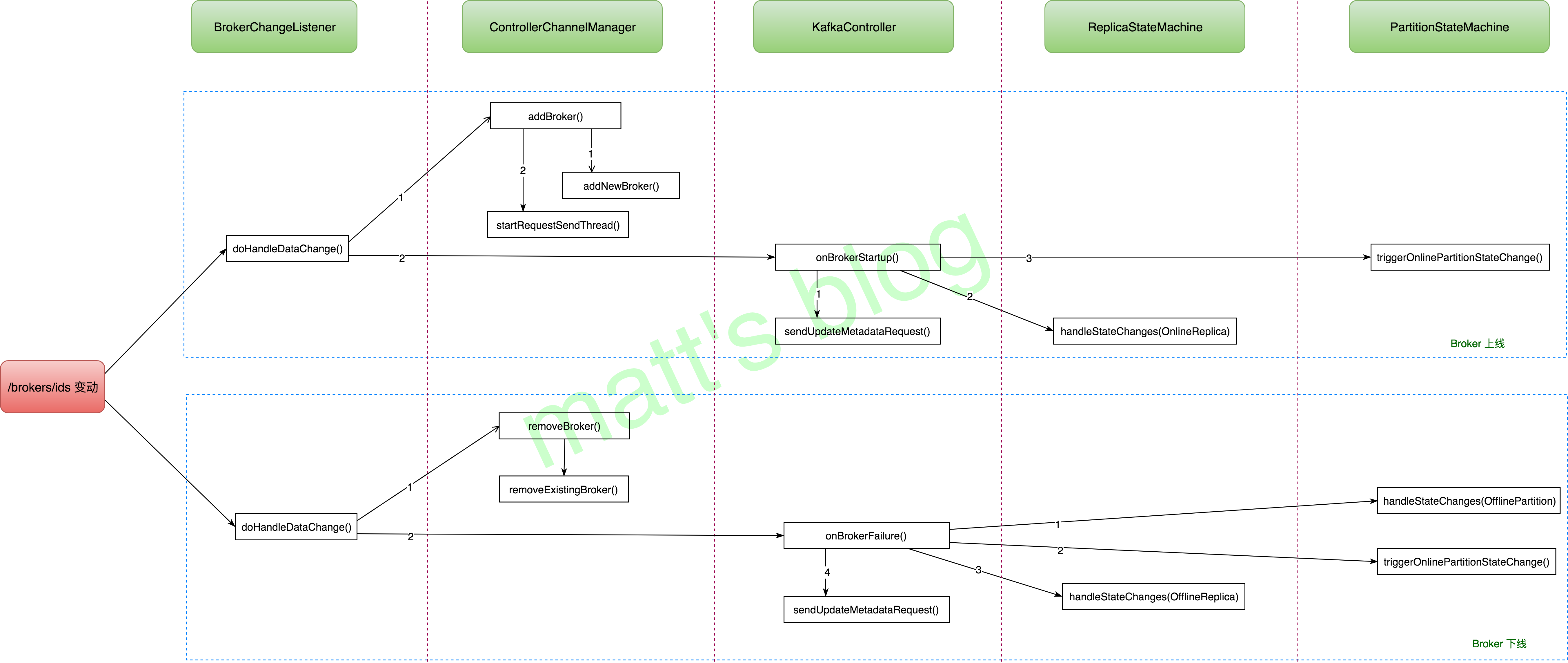
defaddBroker(broker: Broker) { // be careful here. Maybe the startup() API has already started the request send thread brokerLock synchronized { if(!brokerStateInfo.contains(broker.id)) { addNewBroker(broker) startRequestSendThread(broker.id) } } }
//note: 这个是被 副本状态机触发的 //note: 1. 发送 update-metadata 请求给所有存活的 broker; //note: 2. 对于所有 new/offline partition 触发选主操作, 选举成功的, Partition 状态设置为 Online //note: 3. 检查是否有分区的重新副本分配分配到了这个台机器上, 如果有, 就进行相应的操作 //note: 4. 检查这台机器上是否有 Topic 被设置为了删除标志, 如果是, 那么机器启动完成后, 重新尝试删除操作 defonBrokerStartup(newBrokers: Seq[Int]) { info("New broker startup callback for %s".format(newBrokers.mkString(","))) val newBrokersSet = newBrokers.toSet //note: 新启动的 broker // send update metadata request to all live and shutting down brokers. Old brokers will get to know of the new // broker via this update. // In cases of controlled shutdown leaders will not be elected when a new broker comes up. So at least in the // common controlled shutdown case, the metadata will reach the new brokers faster //note: 发送 metadata 更新给所有的 broker, 这样的话旧的 broker 将会知道有机器新上线了 sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq) // the very first thing to do when a new broker comes up is send it the entire list of partitions that it is // supposed to host. Based on that the broker starts the high watermark threads for the input list of partitions //note: 获取这个机器上的所有 replica 请求 val allReplicasOnNewBrokers = controllerContext.replicasOnBrokers(newBrokersSet) //note: 将这些副本的状态设置为 OnlineReplica replicaStateMachine.handleStateChanges(allReplicasOnNewBrokers, OnlineReplica) // when a new broker comes up, the controller needs to trigger leader election for all new and offline partitions // to see if these brokers can become leaders for some/all of those //note: 新的 broker 上线也会触发所有处于 new/offline 的 partition 进行 leader 选举 partitionStateMachine.triggerOnlinePartitionStateChange() // check if reassignment of some partitions need to be restarted //note: 检查是否副本的重新分配分配到了这台机器上 val partitionsWithReplicasOnNewBrokers = controllerContext.partitionsBeingReassigned.filter { case (_, reassignmentContext) => reassignmentContext.newReplicas.exists(newBrokersSet.contains(_)) } //note: 如果需要副本进行迁移的话,就执行副本迁移操作 partitionsWithReplicasOnNewBrokers.foreach(p => onPartitionReassignment(p._1, p._2)) // check if topic deletion needs to be resumed. If at least one replica that belongs to the topic being deleted exists // on the newly restarted brokers, there is a chance that topic deletion can resume //note: 检查 topic 删除操作是否需要重新启动 val replicasForTopicsToBeDeleted = allReplicasOnNewBrokers.filter(p => deleteTopicManager.isTopicQueuedUpForDeletion(p.topic)) if(replicasForTopicsToBeDeleted.nonEmpty) { info(("Some replicas %s for topics scheduled for deletion %s are on the newly restarted brokers %s. " + "Signaling restart of topic deletion for these topics").format(replicasForTopicsToBeDeleted.mkString(","), deleteTopicManager.topicsToBeDeleted.mkString(","), newBrokers.mkString(","))) deleteTopicManager.resumeDeletionForTopics(replicasForTopicsToBeDeleted.map(_.topic)) } }
//note: 这个方法会被副本状态机调用(进行 broker 节点下线操作) //note: 1. 将 leader 在这台机器上的分区设置为 Offline //note: 2. 通过 OfflinePartitionLeaderSelector 为 new/offline partition 选举新的 leader //note: 3. leader 选举后,发送 LeaderAndIsr 请求给该分区所有存活的副本; //note: 4. 分区选举 leader 后,状态更新为 Online //note: 5. 要下线的 broker 上的所有 replica 改为 Offline 状态 defonBrokerFailure(deadBrokers: Seq[Int]) { info("Broker failure callback for %s".format(deadBrokers.mkString(","))) //note: 从正在下线的 broker 集合中移除已经下线的机器 val deadBrokersThatWereShuttingDown = deadBrokers.filter(id => controllerContext.shuttingDownBrokerIds.remove(id)) info("Removed %s from list of shutting down brokers.".format(deadBrokersThatWereShuttingDown)) val deadBrokersSet = deadBrokers.toSet // trigger OfflinePartition state for all partitions whose current leader is one amongst the dead brokers //note: 1. 将 leader 在这台机器上的、并且未设置删除的分区状态设置为 Offline val partitionsWithoutLeader = controllerContext.partitionLeadershipInfo.filter(partitionAndLeader => deadBrokersSet.contains(partitionAndLeader._2.leaderAndIsr.leader) && !deleteTopicManager.isTopicQueuedUpForDeletion(partitionAndLeader._1.topic)).keySet partitionStateMachine.handleStateChanges(partitionsWithoutLeader, OfflinePartition) // trigger OnlinePartition state changes for offline or new partitions //note: 2. 选举 leader, 选举成功后设置为 Online 状态 partitionStateMachine.triggerOnlinePartitionStateChange() // filter out the replicas that belong to topics that are being deleted //note: 过滤出 replica 在这个机器上、并且没有被设置为删除的 topic 列表 var allReplicasOnDeadBrokers = controllerContext.replicasOnBrokers(deadBrokersSet) val activeReplicasOnDeadBrokers = allReplicasOnDeadBrokers.filterNot(p => deleteTopicManager.isTopicQueuedUpForDeletion(p.topic)) // handle dead replicas //note: 将这些 replica 状态转为 Offline replicaStateMachine.handleStateChanges(activeReplicasOnDeadBrokers, OfflineReplica) // check if topic deletion state for the dead replicas needs to be updated //note: 过滤设置为删除的 replica val replicasForTopicsToBeDeleted = allReplicasOnDeadBrokers.filter(p => deleteTopicManager.isTopicQueuedUpForDeletion(p.topic)) if(replicasForTopicsToBeDeleted.nonEmpty) { //note: 将上面这个 topic 列表的 topic 标记为删除失败 // it is required to mark the respective replicas in TopicDeletionFailed state since the replica cannot be // deleted when the broker is down. This will prevent the replica from being in TopicDeletionStarted state indefinitely // since topic deletion cannot be retried until at least one replica is in TopicDeletionStarted state deleteTopicManager.failReplicaDeletion(replicasForTopicsToBeDeleted) }
// If broker failure did not require leader re-election, inform brokers of failed broker // Note that during leader re-election, brokers update their metadata if (partitionsWithoutLeader.isEmpty) { sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq) } }
defhandleControlledShutdownRequest(request: RequestChannel.Request) { // ensureTopicExists is only for client facing requests // We can't have the ensureTopicExists check here since the controller sends it as an advisory to all brokers so they // stop serving data to clients for the topic being deleted val controlledShutdownRequest = request.requestObj.asInstanceOf[ControlledShutdownRequest]
inLock(controllerContext.controllerLock) { //note: 拿到 controllerLock 的排它锁 if (!controllerContext.liveOrShuttingDownBrokerIds.contains(id)) thrownewBrokerNotAvailableException("Broker id %d does not exist.".format(id))
//note: 处理这些 TopicPartition,更新 Partition 或 Replica 的状态,必要时进行 leader 选举 allPartitionsAndReplicationFactorOnBroker.foreach { case(topicAndPartition, replicationFactor) => // Move leadership serially to relinquish lock. inLock(controllerContext.controllerLock) { controllerContext.partitionLeadershipInfo.get(topicAndPartition).foreach { currLeaderIsrAndControllerEpoch => if (replicationFactor > 1) { //note: 副本数大于1 if (currLeaderIsrAndControllerEpoch.leaderAndIsr.leader == id) { //note: leader 正好是下线的节点 // If the broker leads the topic partition, transition the leader and update isr. Updates zk and // notifies all affected brokers //todo: 这种情况下 Replica 的状态不需要修改么?(Replica 的处理还是通过监听器还实现的,这里只是在服务关闭前进行 leader 切换和停止副本同步) //note: 状态变化(变为 OnlinePartition,并且进行 leader 选举,使用 controlledShutdownPartitionLeaderSelector 算法) partitionStateMachine.handleStateChanges(Set(topicAndPartition), OnlinePartition, controlledShutdownPartitionLeaderSelector) } else { // Stop the replica first. The state change below initiates ZK changes which should take some time // before which the stop replica request should be completed (in most cases) try { //note: 要下线的机器停止副本迁移,发送 StopReplica 请求 brokerRequestBatch.newBatch() brokerRequestBatch.addStopReplicaRequestForBrokers(Seq(id), topicAndPartition.topic, topicAndPartition.partition, deletePartition = false) brokerRequestBatch.sendRequestsToBrokers(epoch) } catch { case e : IllegalStateException => { // Resign if the controller is in an illegal state error("Forcing the controller to resign") brokerRequestBatch.clear() controllerElector.resign()
throw e } } // If the broker is a follower, updates the isr in ZK and notifies the current leader //note: 更新这个副本的状态,变为 OfflineReplica replicaStateMachine.handleStateChanges(Set(PartitionAndReplica(topicAndPartition.topic, topicAndPartition.partition, id)), OfflineReplica) } } } } } //note: 返回 leader 在这个要下线节点上并且副本数大于 1 的 TopicPartition 集合 //note: 在已经进行前面 leader 迁移后 defreplicatedPartitionsBrokerLeads() = inLock(controllerContext.controllerLock) { trace("All leaders = " + controllerContext.partitionLeadershipInfo.mkString(",")) controllerContext.partitionLeadershipInfo.filter { case (topicAndPartition, leaderIsrAndControllerEpoch) => leaderIsrAndControllerEpoch.leaderAndIsr.leader == id && controllerContext.partitionReplicaAssignment(topicAndPartition).size > 1 }.keys } replicatedPartitionsBrokerLeads().toSet } }