本篇文章是 Flink 系列 的第二篇,将会给大家讲述一个 Flink 作业(DataStream 高阶 API 为例的作业)是如何转换为 StreamGraph 的, StreamGraph 可以认为是一个还未经过优化处理的逻辑计划,它完全是在 Client 端生成的。StreamGraph 然后再经过优化转换为 JobGraph,Client 端向 JobManager 提交的作业就是以 JobGraph 的形式提交的,也就是说对于 JobManager 来说,它从客户端接收的作业实际上就是一个 JobGraph,然后它再对 JobGraph 做相应处理,生成具体的物理执行计划进行调度。
关于分布式计算中的 Graph,对于很多人来说,最开始接触和理解这个概念应该还是在 Spark 中。Spark 中有个 DAG (Directed Acyclic Graph,有向无环图)的概念,它包括一些边和一些顶点,其中边代表了 RDD(Spark 中对数据的封装和抽象)、顶点代表了 RDD 上的 Operator,在一个作业中,一旦有 Action 被调用,创建的 DAG 就会被提交到 DAG Scheduler,它会将这个 graph 以 task 的形式调度到不同的节点上去执行计算。Spark 在 MapReduce 的基础上提出了 DAG 的概念,带来了很多的好处,比如:更方便对复杂作业(复杂的 DAG)做全局优化、通过 DAG 恢复丢失的 RDD 等等。Apache Flink 在设计实现中,也借鉴了这个设计,Flink 中的每个作业在调度时都是一个 Graph(Flink 一般叫 DataFlow Graph,Spark 中一般叫作 DAG)。另外,Google 的 Beam 也是类似的概念,Collection 和 Transformation 对数据和操作的最基本抽象,Graph 由 Collection 和 Transformation 构成。
一个 Flink 作业(Steaming 作业),从 Client 端提交到最后真正调度执行,其 Graph 的转换会经过下面三个阶段(第四个阶段是作业真正执行时的状态,都是以 task 的形式在 TM 中运行):
StreamGraph:根据编写的代码生成最初的 Graph,它表示最初的拓扑结构;
JobGraph:这里会对前面生成的 Graph,做一些优化操作(比如: operator chain 等),最后会提交给 JobManager;
ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph,是 Flink 调度时依赖的核心数据结构;
物理执行图:JobManager 根据生成的 ExecutionGraph 对 Job 进行调度后,在各个 TM 上部署 Task 后形成的一张虚拟图。
这整个转换的内容还是比较多的,也考虑到单篇文章的篇幅问题,这里会先给大家讲述第一部分的转换,也就是 StreamGraph 的转换,同时也会给大家把基本的概念理清楚,便于后面的讲解。
DataSteam API 如果想对后面的内容理解更清楚,首先需要对 DataStream API 的基本概念有一定的理解,Apache Flink 自从 1.0 开始推出 DataStream API 后,经过最近几年的演化,这部分的代码已经变得比较复杂了,有些地方个人感觉还是有些冗余的,这里尽量给大家梳理清楚。
DataStream A DataStream represents a stream of elements of the same type. A DataStream can be transformed into another DataStream by applying a transformation.
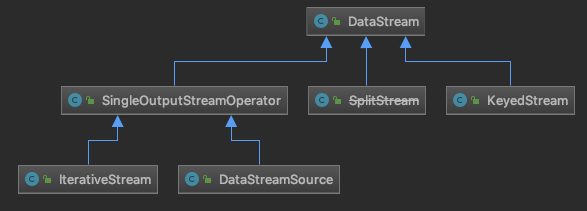
上面是 DataStream 的定义,从这个叙述中,可以看出,DataStream 实际上就是对相同类型数据流做的封装,它的主要作用就是可以用通过 Transformation 操作将其转换为另一个 DataStream,DataStream 向用户提供非常简单的 API 操作,比如 map()、filter()、flatMap() 等,目前 Flink 1.9 的代码里提供的 DataStream 实现如下:
A Transformation represents the operation that creates a DataStream。Transformation 代表创建 DataStream 的一个 operation,这里举一个示例,看一下下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> inputStream = env.addSource(new RandomWordCount.RandomStringSource()); inputStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap (String value, Collector<Tuple2<String, Integer>> out) for (String word : value.split("\\s" )) { out.collect(Tuple2.of(word, 1 )); } } });
这段代码首先会执行 addSource() 操作,它会创建一个 DataStreamSource 节点, 只有创建了 Source 的 DataStream 节点,后面才能对这个 DataStream 做相应的 Transformation 操作(实际上 DataStreamSource 节点也会有一个对应的 SourceTransformation 对象)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public <OUT> DataStreamSource<OUT> addSource (SourceFunction<OUT> function) { return addSource(function, "Custom Source" ); } public <OUT> DataStreamSource<OUT> addSource (SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) { if (function instanceof ResultTypeQueryable) { typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType(); } if (typeInfo == null ) { try { typeInfo = TypeExtractor.createTypeInfo( SourceFunction.class, function.getClass(), 0 , null , null ); } catch (final InvalidTypesException e) { typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e); } } boolean isParallel = function instanceof ParallelSourceFunction; clean(function); final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function); return new DataStreamSource<>(this , typeInfo, sourceOperator, isParallel, sourceName); }
接下来再看 flatMap() 方法,这个实现其实跟前面的实现有一些类似之处,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public <R> SingleOutputStreamOperator<R> flatMap (FlatMapFunction<T, R> flatMapper) { TypeInformation<R> outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper), getType(), Utils.getCallLocationName(), true ); return transform("Flat Map" , outType, new StreamFlatMap<>(clean(flatMapper))); } public <R> SingleOutputStreamOperator<R> transform (String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) { transformation.getOutputType(); OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>( this .transformation, operatorName, operator, outTypeInfo, environment.getParallelism()); @SuppressWarnings ({ "unchecked" , "rawtypes" }) SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform); getExecutionEnvironment().addOperator(resultTransform); return returnStream; }
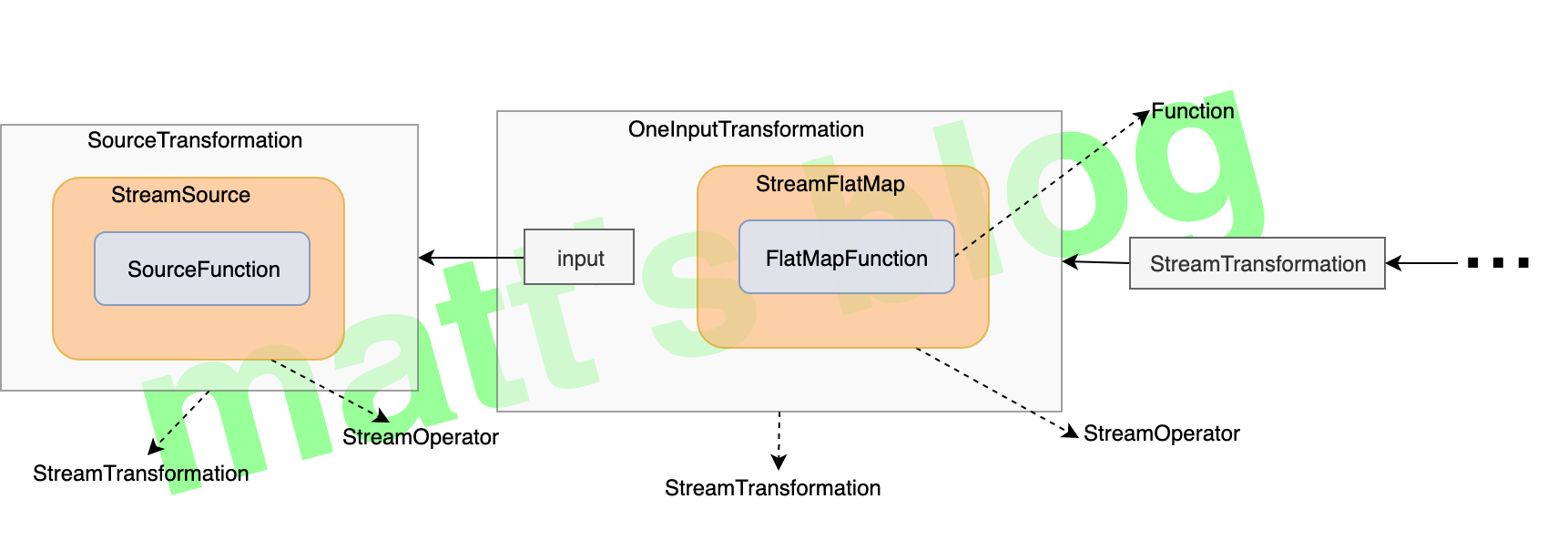
分析到这里,那么 Transformation 到底是什么呢?这里之所以给大家举这个示例,也是为了让大家对 Transformation 有更深入的了解。这里看下下面这一张图,最开始是一个 SourceTransformation,然后又创建一个 OneInputTransformation 对象(这张图就是这里我们举的示例):
实际上,一个 Transformation ,它是对 StreamOperator 的一个封装(而 StreamOperator 又是对 Function 的一个封装,真正的处理逻辑是在 Function 实现的,当然并不一定所有的 Operator 都会有 Function,这里为了便于理解,就按照这个来讲述了),并且会记录它前面的 Transformation,只有这样才能把这个 Job 的完整 graph 构建出来。这里也可以看到,所有对 DataStream 的操作,最终都是以 Transformation 体现的,DataStream 仅仅是暴露给用户的一套操作 API,用于简化数据处理的实现。
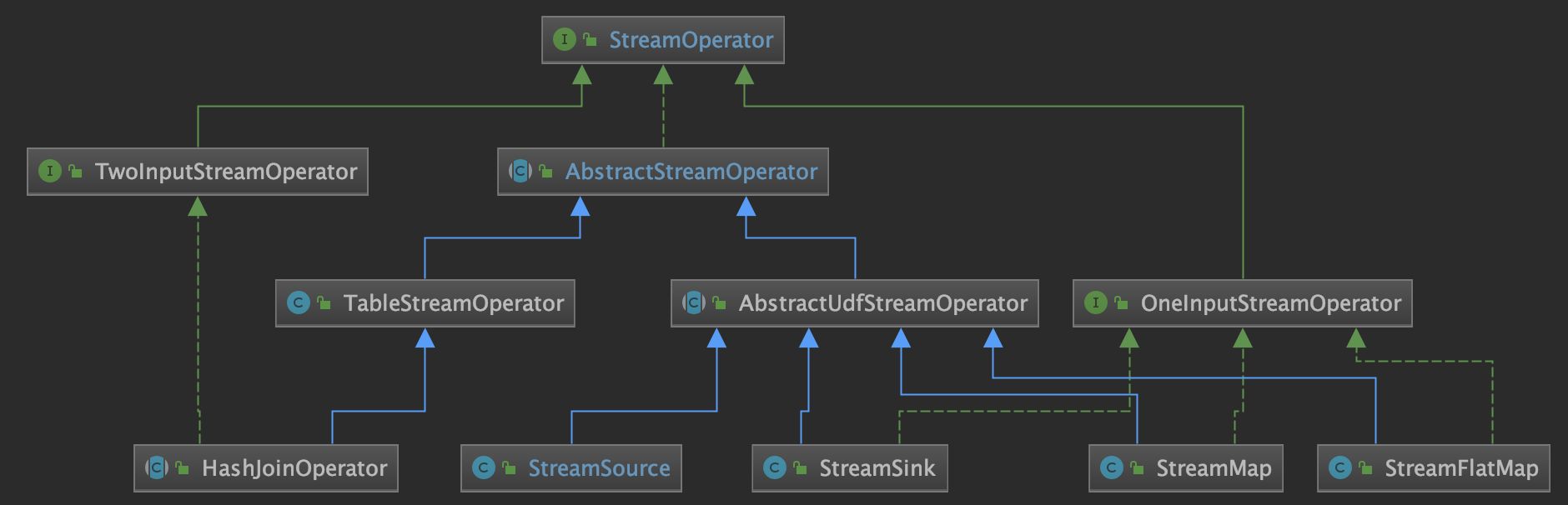
StreamOperator Operator 最基本类的是 StreamOperator,从名字也能看出来,它表示的是对 Stream 的一个 operation,它主要的实现类如下:
AbstractUdfStreamOperator:会封装一个 Function,真正的操作是在 Function 中的实现,它主要是在最基础的方法实现上也会相应地调用对应 Function 的实现,比如:open/close方法也会调用 Function 的对应实现等;
OneInputStreamOperator:如果这个 Operator 只有一个输入,实现这个接口即可, 这个 processElement() 方法需要自己去实现;
TwoInputStreamOperator:如果这个 Operator 是一个二元操作符,是对两个流的处理,比如:双流 join,那么实现这个接口即可,用户需要自己去实现 processElement1() 和 processElement2() 方法。
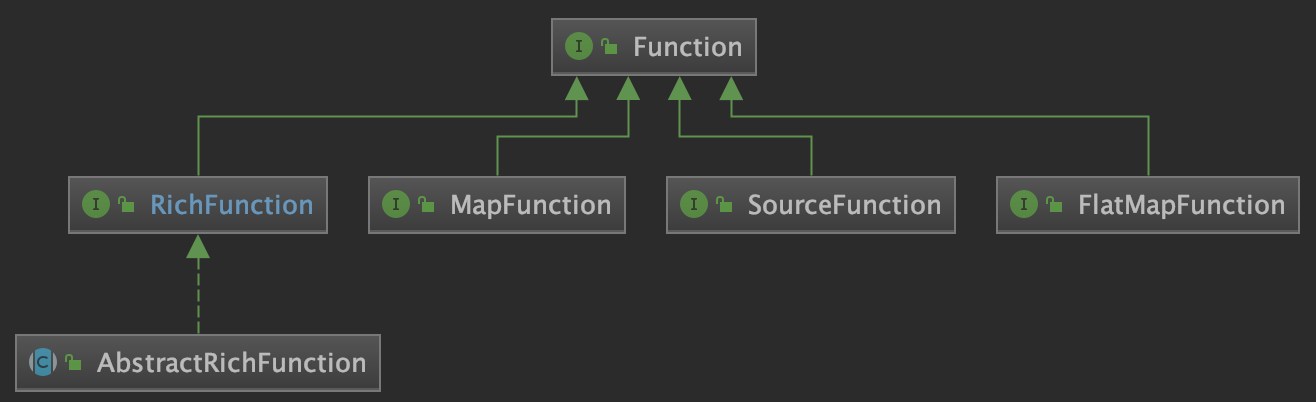
Function Function 是 Transformation 最底层的封装,用户真正的处理逻辑是在这个里面实现的,包括前面示例中实现的 FlatMapFunction 对象。
到这里,终于把最基本这些概念介绍完了,只有对这些概念有了相应的理解之后,阅读源码时才不至于被绕进去。
如何生成 StreamGraph 这里在讲述一个作业转换为 StreamGraph 的细节时,依然以上一篇文章中的示例 —— RandomWordCount 来讲述。在执行 env.getStreamGraph().getStreamingPlanAsJSON() 后,这个 StreamGraph 将会以 JSON 的格式输出出来,输出结果如下:
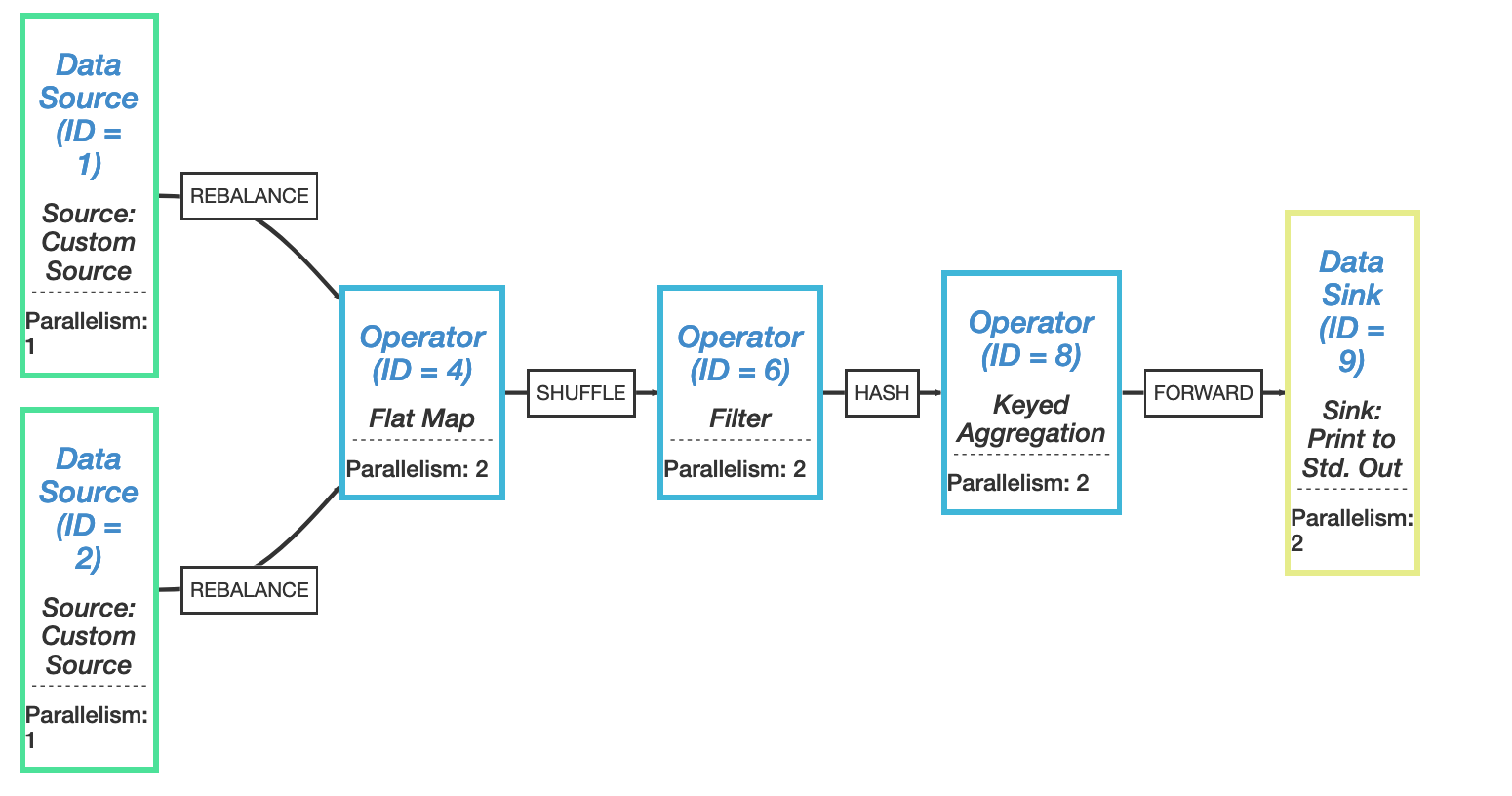
1 {"nodes" :[{"id" :1 ,"type" :"Source: Custom Source" ,"pact" :"Data Source" ,"contents" :"Source: Custom Source" ,"parallelism" :1 },{"id" :2 ,"type" :"Source: Custom Source" ,"pact" :"Data Source" ,"contents" :"Source: Custom Source" ,"parallelism" :1 },{"id" :4 ,"type" :"Flat Map" ,"pact" :"Operator" ,"contents" :"Flat Map" ,"parallelism" :8 ,"predecessors" :[{"id" :1 ,"ship_strategy" :"REBALANCE" ,"side" :"second" },{"id" :2 ,"ship_strategy" :"REBALANCE" ,"side" :"second" }]},{"id" :6 ,"type" :"Filter" ,"pact" :"Operator" ,"contents" :"Filter" ,"parallelism" :8 ,"predecessors" :[{"id" :4 ,"ship_strategy" :"SHUFFLE" ,"side" :"second" }]},{"id" :8 ,"type" :"Keyed Aggregation" ,"pact" :"Operator" ,"contents" :"Keyed Aggregation" ,"parallelism" :8 ,"predecessors" :[{"id" :6 ,"ship_strategy" :"HASH" ,"side" :"second" }]},{"id" :9 ,"type" :"Sink: Print to Std. Out" ,"pact" :"Data Sink" ,"contents" :"Sink: Print to Std. Out" ,"parallelism" :2 ,"predecessors" :[{"id" :8 ,"ship_strategy" :"REBALANCE" ,"side" :"second" }]}]}
在 Flink Plan Visualizer 中可以看到 StreamGraph 可视化之后 graph(用 Chrome 打开可能会显示不全,可以试下 Firefox),如下如所示:
接下来,详细介绍一下 StreamGraph 是如何转换的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Internal public StreamGraph getStreamGraph () return getStreamGraphGenerator().generate(); } private StreamGraphGenerator getStreamGraphGenerator () if (transformations.size() <= 0 ) { throw new IllegalStateException("No operators defined in streaming topology. Cannot execute." ); } return new StreamGraphGenerator(transformations, config, checkpointCfg) .setStateBackend(defaultStateBackend) .setChaining(isChainingEnabled) .setUserArtifacts(cacheFile) .setTimeCharacteristic(timeCharacteristic) .setDefaultBufferTimeout(bufferTimeout); }
StreamGraph 最后是通过 StreamGraphGenerator 的 generate() 方法生成的,那这个方法到底做了什么事情呢?其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public StreamGraph generate () streamGraph = new StreamGraph(executionConfig, checkpointConfig); streamGraph.setStateBackend(stateBackend); streamGraph.setChaining(chaining); streamGraph.setScheduleMode(scheduleMode); streamGraph.setUserArtifacts(userArtifacts); streamGraph.setTimeCharacteristic(timeCharacteristic); streamGraph.setJobName(jobName); streamGraph.setBlockingConnectionsBetweenChains(blockingConnectionsBetweenChains); alreadyTransformed = new HashMap<>(); for (Transformation<?> transformation: transformations) { transform(transformation); } final StreamGraph builtStreamGraph = streamGraph; alreadyTransformed.clear(); alreadyTransformed = null ; streamGraph = null ; return builtStreamGraph; }
最关键的还是 transform() 方法的实现,这里会根据 Transformation 的类型对其做相应的转换,其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 private Collection<Integer> transform (Transformation<?> transform) if (alreadyTransformed.containsKey(transform)) { return alreadyTransformed.get(transform); } LOG.debug("Transforming " + transform); if (transform.getMaxParallelism() <= 0 ) { int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism(); if (globalMaxParallelismFromConfig > 0 ) { transform.setMaxParallelism(globalMaxParallelismFromConfig); } } transform.getOutputType(); Collection<Integer> transformedIds; if (transform instanceof OneInputTransformation<?, ?>) { transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform); } else if (transform instanceof TwoInputTransformation<?, ?, ?>) { transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform); } else if (transform instanceof SourceTransformation<?>) { transformedIds = transformSource((SourceTransformation<?>) transform); } else if (transform instanceof SinkTransformation<?>) { transformedIds = transformSink((SinkTransformation<?>) transform); } else if (transform instanceof UnionTransformation<?>) { transformedIds = transformUnion((UnionTransformation<?>) transform); } else if (transform instanceof SplitTransformation<?>) { transformedIds = transformSplit((SplitTransformation<?>) transform); } else if (transform instanceof SelectTransformation<?>) { transformedIds = transformSelect((SelectTransformation<?>) transform); } else if (transform instanceof FeedbackTransformation<?>) { transformedIds = transformFeedback((FeedbackTransformation<?>) transform); } else if (transform instanceof CoFeedbackTransformation<?>) { transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform); } else if (transform instanceof PartitionTransformation<?>) { transformedIds = transformPartition((PartitionTransformation<?>) transform); } else if (transform instanceof SideOutputTransformation<?>) { transformedIds = transformSideOutput((SideOutputTransformation<?>) transform); } else { throw new IllegalStateException("Unknown transformation: " + transform); } if (!alreadyTransformed.containsKey(transform)) { alreadyTransformed.put(transform, transformedIds); } if (transform.getBufferTimeout() >= 0 ) { streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout()); } else { streamGraph.setBufferTimeout(transform.getId(), defaultBufferTimeout); } if (transform.getUid() != null ) { streamGraph.setTransformationUID(transform.getId(), transform.getUid()); } if (transform.getUserProvidedNodeHash() != null ) { streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash()); } if (!streamGraph.getExecutionConfig().hasAutoGeneratedUIDsEnabled()) { if (transform.getUserProvidedNodeHash() == null && transform.getUid() == null ) { throw new IllegalStateException("Auto generated UIDs have been disabled " + "but no UID or hash has been assigned to operator " + transform.getName()); } } if (transform.getMinResources() != null && transform.getPreferredResources() != null ) { streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources()); } return transformedIds; }
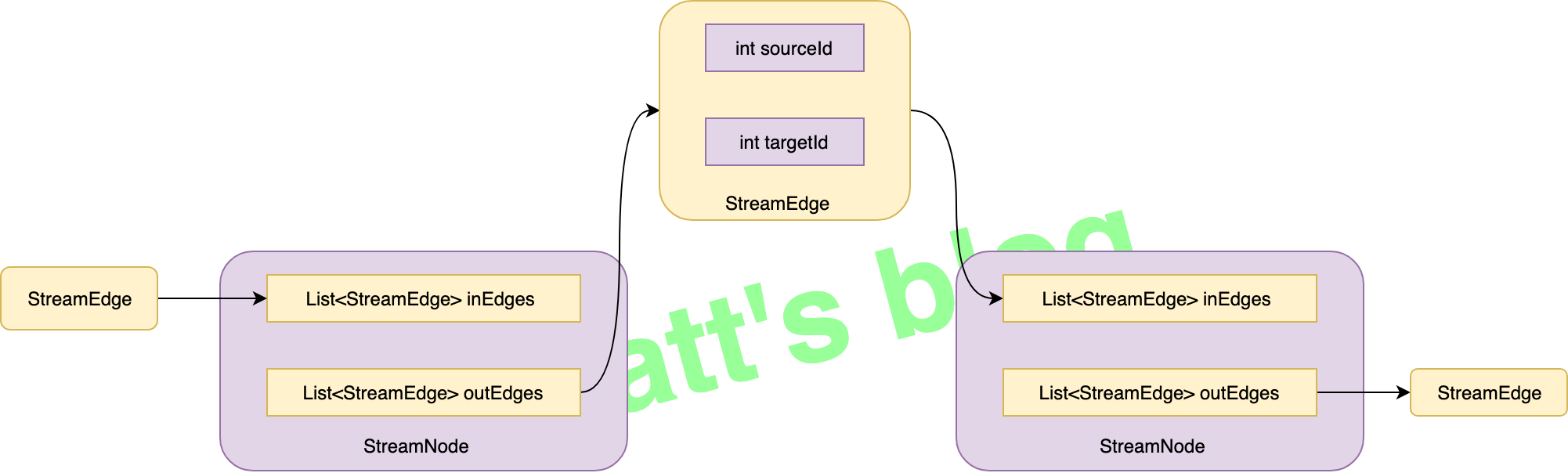
这里以 transformOneInputTransform() 的实现来举个相应的例子,它会给这个 Transformation 创建相应的 StreamNode,并且创建 StreamEdge 来连接前后的 StreamNode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 private <IN, OUT> Collection<Integer> transformOneInputTransform (OneInputTransformation<IN, OUT> transform) { Collection<Integer> inputIds = transform(transform.getInput()); if (alreadyTransformed.containsKey(transform)) { return alreadyTransformed.get(transform); } String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds); streamGraph.addOperator(transform.getId(), slotSharingGroup, transform.getCoLocationGroupKey(), transform.getOperatorFactory(), transform.getInputType(), transform.getOutputType(), transform.getName()); if (transform.getStateKeySelector() != null ) { TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(executionConfig); streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer); } int parallelism = transform.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT ? transform.getParallelism() : executionConfig.getParallelism(); streamGraph.setParallelism(transform.getId(), parallelism); streamGraph.setMaxParallelism(transform.getId(), transform.getMaxParallelism()); for (Integer inputId: inputIds) { streamGraph.addEdge(inputId, transform.getId(), 0 ); } return Collections.singleton(transform.getId()); }
经过上面的 transform() 操作,最后生成的 StreamGraph 样板如下图所示:
关于上面的 transform() ,还有一个需要注意的是:这三个实现方法 transformSelect()、transformPartition()、transformSideOutput() 在操作时,并不会创建真正的 StreamNode 节点,它们会创建一个虚拟节点,将相应的配置赋给对应的 StreamEdge 即可。另外对于 transformUnion() 方法,它连虚拟节点也不会创建,原因其实看源码也能明白,它们并不包含具体的处理操作。
到这里,StreamGraph 的创建过程就分析完了,如果理解了 Flink 基本对象的抽象后,再去看这部分代码,实际上并不复杂,这里是对用户的作业逻辑做了一个最简单的转换,并没做什么优化操作,相当于还是原生的用户作业逻辑。
参考