Apache Kafka 0.9 Consumer Client 介绍【译】
近段时间在公司实习,有一项任务就是负责对Kafka新版本的一些feature做一下调研,主要是调研的内容是Kafka在0.9.0版本中提供的两个新特性:New Consumer API和安全认证机制,本文是在研究Kafka的新consumer API时看过的一篇文章,对于理解新API的设计理念以及应用,有很多的帮助,因此就打算翻译一下,帮助自己更好理解的同时也为开源做一些贡献。本文译自Introducing the Kafka Consumer: Getting Started with the New Apache Kafka 0.9 Consumer Client一文,是Confluent官方出的一篇关于Kafka新Consumer客户端介绍的文章。
注:个人的英文及写作水平有限,虽然有些地方能够理解作者的意思,但是可能自己会表达不准确,读者遇到难以理解的地方,可以对照英文原文进行阅读。另外,有些在Kafka中经常出现专有英文名词,本文会尽量还用英文表示,本来直接看这些英文名词就非常简洁,翻译成中文反而难以理解。
Kafka最初被设计时,它原生地提供了一个Scala版本的producer和Consumer客户端。但是随着Kafka的应用更加广泛,我们意识到这些API有很多的缺陷。比如,Kafka提供了一个high-level的Consumer API,它可以实现consumer group和自动容错,但是不能支持一些更复杂的使用场景,同时我们也提供了一套simple的Consumer API以提供更全面、更细粒度的控制,但是这种Consumer需要开发者自己设计容错机制。因此,我们重新设计和开发了客户端,以适应哪些旧的客户端很难或者无法适用的应用场景,并且建立了一套可以支持长久发展的API。
开始的第一阶段,在0.8.1的版本中,我们重写设计了Producer的API。最近的0.9.0版本完成了第二阶段,引入了新的Consumer API。在Kafka本身提供的一套新的group coordination protocol的基础上,新的Consumer有以下这些优势:
- Clean Consolidated API:新的Consumer结合了旧的”simple”和”high-level”Consumer客户端,同时提供了group协调机制和更细粒度的消费机制;
- Reduced Dependencies:新的Consumer完全是用Java编写的,它在运行过程中没有依赖Scala或者Zookeeper,这使得我们的工程的依赖包更加轻量化;
- Better Security:Kafka 0.9.0提供的security extensions只被新的Consumer所支持;
- 新的Consumer同样也增加一系列用于管理消费过程中group容错的协议。之前这部分的设计是使用Java客户端实现的,它需要频繁地与Zookeeper进行交互,这个实现逻辑上的复杂性使得这些它很难推广到其他语言的客户端上。而随着新协议的提出,实现变得更加简单,实际上C Client已经开始应用这个协议了。
尽管新的Consumer使用了重新设计的API和一个新的coordination protocol,但是Kafka的那些基础的概念并没有任何变化。因此,对旧的Consumer非常熟悉的开发者在理解新Consumer客户端的设计时并不会遇到太大困难。然而,却有一些不易察觉细节需要额外的关注,特别是在理解group management和thread model上时。本文的目的就是讲述一下新Consumer的使用以及解释一下这些细节问题。
有一点需要注意:在本文还在写的时候,新的Consumer在稳定性方面仍然被认为是”beta”。
我们已经解决了几个在0.9.0版中遇到的重要bug,如果你在使用0.9.0版时遇到任何问题,我们建议你先对这个分支进行一下测试。如果依然遇到问题,可以通过mail lists或者JIRA提出。
Getting Started:开始
开始讲述代码之前,我们先回顾一下Kafka的基本概念。在Kafka中,每一个topic都被分为一系列消息的集合,这些集合被称为partition,Producer会在这些消息集合的尾部追加数据,Consumer从给定的位置读取数据。Kafka通过consumer group实现规模化地消费topic数据,group是一系列Consumers共享一个共同的标识符。下图展示了一个有3个partition的topic被一个有2个成员的group消费的情况,topic的每个partition被安排到group中的一个cosumer上。
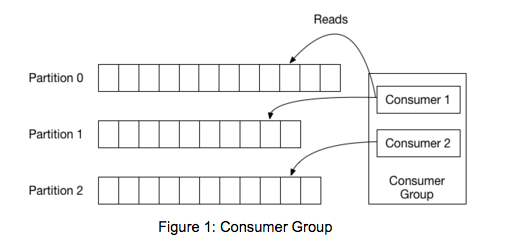
旧的Consumer依赖ZK进行group管理,而新的Consumer则使用了一个Kafka自身提供的group coordination protocol实现。对于每一个group,都会从所有的broker中选取一个作为group coordinator,这个coordinator是负责维护和管理这个group的状态,它的主要工作是当一个consumer加入、一个consumer离开(挂掉或者手动停止等)或者topic的partition改变时重新进行partition分配,这个过程就是group的rebalance。
这里有一个问题需要思考,每个topic的元数据信息(具体的指的是,这个topic有多少个partition,每个partition的leader在哪台broker上)是不是也有coordinator保存的?还是这些元数据信息直接保存在broker上?
当一个group刚开始被初始化时,group中consumer可以选择从每个partition的最小或者最大的offset开始消费数据,然后每个partition中的message会按顺序依次进行消费。随着Consumer的处理,它会对已经成功处理的msg进行commit(提交的是msg的offset)。例如,如下图所示,Consumer当前消费的msg的offset(Current Position)是6,上一次已经提交的msg的offset(Last Committed Offset)是1.
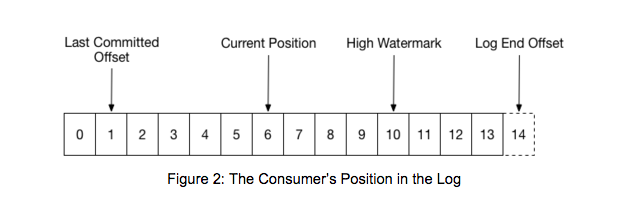
当一个partition被分配到group中的另外一个consumer时,初始化的位置是Last Committed Offset。如果本例中的consumer突然挂掉,这个group中的consumer将不得不从1(Last Committed Offset)开始消费数据,在这种情况下,offset为1~6的message将被重新处理。
图中也展示了在log中其他两个比较重要的位置信息,Log End Offset是写入log中的最新一条message的offset,而High Watermark是log中已经成功备份到其他replicas中的最新一条message的offset,也就是说Log End Offset与High Watermark之间的数据已经写入到log中,但是还未成功备份到其他的replicas中。从consuemr端来看,High Watermark是consumer可以消费的最后一条message的offset,这种机制会阻止Consumer读取那些未备份的message,因为这些message在后面可能会丢失。
Configuration and Initialization:配置与初始化
使用新版的Consumer,需要先在工程中添加kafka-clients依赖,添加的配置信息如下:
1 | <dependency> |
与其他的Kafka客户端一样,新版的Consumer也需要使用一个Properties文件来创建。下面例子中的配置,是对于一个Consumer group来说的几个必备的配置项
1 | Properties props = new Properties(); |
与旧的Consumer和Producer一样, 我们需要先配置一个brokers的初始列表,以便Consumer能够找到集群中其他的节点,这并不需要列出集群中的所有节点,客户端从列表中的broker中来找到全部的alive brokers,本例我们假设这台broker是运行在本地上的。Consumer也需要设置key和value反序列化的方式。最后,为了加入一个Consumer Group,也需要设置group id,它是group的一个标识符。在本文的下面,我们会介绍更多的配置选项。
这里也有一个问题需要思考,Kafka是如何通过初始的broker列表来找到Kafka集群所有的节点信息?
Topic Subscription:订阅Topic
开始消费前,必须首先配置出应用需要订阅的topic信息,下面的例子中,我们订阅了来自Topic为”foo”和”bar”的数据
1 | consumer.subscribe(Arrays.asList("foo", "bar")); |
开始订阅之后,Consumer可以与group的其他Consumer进行协调,来得到自己的partition分配,这个过程是在Consumer开始消费数据时自动进行的。下面,我们会展示如何使用assign API来手动进行partition分配,但是需要注意的是,Consumer中同时使用自动管理和手动管理是没有必要的。
subscribe方法是不能增加的:程序中必须包含想要消费的所有topic列表,你可以在任何时间改变你订阅的topic的集合,但是之前订阅的这些topic会被你使用subscribe方法调用的新的列表所取代。
Basic Poll Loop:基本的poll循环模型
Consumer需要支持并行地拉取数据,常见的情况就是从分布在不同broker上的多个topic的多个partition上拉取数据。为了实现这种情况,Kafka使用了一套类似于Unix中的poll或者select调用的API风格:一旦topic进行注册,未来所有的coordination、rebalance和数据拉取都是在一个event loop中通过一个单一的poll调用来触发的。这种实现方式是简单有效的,它可以处理来自单线程的所有IO。
思考:Consumer在调用
poll方法时处理逻辑是怎么样?
在订阅了一个topic之后,你需要启动一个event loop来获得partition分配并开始开始拉取数据,这听起来很复杂,但是你需要做的就是在一个循环中调用poll方法,然后Consumer会自动处理其他的所有的事情。每一次对于poll方法的调用都会返回一个从其所分配的partition上拉取的message集合(集合可能会空)。下面的例子展示了在一个基本的poll循环模型中打印Consumer拉取的mmessage的offset和value。
1 | try { |
这个pollAPI返回了根据Current Position拉取到的record。当group第一次创建时,这个位置是根据配置来进行设置的,可以被设置每个partition的最早或者最新的offset。但是一旦这个Consumer开始commit offset,之后的每次rebalance都会把position重置到Last Committed Offset位置。poll的这个参数是用来控制当Consumer在Current Position等待数据时block的最大时间,只要有任何record是可用的,Consumer就会立马返回,但是如果没有任何record是可用,Consumer将会等待一定的时长(被设置的时间)。
思考:新API中的record与旧API中的message有什么区别与联系?
Consumer最初被设计时就是运行在它自己的线程上,在多线程情况下使用时如果没有额外的同步机制它并不是线程安全的,而且也不推荐去尝试。在这个例子中,我们使用了一个flag(runnning),当应用关掉时它用于从poll循环中中断。当这个flag被其他线程(例如:关闭进程的线程)设置为false时,当poll返回时循环就会结束,而且无论是否返回record应用都会结束进程。
当Consumer进程结束时,你应该显式地关闭Consumer进程,这样不仅可以清除使用的socket,而且可以确保Consumer会向Coordinator发送它离开group的信息。
在上面的例子中,我们使用了较小的定时来确保在关闭Consumer时没有太多的延迟,或者,你也可以设置一个较长的定时,通过使用weakupAPI来从循环中中断。
1 | try { |
在这个例子中,我们将时长设置为了Long.MAX_VALUE,它意味着Consumer将会一直bolck直到下一批records返回。相比于前面例子中使用的flag,本例中线程通过调用consumer.wakeup()来中断poll循环,同时进程抛出一个WakeupException异常。这个API被其他线程调用是安全的,但值得注意的是:如果进程当前没有调用poll,这个异常会在下次调用时被抛出。在这个例子中,我们可以捕捉这个异常来阻止它继续传播。
思考:1.只要有数据,poll就立马返回吗?还是poll会等待一段时间或者一定消息量后返回?2.poll中设置的time参数在什么情况下起作用?如果拉取的消息为空,而时间又超出的话会出现什么情况?
Putting in all Together:一个完整的例子
在下面的例子中,我们创建一个简单的Runnable任务,它初始化这个Consumer、订阅一个topic的列表,并且一直执行poll循环除非遇到外部触发结束进程。
1 | public class ConsumerLoop implements Runnable { |
为了测试这个示例,需要有一个运行0.9.0版Kafka的broker,并且需要一个有一些待消费数据的topic,向一个topic写入数据的最简单的办法是使用kafka-verifiable-producer.sh脚本。为了确保实验更有趣,我们将topic设置为多个partition,这样的话就不用使一个parition去做所有的工作了。在本例中,Kafka的broker和Zookeeper都运行在本地,你可以在一个Kafka根目录下键入以下命令进行设置topic和partiion。
1 | # bin/kafka-topics.sh --create --topic consumer-tutorial --replication-factor 1 --partitions 3 --zookeeper localhost:2181 |
然后我们创建了一个有三个成员的consumer group,这个group来订阅我们刚才创建的那个topic
1 | public static void main(String[] args) { |
这个例子向一个executor提交三个consumer,每一个线程都分配了一个唯一的id,便于我们清楚是哪个线程在接收数据。当进程停止时,shutdown的Hook将被触发,它将使用weakup中断这三个线程,并且等待它们关闭。如果你运行这个程序,你将会看到所有这些线程接收到数据,下面是运行之后的输出例子:
1 | 2: {partition=0, offset=928, value=2786} |
这个输出展示三个partition的消费情况,每一个partition都被安排到其中的一个线程上。在每个partition中,你都会看到offset如期望中的一样在不断增加,你可以使用命令行或者IDE中的Ctrl+C关闭这个进程。
Consumer Liveness:Consumer存活
Group中每一个Consumer都被安排它订阅topic的partitions的一个子集,group会使用一个group锁在这些partition上。只要这些锁还被持有,其他的Consumer成员就不能从这些partition上读取数据。如果这些Consumer运行正常,这种情况就是我们想要的结果,这也是避免重复读消费数据的唯一办法。但是如果由于节点或者程序故障造成Consumer异常退出时,你需要能够释放这些锁,以便这些partition可以被安排到其他健康的Consumer上。
Kafka的group coordination protocol通过心跳机制来解决这个问题(Consumer通过心跳机制来实现持有锁和释放锁),在每一次rebalance之后,当前group中的所有Consumer都会定期向group的coordinator发送心跳信息,如果可以收到这个Consumer的心跳信息,就证明这个Consumer是正常的。一旦收到心跳信息,这个coordinator会重新开始计时。如果定时到了而还没有收到心跳信息,coordinator将会把这个consumer标记为dead,并且会向group的其他成员发送信号,这样就会进行rebalance操作,从而重新对这些partition进行分配。定时的时长就是session 时长,它可以通过客户端的session.timeout.ms这个参数来设置
1 | props.put("session.timeout.ms", "60000"); |
session时长机制可以确保如果遇到节点或者应用崩亏、或者网络把consumer从group中隔离的情况,锁会被释放。但是,通常应用失败的情况处理起来有点麻烦,因为即使Consumer仍然向coordinator发送心跳信息也不能证明应用是正常运行的。
Consumer的poll循环是被设置为解决这个问题,当你调用poll方法或者其他的阻塞的API时所有的网络IO就已经完成。而且Consumer并不会在后台调用任何其他线程,这就意味着心跳信息只是在调用poll方法时发送给coordinator的。如果因为处理代码的逻辑部分抛出异常或者下游系统崩溃而造成应用停止poll方法调用,那么也会造成没有任何心跳被发送,然后session定时就会超时,这个group就会进行rebalance操作。
如果一个consumer在给定的时间内没有发送心跳信息,这种机制就会被触发一个虚假的rebalance操作。当然可以通过将定时设置足够大来避免这种情况的发生,它默认的时长是30s,但是它没有必要的将时长设置高达几分钟。设置为更长时长的一个问题就是它需要花费更多的时间来发现失败的Consumer。
Delivery Semantics:可靠的消息传递
当一个consumer group刚开始被创建的时候,最初的offset是通过auto.offset.reset配置项来进行设置的。一旦Consumer开始处理数据,它根据应用的需要来定期地对offset进行commit。在每一次的rebalance之后,group会将这个offset将被设置为Last Committed Offset。但如果consumer在对已经处理过的message进行commit之前挂掉了,另外一个Consumer最终会重复处理这些已经处理但未commit的数据。应用中对offset进行commit越频繁,在一次崩溃后你重复消费的数据就会越少。
在前面的例子中,我们都已经设置了自动提交机制,当把enable.auto.commit设置为true(default)时,Consumer会周期性地自动触发的offset commit机制,这个时长可以通过auto.commit.interval.ms来进行配置。通过减少这个间隔,我们可以限制当崩溃发生时Consumer重新处理的数据量。
如果要使用consumer的commit API,首先需要在配置文件中将enable.auto.commit设置为false,来禁止自动commit
1 | props.put("enable.auto.commit", "false"); |
这个commit API使用起来非常简单,难点在于如何与poll循环配合使用。下面的例子,主体中包含了commit细节实现的完整的poll循环。调用同步commit的API是处理手动提交的最简单的方法。
1 | try { |
使用无参的commitSyncAPI进行commit的offset是在调用poll后返回的,因为是同步commit,所以这个调用将会被一直block直到commit成功或者因为不可恢复的错误而失败。处理过程中,需要特别注意的是message处理的时间大于session时长的这种情况,如果这种情况发生,coordinator就会把这个consumer踢出这个group,它会导致抛出CommitFailedException异常。应用程序应该能够处理这种错误,并对由于消费自从上一次成功提交后的message造成的变化进行回滚操作。
一般情况下,你应该确保message被成功处理后,这个offset被commit了。但是如果在commit被发送之前consumer挂掉了,然后这些messages就会被重复处理。如果这个commit机制保证Last Committed Offset不会超过Current Position(如图2所示,上图,非下图),然后系统就会保证at least once消息传递机制。
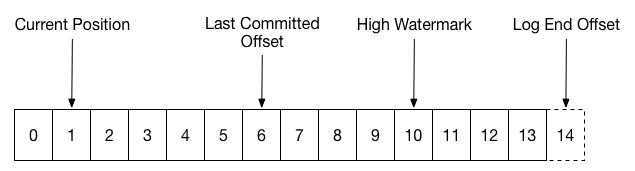
通过改变commit机制来保证Current Position不会超过Last Committed Offset,如上图所示,你将会得到at most once消息传递保证。如果在Current Position赶上Last Committed Offset之前consumer挂掉了,这段时间内的所有messages都会丢失,但是可以确定是没有消息会处理超过一次。为了实现这个机制,我们只需要改变commit和消息处理的顺序。
1 | try { |
要注意的是,如果使用默认的自动commit机制,系统是保证at least once消息处理,因为offset是在这些messages被应用处理后才进行commit的。在最糟糕的情况下,系统不得不重新处理的消息数量是由自动commit的间隔决定的(可以通过auto.commit.interval.ms设置)。
思考:为什么kafka不能保证exactly once?
通过应用commit API,你可以对重复处理的消息量进行更细的控制,在更极端的情况下,你甚至可以在每一条消息被处理后都进行commit,如下面的例子所示
1 | try { |
在这个例子中,我们调用commitSync方法通过对明确的offset进行commit,要注意的是,要进行commit的offset应该是应用将要读取的下一条消息的offset。当commitSync方法被无参调用时,这个consumer对应用返回的Last Offset(+1)进行commit,但是在这里并不能使用,因为我们不允许The Committed Position超过我们实际的处理位置(Current Position)。
由于处理线程在每次进行commit请求并等待服务器返回这个过程中需要进行加锁,很明显对于大多数的应用场景,这种设计并不适用,这种设计会严重影响到consumer的吞吐量。更合理的设计是每接收N条消息后再进行commit,为了更高的吞吐量N的值可以进行调整。
本例中commitSync方法的参数是一个map的数据结构,key为topic partition,value为OffsetAndMetadata的实例。Commit API允许在每次commit时包含一些额外的元数据信息,这些数据信息可以是record进行commit的时间、要发送的host、或者应用程序中需要的任何其他信息,在本例中,我们并没有添加这个额外信息。
相比于对每接收一条message就进行commit,一个更加合理的机制是当你处理完每个partition的数据后进行commit offset。ConsumerRecords集合类提供了获取它内部每个partition集合以及每个partition内数据的方法。下面的例子详细描述这种机制:
1 | try { |
截止到目前为止,我们主要研究的是同步commit的API,但是consumer也提供了异步提交的API——commitAsync。使用异步commit一般情况下会提高系统的吞吐量,因为应用可以在commit结果还未返回时就能开始处理下一批的message。但是你可能在之后才会发现commit失败了,这是需要开发者进行权衡。下面的例子是异步commit的基本用法。
1 | try { |
在本例中,在commitAsync中我们提供了回调方法,这个方法只会在commit完成后(不管成功还是失败)才会被consumer触发。如果你不需要这个设置,你也可以使用无参的commitAsyncAPI。
思考:在进行commit时,如果commit失败,consumer会怎么处理,同步与异步的处理过程是一样的吗?
Consumer Group Inspection:consumer group查看
当一个consuemr group是active,你可以通过在命令行运行consumer-groups.sh脚本来查看partition assignment和group消费情况,这个脚本存放在Kafka的bin目录下
1 | # bin/kafka-consumer-groups.sh --new-consumer --describe --group consumer-tutorial-group --bootstrap-server localhost:9092 |
输出的结果如下所示
1 | GROUP, TOPIC, PARTITION, CURRENT OFFSET, LOG END OFFSET, LAG, OWNER |
上面的结果展示了这个consumer group的partition分配以及哪个consumer实例消费这个partition,还有Last Committed Offset(这里也可以认为是Current Offset)。每个partition的lag就是这个partition的最后offset与Last Committed Offset的差值。Administrators会一直进行监控以确保consuemr group能跟得上producers。
Using Manual Assignment:使用手动的assign
正如本文开始所述的一样,新的Consumer实现了对那些不需要group的场景进行更细粒度的控制,对这种场景的支持是建议使用新Consumer API的重要原因之一。旧的simple consumer虽然也提供这样的设计,但是却需要你自己做很多的容错处理。而新的Consumer API,你只需要提供了你需要读取的topic的partition,然后就可以开始读取数据,其他的东西Consumer会帮你处理。
下面的例子展示了如何使用partitionsFor API来分配安排一个topic的所有partition
1 | List<TopicPartition> partitions = new ArrayList<>(); |
和subscribe方法相似,调用assign方法时必须传入consuemr要读取的所有parition的集合,一旦partition被分配了,poll循环部分就与前面的过程基本一样。
有一点需要的注意的是,不管是一个simple consumer还是一个consumer group,所有offset的commit都必须经过group coordinator。因此,如果你需要进行commit,你必须设置一个合适的group.id,避免与其他的group产生冲突。如果一个simple consumer试图使用一个与一个active group相同的id进行commit offset,coordinator将会拒绝这个commit请求,会返回一个CommitFailedException异常。但是,如果一个simple consumer与另一个simple consumer使用同一个id,系统就不会报任何错误。
Conclusion:结论
新的Consumer给Kafka社区带了很多的好处,比如,简洁的API、更好的安全性和对ZK更少的依赖。本文介绍了new consumer的基本用法,并注重于poll循环模型以及使用commit API来控制传递机制。虽然还有很多需要讨论的地方,但是本文对于基本的使用是足够了。尽管新的comsumer还在开发中,但是我们仍然鼓励你去尝试使用。使用中如果遇到什么问题,欢迎通过邮件告诉我们.
参考
