LLM 系列 (十五):多模态,大模型如何从文字走向理解世界
过去的 LLM 主要围绕文本展开:用户输入一段文字,模型基于上下文生成回答。这个范式已经足够强大,可以支持问答、总结、写作、代码生成和复杂推理。
但真实世界的信息并不只以文本存在。技术文档里有表格、架构图和流程图;代码排障经常伴随截图、日志和监控曲线;会议内容包含语音、视频和演示材料;移动端 Agent 还需要理解界面布局、按钮位置和操作反馈。
如果模型只能处理文本,它看到的世界是不完整的。很多重要信息会在“转成文字”的过程中丢失,比如图像中的空间关系、图表中的趋势变化、视频中的动作过程,以及界面中的布局结构。这就是多模态要解决的问题。
多模态的目标,不是简单给 LLM 增加一个图片输入框,而是让模型能够统一理解文字、图像、语音、视频、表格、界面等不同形态的信息,并在这些信息之间建立关系。从技术上看,多模态至少要解决三个核心问题:
- 不同模态如何表示成模型可以处理的 token;
- 图像、语音、视频如何与语言表示空间对齐;
- 模型如何基于多模态信息进行推理、生成和行动。
为什么需要多模态
多模态的重要性,不只是“让模型能看图”,而是让 LLM 能处理更接近真实任务的信息输入。
在纯文本阶段,很多系统会先把非文本信息转换成文字,再交给模型处理。例如,把图片做 OCR,把语音转成 ASR 文本,把视频抽帧后生成描述,把表格转成 Markdown。这种方式可以工作,但会损失大量原始信息。典型损失包括:
- 空间关系丢失:图片和界面里的位置、布局、相对关系很难完整转成文字;
- 视觉细节丢失:小字、颜色、图标、局部区域、图表趋势可能被忽略;
- 时间过程丢失:视频中的动作变化、事件顺序和因果关系难以只靠摘要表达;
- 结构信息丢失:表格、流程图、架构图、页面层级在纯文本中容易被打散;
- 操作反馈丢失:Agent 执行任务时,界面状态变化和错误提示往往来自截图或视觉反馈。
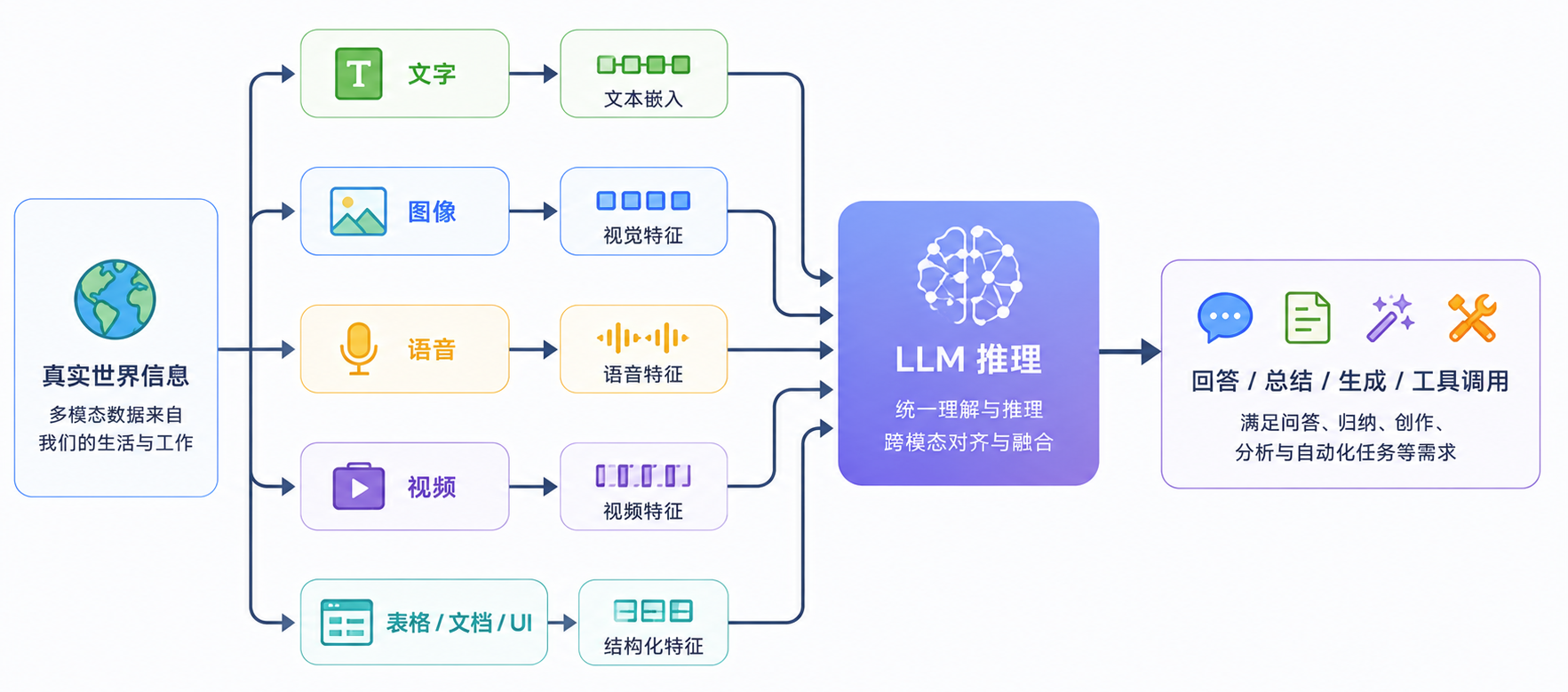
因此,多模态的价值不是多支持一种输入格式,而是让模型从“处理语言”扩展到“处理信息”。它让 LLM 可以阅读文档截图、理解图表趋势、分析视频片段、参与语音交互,也能支撑 Agent 在真实界面中观察环境、判断状态并执行下一步动作。
多模态信息如何进入 LLM
LLM 本质上处理的是一串 token。文本可以通过 tokenizer 切分成 token,再映射成 embedding;但图像、音频、视频这类信号不能直接输入 LLM,需要先经过编码和映射,变成模型可以处理的表示。可以把这个过程理解成两步:
- 模态编码:把图像、音频、视频等原始信号转换成一组向量;
- 空间对齐:把这些向量映射到 LLM 能理解的 embedding 空间。
这里的 token 是广义上的 token / embedding 表示。视觉 token、音频 token 并不是 tokenizer 切出来的文字 token,而是 encoder 生成的向量表示。
简化来看:
1 | 文本 -> tokenizer -> text tokens -> text embeddings |
核心问题是:不同模态的原始信号差异很大,但最终都要进入同一个上下文,由 Transformer 统一处理。
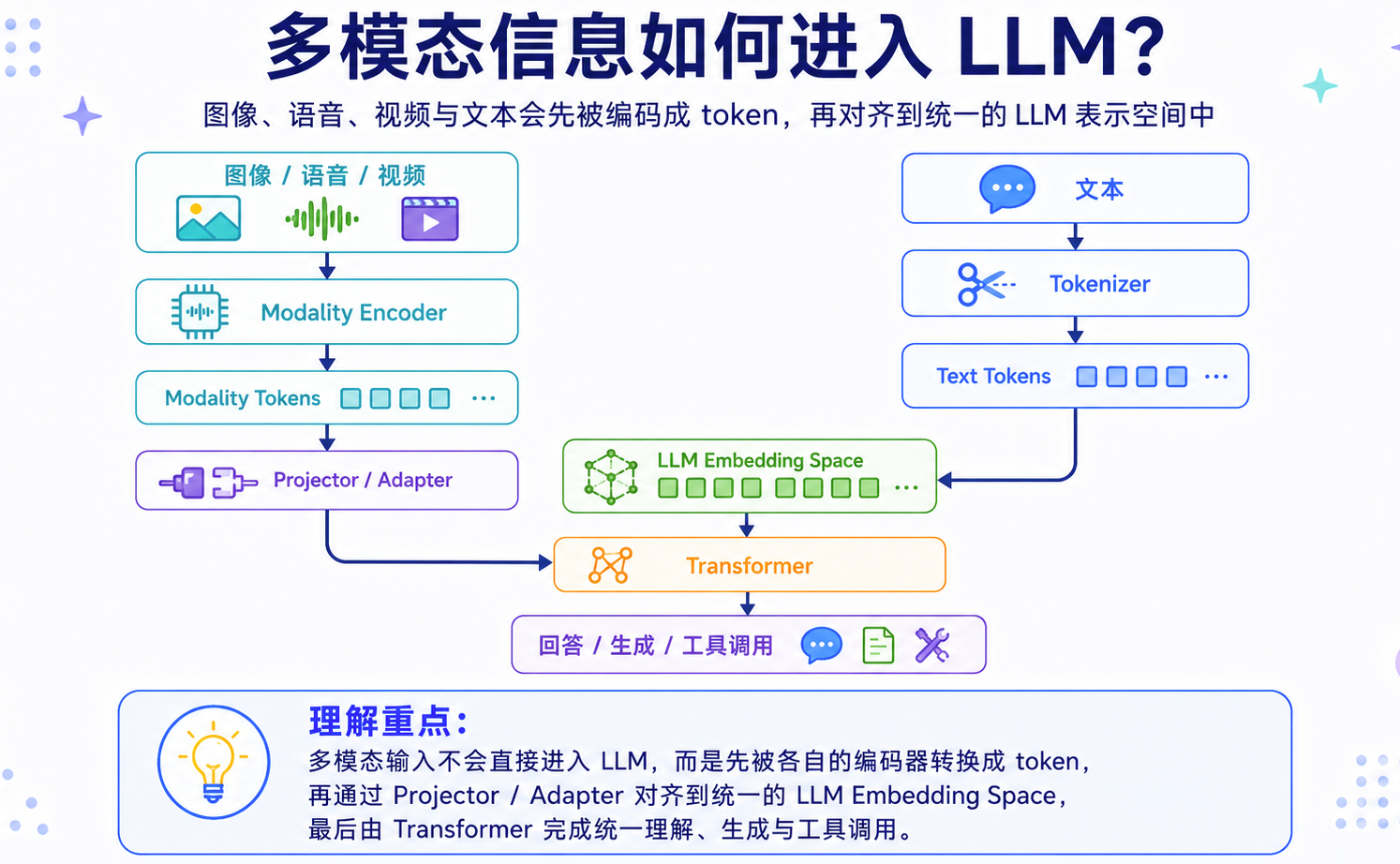
这里有几个关键模块:
| 模块 | 作用 | 典型方案 |
|---|---|---|
| Tokenizer | 把文本切成 token | BPE、SentencePiece |
| Modality Encoder | 把非文本信号编码成向量 | ViT、CNN、Audio Encoder、Video Encoder |
| Projector / Adapter | 把模态向量映射到 LLM embedding 空间 | MLP、Linear Projection、Q-Former、Adapter |
| Token Fusion | 融合文本 token 和多模态 token | 拼接、Cross-Attention、统一 Transformer |
| Position / Layout Encoding | 保留空间位置、时间顺序和文档结构 | 2D position、temporal position、layout embedding |
| LLM Backbone | 对统一 token 序列进行推理和生成 | Decoder-only Transformer、MoE Transformer |
以图像为例,常见流程是:
1 | image -> patches -> vision encoder -> visual embeddings -> projector -> visual tokens |
图像会先被切成多个 patch,每个 patch 类似视觉里的“token”。Vision Encoder 会把这些 patch 编码成视觉向量;Projector 再把这些视觉向量映射到 LLM 的表示空间,让它们可以和文本 token 一起输入模型。
最终输入可能类似:
1 | [visual tokens] + [text tokens] -> LLM -> answer |
- 例如用户输入:请解释这张架构图的核心流程。
- 模型看到的不是原始图片,而是一组已经编码后的 visual tokens,再结合文本问题进行推理。
这里的难点在于:视觉 token、音频 token、视频 token 本身并不是自然语言。模型必须通过训练学会:
- 哪些视觉区域对应哪些文字含义;
- 图像中的空间关系如何影响回答;
- 语音中的时间片段如何对应文本语义;
- 视频中的动作过程如何转化成事件理解;
- 多个模态之间出现冲突时应该如何处理。
所以,多模态输入不是简单“把图片塞进模型”,而是把不同信号编码、压缩、对齐,并组织成 LLM 可以推理的 token 序列。
主流架构路线
多模态架构的核心目标,是把不同模态的信息接入 LLM,并让模型能够在统一上下文中进行推理。这里真正要解决的不是“图片怎么输入”,而是三个问题:
- 表示问题:图像、语音、视频如何变成 token;
- 对齐问题:非文本 token 如何进入语言模型的语义空间;
- 融合问题:不同模态之间如何充分交互,而不是简单拼接。
围绕这三个问题,业内形成了几类主流架构路线。
视觉编码器 + Projector + LLM
这是目前最常见、工程上最容易落地的路线。它的思路是:不直接改造 LLM,而是在 LLM 前面加一个视觉模块。流程可以简化为:
1 | image -> vision encoder -> visual features -> projector -> visual tokens -> LLM |
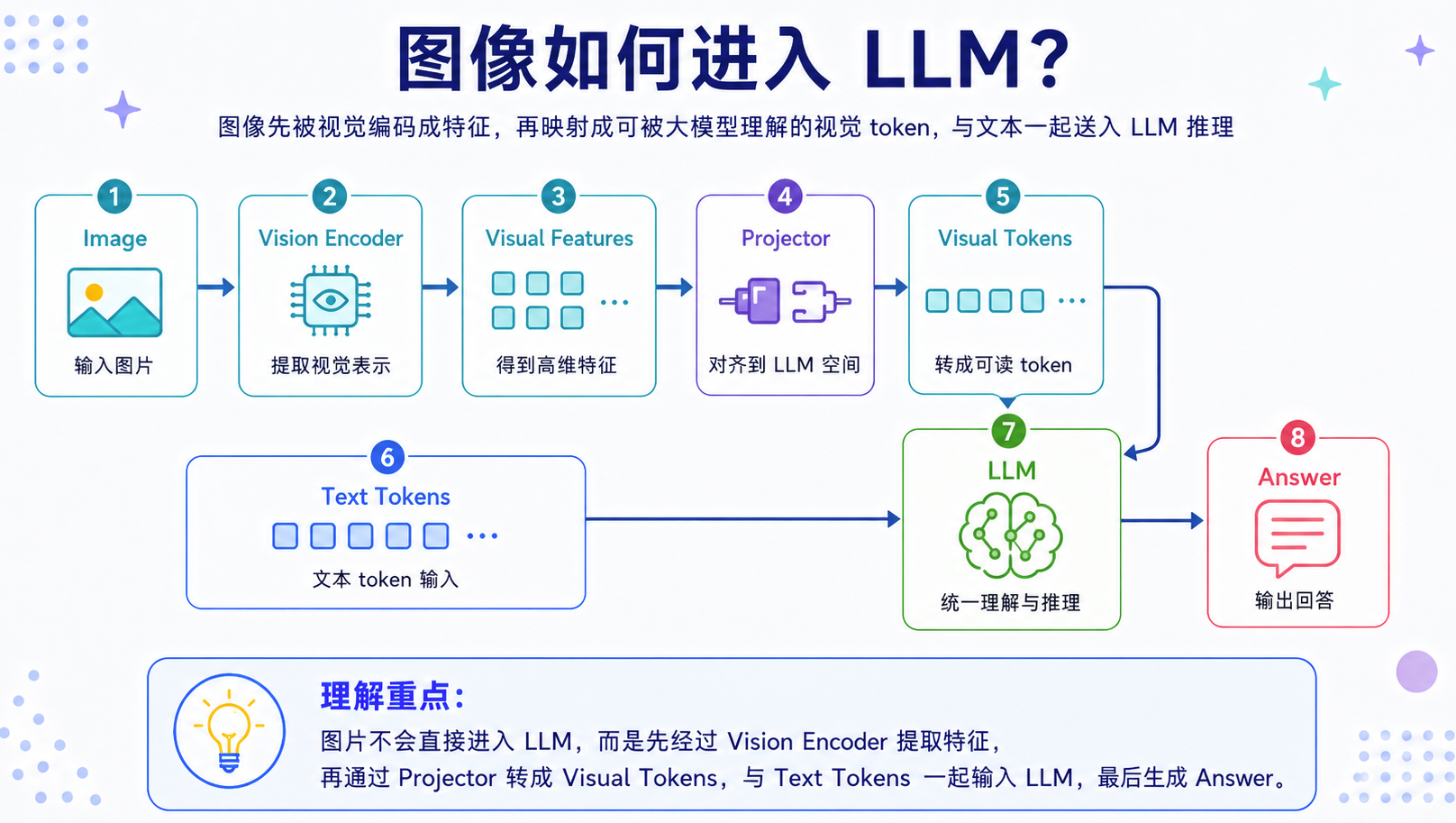
这里通常有三个关键模块:
- Vision Encoder:把图像切成 patch,并编码成视觉特征;
- Projector:把视觉特征映射到 LLM 的 embedding 空间;
- LLM:基于视觉 token 和文本 token 进行推理生成。
这种路线的优点是成本低、改造小、可以复用成熟 LLM。很多模型会冻结一部分 LLM 或视觉编码器,只训练 projector 和少量适配层,从而降低训练成本。
但它也有明显限制:视觉信息进入 LLM 前已经被压缩,模型对细粒度区域、空间关系、图表结构和复杂视觉推理的理解会受到 encoder 与 projector 的限制。
简单说,这条路线解决的是:如何用最小架构改造,把图像接入已有 LLM。
Cross-Attention 融合
第一种路线通常是把视觉 token 和文本 token 拼接后交给 LLM。这样实现简单,但模态交互不一定充分。为了解决这个问题,另一类方案会引入 Cross-Attention,让文本表示可以主动关注视觉特征。可以理解为:
1 | text hidden states <-> visual features |
在这种结构里,文本 token 不只是“看到”一串视觉 token,而是可以通过注意力机制在生成过程中动态查询视觉信息。
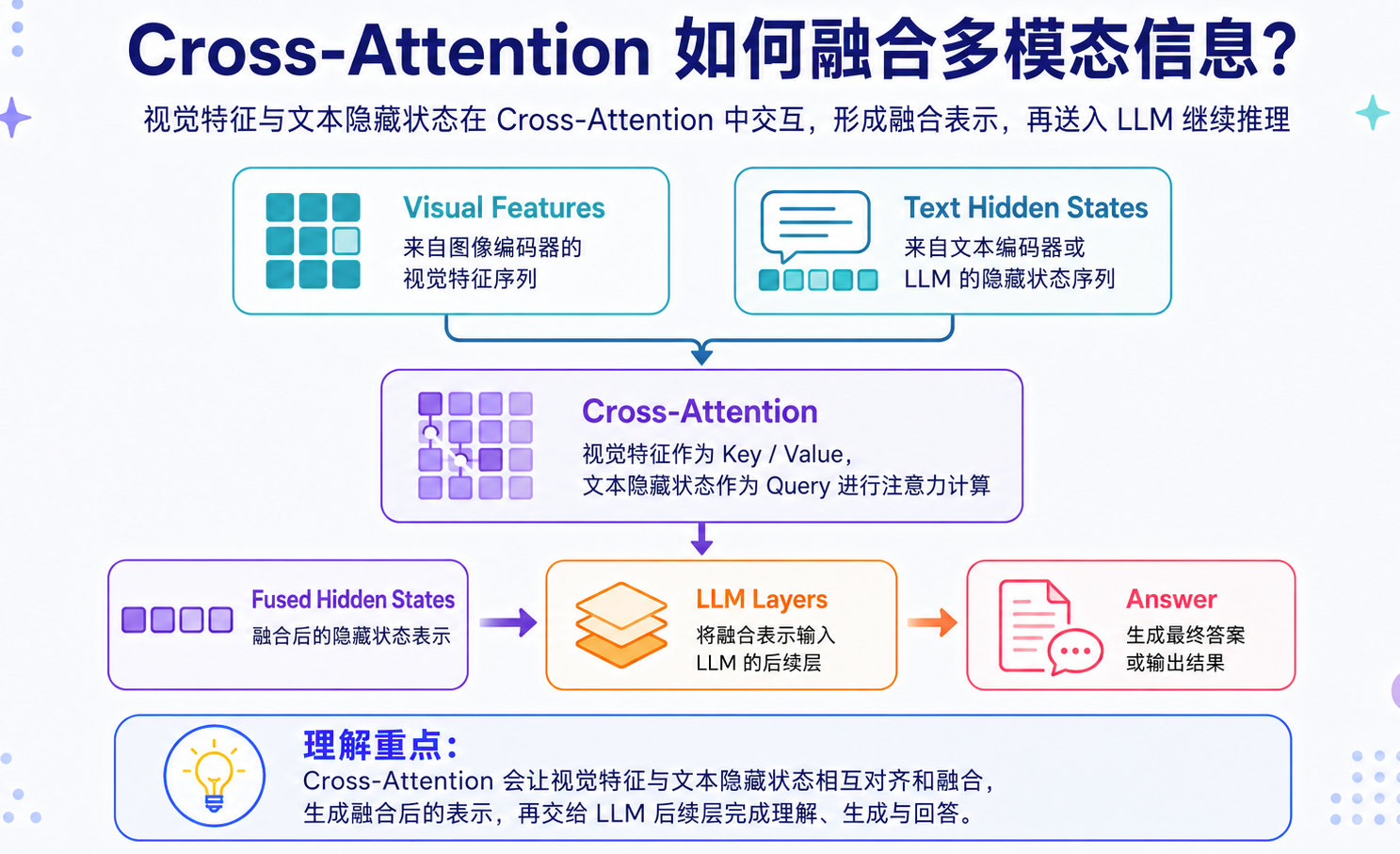
Cross-Attention 的价值在于,它增强了文本与视觉之间的交互能力,尤其适合视觉问答、图文推理、图表理解、复杂文档理解这类任务。但代价也很明显:
- 架构改动更大;
- 训练成本更高;
- 推理时需要维护额外的跨模态注意力计算;
- 不容易直接复用纯文本 LLM 的标准推理优化。
这条路线解决的是:如何让语言 token 和视觉特征发生更充分的交互,而不是浅层拼接。
原生多模态 Transformer
前面两类方案,本质上还是以语言模型为中心,再通过视觉编码器、Projector 或 Cross-Attention 把其他模态接入进来。它们更像是“在 LLM 外围增强多模态能力”。
原生多模态 Transformer 则代表另一种更长期的演进方向:不再把图像、语音、视频看作外挂输入,而是尽量把不同模态都表示成统一 token,由同一个模型结构进行建模。
需要注意的是,目前很多多模态模型仍然是混合架构,并不是所有模态都已经完全由一个统一 Transformer 原生处理。所谓“原生多模态”,更多代表一种架构演进趋势:让模型从设计上具备统一处理文本、图像、语音、视频等信息流的能力。
更进一步看,它会把文本、图像、语音、视频都统一表示成 token,并由同一个 Transformer 处理。
1 | [text tokens, image tokens, audio tokens, video tokens] -> unified Transformer |
它的目标不是“给 LLM 外挂一个视觉模块”,而是让模型从结构上就具备处理多种模态的能力。
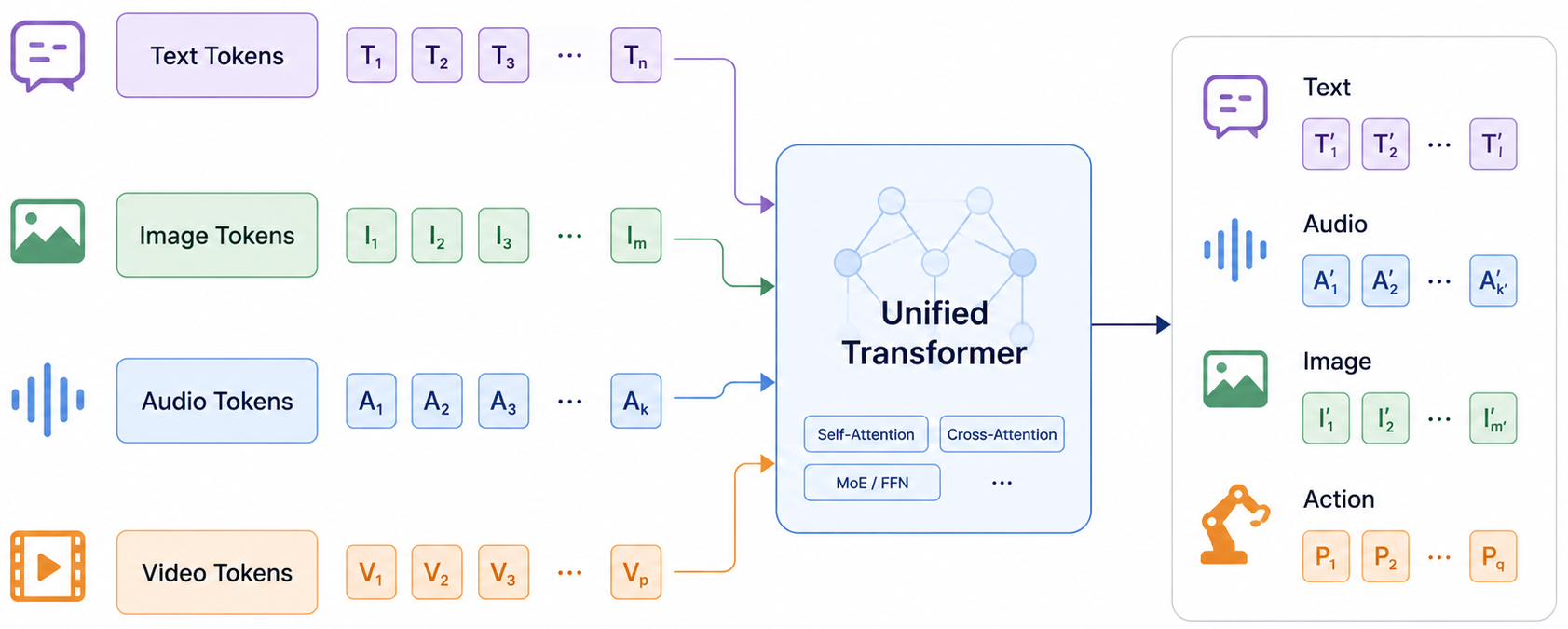
这种路线的优势是能力上限更高,模态之间可以在更深层发生交互,也更适合未来的 any-to-any 模型:文本输入生成语音,图像输入生成文本,语音输入驱动操作,视频输入生成结构化结论。但它的训练难度也更高:
- 不同模态 token 数量差异巨大;
- 图像和视频会显著增加上下文长度;
- 多模态数据配比很难控制;
- 模态之间容易不平衡,模型可能偏向文本;
- 推理成本和 KV Cache 压力更大。
这条路线解决的是:如何从架构层面统一建模多种模态,而不是把多模态能力作为外挂能力。
多模态 MoE
多模态任务之间差异非常大。OCR、图表理解、视觉问答、视频摘要、语音对话、UI 操作所需要的能力并不相同。如果所有 token 都经过同一组参数,模型容量和计算成本都会快速上升。
- MoE 的思路是:让不同 expert 学习不同模态或任务分布,每个 token 只激活部分 expert。
1 | multimodal tokens -> router -> selected experts -> fused representation |
在多模态场景里,expert 可以按照不同方式分工:
- 按模态分工:文本 expert、视觉 expert、语音 expert、视频 expert;
- 按任务分工:OCR expert、图表 expert、推理 expert、UI expert;
- 按层级分工:底层处理感知特征,高层处理语义推理;
- 按动态路由分工:router 根据 token 内容选择 expert。
多模态 MoE 的价值在于:在模型总容量变大的同时,控制每次推理的激活计算量。它适合处理多任务、多模态、高容量需求的基座模型。但挑战也更复杂:
- router 是否能学会合理分配不同模态 token;
- expert 是否会出现负载不均衡;
- 不同模态 expert 是否会割裂,导致融合不足;
- 训练稳定性和通信成本更高;
- 推理部署比 Dense 多模态模型更复杂。
这条路线解决的是:如何在多模态任务越来越复杂时,用稀疏激活扩展模型容量。
小结
几类架构可以这样对比:
| 架构路线 | 解决的问题 | 优点 | 挑战 |
|---|---|---|---|
| Vision Encoder + Projector + LLM | 低成本接入图像能力 | 改造小、复用 LLM、训练成本低 | 融合较浅,视觉能力受 encoder 限制 |
| Cross-Attention 融合 | 增强图文交互 | 模态交互更充分 | 架构复杂,推理成本更高 |
| 原生多模态 Transformer | 统一建模多种模态 | 能力上限高,适合 any-to-any | 数据、训练、推理成本都更高 |
| 多模态 MoE | 扩展多模态容量 | 多任务分工,性能/成本比更好 | 路由、训练稳定性、部署复杂 |
可以看到,多模态架构的演进方向,是从“把视觉接到 LLM 上”,逐步走向“用统一模型处理多种信息流”。
一句话概括:早期多模态更像是 LLM 的外接感知模块,而未来多模态会越来越像一个统一的信息建模系统。
训练流程与数据工程
多模态模型不是只靠架构就能获得能力。架构解决的是“不同模态如何进入模型”,训练解决的是“模型如何真正理解这些模态之间的关系”。一个典型多模态训练流程,可以分成几层:
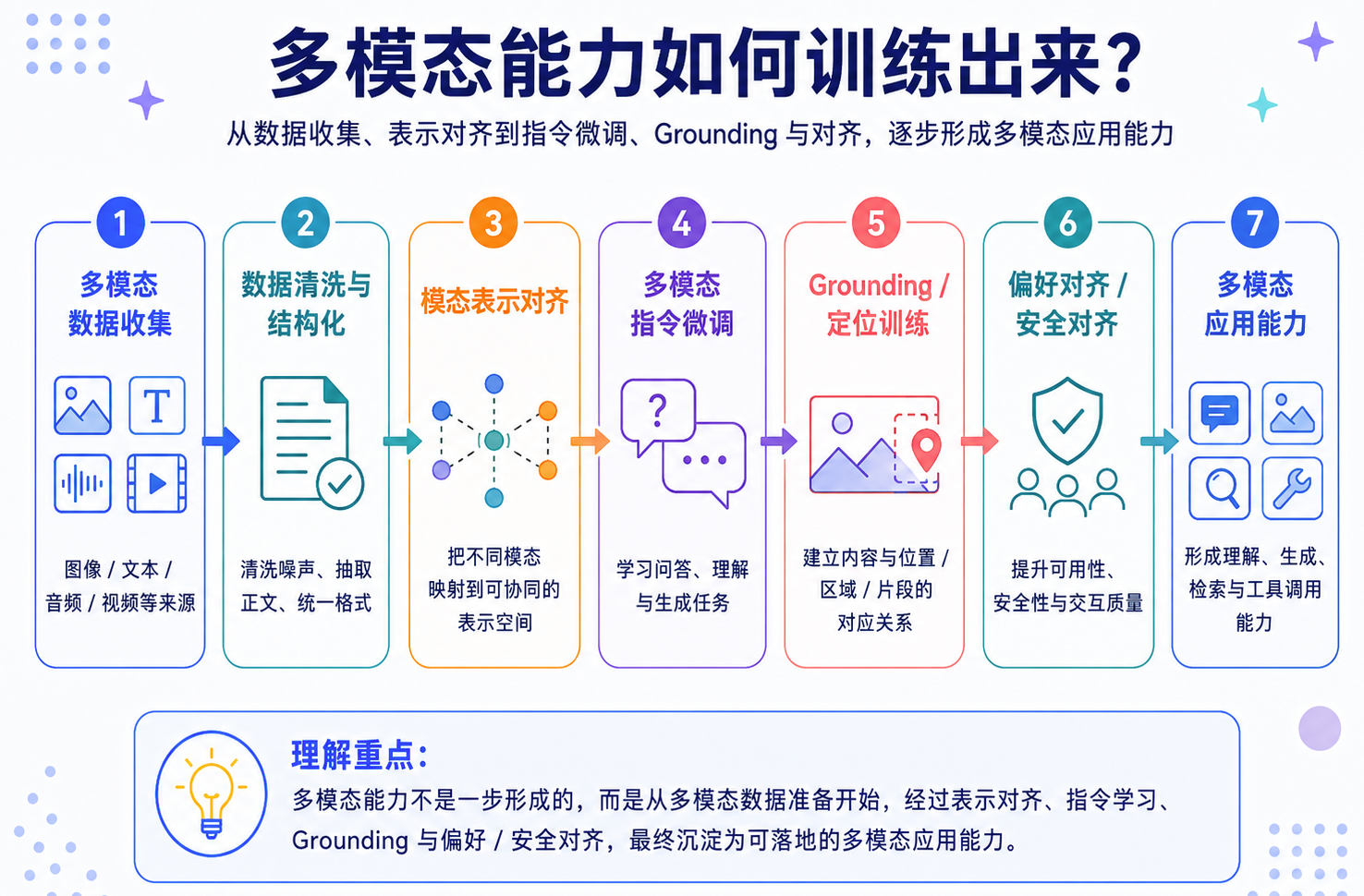
数据工程:样本治理
多模态数据比纯文本数据更复杂,因为它不只包含内容,还包含空间、时间、布局和跨模态关系。常见数据类型包括:
- 图像 - Caption:建立图像内容与语言描述的对应关系;
- 图像 - 问答:训练视觉问答和图文推理能力;
- OCR 文档 - 文本:训练截图、扫描件、PDF、表格理解;
- 图表 - 解释:训练趋势分析、指标理解和结构化推理;
- 视频 - 字幕 / 描述:建立视频片段与事件描述的关系;
- 语音 - 转写文本:建立音频信号与语言文本的关系;
- UI 截图 - 操作轨迹:训练界面理解和 Agent 操作能力。
这一阶段的难点不只是“数据越多越好”,而是要保证数据质量:
- 图文是否匹配;
- OCR 文本是否准确;
- 图表解释是否忠实;
- 视频描述是否覆盖关键事件;
- UI 操作轨迹是否和截图状态一致;
- 是否包含隐私、人脸、敏感信息或版权风险。
如果数据本身错位,例如图片和 caption 不匹配,模型会学到错误的跨模态关系。
模态对齐:统一语义空间
模态对齐的目标,是让模型理解“这个视觉区域、这段语音、这个视频片段”对应什么语言含义。常见训练目标包括:
- 图文对比学习:让匹配的图像和文本距离更近,不匹配的距离更远;
- Caption 生成:输入图像,让模型生成对应描述;
- 图文问答:输入图像和问题,让模型生成答案;
- 图像 - 文本匹配:判断一段文本是否描述了当前图像;
- 语音 - 文本对齐:让音频片段和转写文本建立对应关系;
- 视频 - 事件对齐:让视频片段和事件描述建立时间关系。
这一阶段解决的是“看见”和“说出来”之间的对齐问题。模型需要学会:视觉 token、音频 token、视频 token 不是孤立向量,而是可以和语言概念发生对应。
指令微调:从描述到任务
模态对齐之后,模型可能已经能描述图片,但这还不等于能完成真实任务。真实用户给出的不是“描述这张图”,而是更复杂的指令:
- 请解释这张架构图的核心流程;
- 请提取截图中的错误信息;
- 请根据这张表总结趋势;
- 请判断这个 UI 页面下一步应该点击哪里;
- 请比较这两张图的差异;
- 请根据视频内容总结关键事件。
多模态指令微调的目标,是让模型学会根据用户意图使用多模态信息,而不是只做表面描述。
- 这一步会让模型从:看见图像 -> 描述图像。
- 进一步变成:理解图像 / 文档 / 视频 -> 按任务要求推理和回答。
Grounding:定位与映射
多模态模型不能只回答“图里有一个按钮”,还要知道按钮在哪里、哪个区域对应哪个对象、哪段视频对应哪个事件。Grounding 训练要建立文本和空间 / 时间位置之间的关系:
1 | 对象 -> 边界框 |
这对 UI Agent、机器人、文档定位、图表问答非常关键。例如 UI Agent 需要的不只是回答“点击提交按钮”,还要知道:
1 | 提交按钮在哪个区域? |
没有 Grounding,多模态模型容易停留在“看起来理解了”,但无法把理解落实到具体区域、时间点或动作上。
安全对齐:减少幻觉与风险
多模态模型也会幻觉,而且有时更隐蔽。它可能看错图片、误读图表、编造 OCR 内容,或者在证据不足时给出确定答案。因此,多模态也需要偏好对齐和安全训练:
- 不确定时说明无法判断;
- 对 OCR、图表、医学、法律等场景保持谨慎;
- 对人脸、身份、隐私、地理位置等敏感信息做限制;
- 对工具操作类任务加入确认机制;
- 对图像、视频中的不充分证据避免过度推断;
- 回答最好能引用图像区域、文档段落或视频时间点。
简单说,多模态训练要解决的不只是“看懂”,还包括:看得准 -> 对得上 -> 会执行 -> 可验证 -> 不乱说。
应用、挑战与未来演进
多模态让 LLM 的应用边界明显扩大。它让模型从处理文字,扩展到处理文档、图像、语音、视频和界面环境,也让很多原本需要人工观察和判断的任务,开始具备自动化可能。典型应用可以概括为几类:
| 场景 | 多模态能力 | 典型任务 |
|---|---|---|
| 文档理解 | OCR、版面结构、表格、图表理解 | PDF 问答、合同审阅、财报分析 |
| 图表分析 | 趋势识别、异常点分析、指标关联 | 监控图分析、业务报表解读 |
| 截图问答 | 页面元素识别、错误提示理解 | 排障、客服、产品支持 |
| UI Agent | 界面理解、坐标定位、操作反馈 | 自动填表、网页操作、移动端任务 |
| 视频理解 | 帧理解、时间建模、事件抽取 | 会议总结、教学视频分析、监控片段理解 |
| 语音助手 | ASR、语音理解、实时交互 | 会议纪要、客服录音、实时对话 |
| 多模态 RAG | 从图文表视频中检索证据 | 企业知识问答、研究报告分析 |
但多模态能力越强,系统复杂度也越高。它带来的挑战不只是“模型能不能看懂”,还包括成本、评估、安全和工程稳定性。
| 挑战 | 表现 | 解决方向 |
|---|---|---|
| Token 成本高 | 图片、视频会产生大量视觉 token | token 压缩、分辨率自适应、关键帧抽取 |
| 细粒度识别难 | 小字、密集对象、复杂表格容易出错 | OCR 增强、区域裁剪、高分辨率编码 |
| 空间推理不稳定 | 能识别对象,但位置关系判断不准 | Grounding、2D position、区域级监督 |
| 视频时间建模难 | 动作变化、事件顺序和因果关系复杂 | temporal encoding、clip-level 建模、事件标注 |
| 图像幻觉隐蔽 | 回答自然但没有真实依据 | 证据引用、区域定位、回答校验 |
| 评估复杂 | 不能只看文本答案是否像 | 区域、坐标、时间片段、操作结果评估 |
| 隐私与安全风险高 | 图片、语音、视频包含敏感信息 | 脱敏、权限控制、敏感内容识别 |
这里最值得注意的是:多模态错误往往不像文本错误那么容易被发现。模型可能把一张图解释得很流畅,但实际上看错了关键区域;也可能在视频总结中遗漏关键事件,或者误读 UI 页面状态。
因此,生产级多模态系统不能只依赖模型回答,还需要让关键结论可追溯到图像区域、文档段落或视频时间点;在高风险场景加入人工确认;对 OCR、图表、坐标、时间片段进行专项评估;并对图片、语音、视频中的隐私信息做权限控制和脱敏处理。
未来多模态大模型会沿着几个方向继续演进:
- 原生多模态架构:文本、视觉、语音、视频统一建模,而不是外挂模块;
- 实时多模态交互:模型可以处理连续语音、视频流和界面状态变化;
- 多模态 Agent:模型不仅看懂界面,还能根据视觉反馈执行下一步动作;
- 多模态 RAG:从文字、图片、表格、视频中共同检索证据;
- 更强 Grounding:答案能对应到图像区域、文档段落或视频时间点;
- 多模态 MoE:不同 expert 处理不同模态和任务,提高容量与效率;
- 更严格评估与安全机制:减少看图幻觉、误识别和高风险操作。
简单来说,多模态的目标,不是让 LLM 多支持几种输入格式,而是让模型把文字、图像、语音、视频和外部环境统一到可推理、可生成、可行动的表示空间中。它让大模型从“读懂文字”,进一步走向“理解世界”。
