Apache Flink 初探
本篇文章是 Flink 系列 的第一篇,最近计划花个一到两个月的时间以最新的 Flink-1.9 代码为例把 Flink 的主要内容梳理一遍,这个系列文章的主要内容见 Flink 源码分析,这个 issue 拖了好几个月,现在终于开动了,不容易。梳理的过程也是个人强化学习的过程,博客中有问题的地方也欢迎各位指正(邮件联系 or disqus 评论都行,我这边都会及时回复)。
本篇的题目是 Apache Flink 初探,比较适合对 Flink 不是很了解,想进一步了解的同学,主要会讲述一下流计算的基本知识,以及对 Flink 做了一个简单的介绍,算是这个系列的开胃小菜。
流计算的基础知识
关于流计算,业内有一本口碑神一般存在的书,那就是大名名鼎鼎的《Streaming Systems》,这本书对流计算领域的问题及技术做了很深的讨论,如果你看过相关的内容,你就会发现 Flink 实际上就是开源届里实现最接近 DataFlow 模型的框架,这里先给大家介绍一下流计算相关的背景知识,对于后面理解 Flink 的设计,特别是高阶 API 的设计(实际上 DataStream API 就是为 DataFlow 模型而开发的)。
数据流
计算的数据源可以有很多种类型,比如:电商的交易数据、用户行为日志、物联网数据等,这些数据集可以分为两类:
- 有边界数据集(Bounded dataset): A type of dataset that is finite in size;
- 无边界数据集(Unbounded dataset): A type of dataset that is infinite in size;
从另一个角度来看,无边界数据集更符合现实中数据的产生方式,这样的话,就可以认为有边界数据集是无边界数据集的一个特例或一个子集。
时间域
在分布式计算中,关于时间域有两种类型:
- Event Time(事件时间): This is the time at which events actually occurred;
- Processing Time(处理时间): This is the time at witch events are observed in the system。
简单来说,事件时间是事件真实发生的时间,而处理时间是事件在计算引擎中被处理的时间,理想情况下,两者是相等的,但在实际情况下,它们之间差距的影响因素非常多,可能跟软件、硬件或数据有关,并且这个差距毫无规律可言,如下如图所示:
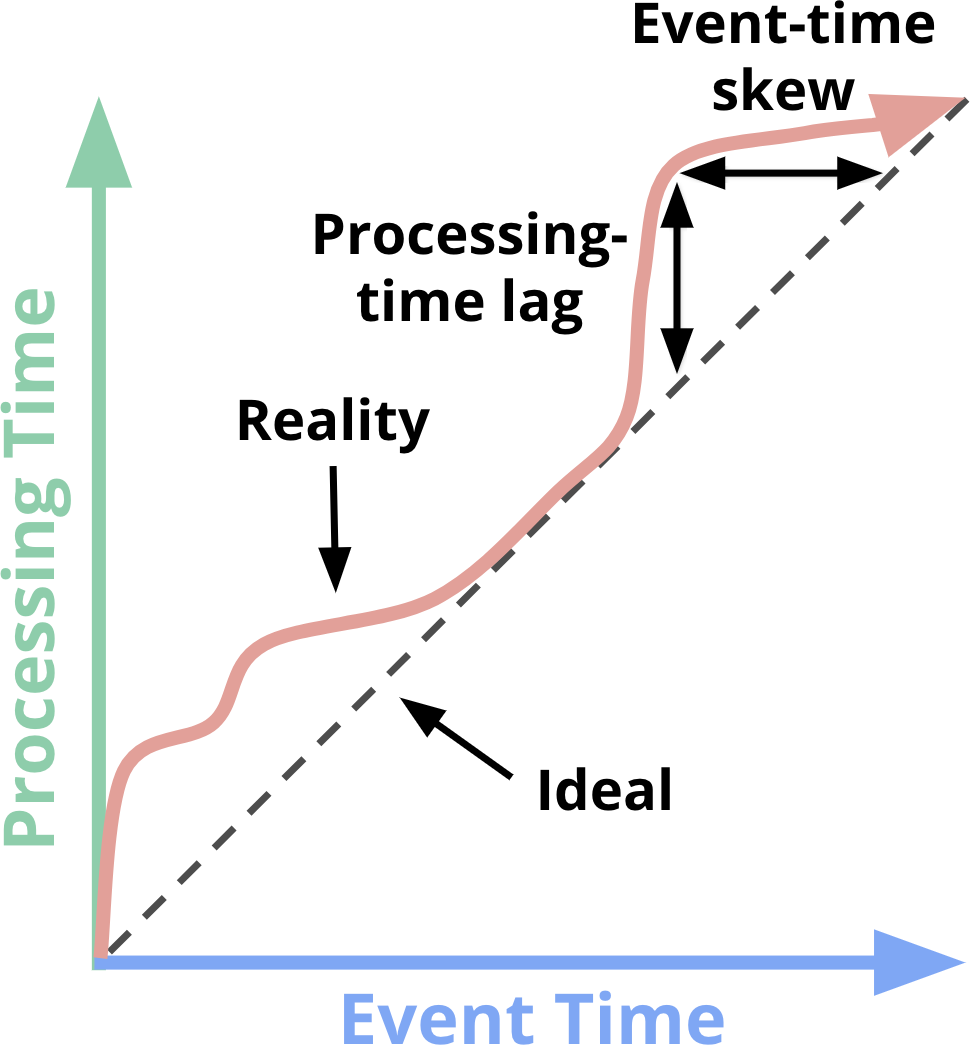
上面的问题给流计算带来了很多的问题,而且由于数据的无边界特性,业内通常的做法是将输入数据进行 window 操作(本质上还是按照时间切片),而对于一些关注 Event Time 的应用来说,按照 Processing Time 做 window 是完全无法满足需求的(流计算之前困扰大家最大的问题之一就是这个准确性的问题)。
Window & Watermark
目前常用的 window 类型有以下几种:
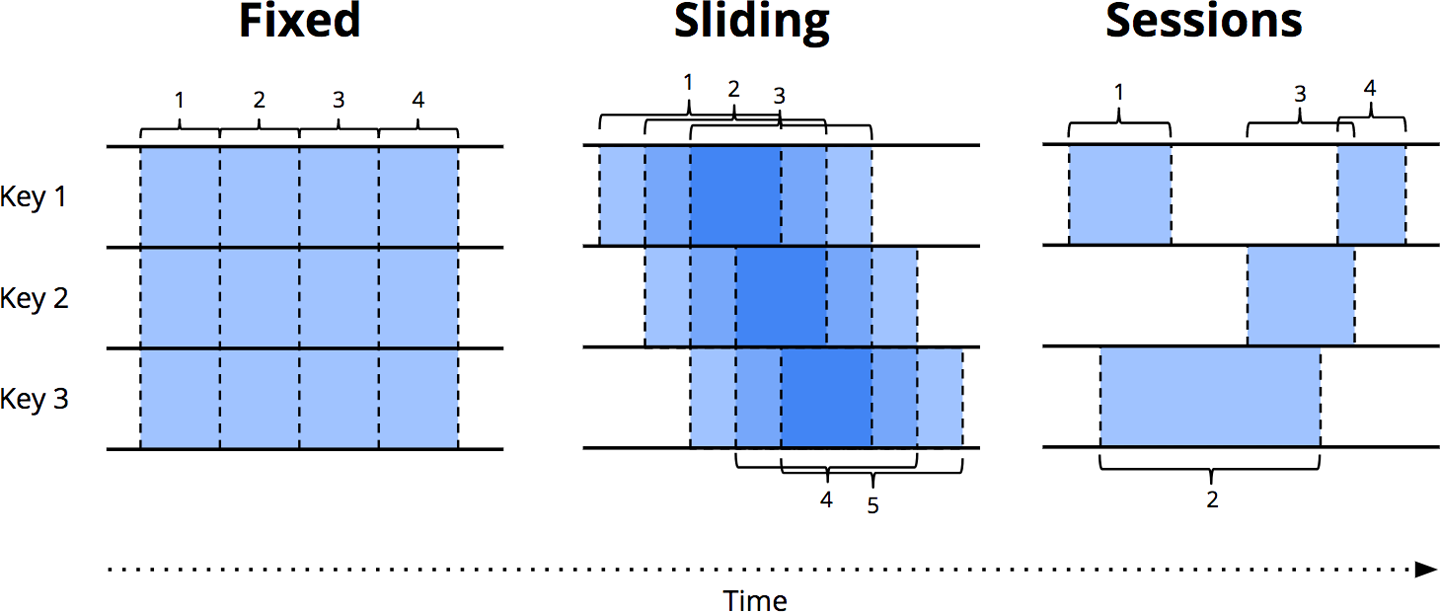
- Fixed Window:按时间切成固定大小的 window,是 aligned window 的一种;
- Sliding Window:也是一种 Fixed Window,但它有 fixed length 和 fixed period 两个设置;
- Sessions:一种 unaligned window,长度是未知的,一种动态的 window,比如分析用户的行为等。
Window 在 Event time 和 Processing time 下都是有意义的,只是适用于不同的应用场景而已,而对于 Event time 场景,如何来保证一个窗口数据的完整性呢?而窗口数据的完整性又确定了数据的准确性。
Watermark 就是来就解决这个问题的,它用于界定什么时间(时间戳)认为一个时间窗口内的数据已经全部到齐,之后晚于该 watermark 到达的数据则为迟到数据。
有状态计算
计算任务可以分为有状态计算和无状态计算:
- 无状态计算:如果处理一个事件(或一条数据)的结果只跟该事件本身有关;
- 有状态计算:计算结果还和之前处理过的事件有关,比如说基本的聚合计算,就是有状态计算。
对于批处理,每次处理的都是全量数据,所以就不用考虑状态这个问题。而流处理,一般会借助外部存储系统实现状态保存(这个对应的 Flink 中 State 模块的内容)。
容错
流计算另一个难点的是容错恢复,如何保证恢复之后作业状态的一致性,目前业内通用的解决方案采用的是 Chandy-Lamport 算法(有兴趣的可以看下 Paper 阅读: Distributed Snapshots: Determining Global States of Distributed Systems),包括 Structured Streaming 也采用的这个方案。
到这里,把流计算的基础知识简单过了一下,想了解更多的同学,建议阅读一下 Google DataFlow 那篇论文或者《Streaming Systems》这本书(Apache Flink 零基础入门(一):基础概念解析 这篇讲述得也不错)。
Why Flink?
流计算领域的开源框架,不可谓不多,但到现在还能让大家记住的(或者对业内产生巨大影响的)其实并不多,通常大家对比的也就是:Storm/Spark Streaming/Flink。在 17 年之前,我们在面临流计算技术选型时还可能会徘徊一下,但如果放在现在,你会发现,几乎没有太大可比性,几个引擎的差距已经很大,简单对比一下(只列出了流计算中重点关注的特性,只是粗略的比较,勿喷):
- Storm:没有 SQL 和高阶 API 的支持、无法支持 exactly once;
- Spark Streaming:对实时计算来说,微批处理天生是有架构上的缺陷;
- Structured Streaming:完全处于初级阶段,没有经过大规模生产业务的验证;
- Kafka Streams:目前没有自己的调度框架,不知道未来 on k8s 会不会在架构上做支持,要不然 kafka streams 要想应用大规模业务场景,维护成本太高,社区最好是能给出一套统一的解决方案,但是如果业务规模比较小,其实选 kafka streams 也不错,只维护一套系统,维护成本会低一些;
- Flink: 有 Streaming SQL 的支持,支持 exactly once 等等;
一圈比较下来,你会发现 Flink 真的是流计算的最佳选择,当然选择 Flink 还有其他很多的原因,可以参考阿里官方给出这两篇文章:
Flink 架构
Apache Flink 采用经典的分布式架构设计 —— Master/Slave 架构,Flink 集群的架构图如下图所示,这张图展示了其整体结构,但是很多内部细节并没有展示,我也翻了很多的博客,也没有找到一张特别满意的架构图。
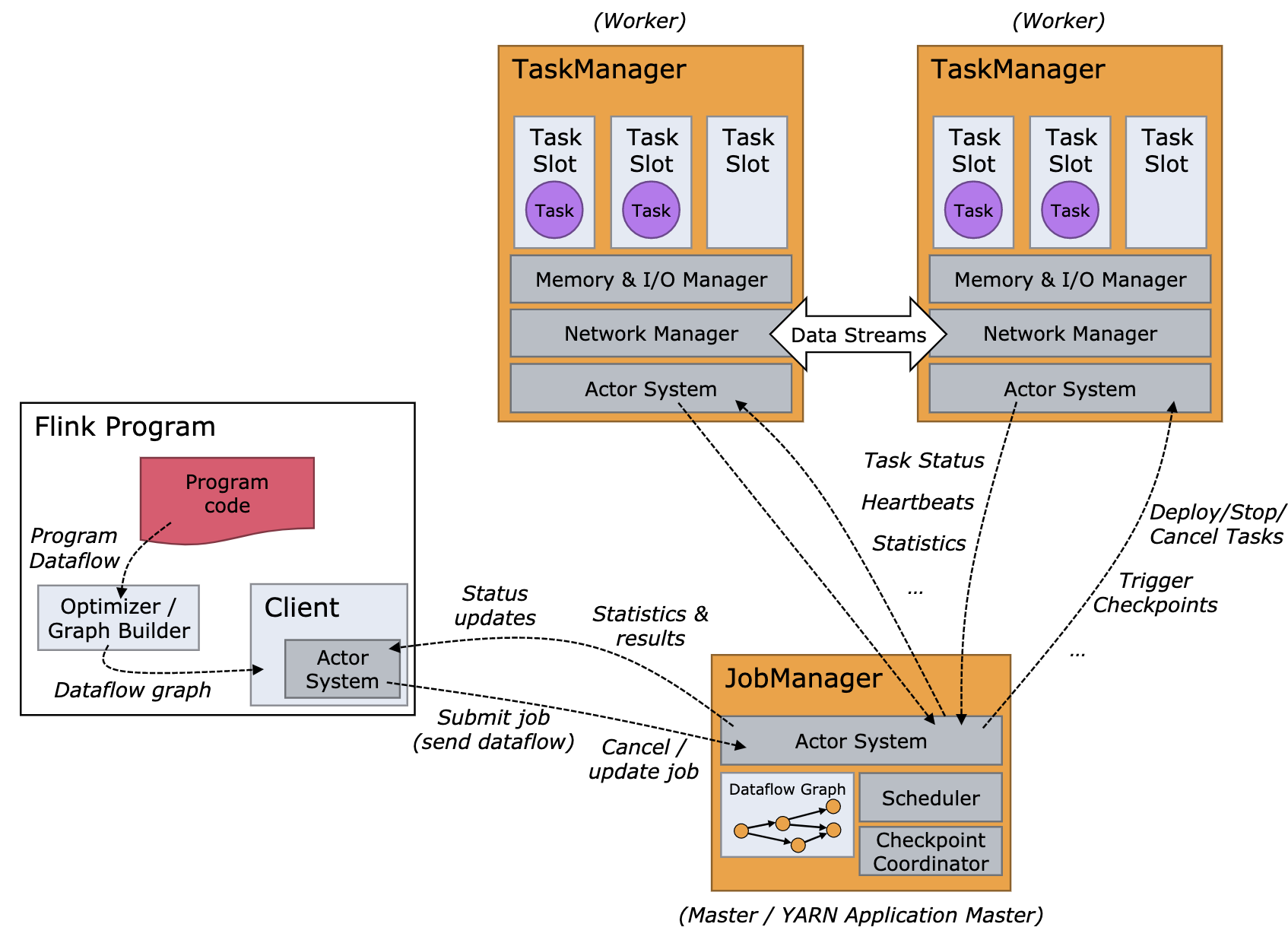
一个 Flink 集群,主要包含了两个核心组件:
- JobManager(master):它会负责整个任务的协调工作,包括:调度 task、触发协调 Tasks 做 Checkpoint、协调容错恢复等等(HA 模式下,一个集群会启动多个 JobManager,但只会有一个处在 leader 状态,其他处在热备状态 —— standby);
- TaskManager(workers):负责执行一个 DataFlow Graph 的各个 tasks 以及 data streams 的 buffer 和数据交换。
JobManager/TaskManager 都是进程级别,TaskManager 在启动时,会根据配置将其内部的资源分为多个 slot,每个 slot 只会启动一个 Task,Task 是线程级别,从这里可以看出 Flink 是多线程调度模型,一个 TM 中可能会有来自多个任务的 task,从资源利用的角度看,这样的设计是有一些收益的,但是从资源隔离的角度看,这种设计就不是那么好了,不过好在现在业内的使用方式基本都是 On Yarn 的单集群单作业模式,相当于把资源隔离这个问题避过去了,但不可否认,这种设计是有缺陷的。
Flink 部署
关于 Flink 的部署,这里推荐一下这几篇文章,本文就没有必要再整理了:
- Standalone Cluster;
- YARN Setup;
- Kubernetes Setup;
- Flink CookBook-环境准备;
- Apache Flink 零基础入门(二):开发环境搭建和应用的配置、部署及运行;
编译 Flink 源码
如果你想自己编译 Flink 安装包的话,可以参考 Flink Readme - Building Apache Flink from Source,这里给了几个不同的编译命令,最终的结果是一样,都可以正常编译出安装包:
1 | # 删除已有的 build,编译 flink binary |
最后生成的安装包就在 flink-dist/target/flink-1.9-SNAPSHOT-bin 下,在 flink 目录下也会生成一个 build-target 的软连。
Flink 示例
这里有一个示例,见 RandomWordCount(后面的文章也会以这个示例讲述),这个示例比较简单,就是先模拟两个数据源,再对流做 union, 再做过滤,最后再做 WorkCount,这个作业可以在 Flink 工程中直接运行。
1 | public class RandomWordCount { |
开胃小菜到这里就结束了,后面会逐步给大家剖析 Flink 的内部实现原理与机制,其实整个 Flink 的代码可以三大块:
- 分布式框架相关的内容,这块的内容,其实你会感觉很多系统有一些相似的地方,但是每套系统又只能自己去开发一遍,像 JobManager/TaskManager 之间的交互、内存管理、IO 管理等都属于这一部分;
- Flink 专门去解决 Streaming Process 问题而实现的设计,其实也就是 DataFlow 模型如何在 Flink 上实现的;
- SQL:这块比较特殊,算是比较单独的一块。
参考:
- Dataflow Programming Model;
- Distributed Runtime Environment;
- Component Stack;
- Apache Flink 进阶(一):Runtime 核心机制剖析 ;
- Apache Flink 零基础入门(一):基础概念解析;
- Apache Flink 零基础入门(二):开发环境搭建和应用的配置、部署及运行;
- Flink SQL 系列 | 5 个 TableEnvironment 我该用哪个?;
- Flink CookBook-环境准备;
- Flink CookBook—Apach Flink核心知识介绍;
- Flink CookBook—流式计算介绍;
- Flink 原理与实现:架构和拓扑概览;
