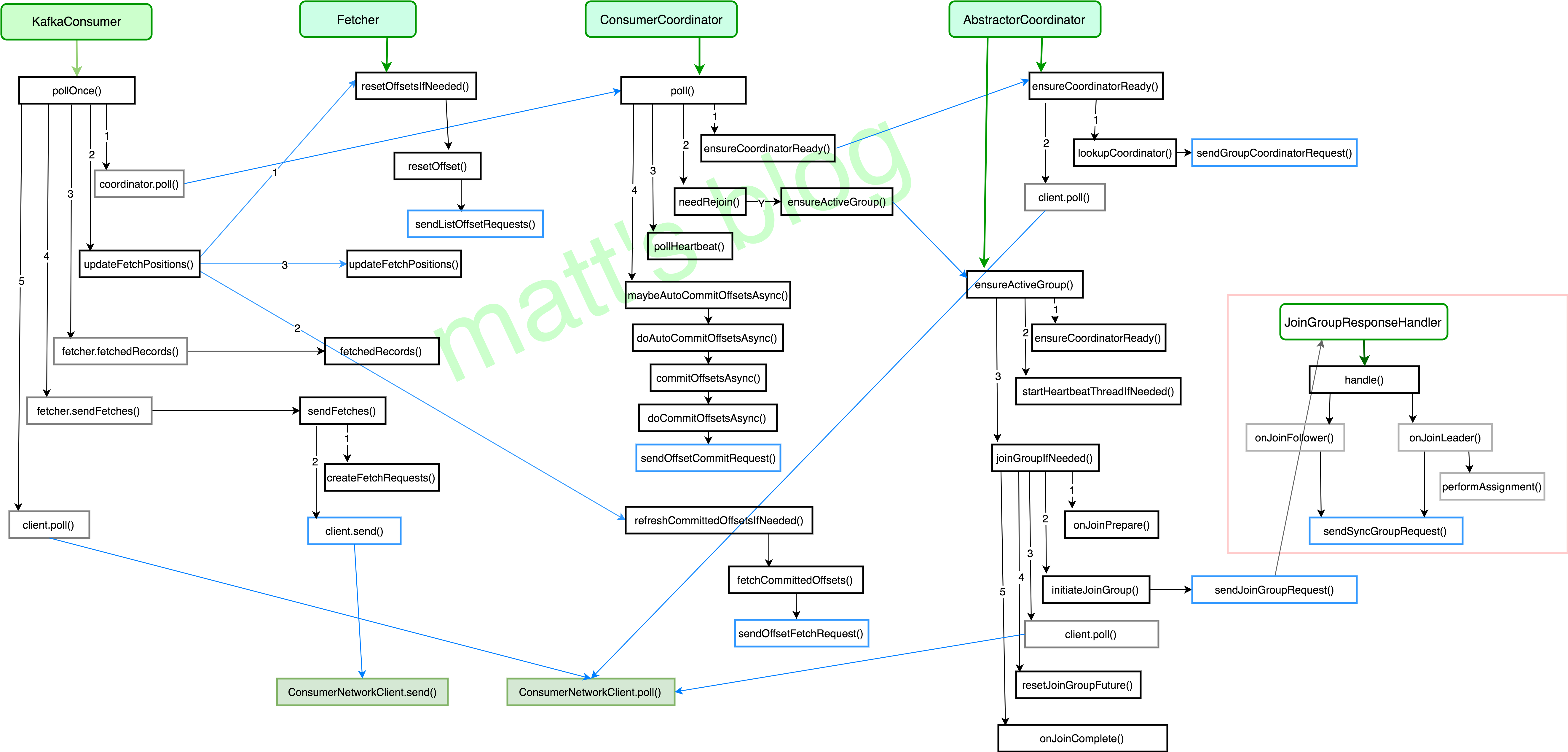
//timeout(ms): buffer 中的数据未就绪情况下,等待的最长时间,如果设置为0,立即返回 buffer 中已经就绪的数据 public ConsumerRecords<K, V> poll(long timeout){ acquire(); try { if (timeout < 0) thrownew IllegalArgumentException("Timeout must not be negative");
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) thrownew IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
// poll for new data until the timeout expires long start = time.milliseconds(); long remaining = timeout; do { Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollOnce(remaining); //note: 从订阅的 partition 中拉取数据,pollOnce() 才是对 Consumer 客户端拉取数据的核心实现 if (!records.isEmpty()) { // 在返回数据之前,发送下次的 fetch 请求,避免用户在下次获取数据时线程 block if (fetcher.sendFetches() > 0 || client.pendingRequestCount() > 0) client.pollNoWakeup();
if (this.interceptors == null) returnnew ConsumerRecords<>(records); else returnthis.interceptors.onConsume(new ConsumerRecords<>(records)); }
long elapsed = time.milliseconds() - start; remaining = timeout - elapsed; } while (remaining > 0);
//note: 记录 tp 的一些 offset 信息 privatestaticclassTopicPartitionState{ private Long position; // last consumed position private Long highWatermark; // the high watermark from last fetch private OffsetAndMetadata committed; // last committed position privateboolean paused; // whether this partition has been paused by the user private OffsetResetStrategy resetStrategy; // the strategy to use if the offset needs resetting }
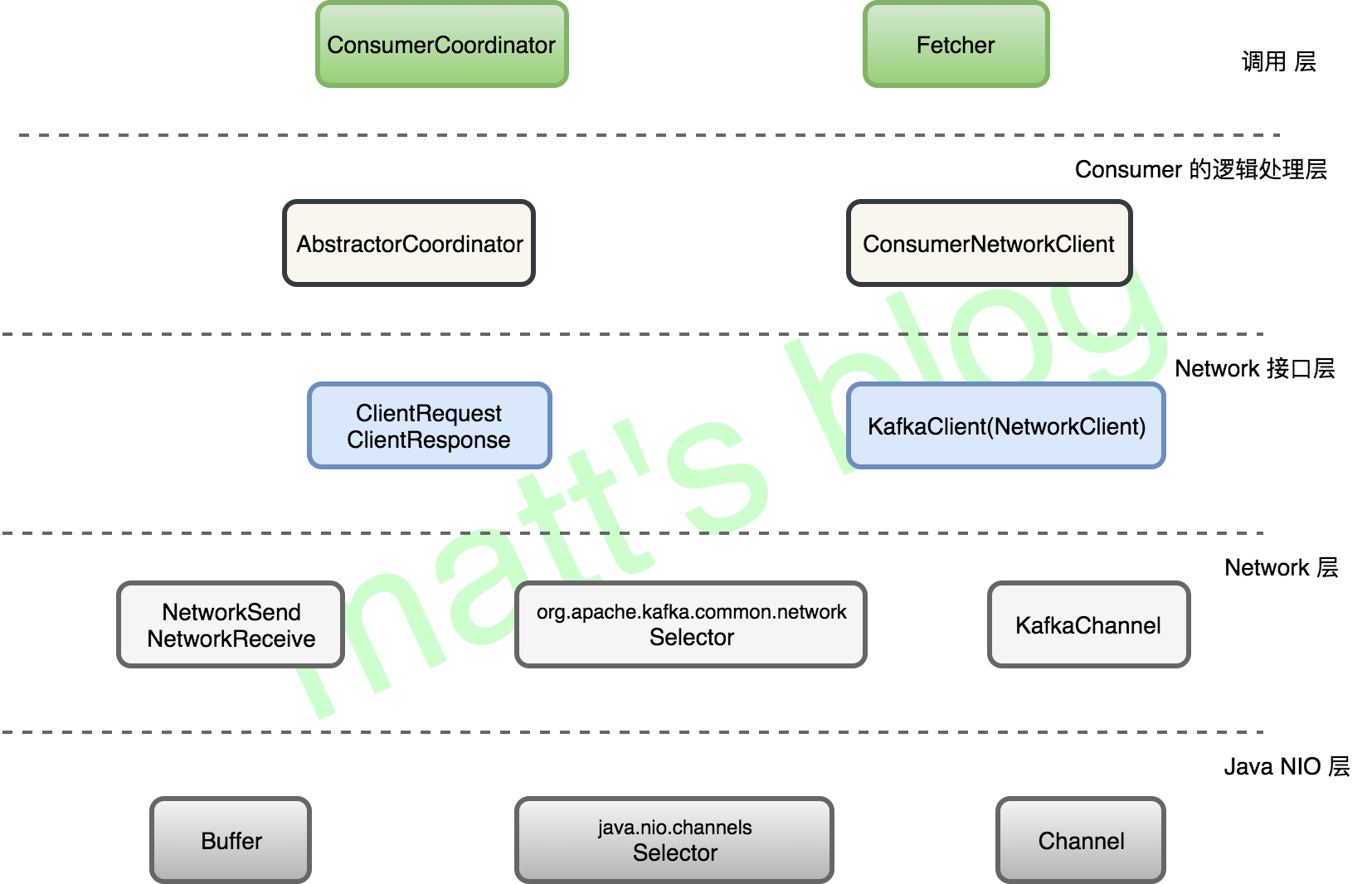
log.debug("Sending fetch for partitions {} to broker {}", request.fetchData().keySet(), fetchTarget); //note: 2 发送 Fetch Request client.send(fetchTarget, request) .addListener(new RequestFutureListener<ClientResponse>() { @Override publicvoidonSuccess(ClientResponse resp){ FetchResponse response = (FetchResponse) resp.responseBody(); if (!matchesRequestedPartitions(request, response)) { // obviously we expect the broker to always send us valid responses, so this check // is mainly for test cases where mock fetch responses must be manually crafted. log.warn("Ignoring fetch response containing partitions {} since it does not match " + "the requested partitions {}", response.responseData().keySet(), request.fetchData().keySet()); return; }
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet()); FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
// 返回获取到的 the fetched records, 并更新 the consumed position public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() { Map<TopicPartition, List<ConsumerRecord<K, V>>> drained = new HashMap<>(); int recordsRemaining = maxPollRecords;//NOTE: 在 max.poll.records 中设置单词最大的拉取条数
private List<ConsumerRecord<K, V>> drainRecords(PartitionRecords<K, V> partitionRecords, int maxRecords) { if (!subscriptions.isAssigned(partitionRecords.partition)) { // this can happen when a rebalance happened before fetched records are returned to the consumer's poll call log.debug("Not returning fetched records for partition {} since it is no longer assigned", partitionRecords.partition); } else { // note that the consumed position should always be available as long as the partition is still assigned long position = subscriptions.position(partitionRecords.partition); if (!subscriptions.isFetchable(partitionRecords.partition)) {//note: 这个 tp 不能来消费了,比如调用 pause log.debug("Not returning fetched records for assigned partition {} since it is no longer fetchable", partitionRecords.partition); } elseif (partitionRecords.fetchOffset == position) {//note: offset 对的上,也就是拉取是按顺序拉的 //note: 获取该 tp 对应的records,并更新 partitionRecords 的 fetchOffset(用于判断是否顺序) List<ConsumerRecord<K, V>> partRecords = partitionRecords.drainRecords(maxRecords); if (!partRecords.isEmpty()) { long nextOffset = partRecords.get(partRecords.size() - 1).offset() + 1; log.trace("Returning fetched records at offset {} for assigned partition {} and update " + "position to {}", position, partitionRecords.partition, nextOffset);
subscriptions.position(partitionRecords.partition, nextOffset);//note: 更新消费的到 offset( the fetch position) }
//note: 获取 Lag(即 position与 hw 之间差值),hw 为 null 时,才返回 null Long partitionLag = subscriptions.partitionLag(partitionRecords.partition); if (partitionLag != null) this.sensors.recordPartitionLag(partitionRecords.partition, partitionLag);
return partRecords; } else { // these records aren't next in line based on the last consumed position, ignore them // they must be from an obsolete request log.debug("Ignoring fetched records for {} at offset {} since the current position is {}", partitionRecords.partition, partitionRecords.fetchOffset, position); } }