LLM 系列 (三):算法原理篇:机器是如何学会语言的
前两篇文章分别介绍了大模型的发展脉络和基础数学知识。到了第三篇,我们还需要补上一块很关键的地基:基本的算法原理。不过,这里的“算法原理”并不是一堂严肃的算法课。本文会尽量站在非算法同学的视角,用更通俗、直观的方式,把语言模型背后那些看起来复杂、晦涩的概念拆开讲清楚。
我们不追求推导公式,也不会一上来就深入 Transformer 的细节。本文更希望回答一个核心问题:
- 机器到底是如何一步步学会处理语言的?
理解这个问题之后,再去看 LLM、Transformer、Attention、预训练、微调这些概念,就不会只是记住一堆名词,而是能知道它们分别解决了什么问题,为什么会一步步演进到今天的大语言模型。
读完这篇文章,希望你能清晰回答下面几个问题:
- 为什么要把文本变成 token 和向量?
- 为什么模型可以从数据中学习?
- 为什么神经网络比手写规则更强?
- 为什么传统序列模型不够用?
- 为什么 Transformer 会成为大模型的核心架构?
前言
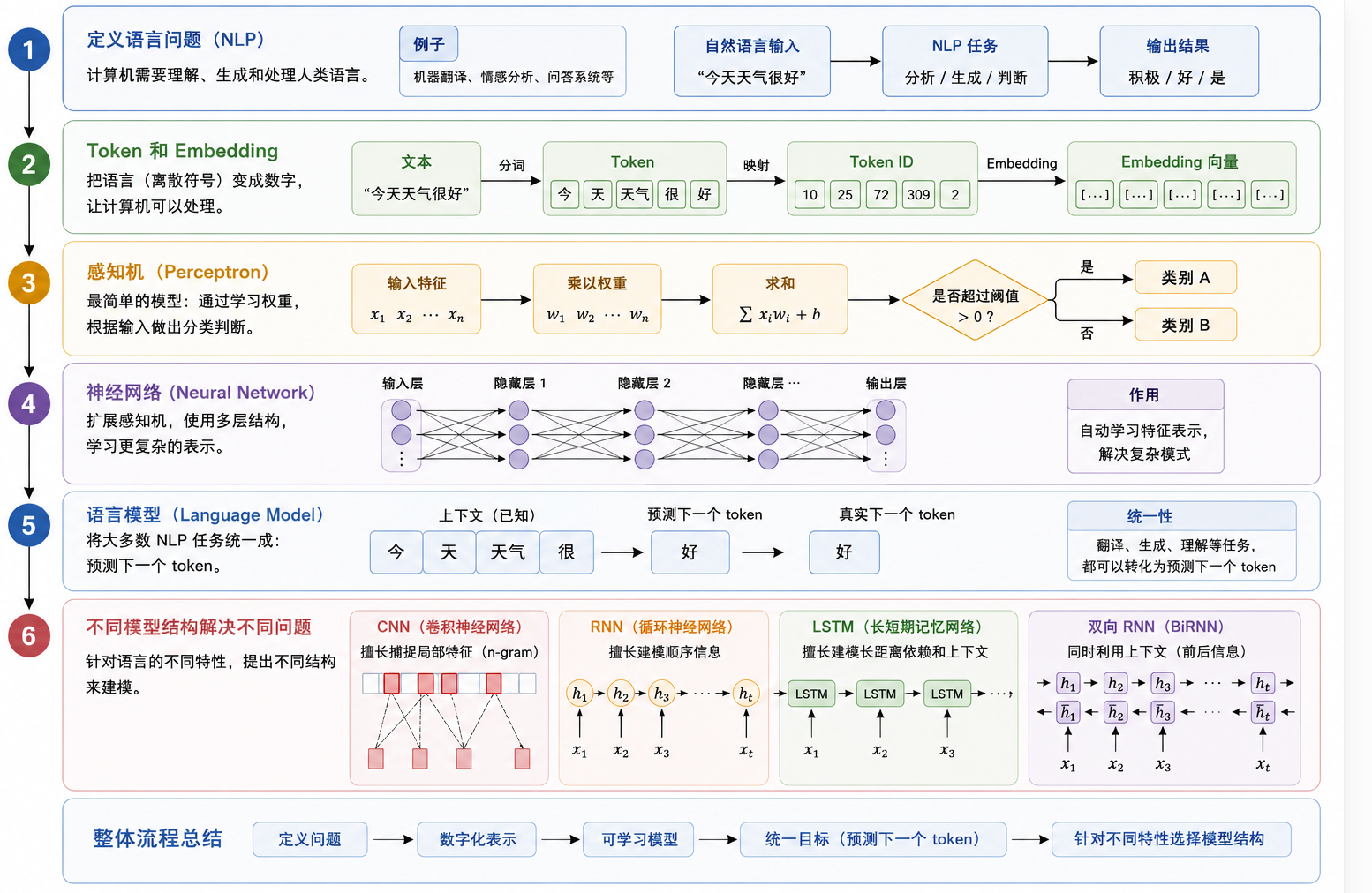
简单来说,这篇文章是为后面深入理解 Transformer 和 LLM 工作原理做准备。我们会从 NLP、词向量、感知机、神经网络讲起,再一路过渡到 CNN、RNN、双向 RNN 等经典模型。核心概念如下表所示:
| 概念 | 它解决什么问题 | 它的不足 | 和 LLM 的关系 |
|---|---|---|---|
| NLP | 让机器处理自然语言 | 语言有歧义和上下文 | 定义了 LLM 要处理的问题 |
| Token | 把文本拆成基本单位 | 切分方式会影响理解 | LLM 的输入和输出单位 |
| 词向量 | 把 token 变成可计算的语义向量 | 早期词向量难表达上下文变化 | LLM 计算语言的基础表示 |
| 感知机 | 让机器学会简单分类 | 只能处理线性问题 | 神经网络的原始雏形 |
| 神经网络 | 自动学习复杂特征 | 需要大量数据和训练 | LLM 的基本学习框架 |
| CNN | 捕捉局部词组特征 | 不擅长长距离依赖 | 早期文本分类常用模型 |
| RNN / 双向 RNN | 按顺序读取文本上下文 | 训练慢,长文本容易遗忘 | Transformer 出现前的重要序列模型 |
| Attention | 动态关注相关信息 | 本篇只做引出 | Transformer 的核心入口 |
NLP:让机器处理语言
NLP,全称 Natural Language Processing,也就是自然语言处理,研究的是如何让机器处理、理解和生成自然语言。它并不是大语言模型出现后才有的概念,早期 NLP 主要依赖人工编写规则和词典,后来逐渐发展到基于统计的方法,再到机器学习和深度学习方法。
对非算法同学来说,可以先不用把 NLP 想得太玄。它本质上是在做一件事:把自然语言问题,转换成机器学习任务。比如:
| 人类要解决的问题 | 对应的机器学习任务 |
|---|---|
| 这条评论是好评还是差评 | 文本分类 |
| 这句话里的公司名是什么 | 序列标注 |
| 两个问题是不是同一个意思 | 文本匹配 |
| 把中文翻译成英文 | 序列生成 |
| 根据文档回答问题 | 阅读理解或生成 |
| 根据上文继续写 | 语言建模 |
语言为什么难?
自然语言难处理,主要不是因为字多,而是因为它不够“规整”。
1 | 苹果很好吃。 |
同样是苹果,第一个是水果,第二个是公司。机器如果只看字面,很难判断。再比如:
1 | 这个模型不太稳定。 |
在不同场景里,模型可能是机器学习模型、业务模型、3D 模型,也可能只是一个抽象方案。也就是说,语言的含义往往不是由单个词决定的,而是由上下文、语序、场景和表达意图共同决定的。
可以把自然语言的难点简单总结成下面几类:
| 难点 | NLP 术语 | 例子 | 机器为什么难 |
|---|---|---|---|
| 一词多义 | 词义消歧 | 苹果、模型、银行 | 同一个词在不同上下文里含义不同 |
| 指代关系 | 指代消解 | 它、这个、那个 | 必须结合前后文判断指的是谁 |
| 语序变化 | 句法分析 | 狗咬人,人咬狗 | 词一样但顺序不同,意思完全不同 |
| 同义表达 | 语义匹配 | 页面很卡、打开很慢 | 表达不同,但语义可能相同 |
| 隐含意图 | 意图识别 | 页面有点慢 | 可能不是描述现象,而是在提出优化诉求 |
所以,NLP 的第一步并不是让机器“真正理解语言”,而是先把这些灵活、模糊、上下文相关的自然语言,转换成机器可以表示、计算和学习的形式。
从文本到 token
模型不能直接处理一整段原始文本。对模型来说,文本需要先被拆成一个个更小的基本单位,这个单位就叫 token。比如下面这句话:
1 | 我喜欢机器学习 |
经过 tokenizer 处理后,可能会被拆成:
1 | [我] [喜欢] [机器] [学习] |
也可能被拆成:
1 | [我] [喜欢] [机器学习] |
不同模型使用的 tokenizer 不完全一样,所以切分结果也可能不同。但它们的目标是一致的:把连续的自然语言文本,转换成模型可以接收的 token 序列。
接下来,每个 token 通常会被映射成一个对应的编号,也就是 token id。比如可以简单理解为:
- [我] -> 101
- [喜欢] -> 245
- [机器学习] -> 1024
这样,文本就从“文字”变成了“数字序列”。tokenizer 整体流程如下所示:
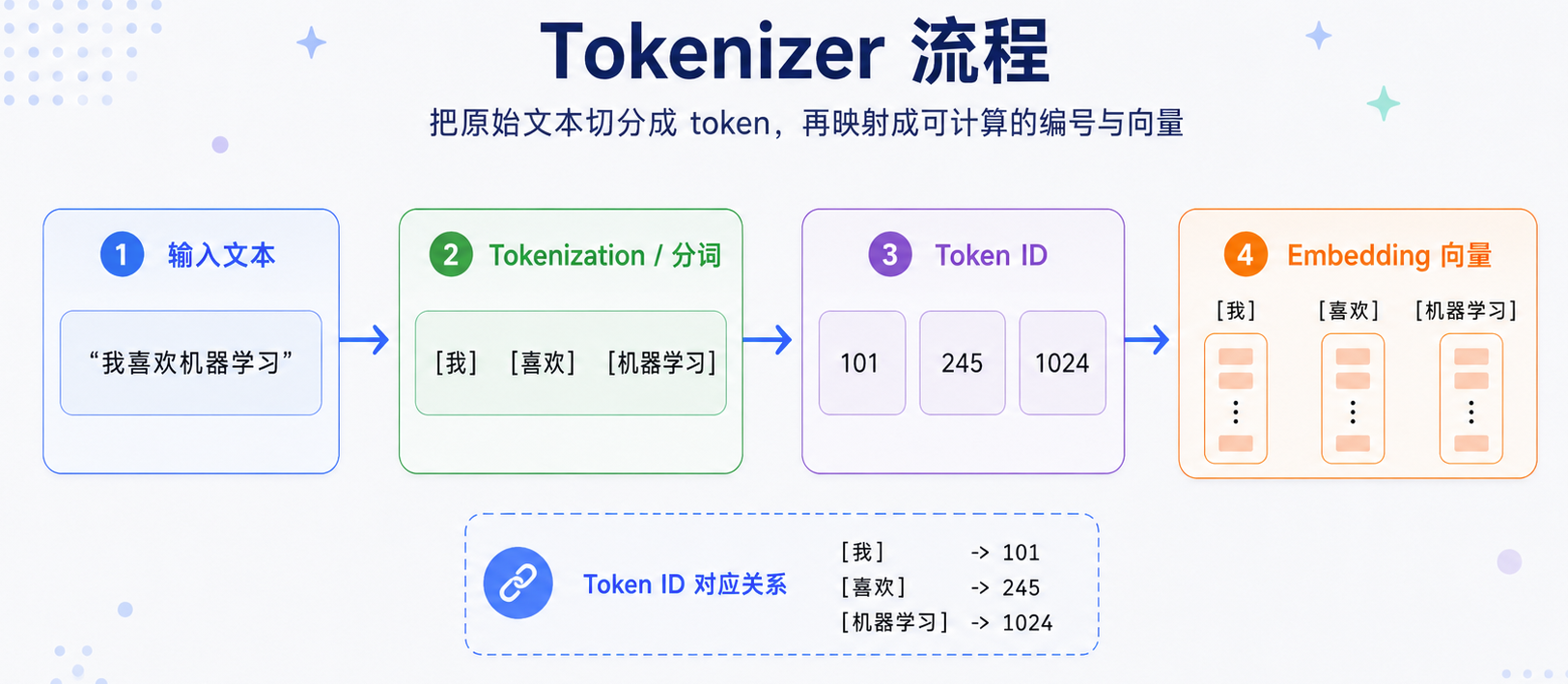
不过,到这一步还不够。token id 只是编号,本身并不包含语义信息。模型知道 101、245、1024 是不同的编号,但并不知道“机器学习”和“深度学习”更接近,也不知道“猫”和“狗”比“猫”和“桌子”更相似。
所以,下一步还需要 embedding,把这些 token 编号转换成真正可以表达语义关系的向量。
Embedding:让 token 有意义
Embedding 可以简单理解为:给每个 token 分配一个向量,让模型能够用数学方式计算词与词之间的关系。也就是说,模型不再只知道“猫”“狗”“桌子”是三个不同的 token,而是能够进一步表示它们在语义上的远近关系。
| token | 向量直觉 |
|---|---|
| 猫 | 接近动物、宠物 |
| 狗 | 接近动物、宠物 |
| 桌子 | 接近家具 |
| 学习 | 接近教育、训练 |
在这样的向量空间里,“猫”和“狗”应该更接近,因为它们都和动物、宠物相关;而“猫”和“桌子”距离会更远,因为它们属于完全不同的语义类别。
这就是 embedding 的核心作用:把离散的 token,变成可以计算相似度和语义关系的向量。
不同模型中,token 的切分方式不同、token 的 embedding 也是不同,embedding 是对应模型训练出来的参数。
词向量:从 one-hot 到 word2vec
在词向量出现之前,常见的文本表示方式是 one-hot(词向量可以看作 embedding 的一种,主要指把词表示成向量)。假设词表里只有 4 个词,每个词都可以用一个只有一位是 1、其余都是 0 的向量表示:
| 词 | one-hot 表示 |
|---|---|
| 猫 | [1, 0, 0, 0] |
| 狗 | [0, 1, 0, 0] |
| 桌子 | [0, 0, 1, 0] |
| 学习 | [0, 0, 0, 1] |
one-hot 的好处是简单,能清楚表示“这个词是谁”。但它的问题也很明显:它不能表示“这个词和谁更像”。
比如“猫”和“狗”在语义上更接近,因为它们都和动物、宠物有关;而“猫”和“桌子”明显不是一类东西。但在 one-hot 表示里,这些词都是彼此独立的编号,模型看不出它们之间的语义远近。
词向量的出现,就是为了解决这个问题。
- word2vec 这类方法的核心直觉是:一个词的意思,可以从它经常出现的上下文中学出来。
比如:我 今天 喝 了 一杯 咖啡
如果“咖啡”经常出现在“喝”“一杯”“早上”这些词附近,模型就会逐渐学到:咖啡更可能和饮品、早餐、杯子这些语义场景相关。
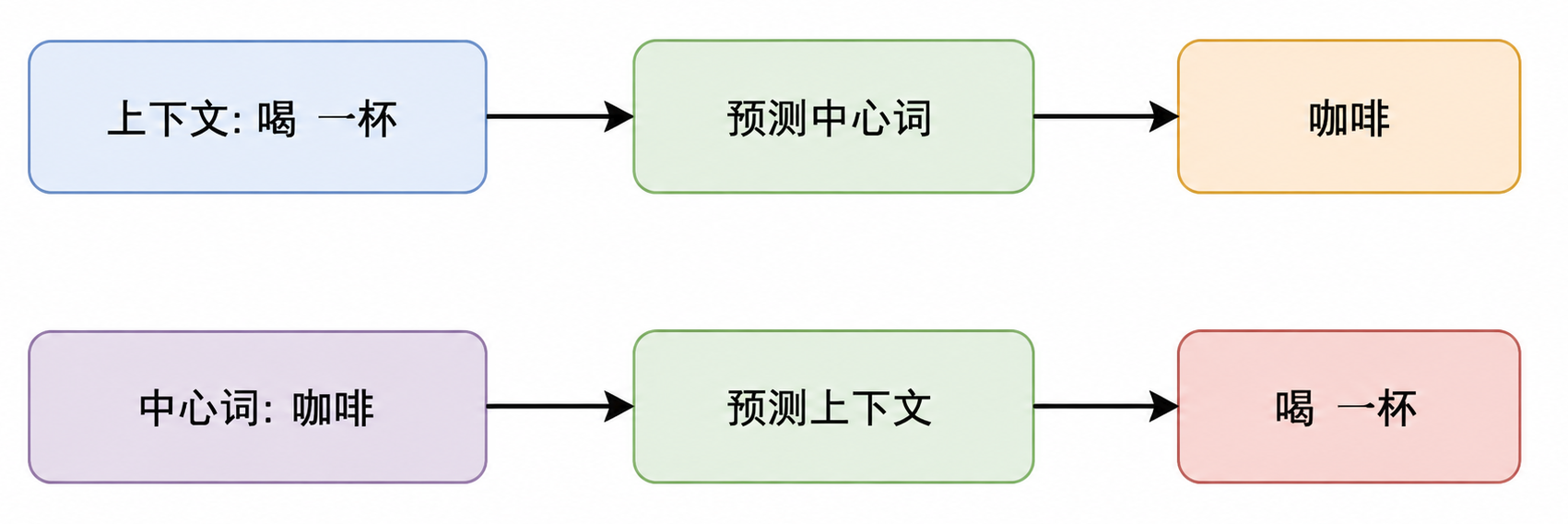
word2vec 中经典训练方式有两类:
| 方法 | 直觉 |
|---|---|
| CBOW | 根据上下文预测中间词 |
| Skip-gram | 根据中心词预测周围词 |
这类词向量的价值在于,它把词从离散编号,放进了一个连续的语义空间。这样一来,模型不仅知道“猫”和“狗”是不同的词,还能知道它们在语义上比“猫”和“桌子”更接近。不过,早期词向量也有明显不足:
| 不足 | 例子 |
|---|---|
| 一个词通常只有一个固定向量 | “苹果”既可能是水果,也可能是公司 |
| 上下文变化表达不够细 | “模型不稳定”在不同场景含义不同 |
| 主要学习词级别关系 | 对长句结构和篇章关系表达有限 |
后来 BERT、GPT 这类模型进一步发展出了上下文相关表示。也就是说,同一个 token 在不同句子里,经过模型计算后可以得到不同的上下文表示。
感知机:机器学习的最小原型
理解神经网络之前,可以先理解感知机。感知机是一个非常早期、非常简单的机器学习模型。它可以看作神经网络的最小原型。
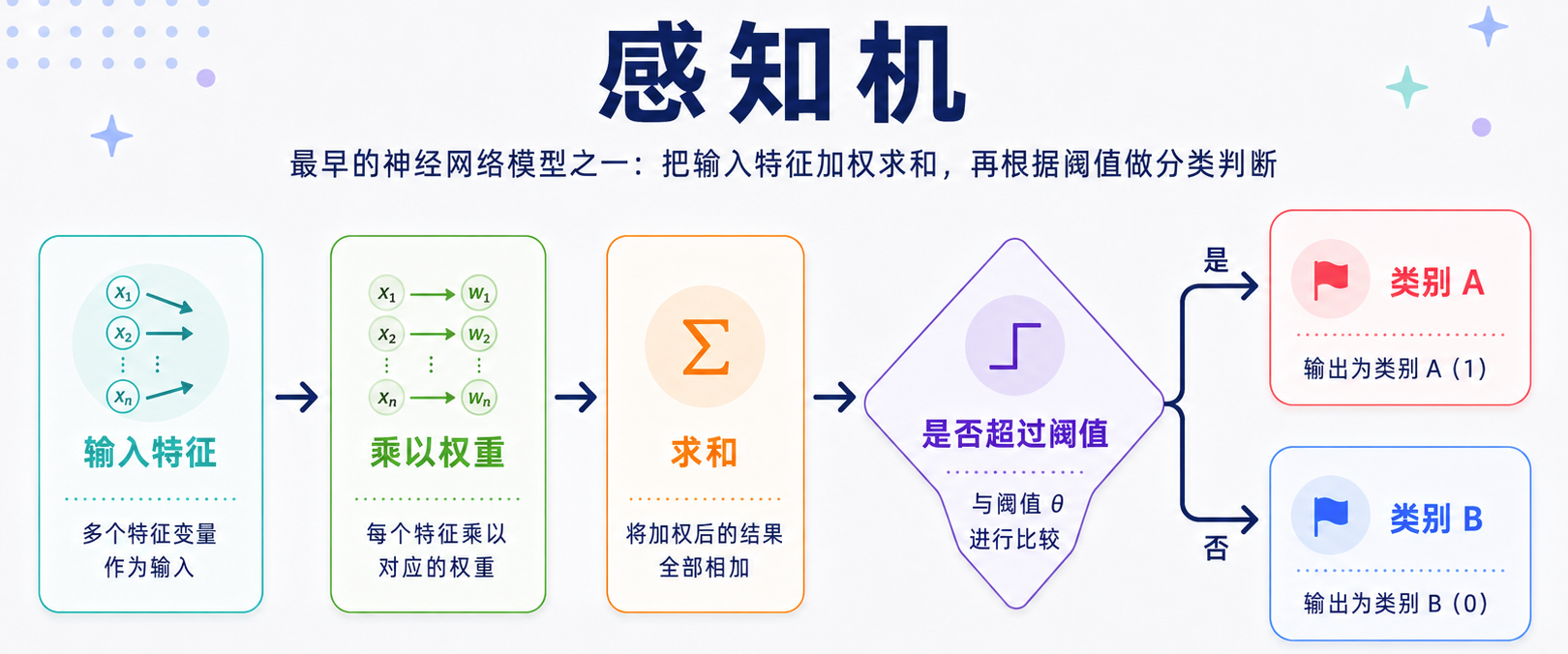
感知机要解决的问题很简单:给定一些输入特征,模型能不能学会做一个基本判断?比如,我们想判断一封邮件是不是垃圾邮件,可以先把邮件拆成一些特征:
| 特征 | 含义 |
|---|---|
| 是否包含“中奖” | 可疑词 |
| 是否包含链接 | 可疑行为 |
| 发件人是否陌生 | 来源特征 |
| 邮件长度 | 内容特征 |
感知机会给每个特征一个权重,然后算一个总分。
1 | 总分 = 特征1 * 权重1 + 特征2 * 权重2 + ... + 偏置 |
如果总分超过某个阈值,就判断为垃圾邮件,否则不是。
所以,感知机本质上就像一张自动学习出来的打分表。它不是靠人手写“如果出现中奖就一定是垃圾邮件”这样的死规则,而是通过数据学习每个特征到底应该占多大权重。
感知机为什么重要?
感知机的重要性在于,它把“机器如何学习”这件事变得非常具体。在感知机之前,我们很容易把机器判断理解成一堆人工规则:如果出现某个词,就执行某个判断。但感知机提供了另一种思路:
- 模型不再完全依赖人手写规则,而是通过数据不断调整权重。
比如一开始,模型可能把“包含链接”这个特征看得太重,导致很多正常邮件也被误判成垃圾邮件。经过训练后,如果模型发现自己判断错了,就会调整相关权重。下一次再遇到类似样本时,判断就可能更准确。
也就是说,感知机已经具备了机器学习最核心的雏形:预测、犯错、调整,再预测。
它和后来的神经网络之间,也有很自然的对应关系:
| 感知机里的东西 | 后来神经网络里的对应物 |
|---|---|
| 输入特征 | 输入向量 |
| 权重 | 参数 |
| 加权求和 | 线性变换 |
| 阈值判断 | 激活函数 |
| 调整权重 | 训练 |
感知机的不足
感知机的优点是简单,缺点也正是太简单。它主要适合处理“线性可分”的问题。简单来说,如果两类样本可以用一条直线分开,感知机就比较擅长;如果样本分布更复杂,无法用一条直线清楚分开,感知机就会很吃力。
可以把它想象成下面这种情况:一边是类别 A,一边是类别 B,中间只需要一条分界线,就能把它们区分开。
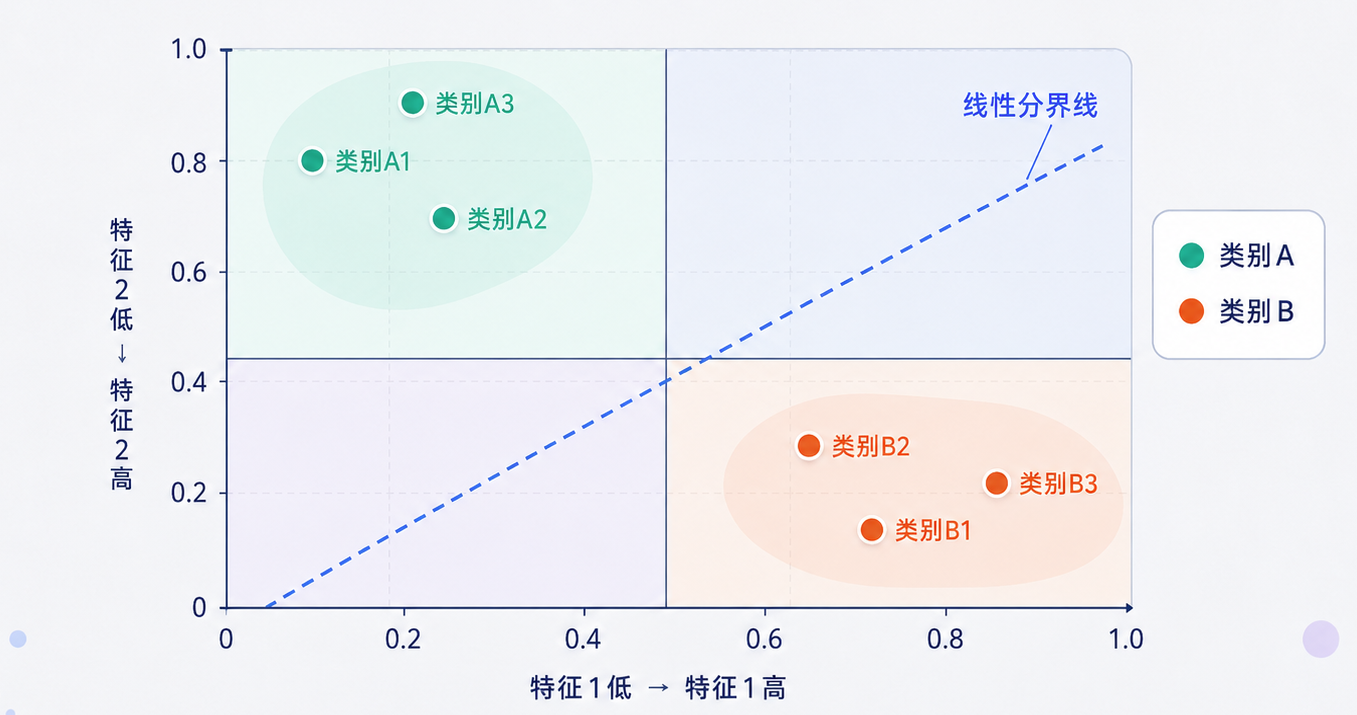
但真实语言问题显然没有这么简单。一句话的含义,往往不是几个特征简单加权就能判断出来的。比如,“这家店的服务可真好,等了两个小时都没人理我”。这句话里,如果只看 “服务”“真好”这些词,模型可能会判断成正面评价,但结合后半句看,实际可能是在表达不满。
语言里有词语组合、上下文变化、语气反转、长距离依赖等复杂现象。单个感知机很难处理这些非线性、上下文相关的问题。所以,我们需要更强的模型:能够把简单特征不断组合,学习更复杂的表示。这就走向了神经网络。
神经网络:从简单到复杂
神经网络可以粗略理解为:把很多类似感知机的计算单元连接起来,形成一个可以学习复杂模式的系统。感知机只做一次加权求和。神经网络会把这种计算堆很多层。如下图所示:
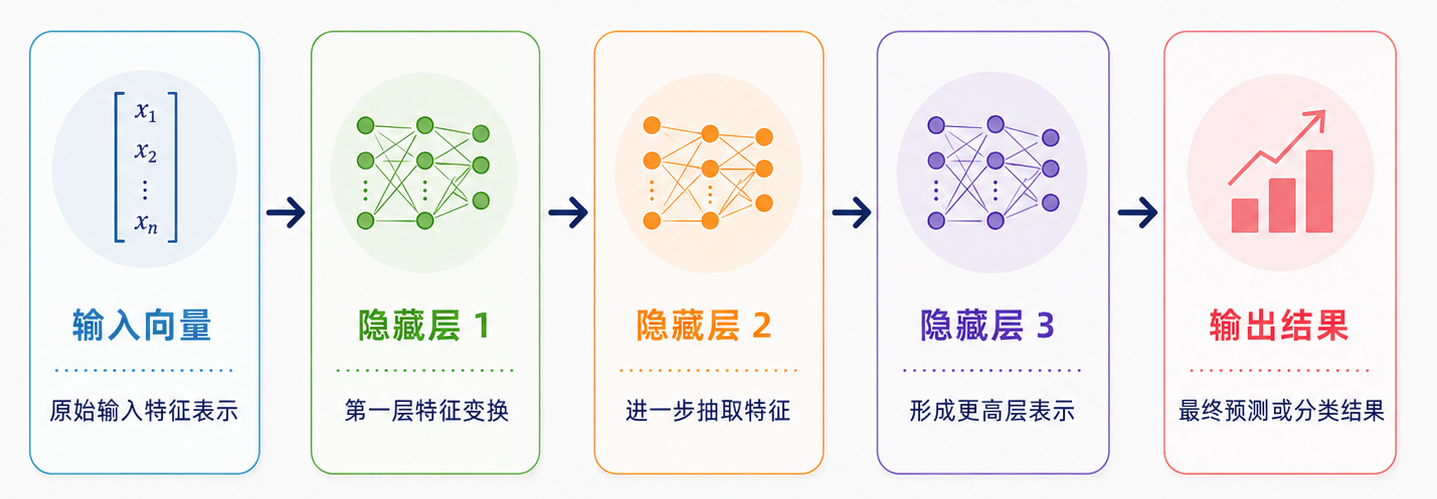
每一层都会对输入做一次表示变换。层数多了以后,模型就有机会学习更复杂的关系。
为什么需要“多层”?
可以用图片识别来类比:模型最底层可能先识别边缘、颜色、纹理;中间层再组合出局部形状;更高层才逐渐识别出完整对象,比如猫、狗、汽车。
语言处理里也类似。模型不是一开始就能理解“这句话表达了什么意图”,它通常需要从更基础的信息一层层组合上来:
| 层次 | 可能学习到什么 |
|---|---|
| 底层 | token、词形、局部搭配 |
| 中层 | 短语、语法关系 |
| 高层 | 语义、意图、任务模式 |
这就是“表示学习”的直觉:模型不只是接收特征,而是在训练中自己学习更有用的中间表示。
神经网络如何训练?
神经网络的训练循环可以概括成三个词:预测 -> 评估 -> 修正
这和人做题有点像:先根据当前能力做出答案,再对照标准答案看错在哪里,最后根据错误调整方法。模型训练也是类似的过程。完整流程可以简化成下面这张图:
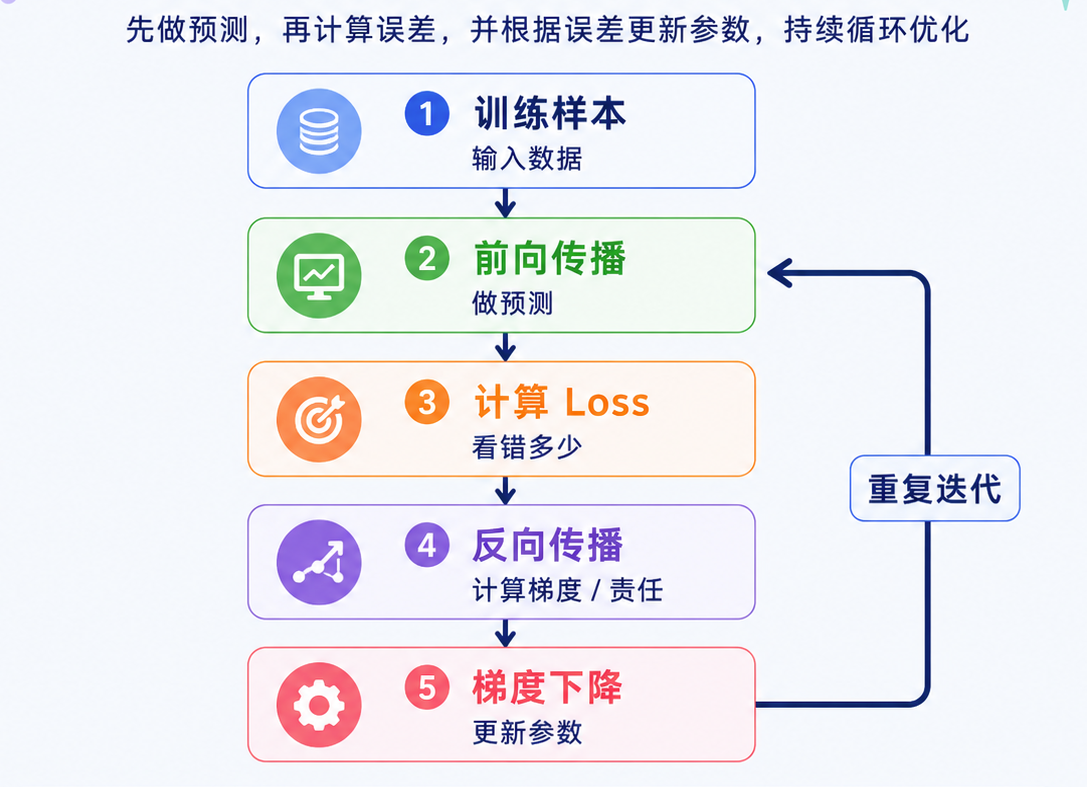
其中几个关键概念可以这样理解:
| 概念 | 小白解释 |
|---|---|
| 前向传播 | 输入一路经过模型,得到预测 |
| Loss | 模型预测和正确答案之间的差距 |
| 反向传播 | 把错误反向传回每一层 |
| 梯度 | 参数应该往哪个方向改 |
| 梯度下降 | 沿着让错误变小的方向更新参数 |
模型不是一次就学会的,而是在大量样本上不断预测、犯错、修正,再继续预测。训练的过程,本质上就是让模型的参数一点点变得更合适。
神经网络的不足
神经网络比感知机强很多,它可以通过多层结构学习更复杂的模式。但普通的前馈神经网络并不天然适合处理语言。原因很简单:语言是有顺序的。比如,下面两句话:
1 | 我不喜欢这个方案。 |
这两句话只差一个“不”,但含义完全不同。如果模型只是把词当成一组特征,而不能理解它们出现的位置和顺序,就很容易判断错误。
所以,对于语言任务来说,仅仅能学习复杂特征还不够。模型还必须能够处理 token 之间的顺序关系、上下文关系,以及长句中前后信息的依赖关系。这就引出了下一类模型:能够处理文本结构和上下文关系的经典神经网络,比如 CNN、RNN、LSTM 和双向 RNN。
序列模型:让模型读懂上下文
语言不是一组孤立的特征,而是一串有顺序的 token。前面的词会影响后面的词,后面的表达也依赖前面的上下文。因此,在 NLP 中有一个非常核心的问题:
- 给定前面的内容,模型能不能预测接下来最可能出现什么?
这就是语言模型要解决的问题。
语言模型:预测下一个 token
语言模型最朴素的直觉,就是根据前面的内容,预测接下来最可能出现什么。比如:
- 我今天早上喝了一杯 __
模型需要判断空白处更可能出现哪个 token:
| 候选 token | 可能性 |
|---|---|
| 咖啡 | 高 |
| 水 | 中 |
| 茶 | 中 |
| 桌子 | 低 |
这个过程看起来像“填空题”,但它非常关键。因为只要上下文足够丰富,很多 NLP 任务都可以转化成“继续生成后面的内容”。比如:
| 任务 | 输入方式 | 输出方式 |
|---|---|---|
| 翻译 | 请翻译这句话 | 生成译文 |
| 摘要 | 请总结这篇文章 | 生成摘要 |
| 问答 | 根据材料回答问题 | 生成答案 |
| 分类 | 判断正面还是负面 | 生成类别 |
| 写代码 | 根据需求写函数 | 生成代码 |
这就是大语言模型的统一性:它没有为每个任务单独设计一套模型,而是把很多任务都转化成“给定上下文后继续生成”。
所以,LLM 的很多能力,底层都可以先用一句话来理解:根据上下文,预测下一个 token。
模型一:CNN 捕捉局部特征
很多人第一次接触 CNN(Convolutional Neural Network,又叫做卷积神经网络),是在图像识别里。图像里的 CNN 会用卷积核扫描图片的局部区域,提取边缘、纹理、形状等特征。文本里也可以使用 CNN。只不过它扫描的不是像素,而是一串 token 对应的向量。
可以把它理解成:
- CNN 擅长从文本中抓局部模式,比如几个词组成的短语。
例如:
1 | 这个 产品 非常 好用 |
CNN 可以用不同大小的窗口扫过句子:
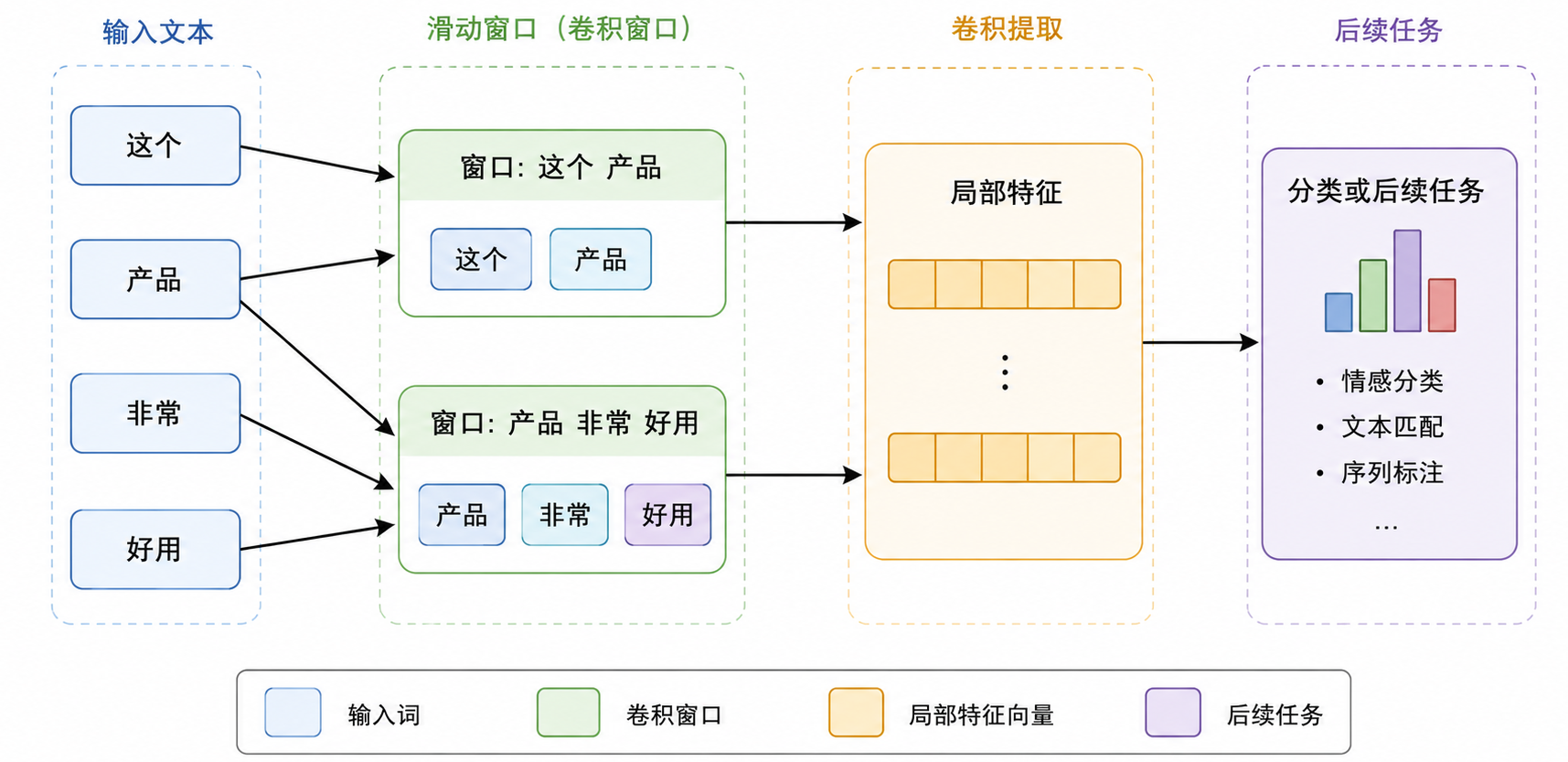
在早期文本分类里,CNN 很实用。比如情感分析中,“非常好用”“极其糟糕”“不推荐购买”这些局部短语很有判断价值。但 CNN 的不足也明显:
| 优点 | 不足 |
|---|---|
| 擅长提取局部 n-gram 特征 | 对很远的词之间关系不敏感 |
| 并行效率较好 | 需要通过多层堆叠扩大感受野 |
| 适合分类任务 | 不天然适合逐步生成文本 |
所以,CNN 在 NLP 里更像是一个“局部特征提取器”。它能很好地抓住短语级别的模式,但不擅长处理长距离依赖。也就是说,如果一句话前面很远的信息会影响后面的判断,CNN 就会比较吃力。
模型二:RNN 按顺序读取文本
RNN,全称 Recurrent Neural Network,中文叫循环神经网络。它是一类专门用来处理序列数据的模型,比如文本、语音、时间序列等。它的基本思路是:
- 从左到右依次读取文本,每读一个 token,就把当前 token 的信息和前面已经读到的信息合并起来,更新成一个新的隐藏状态。
可以简单理解为,RNN 在读一句话时,会一边读当前词,一边带着前面的“记忆”继续往后读。如下图所示:
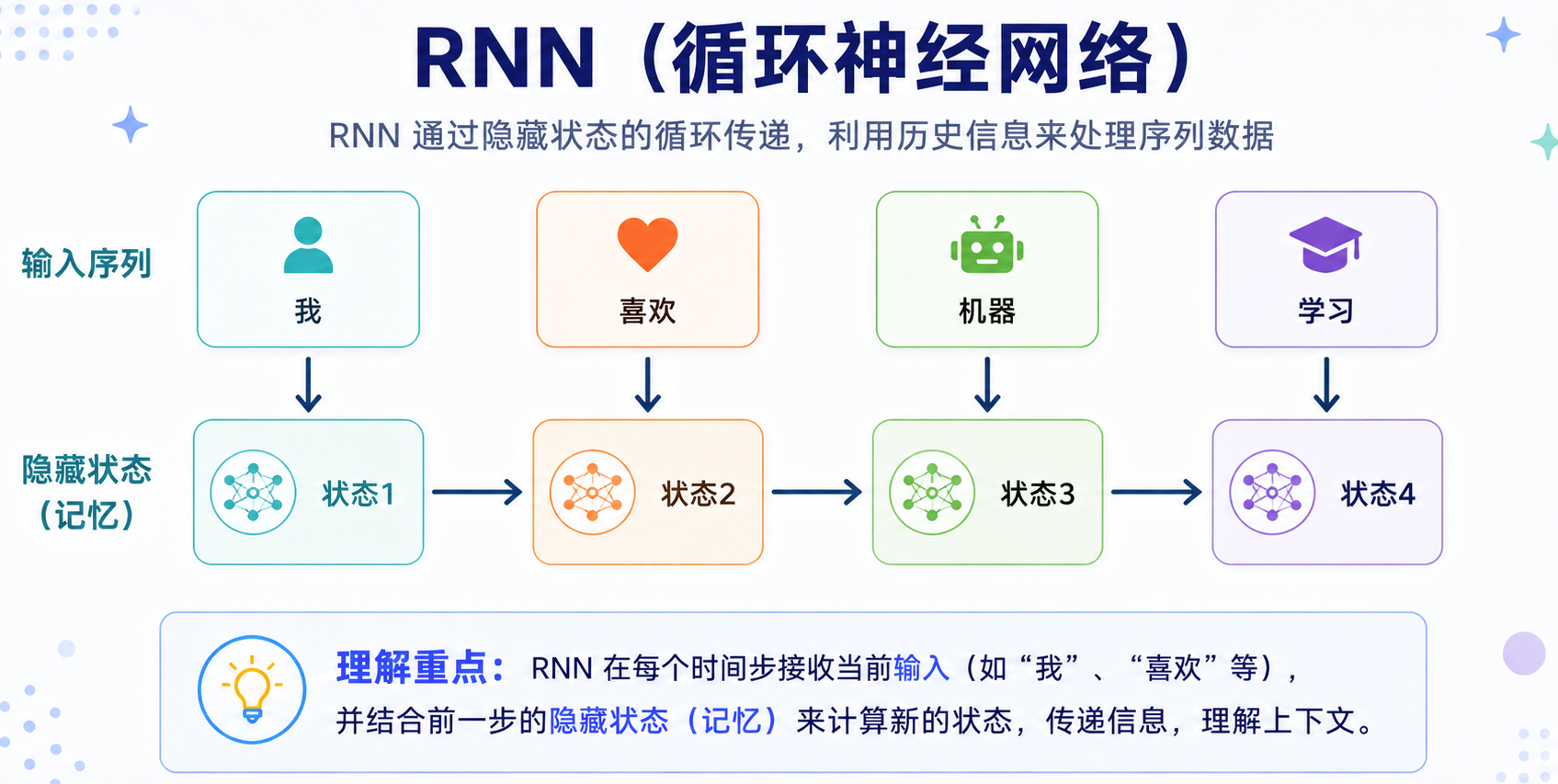
这里的 状态 可以理解为模型到目前为止读到的信息摘要。每读一个新的 token,模型都会更新一次状态。相比 CNN,RNN 更适合表达文本顺序,因为它不是只看局部窗口,而是按顺序一步步读取整句话。
比如读到“我不喜欢这个方案”时,RNN 有机会把“不”这个信息传到后面,影响对整句话的判断。但 RNN 有两个经典问题:
| 问题 | 说明 |
|---|---|
| 长距离依赖困难 | 前面很远的信息传到后面时容易变弱 |
| 并行能力弱 | 后一个状态依赖前一个状态,训练不容易并行 |
所以,RNN 比 CNN 更擅长处理顺序,但当文本变长时,它对长距离上下文的记忆能力仍然有限。
模型三:LSTM 和 GRU 试图增强记忆
LSTM 和 GRU 都是 RNN 的改进版本。它们出现的主要目的,是缓解普通 RNN 容易“忘记前文”的问题。普通 RNN 在读取长文本时,前面的信息需要一步步传到后面。句子越长,早期信息越容易被稀释。LSTM 和 GRU 的改进思路是:给模型增加一种 门控机制。
可以先不用记复杂结构,只抓住一个直觉:LSTM / GRU 给模型增加了 门,让模型自己决定哪些信息要记住,哪些信息要忘掉。
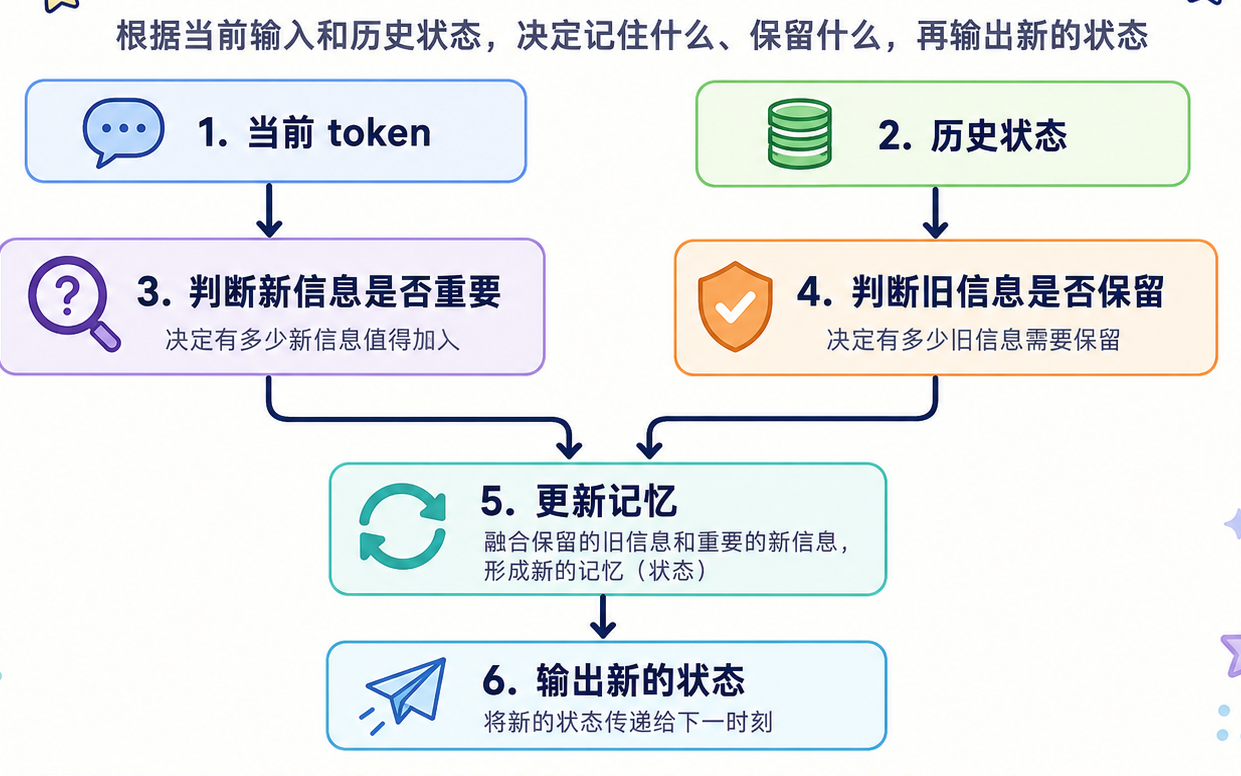
比如这句话:我昨天在朋友推荐的一家店里喝了一杯咖啡。如果模型要预测或理解最后的“咖啡”,它需要记住前面的“喝了一杯”。LSTM/GRU 就是在努力让这种关键信息不要太快丢失。
所以,相比普通 RNN,LSTM / GRU 更擅长处理稍长一些的上下文,也曾经广泛用于机器翻译、语音识别、文本分类等任务。但它们仍然没有彻底解决问题:
| 不足 | 说明 |
|---|---|
| 仍然偏顺序处理 | 长文本训练效率有限 |
| 远距离信息仍可能衰减 | 只是缓解,不是根治 |
| 很难直接建模任意两个 token 的关系 | 信息主要通过状态逐步传递 |
也就是说,LSTM / GRU 让模型“记得更久了一些”,但还没有让模型真正做到“直接看到所有相关信息”。
模型四:双向 RNN 同时看前后文
普通 RNN 通常是从左往右读取文本,因此它在处理当前位置时,主要依赖已经读过的前文信息。但很多语言理解任务,只看前文是不够的,还需要结合后文一起判断。
比如: 苹果 发布 了 新产品
如果只看“苹果”前面的内容,几乎没有有效信息;但如果同时看到后面的“发布”“新产品”,就更容易判断这里的“苹果”指的是公司,而不是水果。
双向 RNN 的思路就是:让模型从两个方向同时读句子。
- 一条 RNN 从左往右读,获取前文信息;
- 另一条 RNN 从右往左读,获取后文信息;
- 最后把两个方向的信息合并起来,得到更完整的上下文表示。
可以简单理解为:
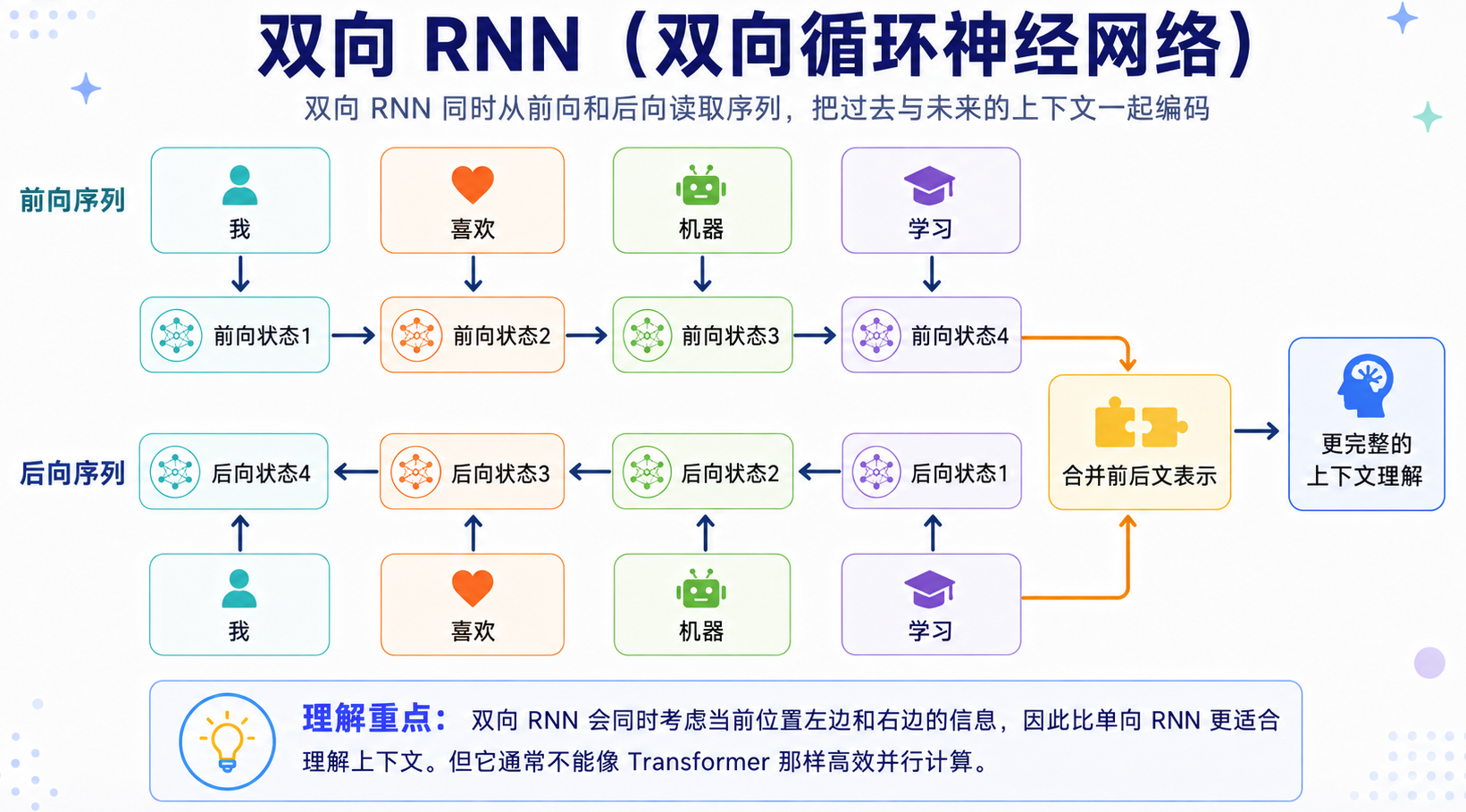
双向 RNN 在很多语言理解任务中非常有用,比如命名实体识别、文本分类、序列标注、句子匹配等。因为这些任务通常可以先看到完整句子,再做判断。不过,双向 RNN 也有自己的边界:
| 场景 | 是否适合 |
|---|---|
| 句子理解、分类、标注 | 适合 |
| 实时生成下一个 token | 不太适合,因为它依赖未来信息 |
原因也很直观:生成式语言模型在写下一个 token 时,只能根据已经出现的内容继续往后生成,不能提前看到未来答案。因此,双向 RNN 更适合理解类任务,而不适合作为自回归生成模型的直接结构。
小结
把这些经典模型放在一起看,脉络就很清楚:
| 模型 | 擅长什么 | 主要不足 |
|---|---|---|
| CNN | 抓局部短语特征 | 不擅长长距离依赖 |
| RNN | 按顺序建模文本 | 长文本容易遗忘,训练慢 |
| LSTM / GRU | 增强记忆能力 | 仍然偏顺序传递 |
| 双向 RNN | 同时利用前后文 | 不适合自回归生成 |
这些模型都在不同阶段推动了 NLP 的发展,但它们也都没有彻底解决一个核心问题:长距离依赖。比如:
- 虽然我昨天在朋友推荐的那家开在巷子深处、装修很有特色、排队也很久的咖啡店里坐了很久,但最后只点了一杯 __
要预测最后空白处的词,模型需要记住前面较早出现的“咖啡店”。如果前文信息在传递过程中被不断稀释,模型可能就无法准确判断这里更可能是“咖啡”,而不是“水”“酒”或其他东西。
这就是 Transformer 出现前,序列建模面临的关键挑战:如何让模型在处理当前位置时,更高效地找到上下文中真正相关的信息。
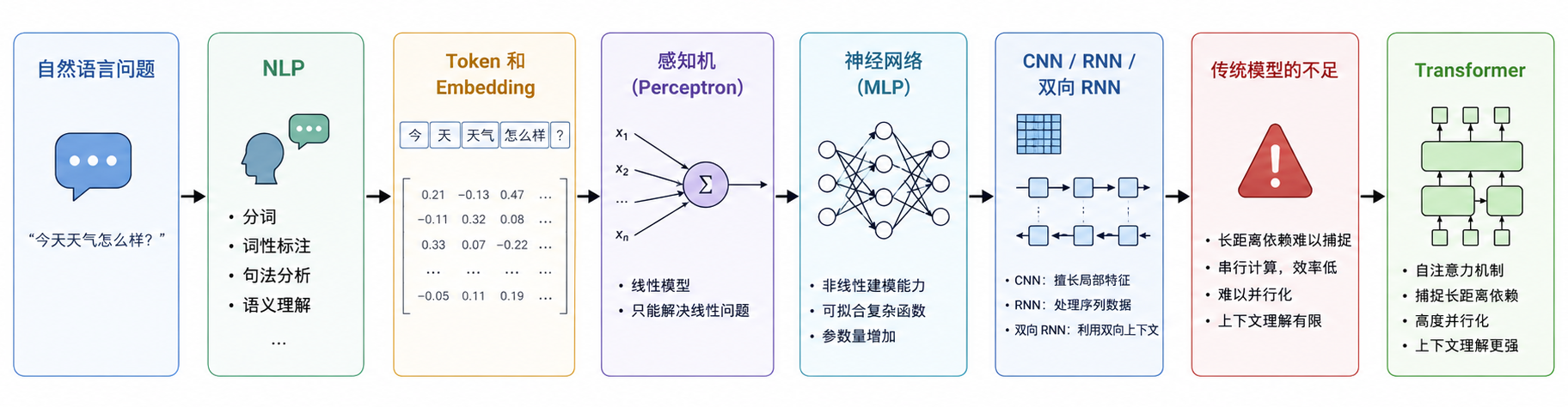
总结
回到文章开头提出的问题:机器到底是如何一步步学会处理语言的?
现在我们可以把这条路径串起来看:
- 首先,NLP 把自然语言问题转换成机器可以处理的任务;
- 接着,token 和 embedding 把文本从“文字”变成可计算的数字表示;
- 然后,感知机和神经网络说明模型并不是靠人手写规则,而是可以通过数据不断调整参数、学习规律;
- 再往后,CNN、RNN、LSTM/GRU、双向 RNN 等模型不断尝试处理语言中的局部特征、顺序关系和上下文依赖;
- 最后,Transformer 通过 Attention 机制,让模型能够更直接地关注上下文中真正相关的信息。
所以,LLM 并不是突然出现的“魔法”。它背后是一条长期演进出来的技术路线。LLM 的能力不是来自某一个单点技术,而是来自语言表示、模型训练、上下文建模和大规模数据共同作用的结果。
最后,用一张图总结本文的核心内容:从语言进入模型,到模型学会预测,再到 Transformer 成为现代 LLM 的核心架构。