Paper 阅读: Lightweight Asynchronous Snapshots for Distributed Dataflow
本篇文章是对 Lightweight Asynchronous Snapshots for Distributed Dataflow 的一个总结,从文章题目也可以看出文章的主题 —— 分布式 dataflow 的轻量级异步 snapshot 算法,它是 Flink 团队在 2015 年发表的论文,主要讲述了对于 Streaming System 如何做 snapshot 的,它选取的是 Chandy-Lamport 算法(论文见 Distributed Snapshots: Determining Global States of Distributed Systems),关于这个算法后面会单独一篇文章来总结。在 Lightweight Asynchronous Snapshots for Distributed Dataflow 这篇论文中,作者更多向我们表达的是 Chandy-Lamport 算法如何在 Flink 中落地的以及如何解决分布式 dataflow 做 snapshot 时遇到的痛点。
问题
分布式有状态的流处理允许在云上部署和执行大规模的流数据计算,并且要求低延迟和高吞吐。这种模式一个比较大的挑战,就是其容错能力,能够应对潜在的 failure。当前业内的方案都是依赖周期性地全局状态的 snapshot 做 failure recovery。但这种方案有两个非常大的缺陷:
- 它们在做 snapshot 时会影响当前计算(目前的算法都是同步 snapshot);
- 它们在当前 Operator State 中会把未处理和正在传输过程中的 record 做为 snapshot 的一部分持久化,这会导致 snapshot 非常大,记录了很多其实并不需要的数据。
本篇论文中提出了一个新的 global consistent snapshot 算法 —— Asynchronous Barrier Snapshot(ABS),它是一个轻量级的算法,非常适合现代 dataflow 系统,数据存储空间占用也非常小(论文原话是 Our solution provides asynchronous state snapshots with low space costs that contain only operator states in acyclic execution topologies.)。另外,这个算法不会影响作业计算,性能开销比较小。
业内现状
在过去的几十年中,关于连续处理系统的 recovery 机制,工业界和学术界提出了很多种解决办法,如: Distributed Snapshots: Determining Global States of Distributed Systems) 和 Naiad: A Timely Dataflow System。有一些系统如 Discretized Streams 和 Comet 会把连续处理当作 无状态的分布式批处理计算 来做状态恢复;对于有状态的 dataflow 系统,如:Naiad、SDGs、Piccolo 和 SEEP,它们是我们的主要关注点,它们使用 checkpoint 获取全局一致的 snapshot 来做故障恢复。
关于 consistent global snapshot 的问题,自从在 Chandy 和 Lamport 的论文中提出来后,过去二十多年一直在被广泛地研究。全局 snapshot 理论上反映了作业执行的总体状态以及 operator 实例的可能状态。对于全局一致性 snapshot 算法,Naiad 中提出了一个简单但代价非常高昂的实现方案:
- 第一步,先停止计算;
- 第二步,开始做 snapshot;
- 第三步,如果 snapshot 完成了,每个 task 再恢复之前的计算。
这个实现方案对吞吐和空间占用都有很大的影响,它并不是一个很好的方案。另一个实现方案,就是 Chandy-Lamport 算法,当前它已经应用在很多的系统中,它是异步地执行快照,并且要求上游数据源可以回溯(也就是要求数据源能够自己备份)。它是通过在数据流中发送 marker 来实现,marker 会触发 operator 和 state 的 snapshot。但这种算法还需要额外的存储空间用于上游数据量恢复,数据流的重新计算也会导致恢复时间较长(主要还是原生算法会对一些 record 也做相应的 snapshot,这会导致存储空间占用过高以及恢复时间过长)。本论文中提出的方案扩展了原生的 Chandy-Lamport 算法,但对于无环 graph 它不会备份未处理及通道中正在传输的 record,对于有环的 graph,它也只需要很少量的 record 备份。
解决方案:Asynchronous Barrier Snapshot(ABS)
因为这个算法的实现本身就是为了解决 Apache Flink 的容错问题,论文中的描述也是以 Flink 系统为例,所以想要搞明白这个算法还是需要一些 Flink 的基础,本文中,我们就不再对 Flink 展开了。这里只简单介绍一下,有兴趣的可以看下官网资料,Flink 是一个可用于 Streaming 和 Batch 处理的大数据处理引擎,它本身的设计也是深受 Google DataFlow 模型的影响,可以说 Flink 是开源系统中最接近 DataFlow 思想的一个计算引擎。另外,Flink 的作业,在提交的时候都会被翻译成一个有向无环图(DAG),对于 Flink Master 来说,提交过来的作业都是一个 graph。
Problem Definition
这里,我们这样定义一个 global snapshot(它需要包含所有的状态信息,这样才能保证 failover 之后能够正确恢复状态):
$G^*=(T^*, E^*)$
它代表一个 execution graph $G = (T, E)$ 的一个全局快照,$T^*$ 代表所有 task 状态的集合,$E^*$ 代表所有 edge 状态的集合。也就是说:
- $∀t ∈ T, s_t^∗ ∈ T^∗$,$T^*$ 会包含所有 Operator 的状态;
- $E^*$ 会包含所有 channel 状态的集合,$e^*$ 会包含 $e$ 中正在传输的所有 record。
为了能够保证 recovery 后正确恢复状态信息,对于每个 $G^*$,都需要保证以下两个特性:
- Termination:snapshot 能够在一定的时间内完成;
- Feasibility:它表示这个 snapshot 是有意义的,也就是说在 snapshot 期间尽管计算没有停止,也不会有任何信息丢失。
ABS for Acyclic Dataflows:非环 dataflow 中的 ABS 实现
这里先看下在无环 dataflow 中 ABS 是如何实现的,因为 Flink 只支持有向无环图,所以这个就是 Flink checkpoint 的实现方案。
当把一个作业的执行逻辑划分为多个 stage 时,做 snapshot 不存储 channel 中的 state 是完全有可能的。如果一个 operator 已经完成了对输入的所有计算,并且数据已经完全输出出去,那么只对 operator 的 state 做 snapshot 就可以达到我们的要求。
具体的实现就是:每个阶段的输入数据都会被周期性地插入一些特殊标记 —— barrier,这些 barrier 会推送到整个 dataflow 中直到 sink 节点(dataflow 中结束节点,它没有下游输出),每个 task 如果收到输入所有的 barrier 就开始做相应的 snapshot。这个算法的实现是有以下假设的:
- 网络传输是可靠的、可以做到 FIFO 传输,并且可以实现
blocked和unblocked,如果一个通道是blocked,它会把这个通道接收到的所有数据缓存起来先不发送,直接收到unblocked的信号才会发送; - Task 可以在其对应的 channel 触发以下三种操作:
blocked、unblocked和sendmsgs,Broadcastingmsgs 表示的是向下游所有的 channel 发送数据; - 对于 source 节点来说,输入节点被抽象为
Nil输入通道(一个虚拟通道)。
这个算法的伪代码如下:
1 | # Algorithm 1 Asynchronous Barrier Snapshotting for Acyclic Execution Graphs |
dataflow graph 执行图如下所示:
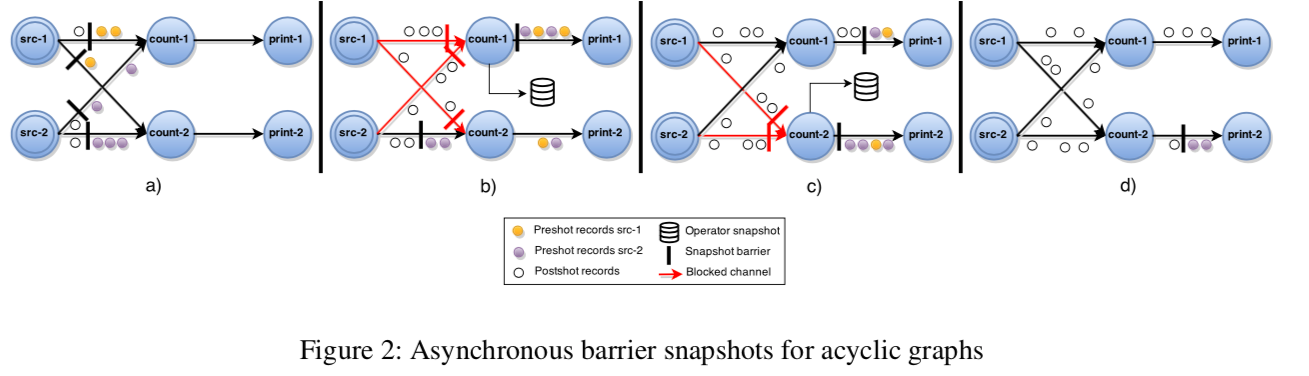
ABS 算法的执行流程如下:
- 中心协调器周期性地在所有输入端插入 barrier;
- 当一个 source 节点接收到 barrier 时,它对当前的状态做下 snapshot,并且 broadcast barrier 到所有的下游节点(如上图中的 a 子图);
- 当一个非 source 节点从它的输入通道中接收到一个 barrier 时,它会 block 当前的 channel 直到接收该节点所有输入端发送的 barrier(如上图中的 b 子图以及代码第 9 行);
- 当从所有输入 channel 都接收到 barrier 之后,这个 task 会对当前状态做一个 snapshot,并且 broadcast 这个 barrier 到所有的输出端(如上图中的 c 子图以及代码第 12-13 行);
- 最后,这个 task 会 unblock 它所有的输入 channel,继续进行计算(如上图中的 d 子图以及代码第 15 行)。
根据前面所示,我们知道,当前一个完整的 snapshot $G^* = (T^*, E^*)$,其 $E^* =0$,Operator 中的 state 信息就是完整的 snapshot。
对于 Termination 要求,它依赖于 channel 的可靠性以及 graph 的无环性;对于 Feasibility 要求,它依赖于 channel 的 FIFO 特性。只要这些是可以满足的,那么这两个要求就是可以满足的。
ABS for Cyclic Dataflows:有环 dataflow 中的 ABS 实现
前面分析完无环的情况,接下来再来看看有环的情况,当前的 ABS 算法稍微做些改造也是可以处理有环的情况。根据前面的介绍,有环带来的最大问题是:
- 死锁,一个 task 可能会不断收到 barrier,导致 snapshot 无法在可预期的时间内完成;
- 当然,有环还会导致另外一个问题,就是数据可能没有记录到 snapshot 中,会导致准确性有误;
对于有环的情况,论文是在不引入额外 channel block 的情况下扩展了原来的算法,这里就不再列出伪代码了,有兴趣的可以看下论文,这里以下图为例简单介绍一下:
- 对于有 back-edge 输入的节点(后边节点做输入的情况)来说,一旦它所有正常的输入 channel 都收到了这个 barrier,它会先对本地状态做本地 copy(下图 b);
- 从这个时间点开始,这个节点会将从 back-edge channel 接收到的所有数据记录下来直到接收到了相应的 barrier(下图 c),第一步 copy 的状态及第二步记录的数据都会作为 snapshot 的一部分。
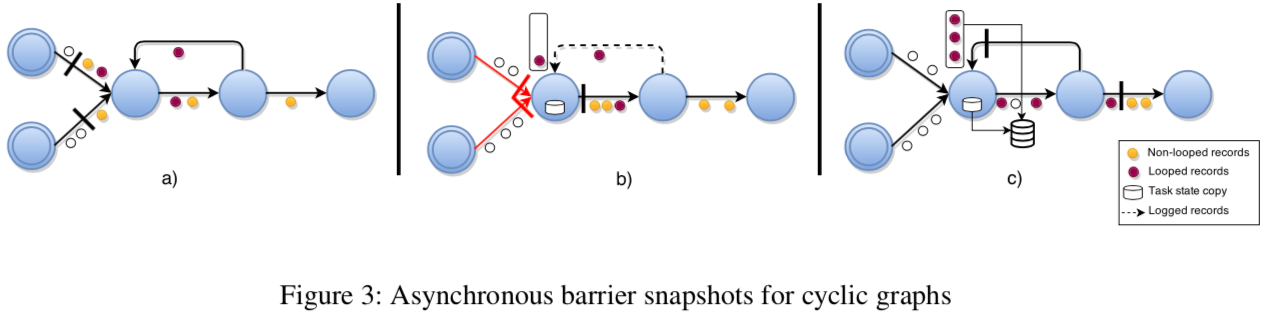
按照改进后的算法,是可以避免死锁的,这样的话 Termination 的要求是可以满足的;Feasibility 的特性依然是依赖于 channel 的 FIFO 来保证,snapshot 中每个 task state 都会包含该 task 在收到前置节点 barrier 之后的状态,对于有后置节点输入的 task 来说,它会把从后置节点接收到的数据记录下来,只会 copy 非常少量的数据。
Failure Recovery
论文还简单介绍了 Flink 是如何做 failover 恢复的,有了前面的全局一致 snapshot 算法,failover 做起来就简单很多。在 Flink 中,还支持 partial graph recovery,对于失败的 task,只需要恢复它的上游即可,并不需要全局恢复。为了在内部实现 exactly-once,通过给数据进行编号来避免重复数据。
性能测试
性能对比了本文提出的 ABS 算法以及 Naiad 中提出的全局同步 snapshot 算法,测试 case 选择了一个有 6 个 operator 的作业,它有三个地方会进行网络 shuffle,这样可以尽量增大 ABS 算法 channel block 带来的影响(如下图 5)。实验中,输入端会模拟 1 百万测试数据,operator 的状态信息主要包括按 key 聚合的中间结果以及 offset 信息,下图的纵坐标是作业运行时间,baseline 表示的是不开启 snapshot 时的性能,在这里做对比使用。
如上图 6,可以看到,当 snapshot 时间间隔非常小,同步的 snapshot 性能非常差,因为它在做 snapshot 会阻塞计算,时间都花费在 snapshot 上了,而 ABS 算法的实验结果就好了很多。如上图 7,集群节点及作业并行度从 5 逐渐增加到 40,可以看到 ABS 算法的性能还很稳定的。
总结
这篇论文是工业界对 Chandy-Lamport 算法实践后做的改进优化,将 Chandy-Lamport 算法在 Flink 的 global consistent snapshot 中落地,这篇论文还是非常值得读一下的,看下 Flink 在解决这个问题的时候是怎么去做的,论文的优化点其实并不是很大,一是把同步变成异步,二是从尽量减小存储空间占用的点出发,最后发现只存储 operator 状态不存储 edge 状态也是完全可以的,而且实践起来的效果确实证明比当时其他系统的算法要好。
参考
