/** * Set-up a fetch request for any node that we have assigned partitions for which doesn't already have * an in-flight fetch or pending fetch data. * @return number of fetches sent */ //note: 向订阅的所有 partition (只要该 leader 暂时没有拉取请求)所在 leader 发送 fetch请求 publicintsendFetches(){ //note: 1 创建 Fetch Request Map<Node, FetchRequest.Builder> fetchRequestMap = createFetchRequests(); for (Map.Entry<Node, FetchRequest.Builder> fetchEntry : fetchRequestMap.entrySet()) { final FetchRequest.Builder request = fetchEntry.getValue(); final Node fetchTarget = fetchEntry.getKey();
/** * Create fetch requests for all nodes for which we have assigned partitions * that have no existing requests in flight. */ //note: 为所有 node 创建 fetch request private Map<Node, FetchRequest.Builder> createFetchRequests() { // create the fetch info Cluster cluster = metadata.fetch(); Map<Node, LinkedHashMap<TopicPartition, FetchRequest.PartitionData>> fetchable = new LinkedHashMap<>(); for (TopicPartition partition : fetchablePartitions()) { Node node = cluster.leaderFor(partition); if (node == null) { metadata.requestUpdate(); } elseif (this.client.pendingRequestCount(node) == 0) { // if there is a leader and no in-flight requests, issue a new fetch LinkedHashMap<TopicPartition, FetchRequest.PartitionData> fetch = fetchable.get(node); if (fetch == null) { fetch = new LinkedHashMap<>(); fetchable.put(node, fetch); }
long position = this.subscriptions.position(partition); //note: 要 fetch 的 position 以及 fetch 的大小 fetch.put(partition, new FetchRequest.PartitionData(position, this.fetchSize)); log.trace("Added fetch request for partition {} at offset {} to node {}", partition, position, node); } else { log.trace("Skipping fetch for partition {} because there is an in-flight request to {}", partition, node); } }
//note: 构造 Fetch 请求 protecteddefbuildFetchRequest(partitionMap: Seq[(TopicPartition, PartitionFetchState)]): FetchRequest = { val requestMap = new util.LinkedHashMap[TopicPartition, JFetchRequest.PartitionData]
partitionMap.foreach { case (topicPartition, partitionFetchState) => // We will not include a replica in the fetch request if it should be throttled. if (partitionFetchState.isActive && !shouldFollowerThrottle(quota, topicPartition)) requestMap.put(topicPartition, newJFetchRequest.PartitionData(partitionFetchState.offset, fetchSize)) } //note: 关键在于 setReplicaId 方法,设置了 replicaId, consumer 的该值为 CONSUMER_REPLICA_ID(-1) val requestBuilder = newJFetchRequest.Builder(maxWait, minBytes, requestMap). setReplicaId(replicaId).setMaxBytes(maxBytes) requestBuilder.setVersion(fetchRequestVersion) newFetchRequest(requestBuilder) }
// the callback for sending a fetch response defsendResponseCallback(responsePartitionData: Seq[(TopicPartition, FetchPartitionData)]) { .... deffetchResponseCallback(delayTimeMs: Int) { trace(s"Sending fetch response to client $clientId of " + s"${convertedPartitionData.map { case (_, v) => v.records.sizeInBytes }.sum} bytes") val fetchResponse = if (delayTimeMs > 0) newFetchResponse(versionId, fetchedPartitionData, delayTimeMs) else response requestChannel.sendResponse(newRequestChannel.Response(request, fetchResponse)) }
// When this callback is triggered, the remote API call has completed request.apiRemoteCompleteTimeMs = time.milliseconds
//note: 配额情况的处理 if (fetchRequest.isFromFollower) { // We've already evaluated against the quota and are good to go. Just need to record it now. val responseSize = sizeOfThrottledPartitions(versionId, fetchRequest, mergedPartitionData, quotas.leader) quotas.leader.record(responseSize) fetchResponseCallback(0) } else { quotas.fetch.recordAndMaybeThrottle(request.session.sanitizedUser, clientId, response.sizeOf, fetchResponseCallback) } }
if (authorizedRequestInfo.isEmpty) sendResponseCallback(Seq.empty) else { // call the replica manager to fetch messages from the local replica //note: 从 replica 上拉取数据,满足条件后调用回调函数进行返回 replicaManager.fetchMessages( fetchRequest.maxWait.toLong, //note: 拉取请求最长的等待时间 fetchRequest.replicaId, //note: Replica 编号,Consumer 的为 -1 fetchRequest.minBytes, //note: 拉取请求设置的最小拉取字节 fetchRequest.maxBytes, //note: 拉取请求设置的最大拉取字节 versionId <= 2, authorizedRequestInfo, replicationQuota(fetchRequest), sendResponseCallback) } }
/** * Fetch messages from the leader replica, and wait until enough data can be fetched and return; * the callback function will be triggered either when timeout or required fetch info is satisfied */ //note: 从 leader 拉取数据,等待拉取到足够的数据或者达到 timeout 时间后返回拉取的结果 deffetchMessages(timeout: Long, replicaId: Int, fetchMinBytes: Int, fetchMaxBytes: Int, hardMaxBytesLimit: Boolean, fetchInfos: Seq[(TopicPartition, PartitionData)], quota: ReplicaQuota = UnboundedQuota, responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit) { val isFromFollower = replicaId >= 0//note: 判断请求是来自 consumer (这个值为 -1)还是副本同步 //note: 默认都是从 leader 拉取,推测这个值只是为了后续能从 follower 消费数据而设置的 val fetchOnlyFromLeader: Boolean = replicaId != Request.DebuggingConsumerId //note: 如果拉取请求来自 consumer(true),只拉取 HW 以内的数据,如果是来自 Replica 同步,则没有该限制(false)。 val fetchOnlyCommitted: Boolean = ! Request.isValidBrokerId(replicaId)
// if the fetch comes from the follower, // update its corresponding log end offset //note: 如果 fetch 来自 broker 的副本同步,那么就更新相关的 log end offset if(Request.isValidBrokerId(replicaId)) updateFollowerLogReadResults(replicaId, logReadResults)
// check if this fetch request can be satisfied right away val logReadResultValues = logReadResults.map { case (_, v) => v } val bytesReadable = logReadResultValues.map(_.info.records.sizeInBytes).sum val errorReadingData = logReadResultValues.foldLeft(false) ((errorIncurred, readResult) => errorIncurred || (readResult.error != Errors.NONE))
// respond immediately if 1) fetch request does not want to wait // 2) fetch request does not require any data // 3) has enough data to respond // 4) some error happens while reading data //note: 如果满足以下条件的其中一个,将会立马返回结果: //note: 1. timeout 达到; 2. 拉取结果为空; 3. 拉取到足够的数据; 4. 拉取是遇到 error if (timeout <= 0 || fetchInfos.isEmpty || bytesReadable >= fetchMinBytes || errorReadingData) { val fetchPartitionData = logReadResults.map { case (tp, result) => tp -> FetchPartitionData(result.error, result.hw, result.info.records) } responseCallback(fetchPartitionData) } else { //note: 其他情况下,延迟发送结果 // construct the fetch results from the read results val fetchPartitionStatus = logReadResults.map { case (topicPartition, result) => val fetchInfo = fetchInfos.collectFirst { case (tp, v) if tp == topicPartition => v }.getOrElse(sys.error(s"Partition $topicPartition not found in fetchInfos")) (topicPartition, FetchPartitionStatus(result.info.fetchOffsetMetadata, fetchInfo)) } val fetchMetadata = FetchMetadata(fetchMinBytes, fetchMaxBytes, hardMaxBytesLimit, fetchOnlyFromLeader, fetchOnlyCommitted, isFromFollower, replicaId, fetchPartitionStatus) val delayedFetch = newDelayedFetch(timeout, fetchMetadata, this, quota, responseCallback)
// create a list of (topic, partition) pairs to use as keys for this delayed fetch operation val delayedFetchKeys = fetchPartitionStatus.map { case (tp, _) => newTopicPartitionOperationKey(tp) }
// try to complete the request immediately, otherwise put it into the purgatory; // this is because while the delayed fetch operation is being created, new requests // may arrive and hence make this operation completable. delayedFetchPurgatory.tryCompleteElseWatch(delayedFetch, delayedFetchKeys) } }
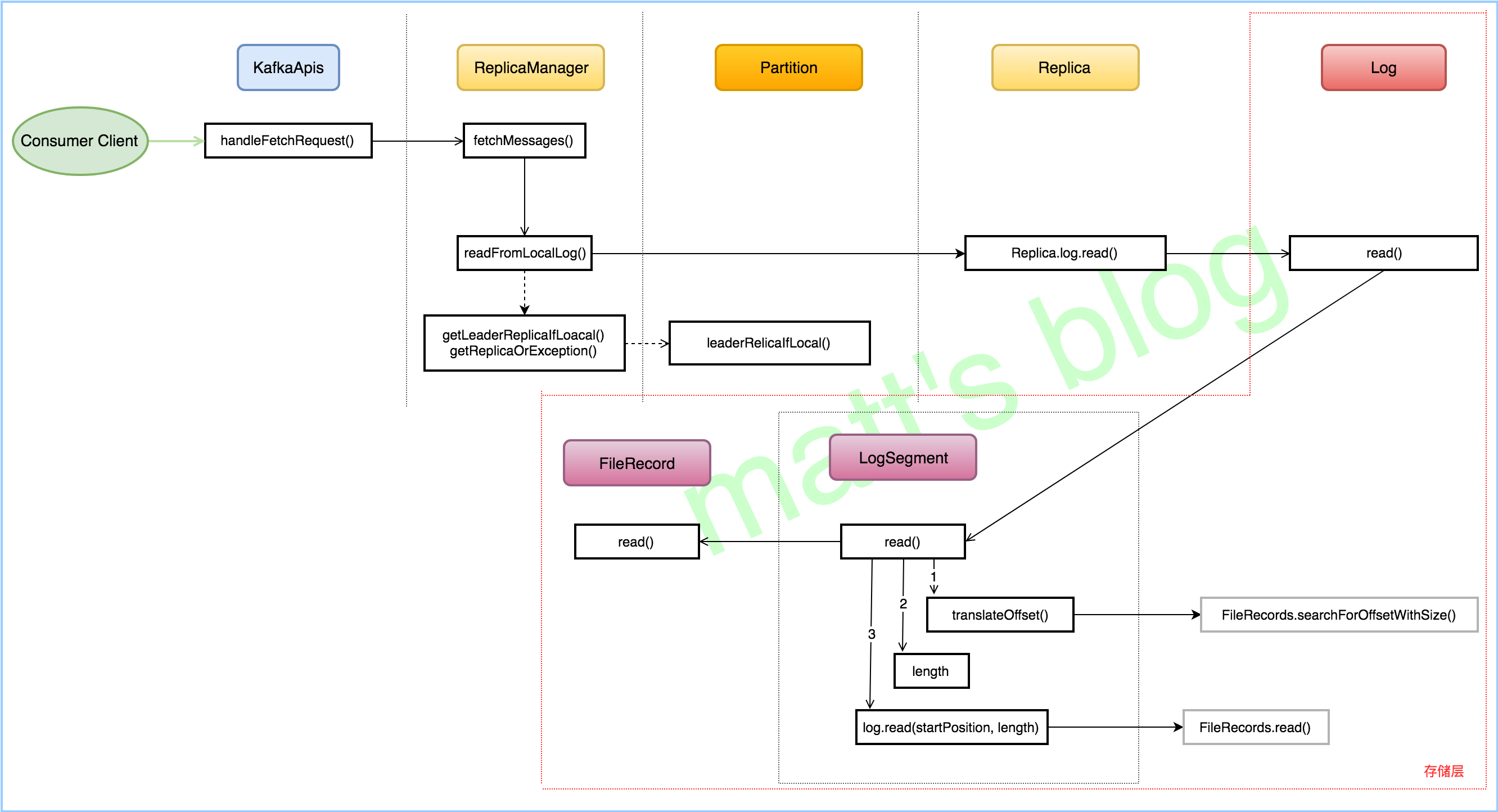
整体来说,分为以下几步:
readFromLocalLog():调用该方法,从本地日志拉取相应的数据;
判断 Fetch 请求来源,如果来自副本同步,那么更新该副本的 the end offset 记录,如果该副本不在 isr 中,并判断是否需要更新 isr;
// decide whether to only fetch from leader //note: 根据决定 [是否只从 leader 读取数据] 来获取相应的副本 //note: 根据 tp 获取 Partition 对象, 在获取相应的 Replica 对象 val localReplica = if (fetchOnlyFromLeader) getLeaderReplicaIfLocal(tp) else getReplicaOrException(tp)
// decide whether to only fetch committed data (i.e. messages below high watermark) //note: 获取 hw 位置,副本同步不设置这个值 val maxOffsetOpt = if (readOnlyCommitted) Some(localReplica.highWatermark.messageOffset) else None
/* Read the LogOffsetMetadata prior to performing the read from the log. * We use the LogOffsetMetadata to determine if a particular replica is in-sync or not. * Using the log end offset after performing the read can lead to a race condition * where data gets appended to the log immediately after the replica has consumed from it * This can cause a replica to always be out of sync. */ val initialLogEndOffset = localReplica.logEndOffset.messageOffset //note: the end offset val initialHighWatermark = localReplica.highWatermark.messageOffset //note: hw val fetchTimeMs = time.milliseconds val logReadInfo = localReplica.log match { caseSome(log) => val adjustedFetchSize = math.min(partitionFetchSize, limitBytes)
// Try the read first, this tells us whether we need all of adjustedFetchSize for this partition //note: 从指定的 offset 位置开始读取数据,副本同步不需要 maxOffsetOpt val fetch = log.read(offset, adjustedFetchSize, maxOffsetOpt, minOneMessage)
// If the partition is being throttled, simply return an empty set. if (shouldLeaderThrottle(quota, tp, replicaId)) //note: 如果被限速了,那么返回 空 集合 FetchDataInfo(fetch.fetchOffsetMetadata, MemoryRecords.EMPTY) // For FetchRequest version 3, we replace incomplete message sets with an empty one as consumers can make // progress in such cases and don't need to report a `RecordTooLargeException` elseif (!hardMaxBytesLimit && fetch.firstEntryIncomplete) FetchDataInfo(fetch.fetchOffsetMetadata, MemoryRecords.EMPTY) else fetch
caseNone => error(s"Leader for partition $tp does not have a local log") FetchDataInfo(LogOffsetMetadata.UnknownOffsetMetadata, MemoryRecords.EMPTY) }
//note: 返回最后的结果,返回的都是 LogReadResult 对象 LogReadResult(info = logReadInfo, hw = initialHighWatermark, leaderLogEndOffset = initialLogEndOffset, fetchTimeMs = fetchTimeMs, readSize = partitionFetchSize, exception = None) } catch { // NOTE: Failed fetch requests metric is not incremented for known exceptions since it // is supposed to indicate un-expected failure of a broker in handling a fetch request case e@ (_: UnknownTopicOrPartitionException | _: NotLeaderForPartitionException | _: ReplicaNotAvailableException | _: OffsetOutOfRangeException) => LogReadResult(info = FetchDataInfo(LogOffsetMetadata.UnknownOffsetMetadata, MemoryRecords.EMPTY), hw = -1L, leaderLogEndOffset = -1L, fetchTimeMs = -1L, readSize = partitionFetchSize, exception = Some(e)) case e: Throwable => BrokerTopicStats.getBrokerTopicStats(tp.topic).failedFetchRequestRate.mark() BrokerTopicStats.getBrokerAllTopicsStats().failedFetchRequestRate.mark() error(s"Error processing fetch operation on partition $tp, offset $offset", e) LogReadResult(info = FetchDataInfo(LogOffsetMetadata.UnknownOffsetMetadata, MemoryRecords.EMPTY), hw = -1L, leaderLogEndOffset = -1L, fetchTimeMs = -1L, readSize = partitionFetchSize, exception = Some(e)) } }
var limitBytes = fetchMaxBytes val result = new mutable.ArrayBuffer[(TopicPartition, LogReadResult)] var minOneMessage = !hardMaxBytesLimit readPartitionInfo.foreach { case (tp, fetchInfo) => val readResult = read(tp, fetchInfo, limitBytes, minOneMessage) //note: 读取该 tp 的数据 val messageSetSize = readResult.info.records.sizeInBytes // Once we read from a non-empty partition, we stop ignoring request and partition level size limits if (messageSetSize > 0) minOneMessage = false limitBytes = math.max(0, limitBytes - messageSetSize) result += (tp -> readResult) } result }
// Because we don't use lock for reading, the synchronization is a little bit tricky. // We create the local variables to avoid race conditions with updates to the log. val currentNextOffsetMetadata = nextOffsetMetadata val next = currentNextOffsetMetadata.messageOffset if(startOffset == next) returnFetchDataInfo(currentNextOffsetMetadata, MemoryRecords.EMPTY)
//note: 先查找对应的日志分段(segment) var entry = segments.floorEntry(startOffset)
// attempt to read beyond the log end offset is an error if(startOffset > next || entry == null) thrownewOffsetOutOfRangeException("Request for offset %d but we only have log segments in the range %d to %d.".format(startOffset, segments.firstKey, next))
// Do the read on the segment with a base offset less than the target offset // but if that segment doesn't contain any messages with an offset greater than that // continue to read from successive segments until we get some messages or we reach the end of the log while(entry != null) { // If the fetch occurs on the active segment, there might be a race condition where two fetch requests occur after // the message is appended but before the nextOffsetMetadata is updated. In that case the second fetch may // cause OffsetOutOfRangeException. To solve that, we cap the reading up to exposed position instead of the log // end of the active segment. //note: 如果 Fetch 请求刚好发生在 the active segment 上,当多个 Fetch 请求同时处理,如果 nextOffsetMetadata 更新不及时,可能会导致 //note: 发送 OffsetOutOfRangeException 异常; 为了解决这个问题, 这里能读取的最大位置是对应的物理位置(exposedPos) //note: 而不是 the log end of the active segment. val maxPosition = { if (entry == segments.lastEntry) { //note: nextOffsetMetadata 对应的实际物理位置 val exposedPos = nextOffsetMetadata.relativePositionInSegment.toLong // Check the segment again in case a new segment has just rolled out. if (entry != segments.lastEntry) //note: 可能会有新的 segment 产生,所以需要再次判断 // New log segment has rolled out, we can read up to the file end. entry.getValue.size else exposedPos } else { entry.getValue.size } } //note: 从 segment 中读取相应的数据 val fetchInfo = entry.getValue.read(startOffset, maxOffset, maxLength, maxPosition, minOneMessage) if(fetchInfo == null) { //note: 如果该日志分段没有读取到数据,则读取更高的日志分段 entry = segments.higherEntry(entry.getKey) } else { return fetchInfo } }
// okay we are beyond the end of the last segment with no data fetched although the start offset is in range, // this can happen when all messages with offset larger than start offsets have been deleted. // In this case, we will return the empty set with log end offset metadata FetchDataInfo(nextOffsetMetadata, MemoryRecords.EMPTY) }
//note: 读取日志分段(副本同步不会设置 maxSize) defread(startOffset: Long, maxOffset: Option[Long], maxSize: Int, maxPosition: Long = size, minOneMessage: Boolean = false): FetchDataInfo = { if (maxSize < 0) thrownewIllegalArgumentException("Invalid max size for log read (%d)".format(maxSize))
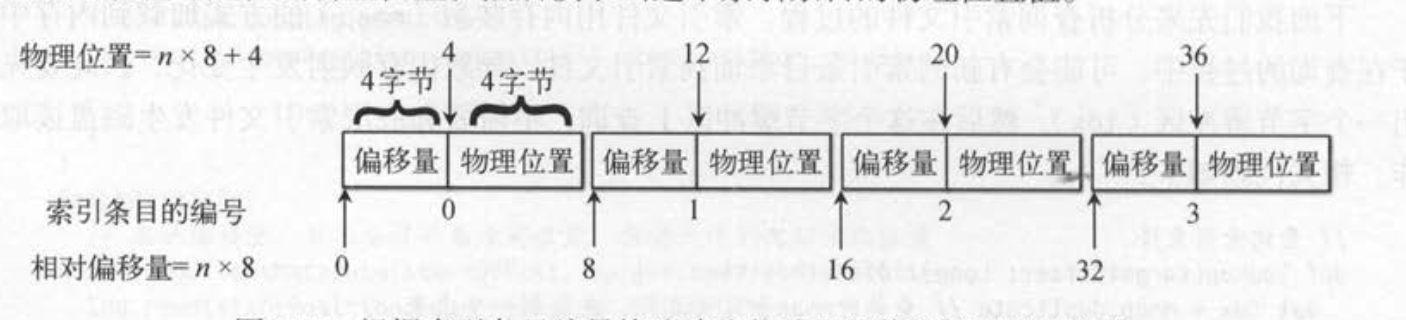
//note: log 文件物理长度 val logSize = log.sizeInBytes // this may change, need to save a consistent copy //note: 将起始的 offset 转换为起始的实际物理位置 val startOffsetAndSize = translateOffset(startOffset)
// if the start position is already off the end of the log, return null if (startOffsetAndSize == null) returnnull
val startPosition = startOffsetAndSize.position.toInt val offsetMetadata = newLogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize = if (minOneMessage) math.max(maxSize, startOffsetAndSize.size) else maxSize
// return a log segment but with zero size in the case below if (adjustedMaxSize == 0) returnFetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
// calculate the length of the message set to read based on whether or not they gave us a maxOffset //note: 计算读取的长度 val length = maxOffset match { //note: 副本同步时的计算方式 caseNone => // no max offset, just read until the max position min((maxPosition - startPosition).toInt, adjustedMaxSize) //note: 直接读取到最大的位置 //note: consumer 拉取时,计算方式 caseSome(offset) => // there is a max offset, translate it to a file position and use that to calculate the max read size; // when the leader of a partition changes, it's possible for the new leader's high watermark to be less than the // true high watermark in the previous leader for a short window. In this window, if a consumer fetches on an // offset between new leader's high watermark and the log end offset, we want to return an empty response. if (offset < startOffset) returnFetchDataInfo(offsetMetadata, MemoryRecords.EMPTY, firstEntryIncomplete = false) val mapping = translateOffset(offset, startPosition) val endPosition = if (mapping == null) logSize // the max offset is off the end of the log, use the end of the file else mapping.position min(min(maxPosition, endPosition) - startPosition, adjustedMaxSize).toInt }
/** * Search forward for the file position of the last offset that is greater than or equal to the target offset * and return its physical position and the size of the message (including log overhead) at the returned offset. If * no such offsets are found, return null. * * @param targetOffset The offset to search for. * @param startingPosition The starting position in the file to begin searching from. */ public LogEntryPosition searchForOffsetWithSize(long targetOffset, int startingPosition) { for (FileChannelLogEntry entry : shallowEntriesFrom(startingPosition)) { long offset = entry.offset(); if (offset >= targetOffset) returnnewLogEntryPosition(offset, entry.position(), entry.sizeInBytes()); } returnnull; }