LLM 系列 (二):机器如何把语言变成数学
上一篇我们从大模型的发展脉络出发,回顾了语言模型如何从早期的统计方法,一步步走向 Transformer、GPT,以及今天无处不在的大模型应用。如果说第一篇回答的是“LLM 是怎么发展到今天的”,那么这一篇想往下多走一层,回答一个更底层的问题:LLM 为什么能被训练出来?机器到底是怎样把语言变成可计算、可优化、可生成的东西?
无论是 Transformer 里的 Attention,预训练里的 loss,微调时的梯度更新,RAG 里的向量检索,还是 LoRA 里的低秩矩阵,本质上都绕不开几类基础数学概念。不过,这篇并不是要把大家重新拉回大学数学课堂。我们不会从定理证明开始,也不会堆大量公式。更重要的是建立一套直觉:机器如何把文字变成向量,如何计算词与词之间的关系,如何预测下一个 token,又如何通过错误和梯度一步步修正自己。
前言
LLM 看起来像是在“理解语言”,但从机器的视角看,它一直在做三件事:
1 | 预测 -> 评估 -> 修正 |
给定一句话:
1 | 我今天早上喝了一杯 __ |
模型会输出一组概率:
| 候选 token | 概率 |
|---|---|
| 咖啡 | 0.62 |
| 水 | 0.18 |
| 茶 | 0.11 |
| 牛奶 | 0.06 |
| 其他 | 0.03 |
这件事背后已经包含了 LLM 最核心的数学链路(这些数学概念和 LLM 概念,会在本系列文章中给读者介绍明白):
| 机器要解决的问题 | 背后的数学 | 对应的 LLM 概念 |
|---|---|---|
| 文字怎么变成数字? | 向量、矩阵、张量 | token、embedding |
| 词之间怎么产生关系? | 点积、相似度、矩阵乘法 | attention、Q/K/V |
| 下一个词怎么预测? | 条件概率、Softmax | next token prediction |
| 错误怎么衡量? | 交叉熵、最大似然 | loss |
| 参数怎么修正? | 梯度、链式法则 | backpropagation |
| 模型怎么变好? | 梯度下降、优化器 | training、fine-tuning |
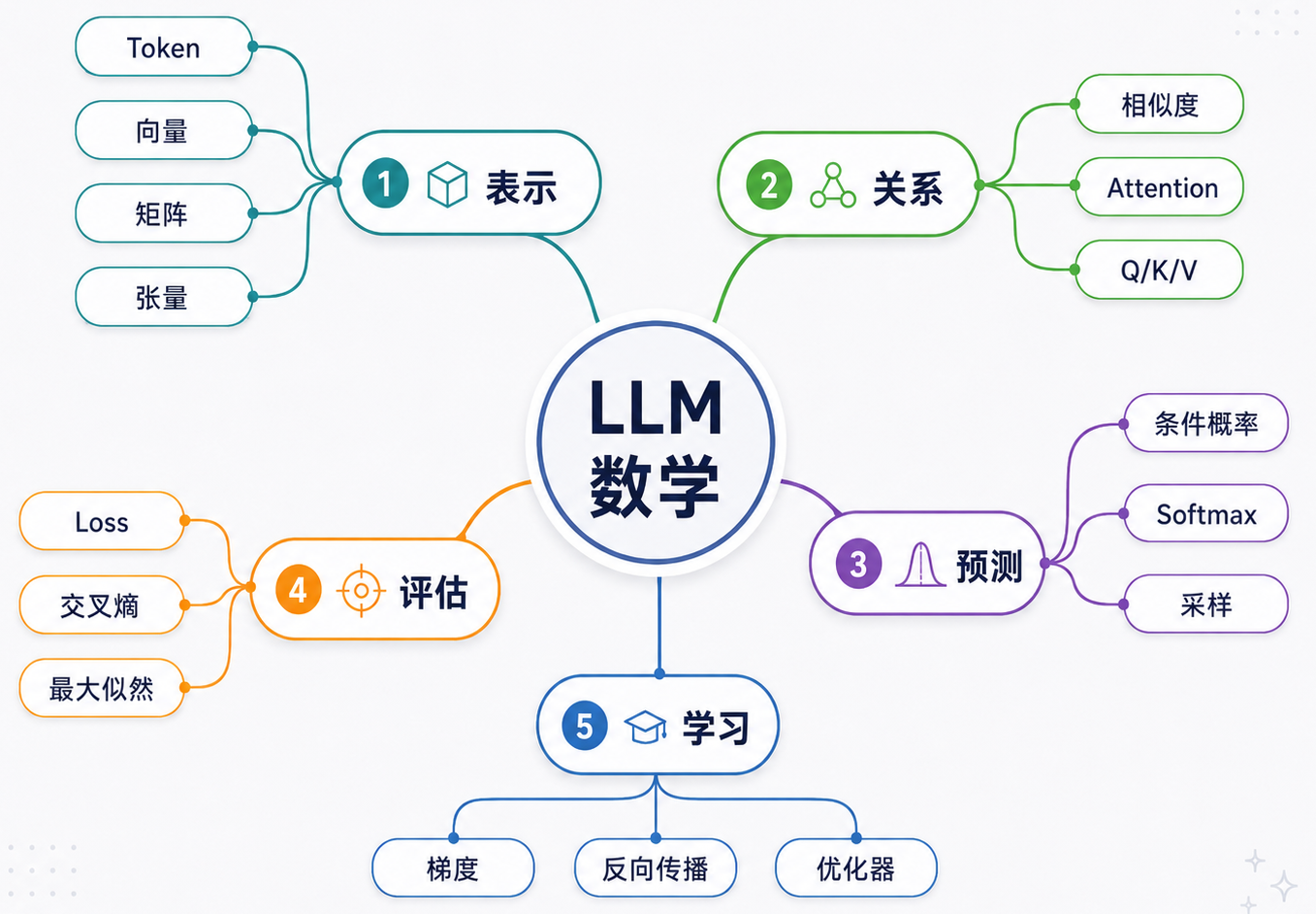
可以把 LLM 的数学主线先简化成下面这张图:
LLM 本质上是在做一件事:先把语言翻译成数字,再用数学计算关系,最后用错误信号反过来修正模型。
总而言之,LLM 的数学不是抽象公式,而是一套让机器理解语言的翻译系统:NLP 告诉我们语言问题难在哪里,线性代数把文字变成向量,Transformer 用 Attention 计算上下文关系,概率论把生成变成“预测下一个 token”,微积分把错误转化为梯度,优化方法则推动模型在一次次更新中变得更好。
如果上面的概念这里完全搞不清楚,也没关系,接下来这个系列的文章,从本章开始会逐步给读者介绍清楚,不过前提是读者有大学数学的基础,明白线性代数、概率统计、微积分的基础原理。
表示与关系:语言如何变成向量并计算相关性
这一节本质上要解决两个问题:
- 语言如何变成机器可以计算的数字?
- 模型如何计算词与词之间的关系?
这两个问题对应 LLM 中非常核心的两类能力:
- 一类是“表示”:把文字变成向量。
- 一类是“关系”:计算这些向量之间谁和谁更相关。
如果说人类读一句话靠语感、经验和上下文,那么机器读一句话,第一步就是把它翻译成数学结构。
从文字到 Token:模型处理语言的最小单位
在进入向量、矩阵和 Attention 之前,需要先理解一个基础概念:Token。人类读文章时,看到的是字、词、句子和段落;但 LLM 并不是直接以“完整句子”为单位处理语言。它会先通过 Tokenizer,把文本切分成一个个更小的单位,这些单位就叫做 token。
- Token 可以是一个字、一个词、一个词的一部分,也可以是标点符号。不同模型使用的 tokenizer 不同,切分结果也可能不一样。
例如一句话:我喜欢喝咖啡。
可能会被切成:
- 我 / 喜欢 / 喝 / 咖啡 / 。
也可能被切成更细的片段。
在模型内部,每个 token 会先被转换成一个编号,再进一步转换成向量。
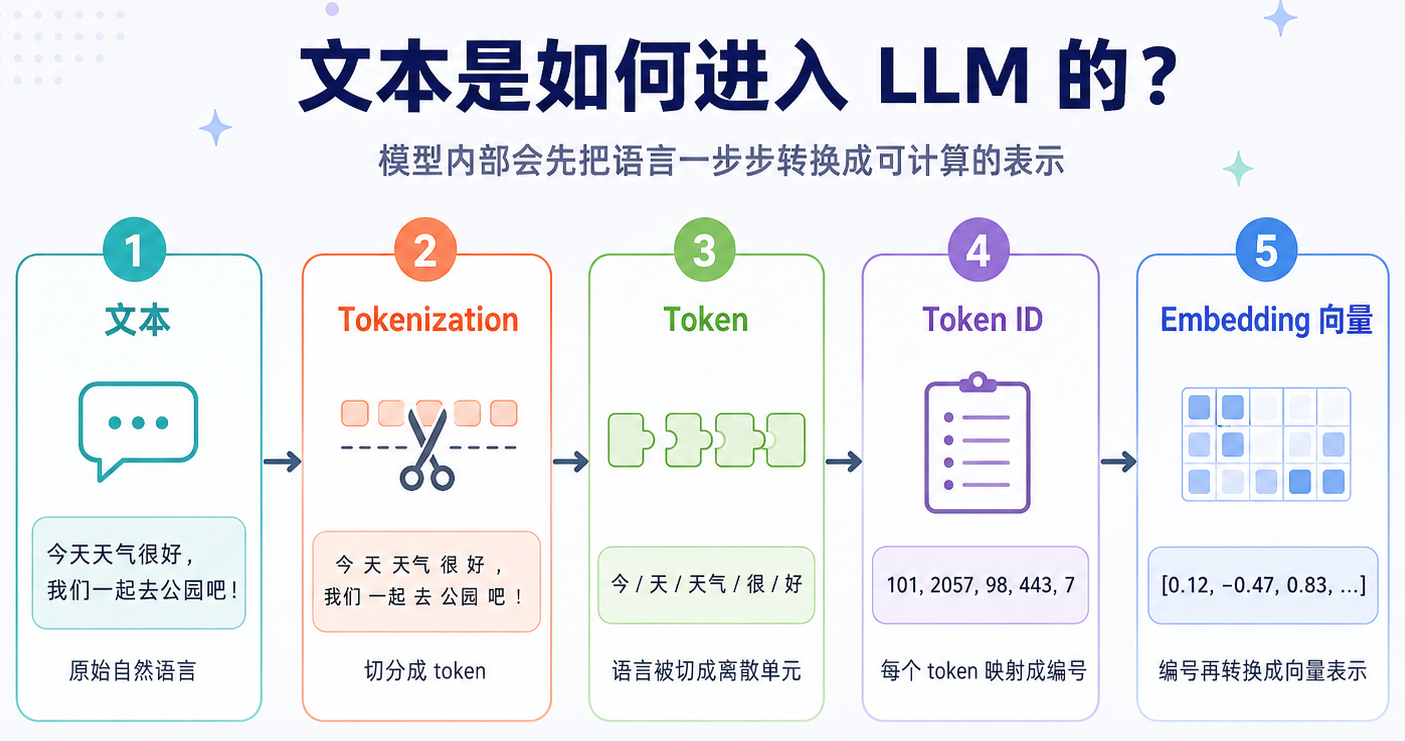
Token 是 LLM 处理语言的基本单位,文本必须先被切成 token,才能继续变成向量并进入模型计算(后面我们讲 embedding、向量空间、Attention、预测下一个 token,都是建立在 token 这个基本单位之上的)。
语言的表示:从 token 到向量空间
计算机并不真正认识“猫”“狗”“咖啡”这些词。对机器来说,它们必须先变成数字,才能参与计算。在线性代数里,最常见的四个对象是:
| 对象 | 直觉 | 在 LLM 里的样子 |
|---|---|---|
| 标量 | 一个数字,比如 loss = 2.13 | loss |
| 向量 | 一串数字,一个语义坐标 | 一个 token 的 embedding |
| 矩阵 | 一张数字表,一次表示变换 | 一层权重、Q/K/V 变换 |
| 张量 | 更高维的数字容器 | batch、序列、hidden state |
这里也用一张图来理解它们的样式:
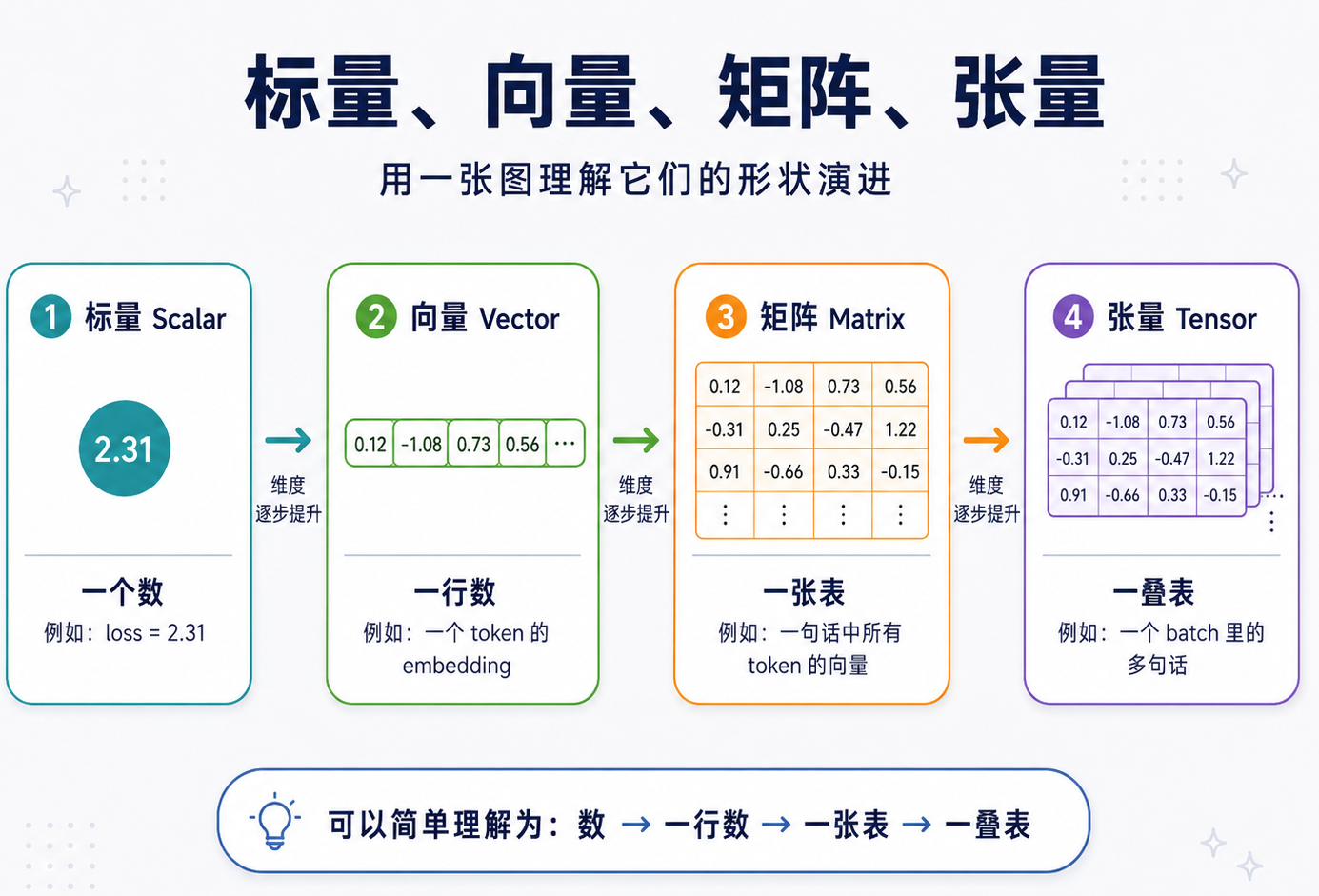
也就是说,LLM 里大多数计算,本质上不是在处理“文字”,而是在处理这些数字结构。
当然只有 token embedding 还不够,Transformer 还需要位置表示,让模型知道 token 在句子中的顺序,否则“我喜欢你”和“你喜欢我”在词集合上很像,但语义完全不同(这部分会在下一篇文章中介绍)。
为什么语言要变成向量?
最朴素的方式,是给每个词一个编号,或者使用 one-hot 表示(one-hot 是一种把“类别”表示成向量的方法)。例如:
| 词 | one-hot 表示 |
|---|---|
| 猫 | [1, 0, 0, 0] |
| 狗 | [0, 1, 0, 0] |
| 桌子 | [0, 0, 1, 0] |
| 咖啡 | [0, 0, 0, 1] |
这种方式简单,但有几个明显问题:
- 太稀疏:词表很大时,每个向量都非常长;
- 没有语义距离:“猫”和“狗”看起来跟“猫”和“桌子”一样远;
- 不适合泛化:模型很难知道哪些词意思接近。
而 Embedding 的思路是:不再用一堆 0 和 1 表示词,而是给每个 token 一个稠密向量。例如:
| token | embedding 示例 |
|---|---|
| 猫 | [0.21, -0.13, 0.88, …] |
| 狗 | [0.24, -0.10, 0.82, …] |
| 桌子 | [-0.57, 0.62, 0.09, …] |
这些数字不是人工写死的,而是在训练过程中学出来的。它们的目标是让语义相近的词,在向量空间里也更接近。
向量:语义的坐标
可以把 embedding 想成一个语义地图:
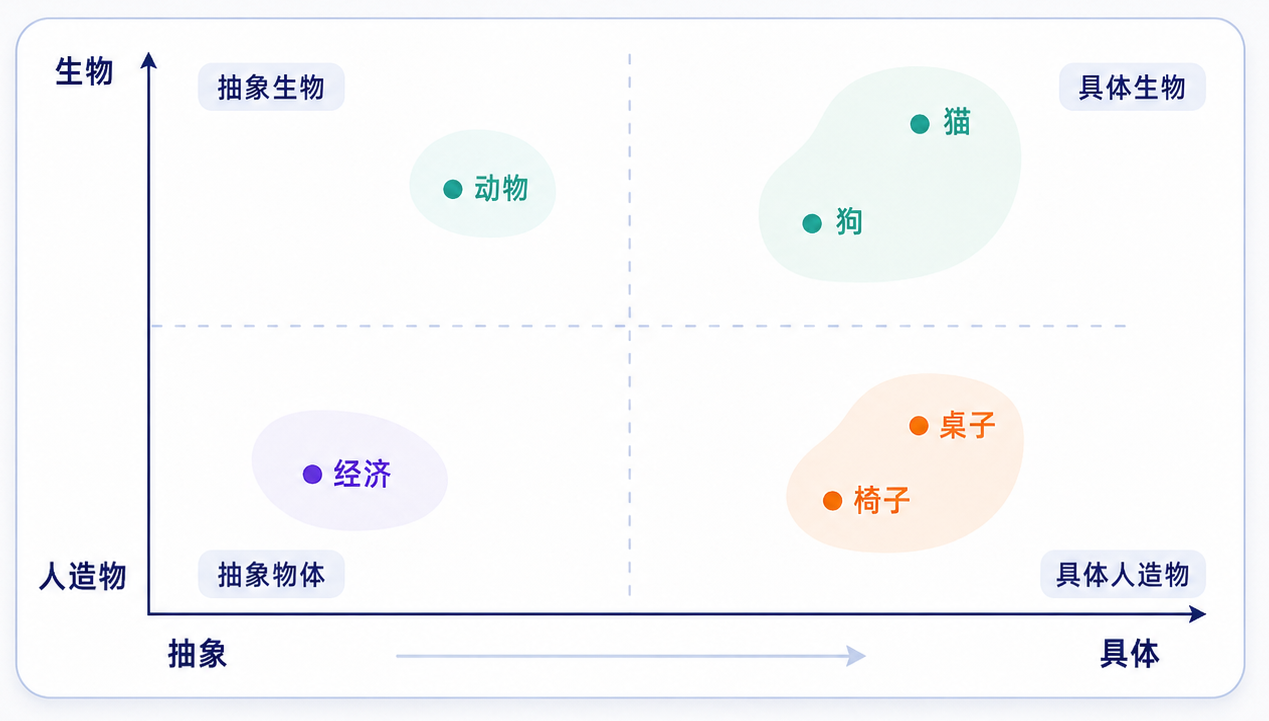
真实 embedding 当然不是二维,而可能是几百、几千甚至更高维。但直觉类似:语义相近的 token,向量位置也更接近。
向量化之后,很多语言的问题也变成了数学问题:
- “猫”和“狗”是不是更接近? –> 两个向量距离是否更近?
- “苹果”在句子里是什么意思? –> 上下文向量落在哪个语义区域?
- 一段文档和问题是否相关? –> 文档向量和问题向量相似度多高?
矩阵:表示变换器
向量表示一个对象,矩阵表示一种变换。在 Transformer 里,很多操作都可以理解成:
1 | 新表示 = 旧表示 × 参数矩阵 |
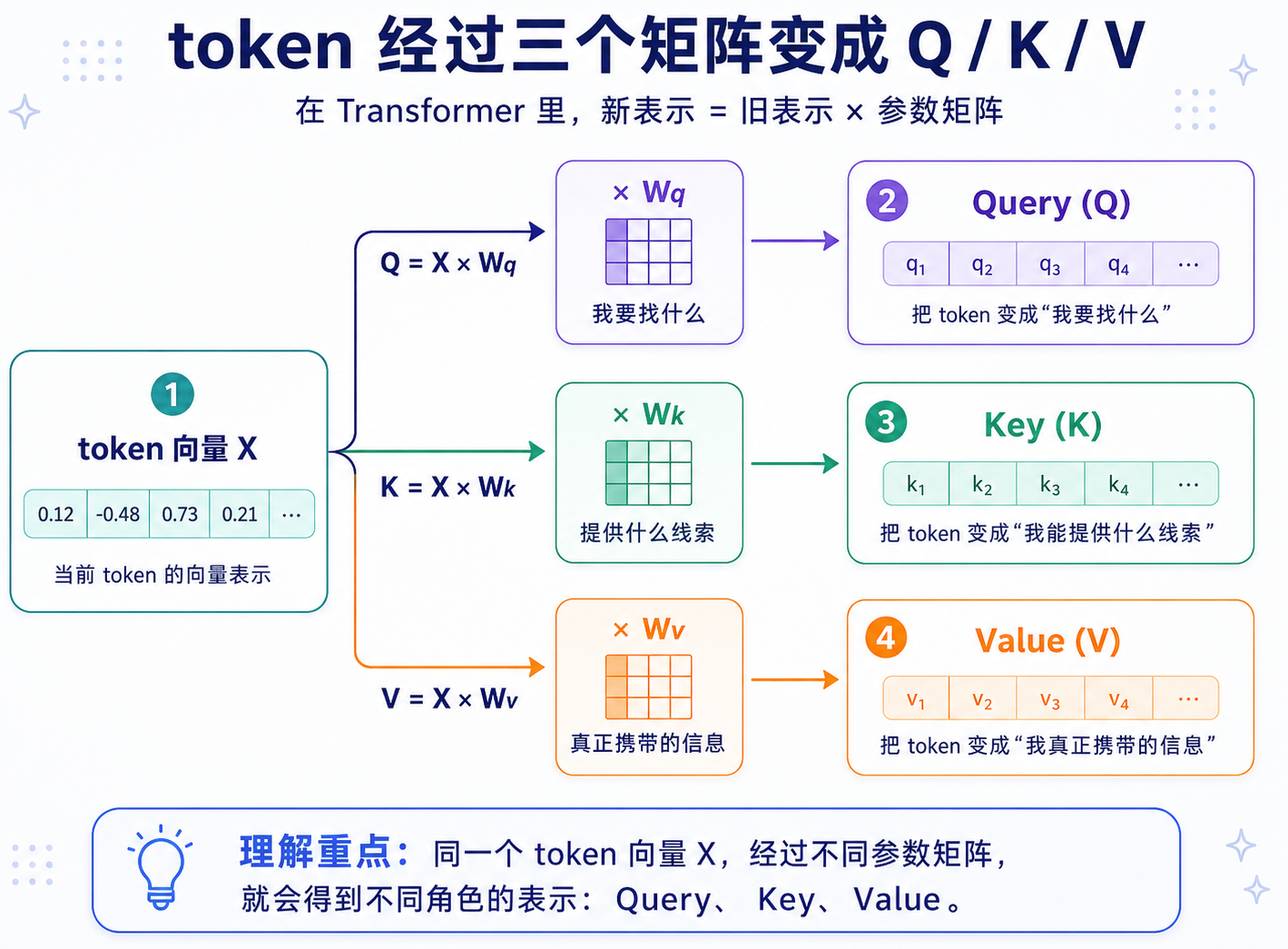
Transformer 中的 Wq/Wk/Wv 是参数矩阵,Q/K/V是 token 向量经过这些矩阵线性投影后得到的表示:
| 符号 | 可以怎么理解 |
|---|---|
X |
当前 token 的向量表示 |
Wq |
把 token 变成“我要找什么”的矩阵 |
Wk |
把 token 变成“我能提供什么线索”的矩阵 |
Wv |
把 token 变成“我真正携带的信息”的矩阵 |
这里可以记住一句话:矩阵是 LLM 里最常见的“表示变换器”。
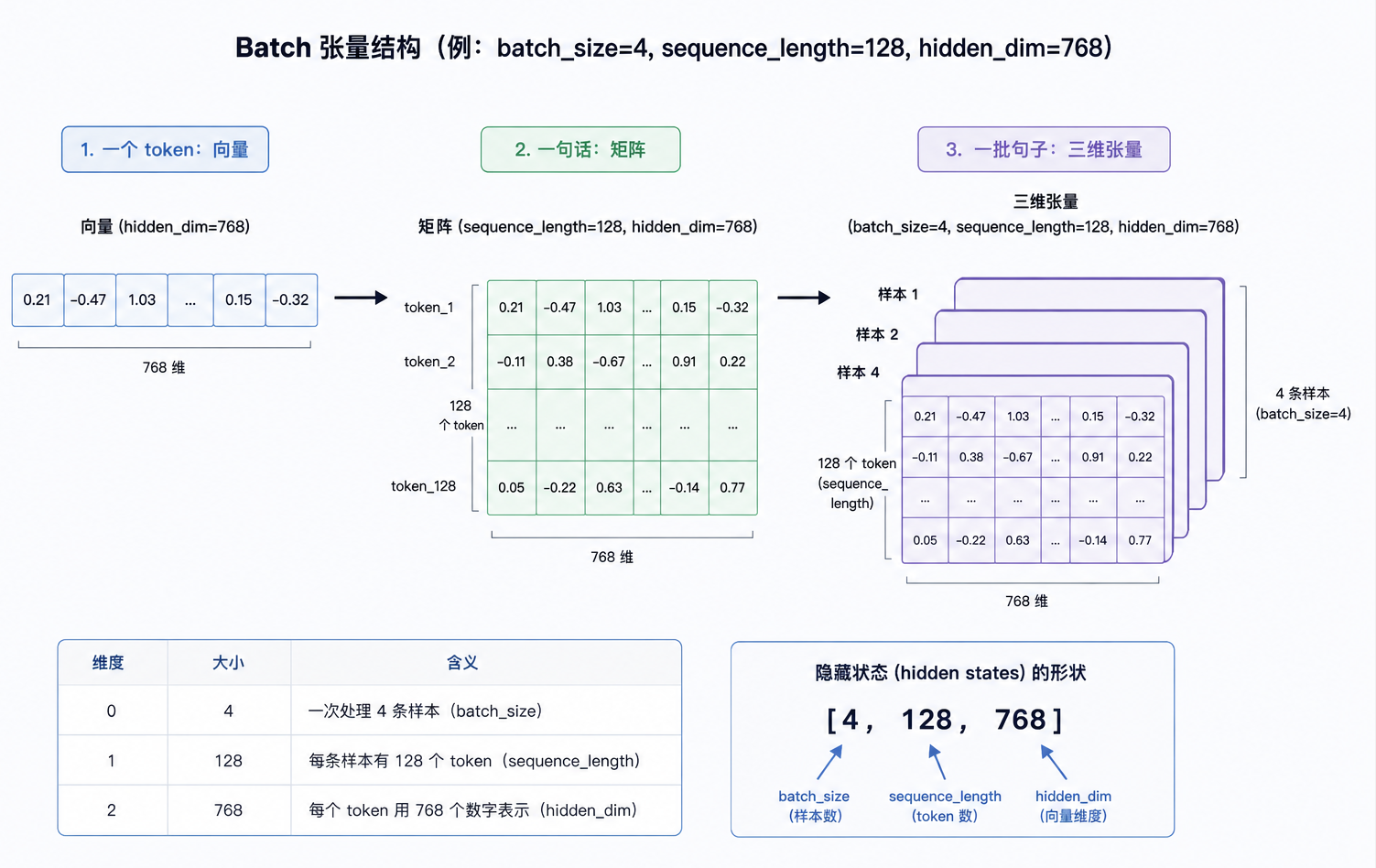
张量:把一批句子组织起来
当我们只看一个 token,它是向量。当我们看一句话,它是矩阵。当我们一次处理多句话,它就变成了张量。下面举个例子:
1 | batch_size = 4 |
可以理解为:一次处理 4 句话、每句话 128 个 token、每个 token 用 768 维向量表示。如下图所示:
关系的计算:从相似度到 Attention
相似度:模型怎么判断“像不像”
当词变成向量之后,模型就可以计算它们之间的关系。常见的相似度计算方式有:
| 方法 | 基本原理 | 常见位置 | 适合场景 |
|---|---|---|---|
| 点积 | 将两个向量对应维度相乘后求和。 两个向量方向越一致、数值越大,分数越高 |
Attention score | 适合在模型内部快速计算相关性,尤其是 Q 和 K 的匹配 |
| 余弦相似度 | 计算两个向量夹角的余弦值,重点看方向是否接近。 不太关心向量长度,更关心“语义方向”是否一致 |
向量检索、RAG、语义搜索 | 适合比较文本、问题、文档之间的语义相似度 |
| 欧氏距离 | 计算两个点在空间中的直线距离。 两个点离得越近,表示越相似 |
聚类、传统机器学习、部分向量检索场景 | 适合空间距离有明确意义的场景,但在高维语义向量中不一定总是最优 |
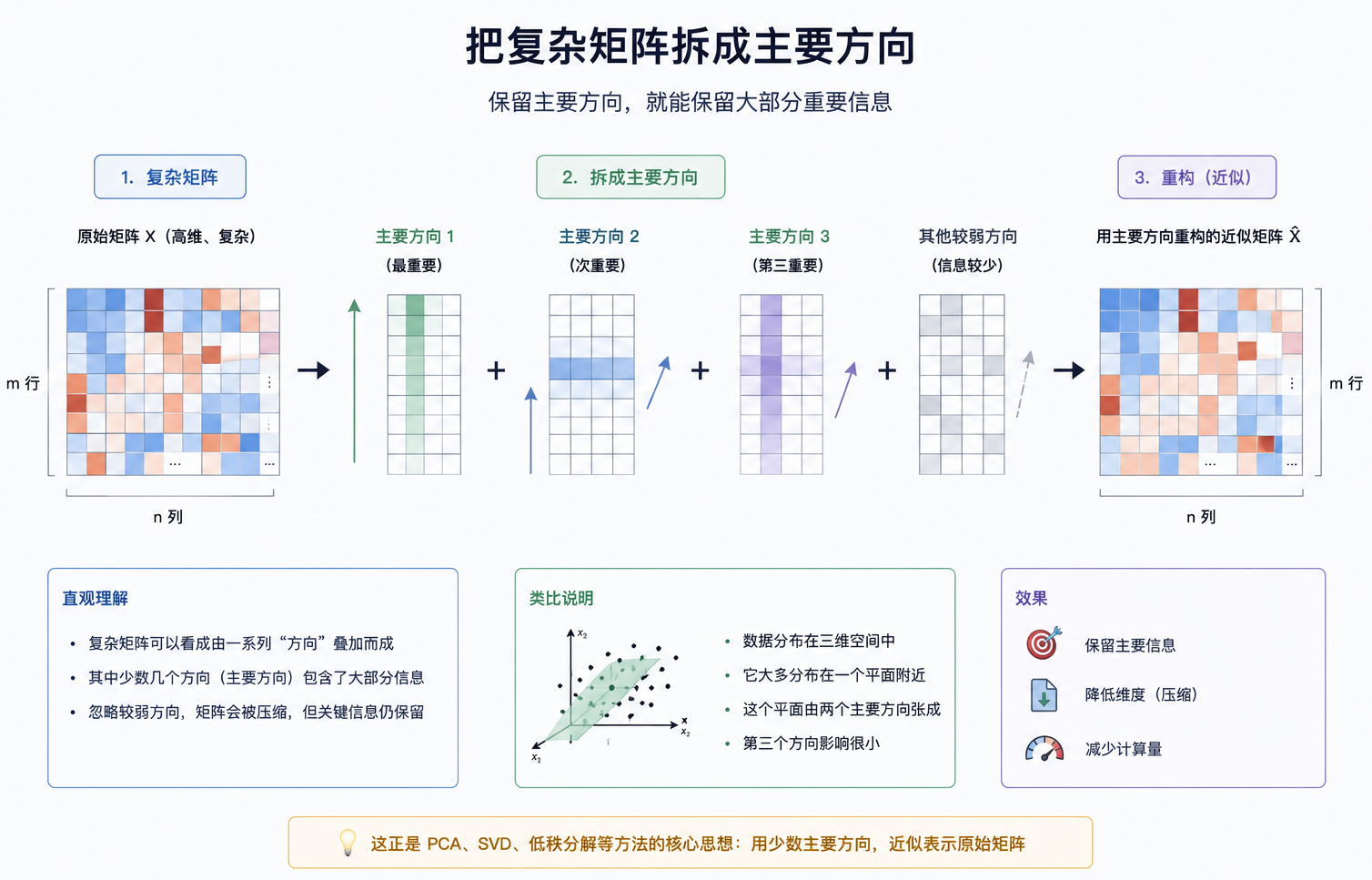
SVD、低秩:复杂矩阵里的主要方向
对于一个复杂矩阵里,往往不是每个方向都同等重要,有些方向承载了主要信息,有些方向只是细节或噪声。SVD(奇异值分解) 是分析矩阵结构的一种分解方法,低秩近似是用少量主要方向表达矩阵信息的思想;它们常用来理解降维、压缩和 LoRA 背后的数学直觉。
| 概念 | 基本原理 | 和 LLM 的关系 | 常见应用 |
|---|---|---|---|
| SVD | 将一个矩阵分解成几个更简单的矩阵,拆出其中最重要的方向和强度(把复杂矩阵拆成几个主要方向) | 帮助理解降维、压缩、低秩近似 | 模型压缩、降维、矩阵分析、理解 LoRA 的数学基础 |
| 低秩 | 如果一个矩阵的大部分信息可以由少数几个方向表达,就可以用更小的矩阵近似它(用更少参数表达主要变化) | LoRA 利用低秩矩阵近似参数更新,不必完整微调整个大矩阵 | LoRA、参数高效微调、模型压缩 |
关系的计算:相似度与 Attention
线性代数让 token 有了向量。接下来,模型要回答两个更关键的问题:
- 当前 token 应该从上下文里看哪些 token?
- 每个 token 应该贡献多少信息?
这里举个例子,有一句话:小明把书放进书包,因为它太重了。
- 这里的“它”指的是“书”,还是“书包”?
人类会根据语义判断。模型也需要计算:当前 token 应该重点关注上下文中的哪些 token。
这件事可以拆成三个动作:
| 动作 | 数学形式 | 作用 | |
|---|---|---|---|
| 算相关性 | 点积 | 判断两个 token 是否匹配 | |
| 分配权重 | Softmax | 把相关性分数变成注意力比例 | 让重要 token 贡献更多 |
放回刚才的句子,可以这样理解:
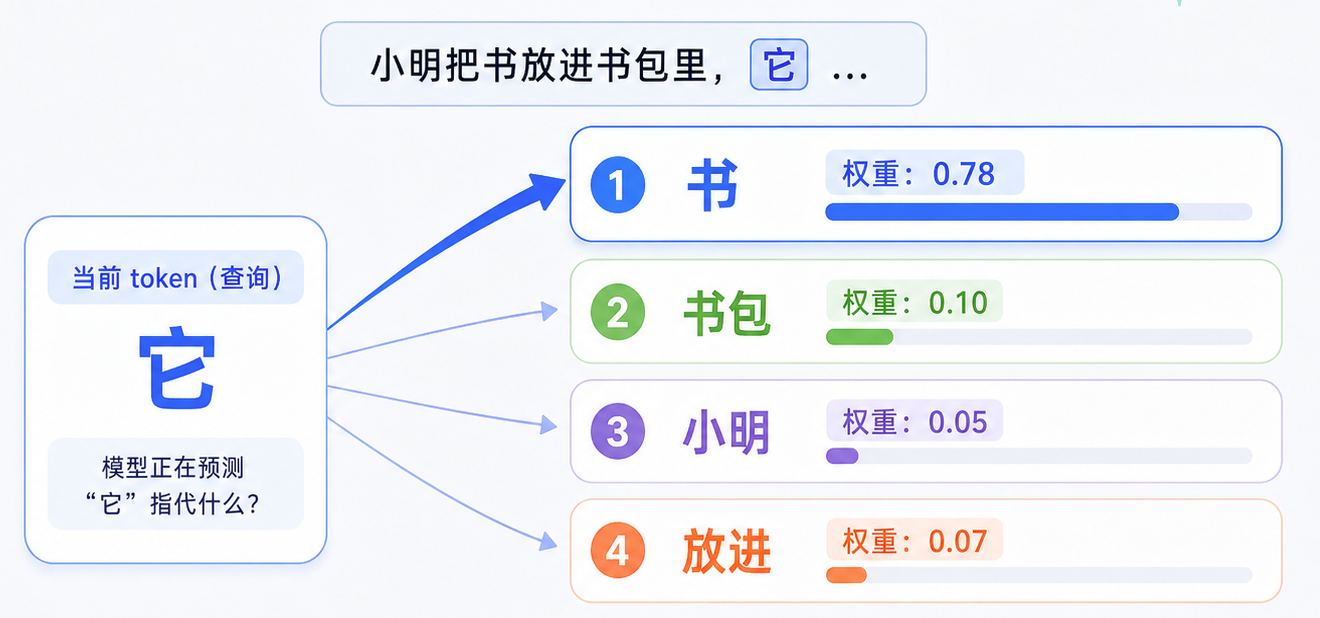
这不是说模型一定永远这样判断,而是展示 Attention 权重的阅读方式:权重越高,当前 token 从那里拿到的信息越多。
什么是 Attention(注意力机制)
继续用上面的示例:小明把书放进书包,因为它太重了。
当人类理解“它”时,会自然回头看前面的词,并判断“它”更可能指向“书”,而不是“小明”或“放进”。这说明,一个词的含义往往不是孤立决定的,而是由上下文共同决定的。
如何解决这个问题呢?
- 2014 年,Dzmitry Bahdanau、Kyunghyun Cho、Yoshua Bengio 在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中提出了 Attention 机制,用来解决机器翻译中长句被压缩成单一向量后信息丢失、词语对齐困难的问题。
- 后来,Vaswani 等人在 2017 年的论文《Attention Is All You Need》中进一步将 Attention 发展为 Transformer 的核心结构,在 Transformer 中采用并系统化了 Q/K/V 形式的 scaled dot-product attention,让模型能够判断:当前 token 想找什么信息,哪些 token 与它相关,以及最终应该读取哪些内容。
Attention 的核心思想简单来说,就是让模型在处理某个 token 时,能够动态地判断上下文中哪些 token 更重要,并给它们分配不同的权重。
后续会有一篇文章,专门来分析这篇跨时代意义的论文 —— transformer,这里读者简单了解其中使用到的数学理论即可。
Q、K、V:同一个向量的三种线性投影
在 Transformer 中,每个 token 进入模型后,都会先变成一个向量。然后模型会用三个不同的矩阵,把这个向量变换成三种不同的表示:
| 名称 | 数学含义 | 直觉理解 |
|---|---|---|
| Q(Query) | 当前 token 的查询向量 | 我想找什么信息 |
| K(Key) | 其他 token 的匹配向量 | 我这里有什么特征可以被匹配 |
| V(Value) | 其他 token 的内容向量 | 如果被关注,真正传递什么信息 |
从数学上看,Q、K、V 本质上都是矩阵乘法(Transformer 内部的机制这里先不做过多赘述,简单有一个了解即可,重点关注背后的数学原理)。
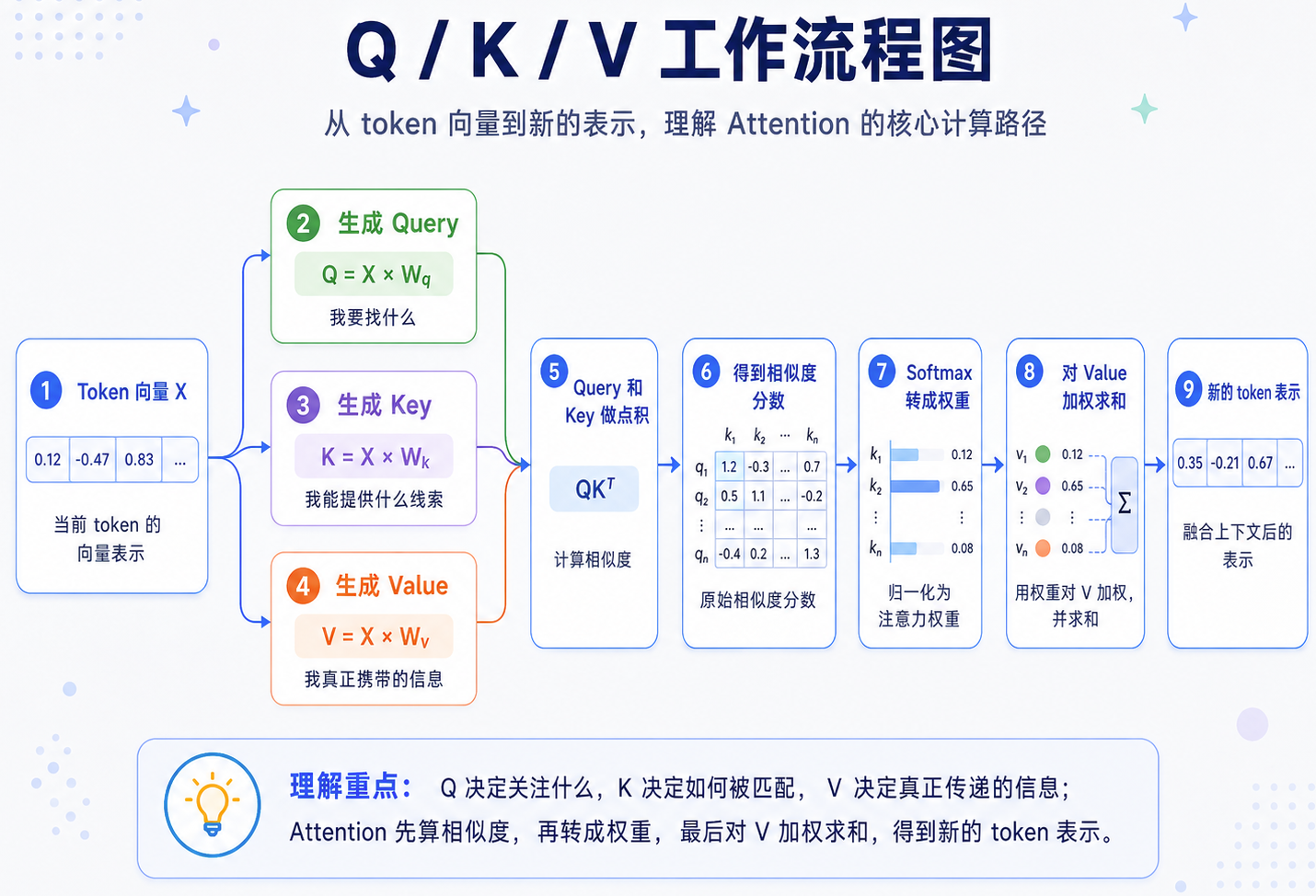
Softmax:把分数变成权重
在 Transformer 中,用 Q 和 K 计算完相关性后,会得到一组分数。比如当前 token 在看其他 token 时,可能得到这样的分数:
| token | 分数 |
|---|---|
| 我 | 1.2 |
| 喜欢 | 2.5 |
| 咖啡 | 0.8 |
这些分数本身还不能直接当作“关注比例”,因为它们可能很大、很小,甚至可能是负数。Softmax 的作用,就是把这些分数转换成一组更好理解的权重(不过 Softmax 不是简单线性归一化,它会先对分数做指数变换,再归一化,因此会放大高分项的优势):
| token | 原始分数 | Softmax 后的权重 |
|---|---|---|
| 我 | 1.2 | 0.18 |
| 喜欢 | 2.5 | 0.66 |
| 咖啡 | 0.8 | 0.16 |
Softmax 有两个重要特点:
- 所有权重都是正数: 不会出现负的关注比例;
- 所有权重加起来等于 1: 可以理解成一组分配比例。
所以,Softmax 背后的数学概念很简单:它把一组“相关性分数”,转换成一组“信息分配权重”。
预测与评估:概率、Softmax 与交叉熵
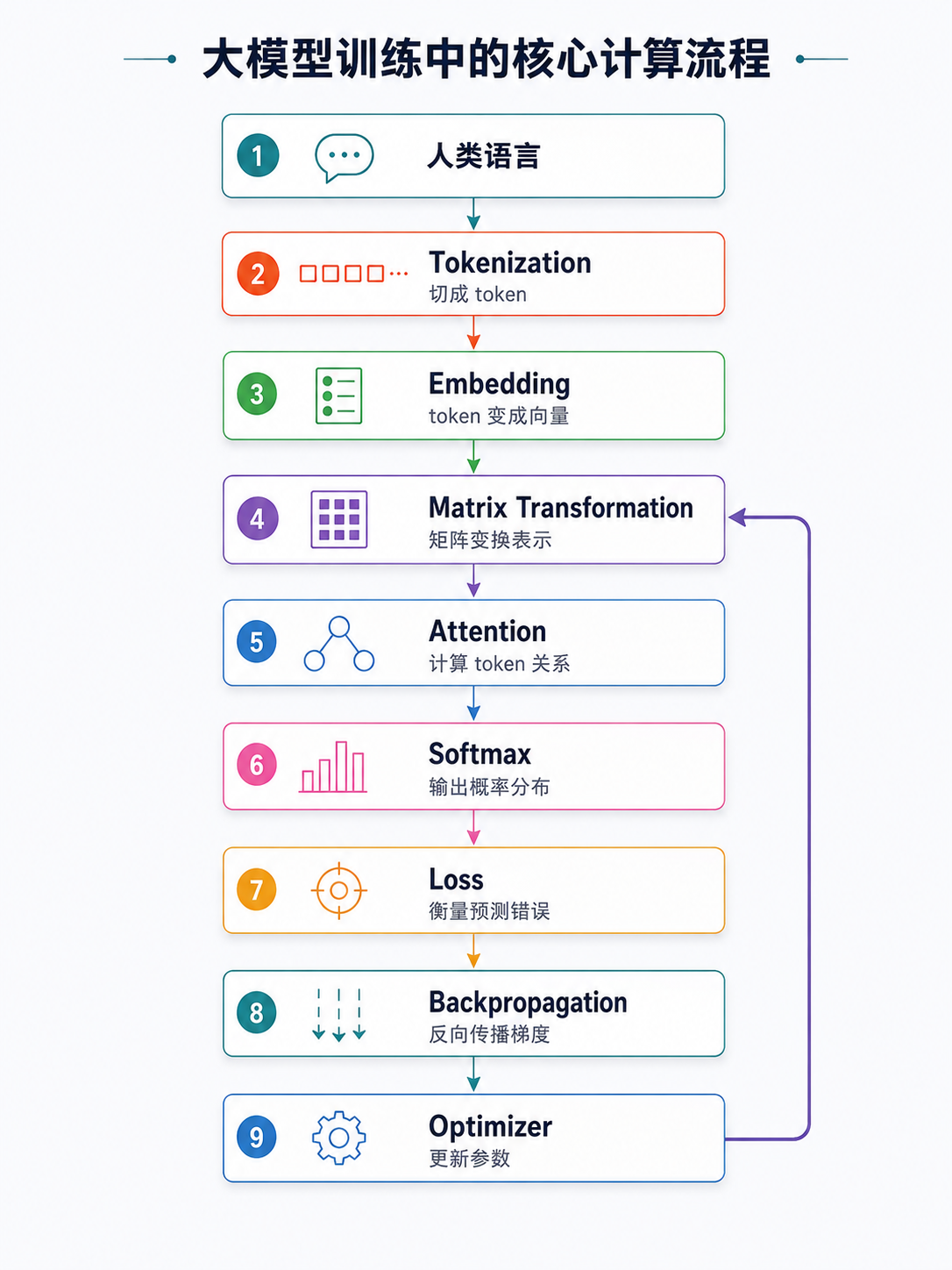
前面我们讲了:语言会先变成 token,再变成向量,模型通过矩阵乘法、相似度、Attention 等方式计算上下文关系。但计算完关系之后,模型最终还是要回答一个非常具体的问题:在当前上下文后面,下一个 token 最可能是什么?
可以先看一张总图:
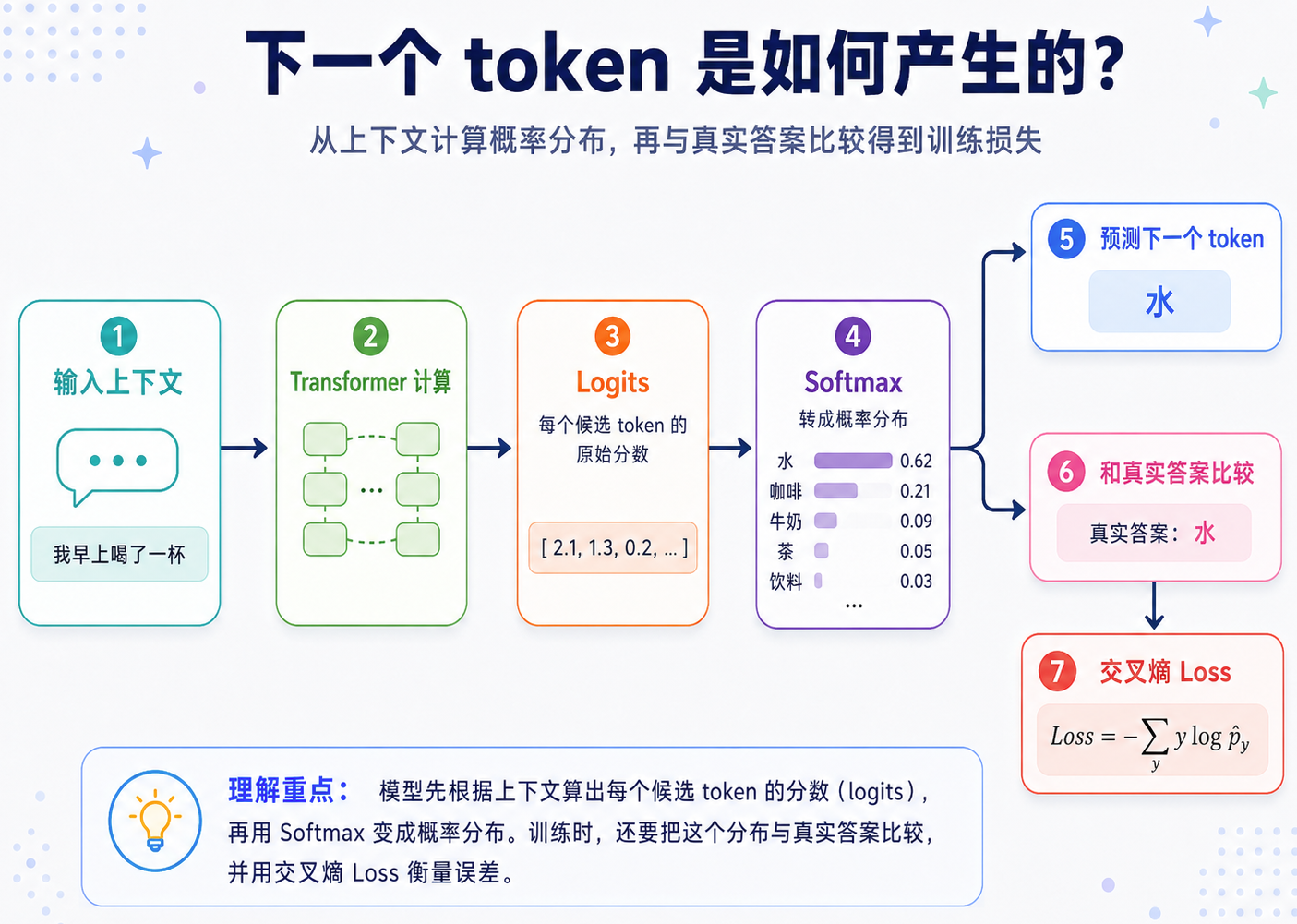
在本章节中,重点会介绍的数学概念,及 LLM 中的应用如下:
| 问题 | 数学概念 |
|---|---|
| 下一个词是什么? | 条件概率 |
| 分数怎么变成概率? | Softmax |
| 结果为什么有时稳定、有时发散? | 期望、方差 |
| 新信息为什么会改变回答? | 贝叶斯思想 |
| 怎么知道模型错了多少? | 交叉熵 |
LLM 输出的是概率分布
LLM 每一步生成时,不是直接从数据库里取一个答案,而是在预测下一个 token 的概率分布。当我们输入:
1 | 我早上喝了一杯 |
模型并不是从数据库里查找“下一句话应该是什么”,而是在所有可能 token 里预测概率。例如:
| 候选 token | 模型预测概率 | 直觉理解 |
|---|---|---|
| 咖啡 | 0.62 | 最可能 |
| 水 | 0.18 | 也合理 |
| 茶 | 0.11 | 有可能 |
| 牛奶 | 0.06 | 概率较低 |
| 其他 | 0.03 | 很多低概率 token 的合计 |
所以,LLM 生成文本的基本单位不是“一句话”,而是“一步一步预测下一个 token”。
| 我们看到的现象 | 背后的数学解释 |
|---|---|
| 模型可以继续写文章 | 每一步都在预测下一个 token |
| 同一个问题可能生成不同回答 | 采样来自概率分布 |
| 有些回答更稳定,有些回答更发散 | 概率分布有时集中,有时分散 |
| temperature 可以控制创造性 | 改变概率分布的尖锐程度 |
条件概率:上下文决定下一个 token
语言模型真正学习的是:
1 | P(下一个 token | 前面的上下文) |
这句话读起来像公式(也就是条件概率,在上下文确定的前提下,下一个 token 出现的概率),但意思很简单:在已经看到这些文字的前提下,下一个词最可能是什么?
同一个词,在不同上下文里的概率会完全不同。
| 上下文 | 更可能的下一个 token |
|---|---|
| 我早上喝了一杯 | 咖啡、水、牛奶 |
| 程序抛出了一个 | 异常、错误 |
| 请把这段代码转换成 | Python、Java、SQL |
| 今天天气非常 | 好、热、冷 |
这也是为什么 prompt 很重要。
prompt 本质上是在改变上下文,而上下文会改变后续 token 的概率分布。
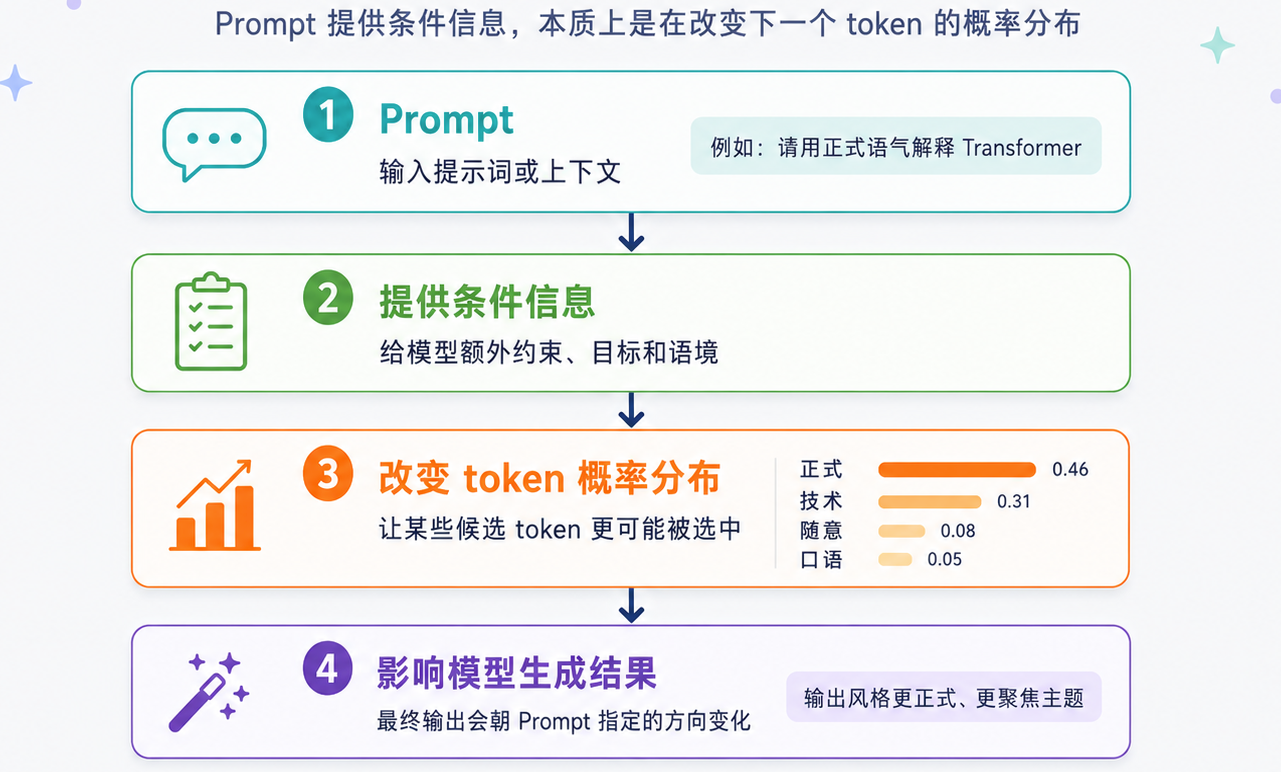
举个例子:
| Prompt | “苹果”更可能表示什么 |
|---|---|
| 我削了一个苹果 | 水果 |
| 苹果发布了新品 | 公司 |
| 苹果股价上涨 | 公司 |
| 这个苹果很甜 | 水果 |
模型并不是先“理解苹果的唯一含义”,而是根据上下文让某些含义的概率升高。
期望、方差和不确定性:为什么有的回答稳定,有的回答发散
概率分布不只是告诉我们“谁最大”,还告诉我们模型有多确定。这里可以简单理解三个概念:
| 概念 | 原理 | 在 LLM 里的表现 |
|---|---|---|
| 期望 | 对所有可能结果按概率加权平均,表示模型预测的中心趋势 | 模型大概率会往哪个方向回答 |
| 方差 | 衡量结果相对期望的分散程度,方差越大,输出越不稳定 | 回答是否稳定 |
| 不确定性 | 当多个 token 或答案路径的概率都接近时,模型难以唯一确定最优选择 | 模型可能生成不同答案 |
比如一个确定性问题:
1 | 2 + 2 = ? |
| token | 概率 |
|---|---|
| 4 | 0.96 |
| 3 | 0.01 |
| 5 | 0.01 |
| 其他 | 0.02 |
这个分布很集中,模型回答通常稳定。
再看一个开放问题:
1 | 请给我一个创业方向 |
| token | 概率 |
|---|---|
| AI | 0.22 |
| 教育 | 0.18 |
| 工具 | 0.15 |
| 内容 | 0.12 |
| 其他 | 0.33 |
这个分布更分散,所以模型可能给出不同答案。
| 分布形状 | 直觉 | 常见场景 |
|---|---|---|
| 很集中 | 模型很确定 | 数学题、事实题、格式明确的问题 |
| 比较分散 | 多个答案都合理 | 创意写作、方案建议、开放讨论 |
| 过于分散 | 模型方向不清楚 | prompt 太模糊、约束太少 |
所以 temperature、top-k、top-p 这些生成参数,本质上都是在控制如何从概率分布中选择下一个 token。
贝叶斯思想:新信息会改变模型判断
贝叶斯思想可以简单理解为一句话:我们不是一次性判断真相,而是根据新证据不断更新自己的判断。
贝叶斯可以用一句话理解:看到新证据后,应该更新原来的判断。而在 LLM 里,prompt 就是类似一种“新证据”会改变后续的模型输出。比如“苹果”这个词,本身有多种含义:
| 新上下文 | 模型更可能的判断 |
|---|---|
| 我削了一个苹果 | 苹果是水果 |
| 苹果发布了新品 | 苹果是公司 |
| 苹果股价上涨 | 苹果是公司 |
| 这个苹果很甜 | 苹果是水果 |
这不是模型在查字典,而是上下文改变了不同含义的概率。
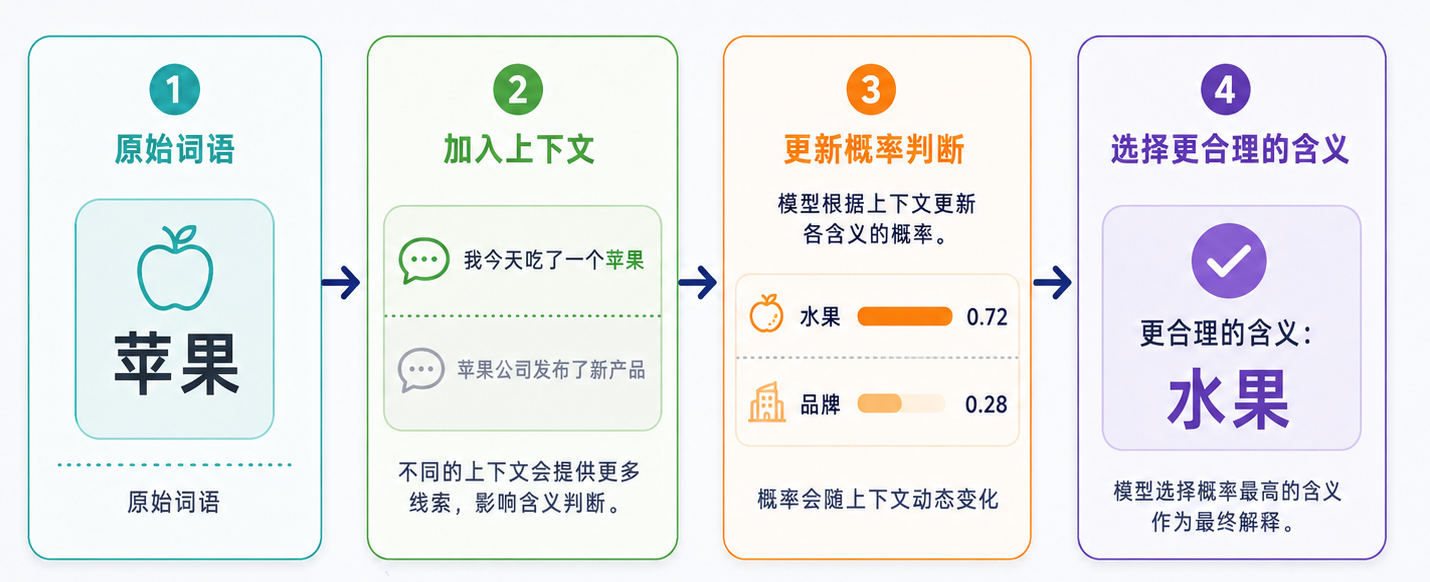
所以,贝叶斯思想对理解 LLM 很有帮助:模型不是一次性固定答案,而是在不断根据上下文更新“接下来什么更可能”。
交叉熵与最大似然:怎么衡量模型预测得好不好
有了概率之后,训练还需要回答另一个问题:模型这次预测,到底错了多少?假设真实答案是“咖啡”,模型给出下面的概率:
| token | 预测概率 |
|---|---|
| 水 | 0.5 |
| 咖啡 | 0.2 |
| 茶 | 0.2 |
| 牛奶 | 0.1 |
人能看出来:模型不太对,因为正确答案“咖啡”的概率只有 0.20。但机器需要一个数字来表示错误程度,这个数字就是 loss(交叉熵就是一种常见的损失函数)。
语言模型常用的 loss 是交叉熵。对单个 token 来说,可以先这样理解:
- 正确 token 的概率越高,loss 越小;
- 正确 token 的概率越低,loss 越大。
| 真实 token | 模型给真实 token 的概率 | loss 直觉 |
|---|---|---|
| 咖啡 | 0.9 | 很小 |
| 咖啡 | 0.6 | 较小 |
| 咖啡 | 0.2 | 较大 |
| 咖啡 | 0.01 | 非常大 |
交叉熵不只是看“有没有猜中”,还看模型是不是把足够多的概率分给了正确答案。
| 预测情况 | 惩罚 |
|---|---|
| 答对且很自信 | 很小 |
| 答对但不自信 | 中等 |
| 答错但不自信 | 较大 |
| 答错还很自信 | 很大 |
从另一个角度看,训练语言模型就是最大似然:让训练语料里的句子,在模型看来越来越“可能出现”。
| LLM 说法 | 数学术语 | 数学原理 |
|---|---|---|
| 让模型更像训练数据那样说话 | 最大似然 | 模型会计算一段训练文本出现的概率,并不断调整参数,让训练数据中的句子在模型看来“更可能出现”。 |
| 让正确 token 概率更高 | 最小化交叉熵 | 交叉熵关注真实 token 被分到的概率。如果正确 token 概率越高,loss 越小;如果正确 token 概率很低,loss 就会变大。 |
| 让预测错误变少 | 最小化 loss | loss 是所有训练样本预测误差的汇总指标,训练通过反向传播和优化器让平均 loss 下降 |
LLM 的生成,是不断根据上下文预测下一个 token 的概率;LLM 的训练,是不断让正确 token 的概率变高,让交叉熵 loss 变低。
学习与优化:模型如何从错误中变好
前面讲到,交叉熵会把模型预测错误变成一个数字:loss。但模型不能只知道“我错了”,还必须知道:
| 问题 | 数学概念 |
|---|---|
| 错误怎么表示成目标? | 目标函数、损失函数 |
| 参数该往哪里改? | 导数、偏导数、梯度 |
| 错误怎么传回前面层? | 链式法则、反向传播 |
| 参数怎么一步步更新? | 梯度下降、优化器 |
| 怎么避免训练不稳定? | 正则化、凸优化思想、约束优化 |
损失函数:把“模型错了”变成数学目标
训练 LLM,本质上是在最小化一个函数:
1 | Loss = 模型预测结果 和 真实答案之间的差距 |
更数学一点,可以写成:
1 | min L(θ) |
这里:
| 符号 | 含义 |
|---|---|
| θ | 模型里的所有参数 |
| L(θ) | 当前参数下的 loss |
| min | 希望找到一组参数,让 loss 尽可能小 |
在语言模型里,常见目标是:
1 | 让真实下一个 token 的概率尽可能高 |
所以训练目标可以理解为:
1 | 最小化交叉熵(Loss) = 最大化训练文本出现的概率 |
到这里的话,一个“模型表现好不好”,被定义成一个可以计算、可以优化的函数。
导数、偏导数、梯度:找到参数应该怎么改
LLM 有大量参数,训练时要回答一个问题:
1 | 如果某个参数稍微变大一点,loss 会变大还是变小? |
这就是导数要解决的问题。
| 概念 | 数学原理 | 在 LLM 中的作用 |
|---|---|---|
| 导数 | 衡量一个变量变化时,函数如何变化 | 看参数变化会不会影响 loss |
| 偏导数 | 多个变量中,只看其中一个变量的影响。 | 看某个参数对 loss 的影响 |
| 梯度 | 所有偏导数组成的向量 | 给出整体参数更新方向 |
这三个数学概念,简单举个例子:
| 概念 | 计算方式示例 | 含义 |
|---|---|---|
| 导数 | 如果 f(x) = x²,那么 f'(x) = 2x |
当 x 变化一点时,f(x) 会怎么变 |
| 偏导数 | 如果 L(w, b) = (wx + b - y)²,分别求 ∂L/∂w 和 ∂L/∂b |
只看 w 或 b 单独变化时,对 loss 的影响 |
| 梯度 | ∇L = [∂L/∂w, ∂L/∂b] |
把所有参数对 loss 的影响组合起来 |
这里最重要的数学结论是:
| 方向 | 含义 |
|---|---|
| 梯度方向 | loss 上升最快的方向 |
| 负梯度方向 | loss 下降最快的方向 |
所以训练经常有句话:loss 告诉模型“错了多少”,梯度告诉模型“往哪里改”。
反向传播:用链式法则把错误传回每一层
反向传播是 Transformer 能够被大规模训练的关键机制之一。如果没有反向传播,模型即使知道最后预测错了,也很难判断前面每一层、每一个参数应该承担多少责任,更谈不上在工业界进行大规模训练和优化。
我们知道,Transformer 由多层神经网络结构组成。从 Embedding 层,到多层 Attention 和 Feed Forward,再到最终输出层,信息是一步步向前计算的。那么问题来了:如果最后一层输出错了,loss 很大,模型应该如何把这个错误传回前面的层,并据此修改每一层的参数呢?
这就是反向传播解决的问题,而反向传播背后的数学原理就是链式法则。
简单写成:
1 | 如果 L 依赖 y,y 又依赖 x, |
放到神经网络里反向传播的路径是 Loss → 输出层 → 中间层 → Embedding 层,如下图所示:
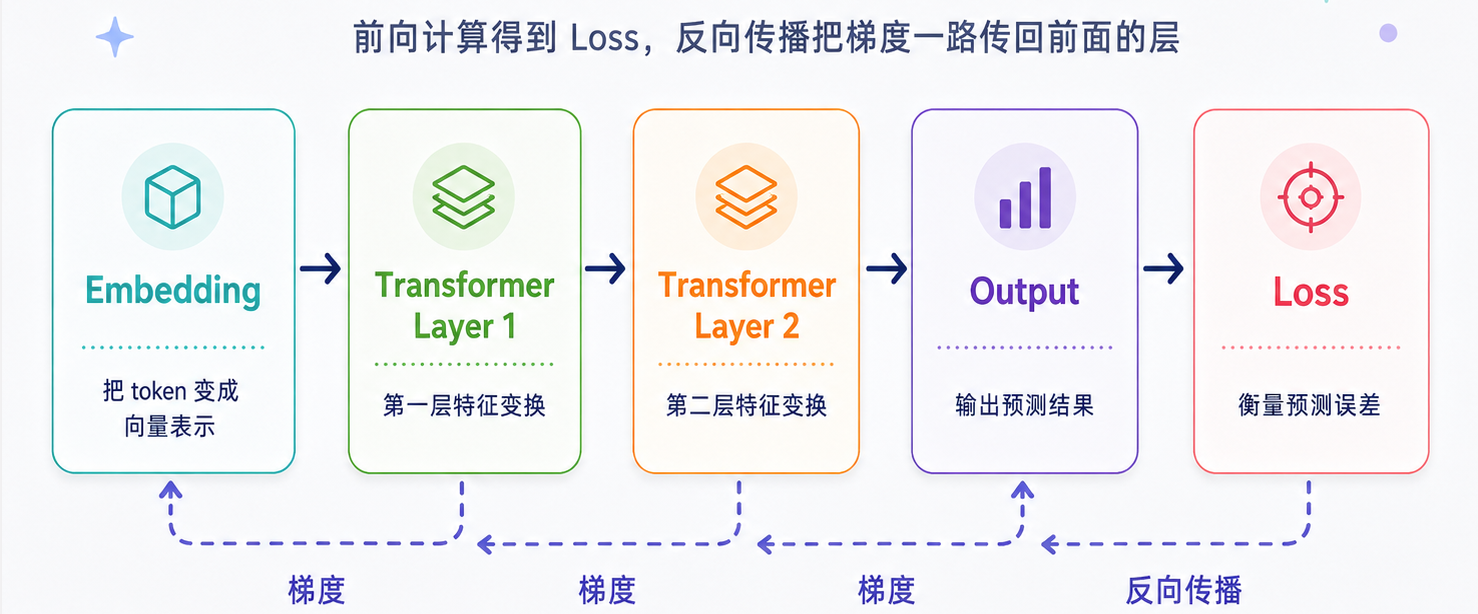
| 问题 | 反向传播怎么回答 |
|---|---|
| 最后错了多少? | 计算 loss |
| 哪一层影响了错误? | 计算该层输出对 loss 的影响 |
| 哪个参数该改? | 计算参数梯度 |
| 改多少? | 梯度大小和学习率共同决定 |
一句话理解:反向传播不是新的数学魔法,而是链式法则在神经网络里的工程实现。
梯度下降与优化器:让 loss 一步步变小
有了梯度,就可以更新参数。最基础的更新公式是:
1 | θ_new = θ_old - η × ∇L(θ) |
这里:
| 符号 | 含义 | LLM 中的含义 |
|---|---|---|
| θ_old | 当前参数 | 当前模型里的所有权重参数,比如 Embedding、Attention、FFN 里的矩阵参数 |
| θ_new | 更新后的参数 | 经过一次训练 step 后的新模型参数 |
| η | 学习率 | 每次参数更新的步长 |
| ∇L(θ) | 当前梯度 | 当前 batch 数据中,每个参数对 loss 的影响方向和大小 |
| -∇L(θ) | loss 下降方向 | 让 loss 下降最快的方向 |
这就是梯度下降。
真实 LLM 训练里,通常不会只用最朴素的梯度下降,而会用更复杂的优化器,例如 Adam。
| 优化方法 | 数学思想 | 直觉理解 |
|---|---|---|
| SGD | 按当前梯度更新参数 | 每次看当前坡度走一步 |
| Momentum | 累积历史梯度方向 | 不只看当前一步,也看惯性 |
| Adam | 同时估计梯度均值和梯度波动 | 给不同参数自适应调整步长 |
这一小节重点是:优化器决定怎么用梯度更新参数,学习率决定每一步走多大。
训练稳定性:正则化、凸优化与约束思想
真实训练中,loss 不会一直平滑下降,常见问题很多,如下:
| 问题 | 表现 | 数学原因 |
|---|---|---|
| 学习率太大 | loss 震荡或爆炸 | 每一步跨得太远 |
| 学习率太小 | 训练很慢 | 每一步变化太小 |
| 梯度爆炸 | 参数更新失控 | 梯度数值过大 |
| 梯度消失 | 前面层学不动 | 梯度经过多层后变得很小 |
| 过拟合 | 训练集好,测试集差 | 模型记住噪声而不是规律 |
正则化就是解决过拟合的一类方法。数学上,它通常是在原来的 loss 后面加一个惩罚项:
1 | L_total = L_train + λR(θ) |
| 部分 | 含义 |
|---|---|
| L_train | 训练误差 |
| R(θ) | 对参数复杂度的惩罚 |
| λ | 惩罚强度 |
最后可以用一张表简单介绍几个优化概念:
| 概念 | 数学原理 | 对理解 LLM 的帮助 |
|---|---|---|
| 凸优化 | 如果目标函数是凸的,局部最优就是全局最优 | 帮助理解什么是“好优化问题” |
| 岭回归 | 在 loss 里加入 L2 参数惩罚 | 理解正则化 |
| 拉格朗日乘子 | 把约束条件合并进优化目标 | 理解带约束优化 |
| Proximal Gradient | 把普通梯度下降和复杂正则项结合 | 理解稀疏化、约束优化 |
| 凸松弛 | 把难优化问题放宽成更容易求解的问题 | 理解近似求解思想 |
LLM 的学习过程,就是把预测错误定义成 loss,用梯度找到参数修改方向,用反向传播把错误传回每一层,再通过优化器一步步更新参数。数学上看,它不是“模型突然理解了语言”,而是在大量样本上持续最小化一个目标函数。
总结
到这里,我们并不是把大学数学重新学了一遍,而是把和 LLM 最相关的几类数学概念重新串了起来。LLM 看起来是在理解语言、生成文字,但从数学上看,它背后一直在做几件非常基础的事情:
| 问题 | 数学工具 | 在 LLM 中的作用 |
|---|---|---|
| 语言怎么被机器处理? | Token、向量、矩阵 | 把文字变成可计算的数字表示 |
| 词和词之间怎么建立关系? | 点积、余弦相似度、Attention | 计算 token 之间的相关性 |
| 下一个 token 怎么预测? | 条件概率、Softmax | 把模型分数变成概率分布 |
| 模型错了怎么衡量? | 交叉熵、最大似然、loss | 把预测错误变成可优化的数字 |
| 模型怎么变好? | 梯度、反向传播、优化器 | 根据错误调整参数 |
所以,LLM 的核心并不是“机器突然懂了语言”,而是把语言问题转化成了一系列可以计算、可以预测、可以优化的问题。
