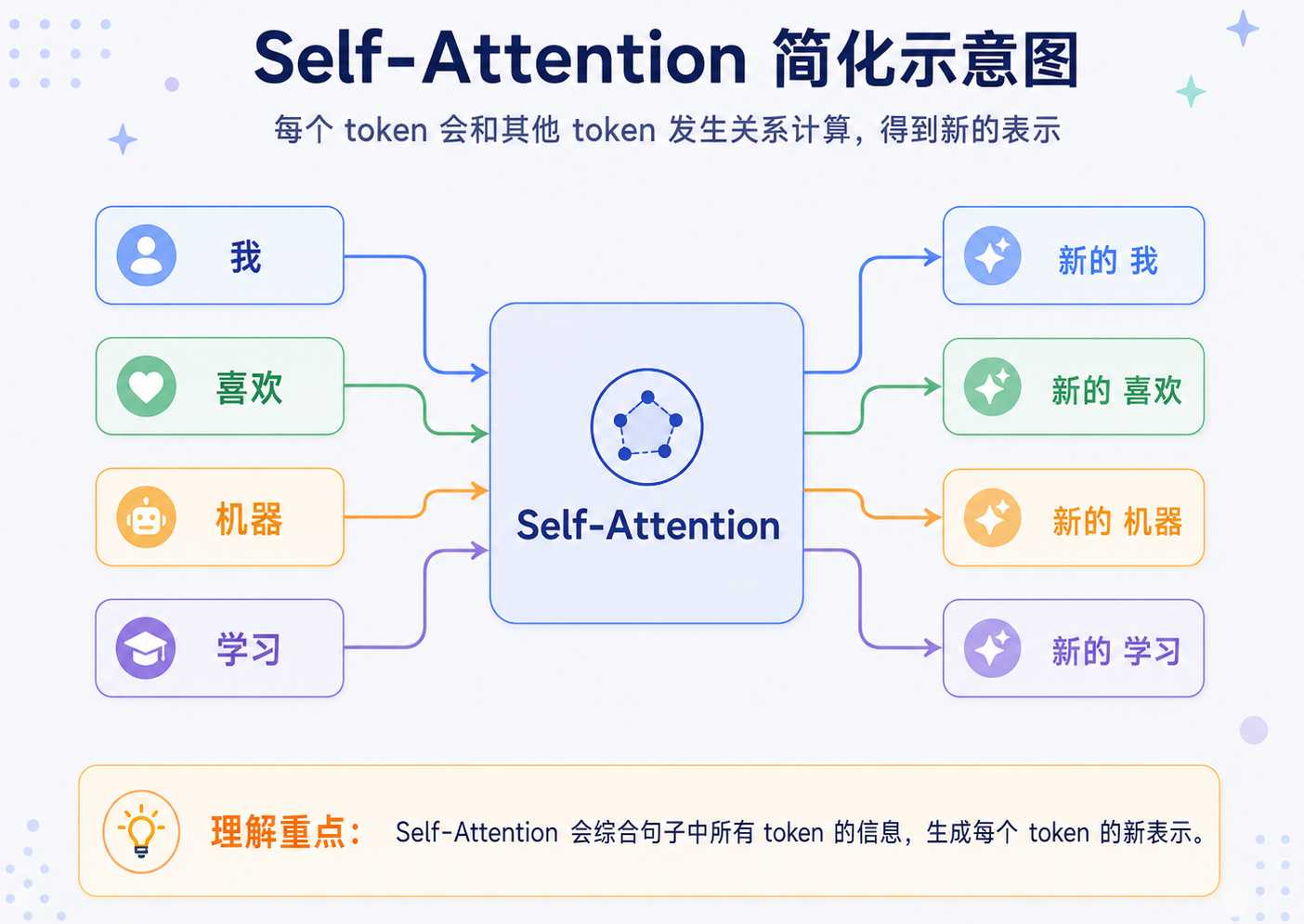
注意这里的 新的 token 表示 很重要。进入 Self-Attention 之前,学习 只是一个 token 的向量。
经过 Self-Attention 之后,学习 的表示已经融合了上下文,知道它前面有 机器,所以这里更可能指机器学习这个技术概念,而不是普通意义上的学习行为(在 Self-Attention 中,句子里的每个 token 的向量表示都会被更新,变成融合上下文的新表示)。
Self-Attention 可以理解为给句子内部建立了一张关系网:
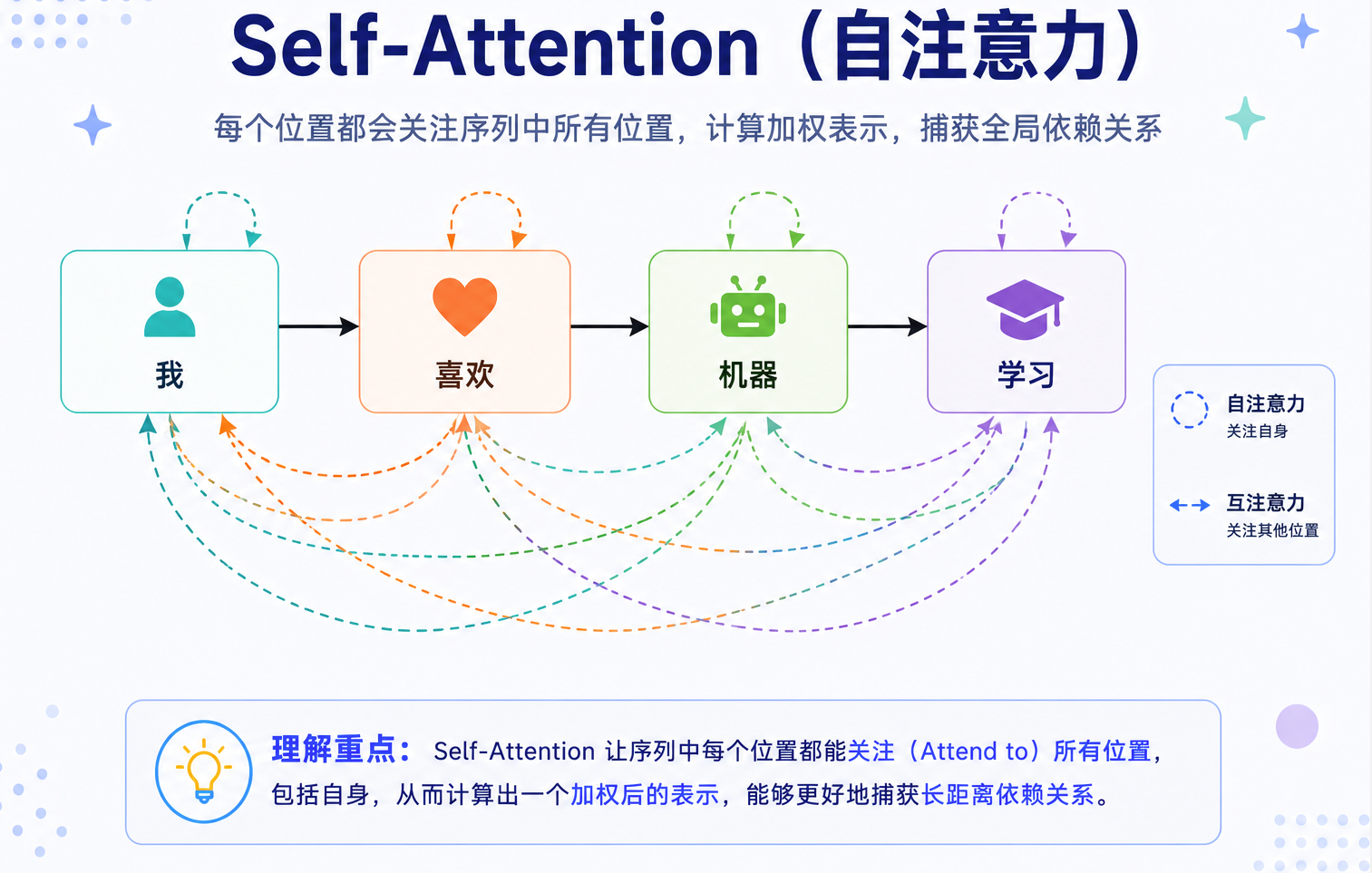
在真实模型里,这张关系网不是人工指定的,而是通过训练学出来的。模型会在大量文本中逐渐学会:
- 哪些词之间经常有关联。
- 哪些词决定语义。
- 哪些词影响情感。
- 哪些词表示指代关系。
- 哪些词对预测下一个 token 更重要。
不过,一个 Attention 视角可能还不够。语言关系很复杂,同一句话可以从不同角度理解。
比如:小明 把 书 放在 桌子 上,因为 它 很重
这里的它可能需要结合上下文判断指代对象。模型可能需要同时关注语法结构、实体关系、位置关系、语义合理性。
所以 Transformer 引入了 Multi-Head Attention,也就是多头注意力。
多头注意力可以理解成:让模型用多个视角同时观察同一句话。
| 注意力头 | 可能关注的关系 |
|---|---|
| Head 1 | 相邻词和短语搭配 |
| Head 2 | 主语、谓语、宾语关系 |
| Head 3 | 指代关系 |
| Head 4 | 情感和语气 |
| Head 5 | 长距离依赖 |
这些分工不是人手写进去的,而是模型在训练过程中自己学出来的。
可以简单理解成:
- 单头 Attention 像一个人读句子。
- 多头 Attention 像一组人从不同角度读同一句话,最后把各自看到的信息合起来。
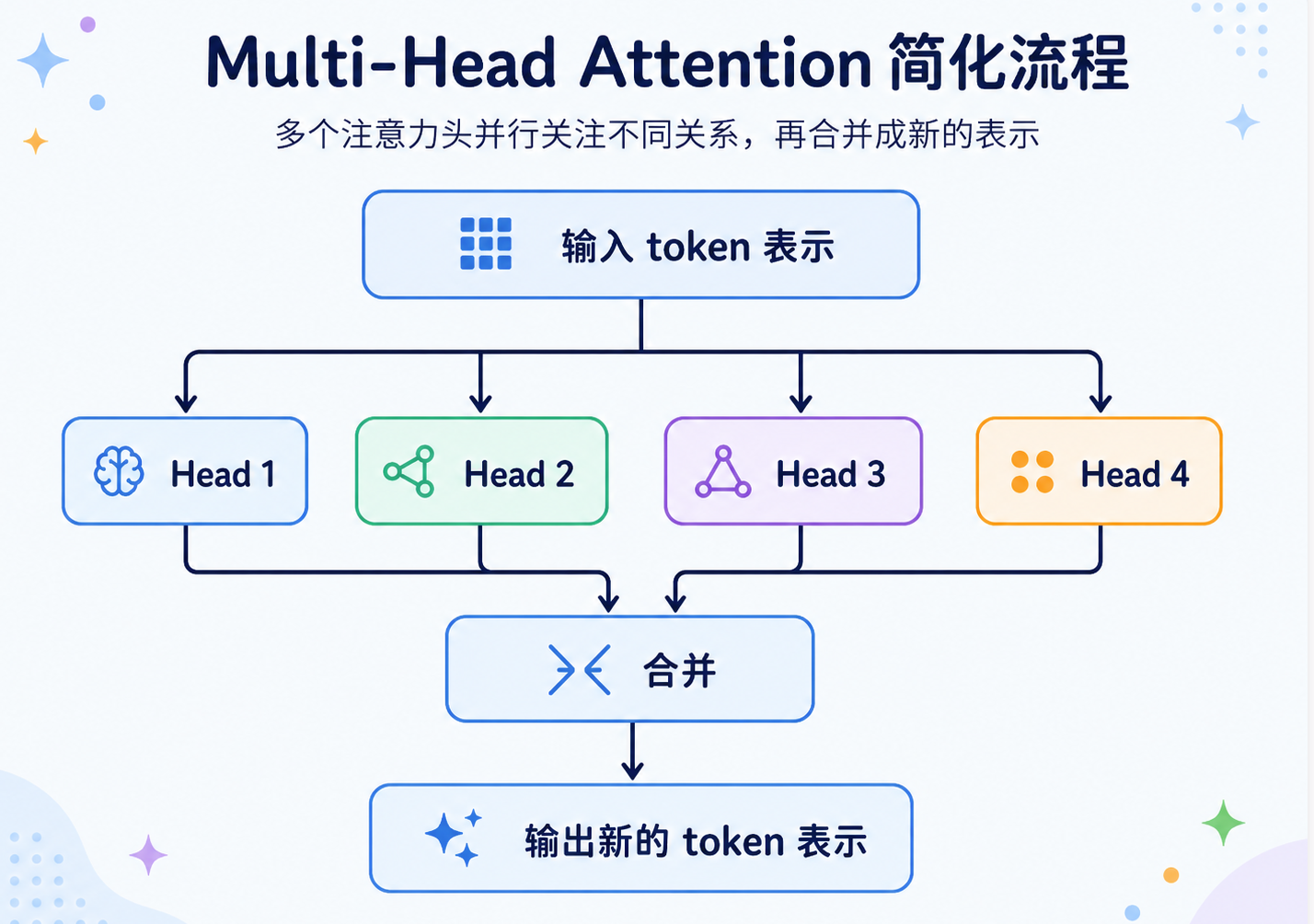
这就是 Transformer 表达能力强的重要原因之一:它不是只用一种方式理解文本,而是可以在多个语义空间里同时建模 token 之间的关系。
Transformer Block:堆叠模型能力
Attention 是 Transformer 的核心机制,但一个真正可训练、可堆叠的模型,不能只有 Attention。
原因很简单:Attention 主要解决的是“当前 token 应该参考哪些上下文信息”。但拿到上下文信息之后,模型还需要继续加工这些信息、保留原始信息、稳定每一层的计算结果。否则,模型层数一深,训练就容易变得不稳定。
所以在 Transformer 里,Attention 通常会被封装进一个更完整的基础模块中,这个模块就叫 Transformer Block。
可以把 Transformer Block 理解为:Transformer 里可以反复堆叠的一层“语言理解单元”。
每经过一个 Transformer Block,token 的表示都会被更新一次:先通过 Self-Attention 和上下文建立关系,再通过前馈网络进一步加工,最后输出给下一层。
一个完整的 Transformer Block 通常包含几部分:
| 组件 | 作用 | 直觉理解 |
|---|---|---|
| Multi-Head Self-Attention | 建模 token 之间的关系 | 让每个 token 知道该看谁 |
| Feed Forward Network | 进一步加工 token 表示 | 对上下文信息做消化和提炼 |
| Residual Connection | 保留原始信息 | 避免层数太深时信息丢失 |
| LayerNorm | 稳定每层计算 | 让训练过程更平稳 |
整体结构如下所示:
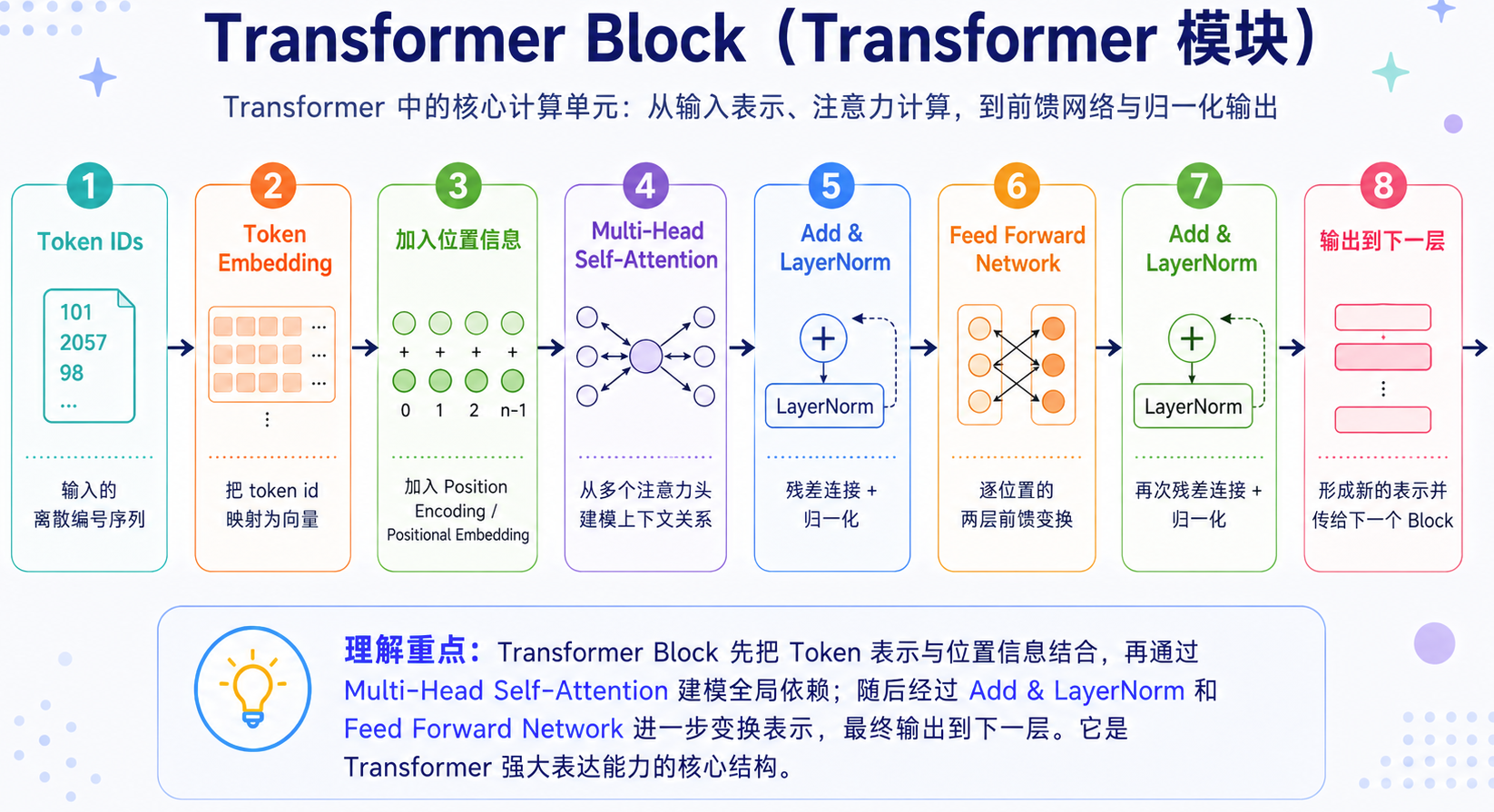
这里有几个点特别重要。
Transformer 需要位置编码
Self-Attention 擅长计算 token 之间的关系,但它本身并不天然知道 token 的先后顺序。
也就是说,如果只看 Self-Attention,模型更关心“哪些 token 之间有关联”,但还需要额外的信息告诉它:“谁在前,谁在后”。
而语言里的顺序非常重要。比如:
狗 咬 人人 咬 狗
这两个句子使用的是同样的 token,但顺序不同,意思就完全变了。
所以在 Transformer 中,模型需要引入位置信息。常见做法是在 token embedding 的基础上加入位置编码,或者在 Attention 计算过程中引入相对位置信息。可以先简单理解为:位置编码的作用,就是告诉模型每个 token 在句子中的位置,让模型能够区分不同顺序带来的语义差异。
Feed Forward Network 加工信息
Attention 主要解决“看谁”的问题。
Feed Forward Network 更像是对每个 token 的表示做一次非线性加工,让模型有能力表达更复杂的模式。
可以粗略理解为:
- Attention 负责汇总上下文。
- Feed Forward 负责消化和加工上下文。
残差连接和 LayerNorm 稳定训练
现代 LLM 往往有很多层 Transformer Block。如果每一层都直接覆盖上一层的信息,训练会很不稳定,也容易出现梯度消失、信息丢失等问题。
- 残差连接:不要让每一层从零开始重写信息,而是在原有信息基础上做增量修改。
- LayerNorm:把每一层的数值范围整理得更稳定,避免训练过程中数值忽大忽小。
小结
所以,一个 Transformer Block 不是一个神秘黑盒,而是一组配合明确的组件:
- Attention 负责找关系。
- Feed Forward 负责加工表示。
- Position 负责补顺序。
- Residual 和 LayerNorm 负责让深层网络稳定训练。
大模型就是把这样的 block 堆很多层。
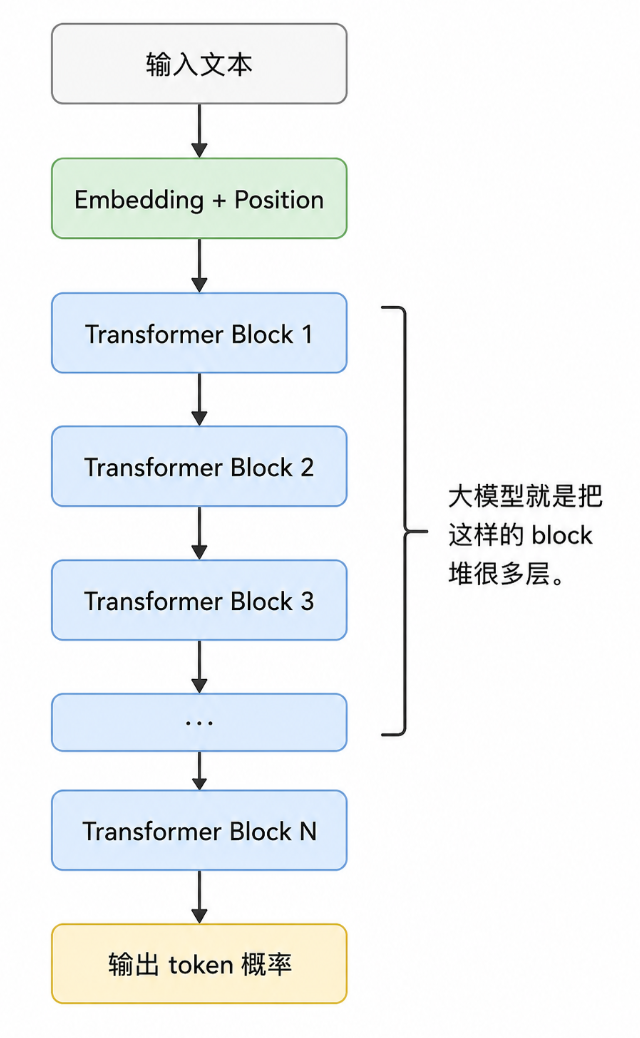
层数越多,参数越多,模型就越有机会学习更复杂的语言规律。当然,这也意味着需要更多数据、更大算力和更复杂的训练工程。
Transformer 如何跑起来?
前面我们已经分别看了 Attention、Self-Attention、Multi-Head Attention、位置编码、Feed Forward Network、残差连接和 LayerNorm。到这里,读者可能会有一个很自然的问题:这些组件组合在一起之后,Transformer 到底是怎么处理一句话的?
这一节我们就把整个流程串起来。先不用纠结每一步背后的公式,只需要理解一件事:
- Transformer 的工作过程,就是不断更新每个 token 的表示,让它从一个孤立的词,逐渐变成融合上下文信息的语义表示。
假设输入一句话:我 喜欢 机器 学习
第一步,Tokenizer 会先把文本切成 token,并转换成 token id。
| token | token id |
|---|---|
| 我 | 101 |
| 喜欢 | 245 |
| 机器 | 830 |
| 学习 | 512 |
这些 id 只是编号,本身没有语义。模型还不能直接理解它们。
第二步,Embedding 层会把每个 token id 转成向量。
| token | 初始向量直觉 |
|---|---|
| 我 | 和说话人、主体相关 |
| 喜欢 | 和情感、偏好相关 |
| 机器 | 和设备、技术相关 |
| 学习 | 和教育、训练、学习行为相关 |
到这一步,每个 token 都有了一个初始表示,但它仍然比较孤立。比如 学习还不知道自己前面有机器,所以还不能确定这里是不是机器学习这个技术概念。
第三步,模型会加入位置信息。
因为 Self-Attention 本身更擅长计算 token 之间的关系,但它并不天然知道顺序。加入位置信息后,模型才知道:
我在第 1 个位置;喜欢在第 2 个位置;机器在第 3 个位置;学习在第 4 个位置。
这一步很重要,因为机器 学习和学习 机器的含义并不一样。
第四步,进入 Self-Attention。
每个 token 都会生成三类向量:Q、K、V。
可以继续用前面的直觉理解:
| 向量 | 作用 | 直觉 |
|---|---|---|
| Q | Query | 我想找什么信息 |
| K | Key | 我有什么信息可被匹配 |
| V | Value | 我真正提供什么内容 |
以学习为例,它会用自己的 Q 去匹配其他 token 的 K,判断哪些 token 对理解自己更重要。
| 被关注 token | 对理解学习的重要程度 |
|---|---|
| 我 | 低 |
| 喜欢 | 中 |
| 机器 | 高 |
| 学习 | 中 |
因为机器和学习之间关系很强,所以学习会更多吸收机器的信息。经过这一步,学习的表示就不再只是普通的学习行为,而更接近机器学习这个技术概念。
第五步,Multi-Head Attention 会从多个角度重复这个过程。
- 一个注意力头可能关注短语搭配,比如
机器 + 学习; - 另一个注意力头可能关注主谓关系,比如
我 + 喜欢; - 还有的注意力头可能关注更长距离的语义关系。
多个头的结果会被合并起来,形成更丰富的 token 表示。
第六步,Feed Forward Network 会继续加工每个 token 的表示。
如果说 Attention 解决的是“应该看谁”,那么 FFN 更像是在做“看完之后怎么理解”。
它会对每个 token 的表示做进一步变换,让模型有能力表达更复杂的语义模式。
第七步,残差连接和 LayerNorm 会帮助信息稳定传递。
残差连接让模型不要每一层都完全重写信息,而是在原有表示上做增量修改。
LayerNorm 则让每一层的数值分布更稳定,避免深层模型训练时出现数值波动太大的问题。
第八步,这样的 Transformer Block 会重复很多层。
- 第一层可能更多学习局部词语关系;
- 中间层可能学习短语、语法、指代关系;
- 更高层可能学习语义、意图和任务模式。
这不是人工规定的分工,而是模型在大量数据训练中逐渐形成的表示能力。
最后,如果是 GPT 这类 Decoder-only 模型,最顶层会输出一个概率分布,用来预测下一个 token。
比如输入:我 喜欢 机器 学习
模型可能预测:
| 候选 token | 可能性 |
|---|---|
| 。 | 高 |
| 和 | 中 |
| 相关 | 中 |
| 桌子 | 低 |
模型选择一个 token 之后,再把它拼回上下文,继续生成后面的内容。
整个流程可以用一张图串起来:
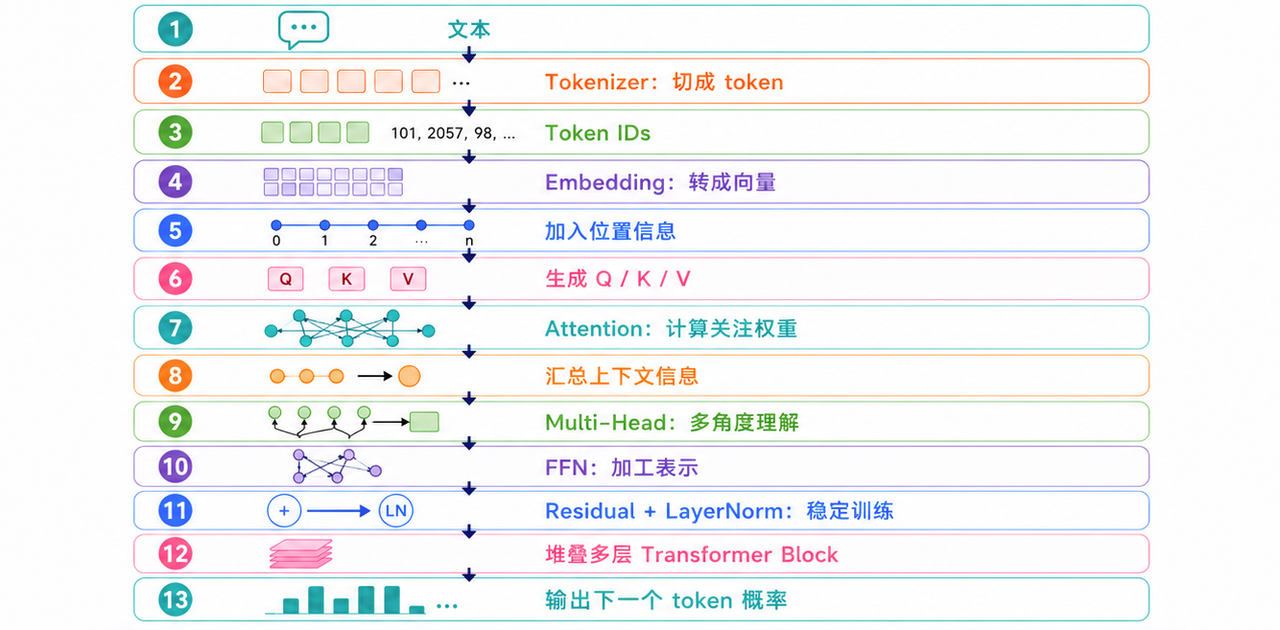
可以把这张图记成一句话:文本先变成 token,token 再变成向量,向量经过多层 Transformer Block 不断融合上下文,最后输出下一个 token 的概率。
这样,Transformer 就不再是一堆独立概念,而是一条完整的计算链路。
总结
讲到这里,我们已经知道 Transformer 的核心能力是:通过 Attention,让文本中的 token 直接建立关系。
但 Transformer 本身并不等同于 GPT,也不只用于生成式大语言模型。它更像是一套基础架构,可以根据任务目标,组合成不同类型的模型。常见的 Transformer 架构大致有三类:
| 架构 | 代表模型 | 适合任务 | 特点 |
|---|---|---|---|
| Encoder-only | BERT | 理解、分类、标注 | 可以看完整上下文 |
| Decoder-only | GPT | 文本生成、对话、代码生成 | 只能看前文,预测后文 |
| Encoder-Decoder | T5、早期翻译模型 | 翻译、摘要 | 一边理解输入,一边生成输出 |
其中,GPT 这类大语言模型主要采用 Decoder-only 架构。
这里需要区分训练阶段和生成阶段:生成时,模型确实是一个 token 一个 token 往后生成;但训练时,模型可以一次性看到一整段文本,并通过 Causal Mask 让每个位置只能关注它前面的 token,从而并行学习每个位置的“下一个 token”预测。
原因也很直观:GPT 的核心任务是生成文本,而生成文本本质上就是不断预测下一个 token。
比如输入:我今天早上喝了一杯
模型需要预测下一个最可能出现的 token:
| 候选 token | 可能性 |
|---|---|
| 咖啡 | 高 |
| 水 | 中 |
| 茶 | 中 |
| 桌子 | 低 |
如果模型生成了“咖啡”,它会把“咖啡”拼回原来的上下文里,再继续预测下一个 token。
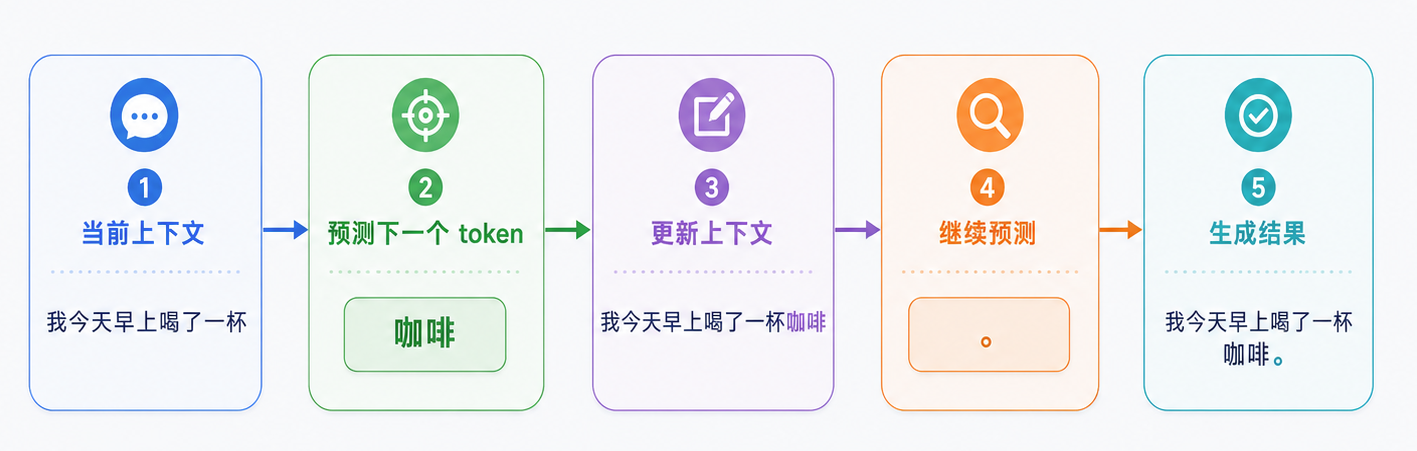
这就是自回归生成。
所谓自回归,可以简单理解为:模型每次只生成一个 token,然后把这个 token 放回上下文,再继续生成下一个 token。
这个过程看起来简单,但它带来了一个很重要的约束:模型在生成当前位置时,只能看到已经出现的内容,不能提前看到后面的答案。
例如模型在预测 咖啡时,只能看到:我今天早上喝了一杯。它不能提前看到完整句子:我今天早上喝了一杯咖啡。
否则就相当于考试时提前看到了答案。
为了保证这一点,Decoder-only Transformer 会使用 Causal Mask,也就是因果掩码。
- Causal Mask 的作用是:当前位置只能关注自己和前面的 token,不能关注后面的 token。
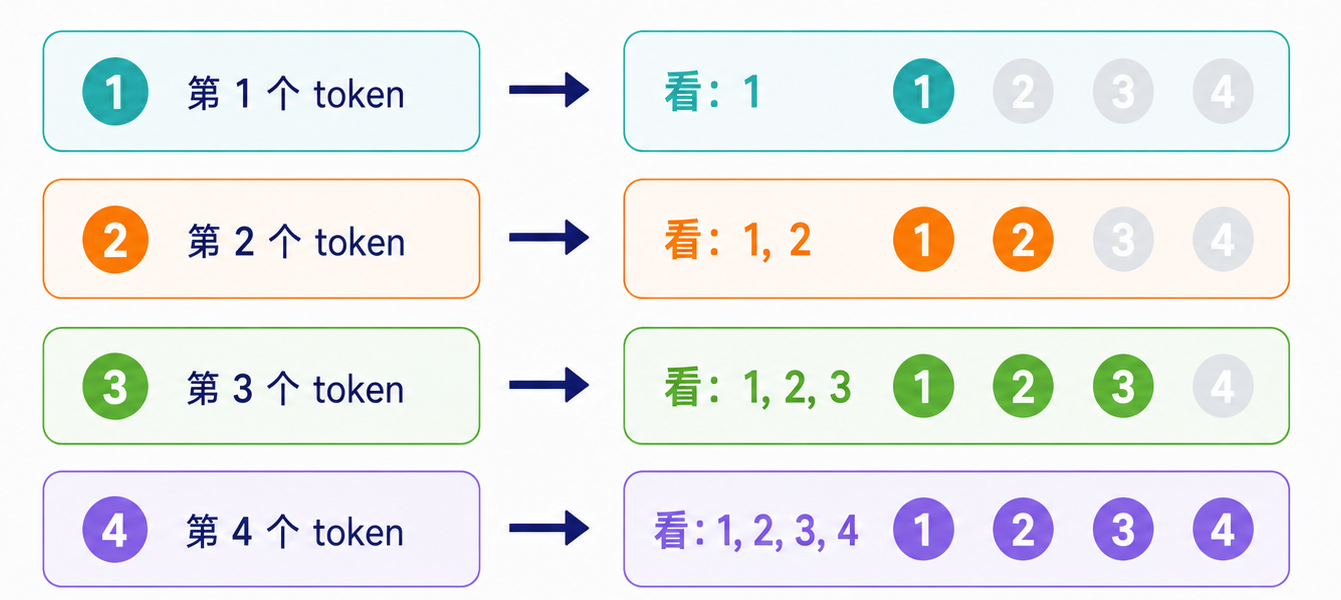
这样一来,Decoder-only Transformer 就和语言模型的训练目标非常匹配:给定前文,预测下一个 token。
现在我们就可以回到文章开头的问题:为什么大模型选择了 Transformer?
可以从五个角度理解:
- Transformer 能直接建模 token 之间的关系:它不需要像 RNN 那样把信息一步步往后传,而是可以通过 Attention 让任意两个 token 直接建立联系。这让模型更容易捕捉长距离依赖和复杂上下文关系。
- Transformer 更适合并行训练:RNN 需要按顺序一步步计算,而 Transformer 在训练阶段可以让一段文本里的 token 同时参与计算。这对大规模数据训练非常重要,也更适合 GPU 这类并行计算硬件。
- Transformer 的表达能力更强:Self-Attention、Multi-Head Attention、多层 Transformer Block 叠加之后,模型可以从多个角度学习语言中的语义、语法、指代、上下文和任务模式。
- Transformer 更适合规模化:现代 LLM 的一个重要特点是规模很大:数据多、参数多、训练计算量大。Transformer 架构在规模变大之后,仍然能持续受益于更多数据和更多参数,这让它成为大模型时代的基础架构。
- Transformer 和“预测下一个 token”的目标非常契合:Decoder-only Transformer 天然适合自回归生成,而很多 NLP 任务都可以转换成文本生成任务。
| 任务 | 输入方式 | 输出方式 |
|---|---|---|
| 翻译 | 请把这句话翻译成英文 | 生成译文 |
| 摘要 | 请总结这篇文章 | 生成摘要 |
| 问答 | 根据材料回答问题 | 生成答案 |
| 分类 | 判断这条评论是正面还是负面 | 生成类别 |
| 写代码 | 根据需求写一个函数 | 生成代码 |
这就是 LLM 很重要的统一性: 很多看起来不同的任务,最后都可以变成“给定上下文,继续生成文本”。
可以用一张图总结 Transformer 到 LLM 的整体流程:
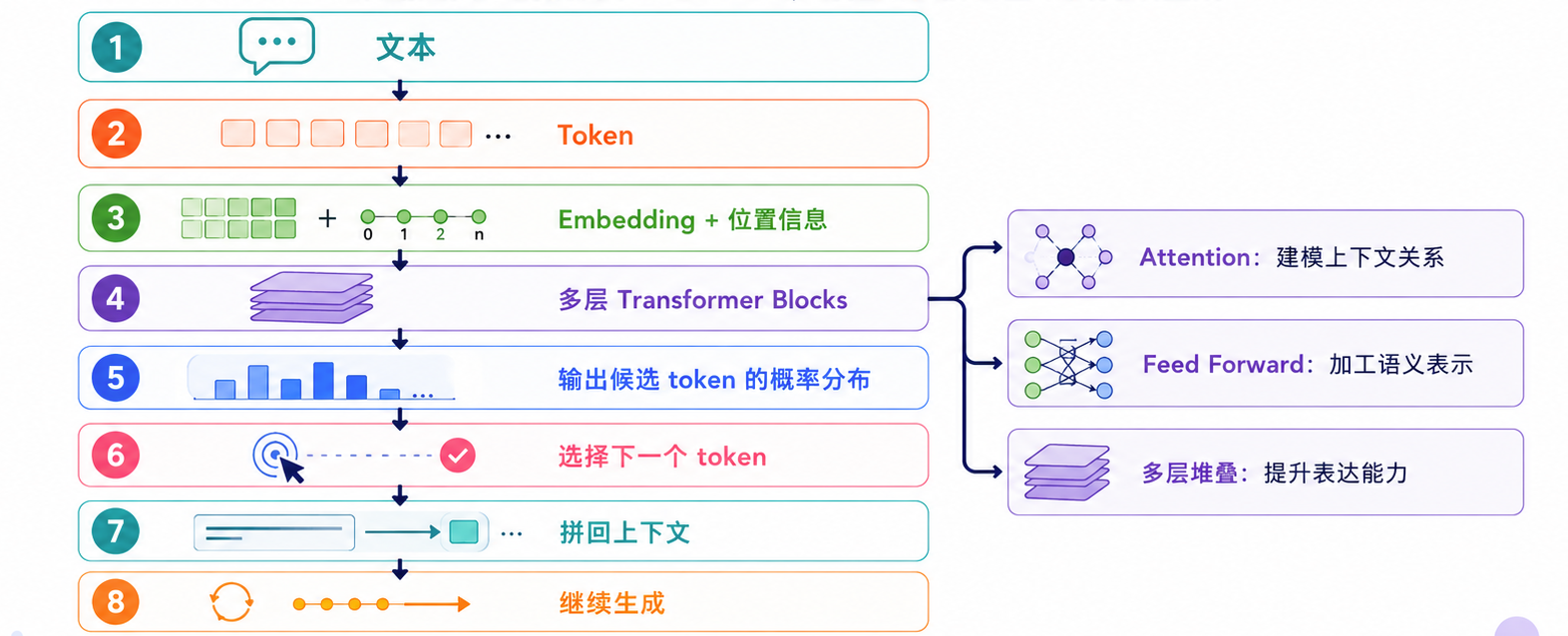
所以,Transformer 不是大模型的全部,但它是现代大语言模型最核心的计算骨架。
它解决的不是某一个单点问题,而是一组关键问题:
| 关键问题 | Transformer 的解决方式 |
|---|---|
| 如何理解上下文? | 用 Attention 建立 token 之间的关系 |
| 如何处理长距离依赖? | 让远距离 token 可以直接互相关注 |
| 如何提升训练效率? | 支持更好的并行计算 |
| 如何增强表达能力? | 通过多头注意力和多层 block 堆叠 |
| 如何生成文本? | 用 Decoder-only 架构预测下一个 token |
理解了 Transformer,再看后面的预训练、指令微调、SFT、RLHF、RAG、Agent、多模态、推理模型,就会清楚很多。
