Paper 阅读: Real-Time Machine Learning: The Missing Pieces
这周抽空看了关于 ray 的一篇论文,论文是 2017 年发表的(见:Real-Time Machine Learning: The Missing Pieces,他们比较新的论文是 18 年发表的,见:Ray: A Distributed Framework for Emerging AI Applications),虽然论文描述的架构与现在 ray 真正的构架实现已经有了较大的不同,主要也是 ray 这两年发展比较快,架构做了很多的优化,不过本篇论文依然值得仔细阅读学习 一下的,这篇论文也展示了 ray 最初设计实现的出发点。
本章不会严格按照论文翻译,整体会按照下面的思路来叙述:
- 遇到的问题什么?
- 当前业内的方案是什么?
- 论文提出了什么样的解决方案?达到了什么效果?
问题
现在有越来越多的 ML 应用,不仅仅使用静态模型进行训练预测,它们会使用动态、实时决策的反馈来实时调整应用,这种场景就给计算模型提出了一些新的要求:
- 高吞吐低延迟;
- 自适应创建任意的 task graph;
- 针对不同的数据集使用的不同内核(可以理解为融合计算);
这些要求如果单独去实现的话,并不是很难,但是把它们在一套系统里同时实现就非常有挑战性了,而目前业内并没有这样的一套方案(指的是这套系统设计之前,业内还没有)。
举个例子
这里,我们看个示例,下图 a 是一个传统的 ML 应用架构,它主要使用离线数据做训练和预测(ML 中监督式学习),但是现在有个趋势,就是如下图 b 所示的构架越来越多,即 ML 应用与实时反馈的回路紧密集成,它会依赖实时数据做训练和预测。
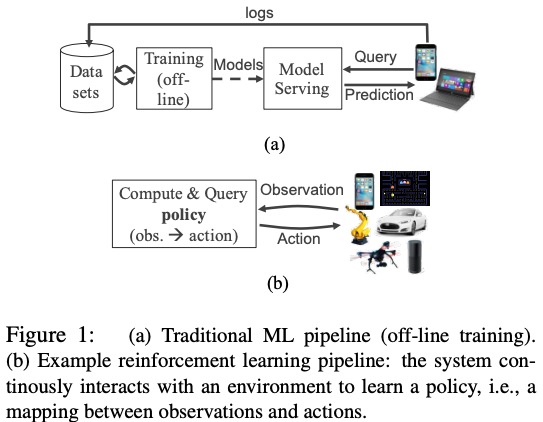
场景对计算模型的要求
对于前面提出的场景,对模型的灵活性和性能有了新的要求,在满足这些要求的同时,还要保持现代分布式执行模型的优势(比如:应用级别的容错保证等等),挑战性很大,根据之前在 Spark、MPI 和 TensorFlow 开发 ML 和 RL(强化学习)的经历,这些痛点更加明显。当然这些要求也是通用的,并不仅仅使用在 ML 和 RL 中。
性能要求
这些 ML 应用也是有严格的延迟和吞吐要求:
- R1:low latency,ML 应用的实时性、reactive 和 interactive 特性都是需要端到端执行的毫秒级延迟;
- R2:High throughput,训练和部署期间的计算都是需要支持每秒几百万 task 执行的高吞吐任务;
执行模型要求
尽管现在业内很多的执行模型已经对常见计算模式的识别和优化取得了很大进展,但 ML 应用还需要更大的灵活性:
- R3:dynamic task creation,诸如蒙卡洛树搜索(Monte Carlo Tree)的 RL 基本算法在执行期间会根据其他 task 执行的结果动态创建新的 task;
- R4:heterogeneous tasks(异构任务),深度学习和 RL 在执行时间和资源需求上差异很大,因此对执行异构任务和资源的支持是非常有必要的;
- R5:arbitrary dataflow dependencies,深度学习和 RL 应用会产生任意且更细粒度的任务依赖;
实践要求
- R6:transparent fault tolerance:容错是一个非常重要和核心的要求,但与高吞吐、非确定性 task 执行放在一起实现就有一定难度了;
- R7:debuggablitity and profiling(调试和性能分析):调试和性能分析是编写任何分布式作业最耗时的方面,ML 应用尤其如此,这些应用通常是计算密集和随机的。
上面的要求与我们常见的大数据计算系统,如:Flink 和 Spark,最大的区别是 R3~R5,对于 Flink 和 Spark 来说,向集群提交的 dataflow graph 是固定的,提交之后是不能改变的,这种模式在 ML 场景就显得非常不灵活了。
业内现况
Static dataflow Systems,它们需要开发者提前设计好 dataflow graph,比如:MR 和 Spark。对于其他的像 Dryad 和 Naiad 的系统,它们是支持复杂的依赖结构(R5);TensorFlow 和 MXNet,它们对深度学习场景做了很多优化。然而没有一个系统,可以完全支持根据输入数据和 task 执行任意动态扩展 dataflow graph。
Dynamic Dataflow Systems,像 CIEL 和 Dask 不但支持上面 static dataflow Systems 的很多特性,还支持动态 task 创建(R3),这些模型符合我们 R3~R5 的需要。然而,它们有一些受限的地方,比如:完全中心化的调度,它们会导致我们不得不在吞吐和 latency 之间做取舍。
Other Systems 像 Open MPI 和基于 actor 模型变体的系统(Orleans 和 Erlang)提供了低延迟(R1)和高吞吐(R2)的分布式计算。尽管这些系统也可以支持我们执行模型的需要(R3-R5,并且已经在 ML 中应用了),但是很多系统 level 的逻辑需求却需要应用程序自己去实现,比如:容错和 task 调度的本地感知。
综上,业内并没有一套可以完全符合我们的需求的系统,所以最好的办法就是重新造轮子,从头开始设计和写一套系统,业内对这块也有了很多的实践,虽然是重头开始设计,但还是可以从业内现有的系统中借鉴很多的经验(毕竟这套系统设计的出发点,也考虑到了通用性,而不仅仅用在 ML 领域)。
解决方案:一套新的架构模型
论文发表的时候,ray 还处于初期,当时的一些架构设计后来也有了一些变化,但本文依然以论文中的架构为主来介绍。
API 和 执行模型
新提出的架构与 Flink 和 Spark 最大区别是在 R3~R5,为了支持这三个执行模型要求,这里设计了一套 API,它允许任意的 function 作为远程的 task 执行(并且还是在 dataflow 中的一环)。
- task 创建是非阻塞的:当一个 task 创建后,会以
future做 task 的返回值,task 是在系统中异步执行的; - 任意 function 的执行都可以作为远程 task 执行:为了支持 R4,function 都可以作为远程 task 执行的;task 创建的参数可以是一个
future,这样的话,新创建的 task 就会依赖这个 future 对应的 task,它也就实现了任意的 DAG 依赖(R5); - 任何执行的 task 都可以在不阻塞它们计算的同时创建新的 task,因此,task 的吞吐不会受到 worker 带宽的限制(R2),并且可以做到动态创建 graph(R3);
- 一个 task 的返回值可以通过调用
get方法得到,它会阻塞直到 task 执行结束; wait方法可以执行批量任务等待,该方法需要指定一个 future 列表、timeout 参数和要返回的 task number 的数量,这个方法会返回 future 任务的子集,它们是在 timeout 达到或满足数量要求时返回的。
这里看这些 API 可能会有一些不太理解,给大家推荐一篇文章:高性能分布式执行框架——Ray,这篇文章对于这些 API 在 ray 上的实现都有详细的示例,有兴趣的可以看下。
架构设计
这里设计的架构也是 Master/Slave 模型,它包含:运行在每个 node 上的 worker 进程、每个 node 会有一个 local scheduler、一个或多个 global scheduler 以及在 worker 间做数据共享的内存对象存储,如下图所示(大家依然可以看下这篇文章 高性能分布式执行框架——Ray,它介绍了 Ray 的落地实现架构,但论文中更多的还是模型设计)。
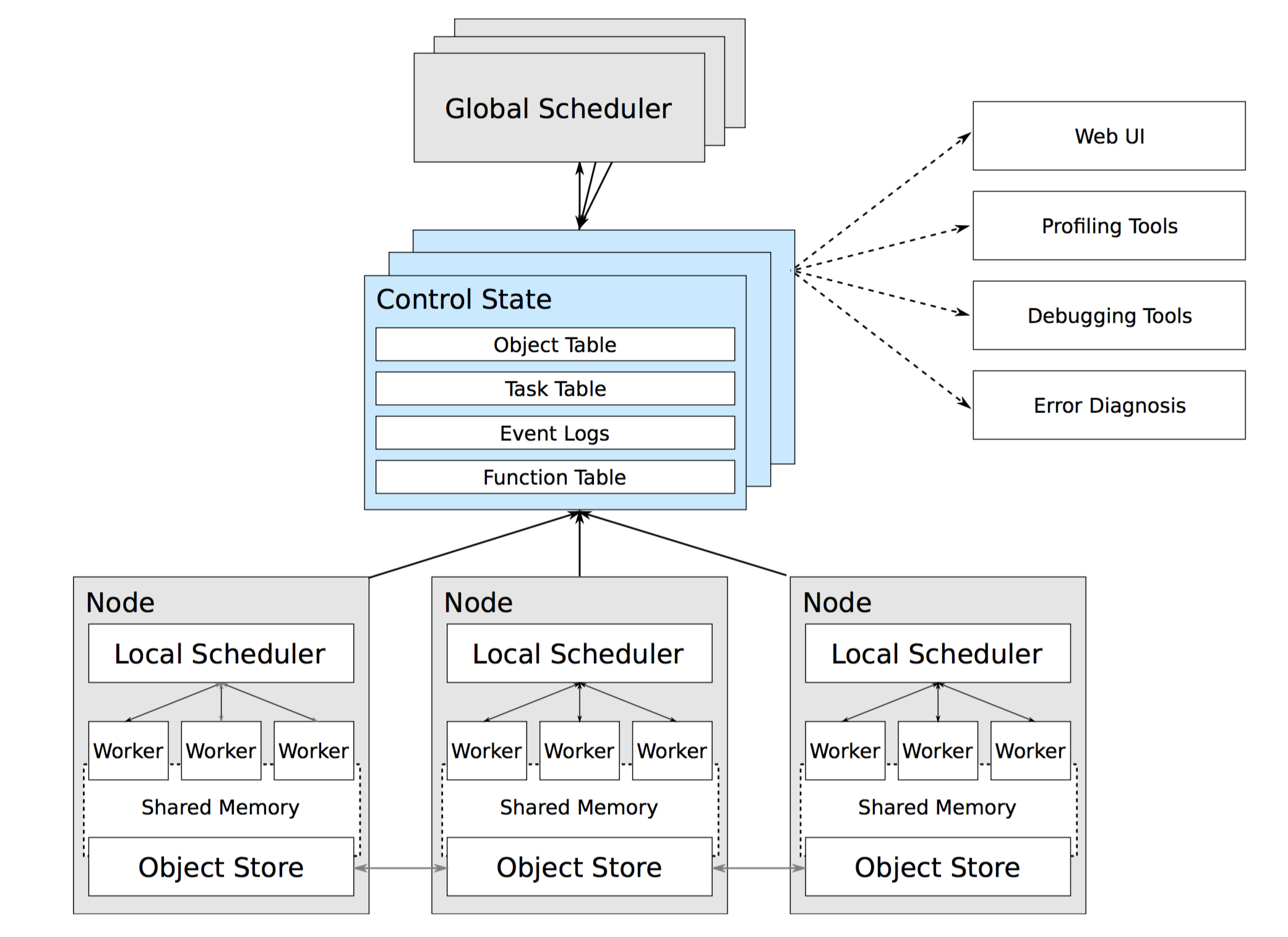
Master 负责全局协调和状态维护,Slave 执行分布式计算任务,不同与传统计算系统的是,它使用了混合任务调度的思路:
- Global Scheduler:Master上启动了一个全局调度器,用于接收本地调度器提交的任务,并将任务分发给合适的本地任务调度器执行;
- Control State(db 服务):Master 上启动了一到多个 db server 用于保存分布式任务的状态信息,包括对象机器的映射、任务描述、任务debug信息等;
- Local Scheduler:每个 Slave 上启动了一个本地调度器,用于接收本地 worker 提交任务的请求以及提交任务请求到全局调度器;
- Worker:每个 Slave 上可以启动多个 Worker 进程执行分布式任务,并将计算结果存储到 ObjectStore;
- Object Store:每个 Slave 上启动了一个 Object Store 存储只读数据对象,Worker 可以通过共享内存的方式访问这些对象数据,这样可以有效地减少内存拷贝和对象序列化成本(Object Store 底层由 Apache Arrow 实现)。
Centralized Control State
如前面图中所示,这套架构是依赖一个逻辑中心控制器,为了实现这套架构,设计时使用了一个 database 来做 Control State 的工作,存储系统的状态信息以及用于系统组件间的通信信息。
在这个设计中,除了 Control State,其他组件都是无状态的,所以只要 Control State 具有容错性,系统就可以简单恢复任务中失败的节点(因为 dataflow graph 是不固定,所以真正实现时 recover 的逻辑与 Spark 和 Flink 这类系统是不同的)(R6
)。为了实现高吞吐,在写数据库的时候,允许按 key hash 写入(R1-R2)。
Hybrid Scheduler
这套架构采用混度调度器的模式,简单来说,在 task 调度时,实现如下:
- worker 提交 task 到本地调度器,它会决定是 assign 到本地本机其他 worker 还是上报到 global 调度器,global 调度器会根据全局信息(资源利用率和计算本地化等因素)来决定把 task 分配到哪个节点上;
- 因为 task 是允许创建其他 task,所以一个集群里的 task 调度请求是可能来自任何的 worker 的;
- 系统允许本地调度器处理本地的调度工作,可以减少与全局调度器的交互,最大限度减少了通信开销。
其他
ray 在真正实现时,提交给作业是一个更细粒度的 remote function,任务 DAG 依赖关系由函数依赖关系自由控制,像 Flink 和 Spark 系统,提交的是任务的 DAG,一旦提交就不能修改。
总结
就像在前面文中说的一样,个人感觉这套架构与目前主流大数据计算引擎最大的区别还是 R3~R5,这样设计也是因为业务场景驱动,static dataflow graph 在一些 ML 和图计算的场景下无法很好的满足业务需求,每套计算引擎最开始要解决的问题都不太一样,都有一个自己的切入点,只不过做着做着大家发现自己的场景很有限,都想切入到更多的领域,做一个更加通用的引擎,通用引擎对于一些简单业务场景来说可能会显得特别重、对另一些复杂业务场景来说可能又显得不能完全支持,这也是计算引擎最近几年遍地开花的原因,而且相信未来还会有很大变化。而且现在有个趋势:对于业务来说,大家发现没有必要非要使用什么统一的引擎,引擎(包括存储和计算)是什么我可以完全不 care,面向用户的是统一的 DSL,用什么引擎由平台来帮业务选择,这个或许是一个趋势,但从另一个方面来说维护多套引擎的成本有点高,就像现在公司不会选择在服务器维护很多套操作系统一样,最终会是什么样子,过几年再看。
业内实践
关于 ray,目前国内看到的是蚂蚁金服有在使用,其他公司好像没有听说过,ray 目前已经在蚂蚁金服的很多业务上落地,这个大家可以参考今年阿里云栖大会上蚂蚁金服的分享(见:开放计算架构:蚂蚁金服是如何用一套架构容纳所有计算的?),可以看到 ray 中落地比较好的场景还是 ML 和图计算相关的业务,关于图计算,国内估计也只有蚂蚁和腾讯有这么强烈的业务需求。刚好今天看到一篇文章 —— 腾讯开源全栈机器学习平台 Angel 3.0,支持三大类型图计算算法,腾讯这边在图计算这块选择了他们开源的 Angel 平台做图计算,他们有兴趣地的可以深入看下。
最后,说点题外话,笔者本来计划今年每个月都要输出一篇经典论文的阅读笔记的,但不料的是,今年工作实在是太忙太累,很多计划并没有落地执行,后面会多花点工作之外的时间把今年欠的博客补一下,最近也会开始写 Apache Flink1.9 源码分析系列以及 Paper 阅读总结系列,文章会在公众号同步发布,大家多多关注。

参考:
