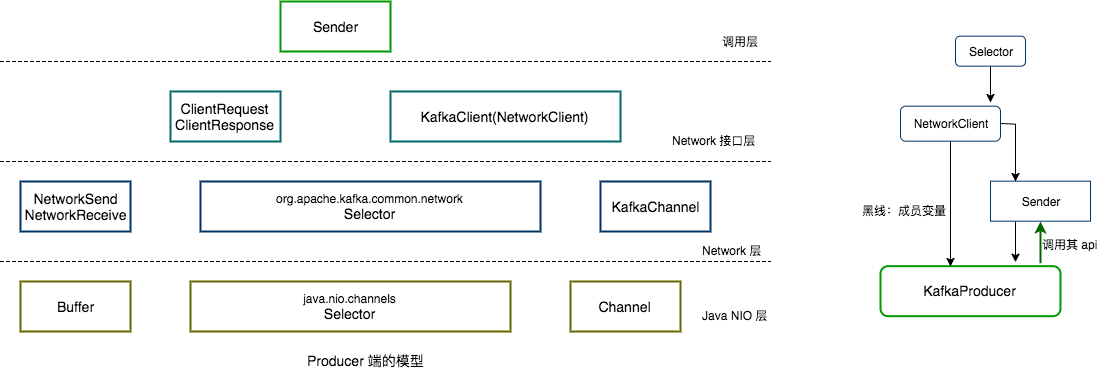
// org.apache.kafka.clients.producer.internals.Sender /** * Wake up the selector associated with this send thread */ publicvoidwakeup(){ this.client.wakeup(); }
// org.apache.kafka.clients.NetworkClient /** * Interrupt the client if it is blocked waiting on I/O. */ @Override publicvoidwakeup(){ this.selector.wakeup(); }
// org.apache.kafka.common.network.Selector /** * Interrupt the nioSelector if it is blocked waiting to do I/O. */ //note: 如果 selector 是阻塞的话,就唤醒 @Override publicvoidwakeup(){ this.nioSelector.wakeup(); }
long endIo = time.nanoseconds(); this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());
// we use the time at the end of select to ensure that we don't close any connections that // have just been processed in pollSelectionKeys //note: 每次 poll 之后会调用一次 //TODO: 连接虽然关闭了,但是 Client 端的缓存依然存在 maybeCloseOldestConnection(endSelect); }
// register all per-connection metrics at once sensors.maybeRegisterConnectionMetrics(channel.id()); if (idleExpiryManager != null) idleExpiryManager.update(channel.id(), currentTimeNanos);
try {
/* complete any connections that have finished their handshake (either normally or immediately) */ //note: 处理一些刚建立 tcp 连接的 channel if (isImmediatelyConnected || key.isConnectable()) { if (channel.finishConnect()) {//note: 连接已经建立 this.connected.add(channel.id()); this.sensors.connectionCreated.record(); SocketChannel socketChannel = (SocketChannel) key.channel(); log.debug("Created socket with SO_RCVBUF = {}, SO_SNDBUF = {}, SO_TIMEOUT = {} to node {}", socketChannel.socket().getReceiveBufferSize(), socketChannel.socket().getSendBufferSize(), socketChannel.socket().getSoTimeout(), channel.id()); } else continue; }
/* if channel is not ready finish prepare */ //note: 处理 tcp 连接还未完成的连接,进行传输层的握手及认证 if (channel.isConnected() && !channel.ready()) channel.prepare();
/* if channel is ready read from any connections that have readable data */ if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) { NetworkReceive networkReceive; while ((networkReceive = channel.read()) != null)//note: 知道读取一个完整的 Receive,才添加到集合中 addToStagedReceives(channel, networkReceive);//note: 读取数据 }
/* if channel is ready write to any sockets that have space in their buffer and for which we have data */ if (channel.ready() && key.isWritable()) { Send send = channel.write(); if (send != null) { this.completedSends.add(send);//note: 将完成的 send 添加到 list 中 this.sensors.recordBytesSent(channel.id(), send.size()); } }
/* cancel any defunct sockets */ //note: 关闭断开的连接 if (!key.isValid()) close(channel, true);
} catch (Exception e) { String desc = channel.socketDescription(); if (e instanceof IOException) log.debug("Connection with {} disconnected", desc, e); else log.warn("Unexpected error from {}; closing connection", desc, e); close(channel, true); } } }
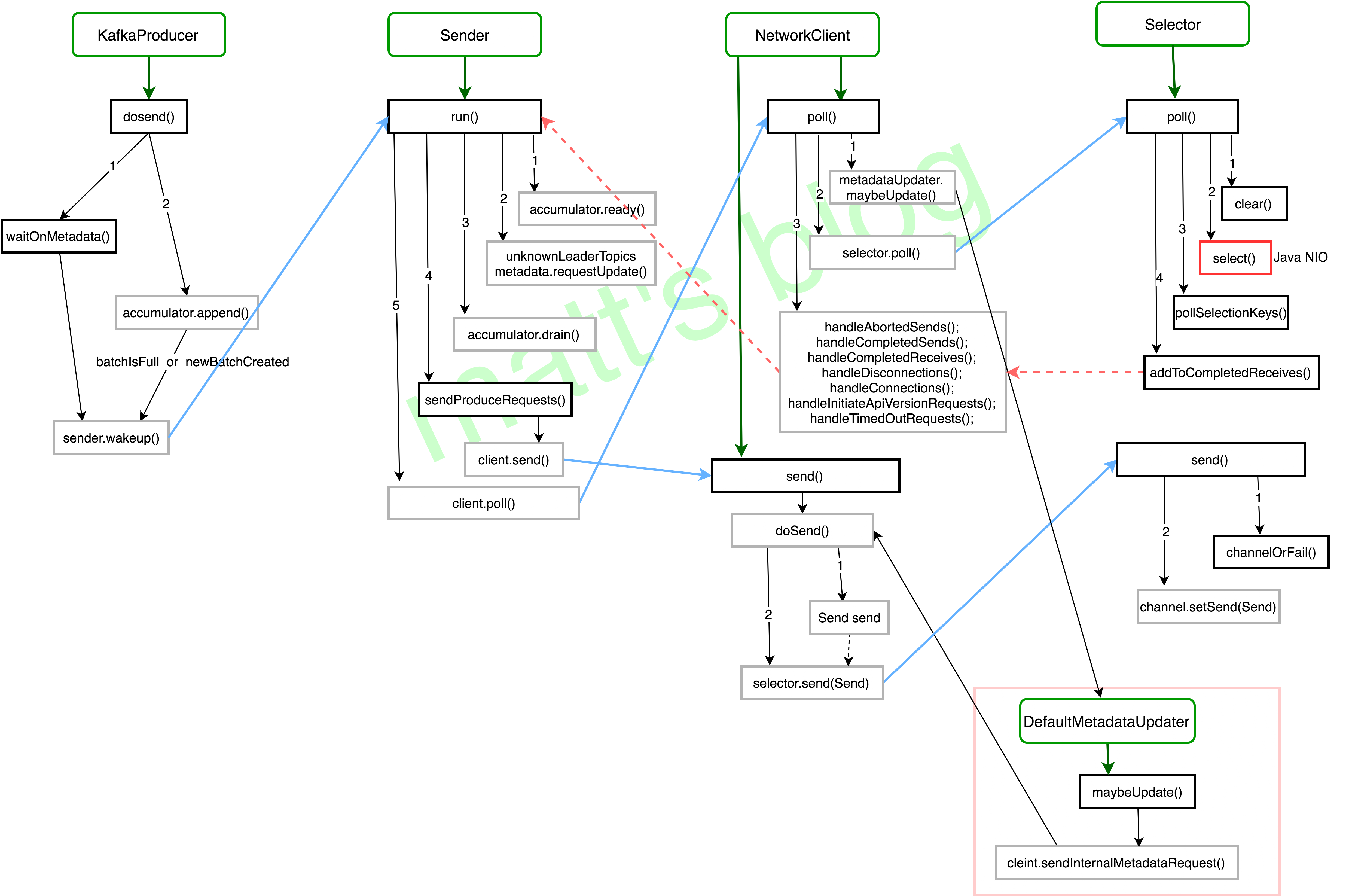
addToCompletedReceives()
这个方法的目的是处理接收到的 Receive,由于 Selector 这个类在 Client 和 Server 端都会调用,这里分两种情况讲述一下:
/** * checks if there are any staged receives and adds to completedReceives */ privatevoidaddToCompletedReceives(){ if (!this.stagedReceives.isEmpty()) {//note: 处理 stagedReceives Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this.stagedReceives.entrySet().iterator(); while (iter.hasNext()) { Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next(); KafkaChannel channel = entry.getKey(); if (!channel.isMute()) { Deque<NetworkReceive> deque = entry.getValue(); addToCompletedReceives(channel, deque); if (deque.isEmpty()) iter.remove(); } } } }
//note: 发送请求 privatevoiddoSend(ClientRequest clientRequest, boolean isInternalRequest, long now){ String nodeId = clientRequest.destination(); if (!isInternalRequest) { // If this request came from outside the NetworkClient, validate // that we can send data. If the request is internal, we trust // that that internal code has done this validation. Validation // will be slightly different for some internal requests (for // example, ApiVersionsRequests can be sent prior to being in // READY state.) if (!canSendRequest(nodeId)) thrownew IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready."); } AbstractRequest request = null; AbstractRequest.Builder<?> builder = clientRequest.requestBuilder(); //note: 构建 AbstractRequest, 检查其版本信息 try { NodeApiVersions versionInfo = nodeApiVersions.get(nodeId); // Note: if versionInfo is null, we have no server version information. This would be // the case when sending the initial ApiVersionRequest which fetches the version // information itself. It is also the case when discoverBrokerVersions is set to false. if (versionInfo == null) { if (discoverBrokerVersions && log.isTraceEnabled()) log.trace("No version information found when sending message of type {} to node {}. " + "Assuming version {}.", clientRequest.apiKey(), nodeId, builder.version()); } else { short version = versionInfo.usableVersion(clientRequest.apiKey()); builder.setVersion(version); } // The call to build may also throw UnsupportedVersionException, if there are essential // fields that cannot be represented in the chosen version. request = builder.build();//note: 当为 Produce 请求时,转化为 ProduceRequest,Metadata 请求时,转化为 Metadata 请求 } catch (UnsupportedVersionException e) { // If the version is not supported, skip sending the request over the wire. // Instead, simply add it to the local queue of aborted requests. log.debug("Version mismatch when attempting to send {} to {}", clientRequest.toString(), clientRequest.destination(), e); ClientResponse clientResponse = new ClientResponse(clientRequest.makeHeader(), clientRequest.callback(), clientRequest.destination(), now, now, false, e, null); abortedSends.add(clientResponse); return; } RequestHeader header = clientRequest.makeHeader(); if (log.isDebugEnabled()) { int latestClientVersion = ProtoUtils.latestVersion(clientRequest.apiKey().id); if (header.apiVersion() == latestClientVersion) { log.trace("Sending {} to node {}.", request, nodeId); } else { log.debug("Using older server API v{} to send {} to node {}.", header.apiVersion(), request, nodeId); } } //note: Send是一个接口,这里返回的是 NetworkSend,而 NetworkSend 继承 ByteBufferSend Send send = request.toSend(nodeId, header); InFlightRequest inFlightRequest = new InFlightRequest( header, clientRequest.createdTimeMs(), clientRequest.destination(), clientRequest.callback(), clientRequest.expectResponse(), isInternalRequest, send, now); this.inFlightRequests.add(inFlightRequest); //note: 将 send 和对应 kafkaChannel 绑定起来,并开启该 kafkaChannel 底层 socket 的写事件 selector.send(inFlightRequest.send); }
//note: 每次调用时都会注册一个 OP_WRITE 事件 publicvoidsetSend(Send send){ if (this.send != null) thrownew IllegalStateException("Attempt to begin a send operation with prior send operation still in progress."); this.send = send; this.transportLayer.addInterestOps(SelectionKey.OP_WRITE); }
//note: 调用 send() 发送 Send public Send write()throws IOException { Send result = null; if (send != null && send(send)) { result = send; send = null; } return result; }