Kafka 源码解析之 LeaderAndIsr 请求的处理(二十二)
本篇算是 Controller 部分的最后一篇,在前面讲述 ReplicaManager 时,留一个地方没有讲解,是关于 Broker 对 Controller 发送的 LeaderAndIsr 请求的处理,这个请求的处理实现会稍微复杂一些,本篇文章主要就是讲述 Kafka Server 是如何处理 LeaderAndIsr 请求的。
LeaderAndIsr 请求
LeaderAndIsr 请求是在一个 Topic Partition 的 leader、isr、assignment replicas 变动时,Controller 向 Broker 发送的一种请求,有时候是向这个 Topic Partition 的所有副本发送,有时候是其中的某个副本,跟具体的触发情况有关系。在一个 LeaderAndIsr 请求中,会封装多个 Topic Partition 的信息,每个 Topic Partition 会对应一个 PartitionState 对象,这个对象主要成员变量如下:
1 | public class PartitionState { |
由此可见,在 LeaderAndIsr 请求中,会包含一个 Partition 的以下信息:
- 当前 Controller 的 epoch(Broker 收到这个请求后,如果发现是过期的 Controller 请求,就会拒绝这个请求);
- leader,Partition 的 leader 信息;
- leader epoch,Partition leader epoch 信息(leader、isr、AR 变动时,这个 epoch 都会加1);
- isr 列表;
- zkVersion,;
- AR,所有的 replica 列表。
LeaderAndIsr 请求处理
处理整体流程
LeaderAndIsr 请求可谓是包含了一个 Partition 的所有 metadata 信息,Server 在接收到 Controller 发送的这个请求后,其处理的逻辑如下:
1 | //KafkaApis |
上述处理逻辑分为以下两步:
- ReplicaManager 调用
becomeLeaderOrFollower()方法对这个请求进行相应的处理; - 如果请求中包含
__consumer_offset的 Partition(对应两种情况:之前是 fllower 现在变成了 leader、之前是 leader 现在变成了 follower),那么还需要调用这个方法中定义的onLeadershipChange()方法进行相应的处理。
becomeLeaderOrFollower() 的整体处理流程如下:
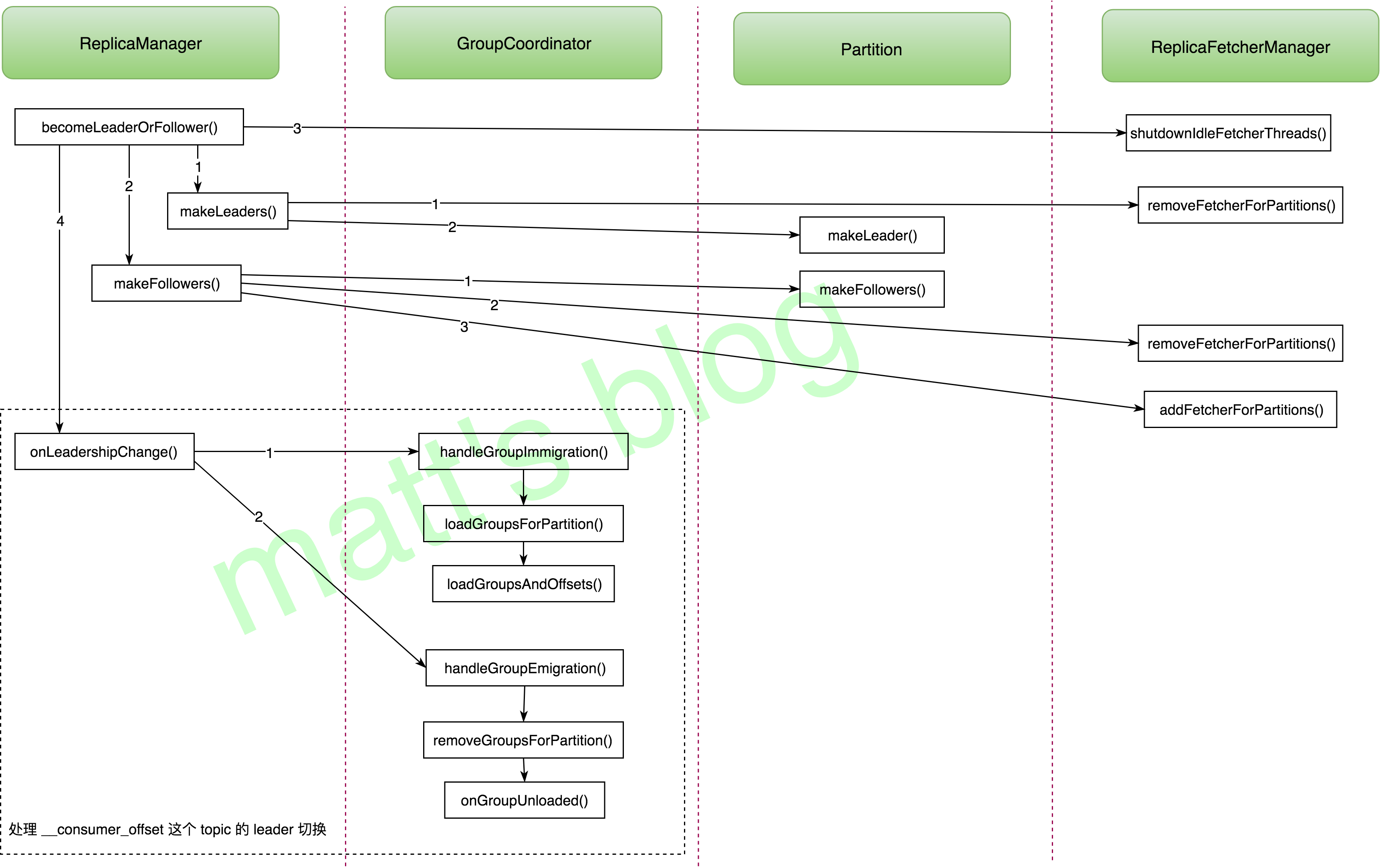
becomeLeaderOrFollower
这里先看下 ReplicaManager 的 becomeLeaderOrFollower() 方法,它是 LeaderAndIsr 请求处理的实现,如下所示:
1 | //note: 处理 LeaderAndIsr 请求 |
上述实现,其处理逻辑总结如下:
- 检查 Controller 的 epoch,如果是来自旧的 Controller,那么就拒绝这个请求;
- 获取请求的 Partition 列表的 PartitionState 信息,在遍历的过程中,会进行一个检查,如果 leader epoch 小于缓存中的 epoch 值,那么就过滤掉这个 Partition 信息,如果这个 Partition 在本地不存在,那么会初始化这个 Partition 的对象(这时候并不会初始化本地副本);
- 获取出本地副本为 leader 的 Partition 列表(partitionsTobeLeader);
- 获取出本地副本为 follower 的 Partition 列表(partitionsToBeFollower);
- 调用
makeLeaders()方法将 leader 的副本设置为 leader; - 调用
makeFollowers()方法将 leader 的副本设置为 follower; - 检查 HW checkpoint 的线程是否初始化,如果没有,这里需要进行一次初始化;
- 检查 ReplicaFetcherManager 是否有线程需要关闭(如果这个线程上没有分配要拉取的 Topic Partition,那么在这里这个线程就会被关闭,下次需要时会再次启动);
- 检查是否有
__consumer_offsetPartition 的 leaderAndIsr 信息,有的话进行相应的操作。
这其中,比较复杂的部分是第 5、6、9步,也前面图中标出的 1、2、4步,文章下面接着分析这三部分。
makeLeaders
ReplicaManager 的 makeLeaders() 的作用是将指定的这批 Partition 列表设置为 Leader,并返回是新 leader 对应的 Partition 列表(之前不是 leader,现在选举为了 leader),其实实现如下:
1 | //note: 选举当前副本作为 partition 的 leader,处理过程: |
实现逻辑如下:
- 调用 ReplicaFetcherManager 的
removeFetcherForPartitions()方法移除这些 Partition 的副本同步线程; - 遍历这些 Partition,通过 Partition 的
makeLeader()方法将这个 Partition 设置为 Leader,如果设置成功(如果 leader 没有变化,证明这个 Partition 之前就是 leader,这个方法返回的是 false,这种情况下不会更新到缓存中),那么将 leader 信息更新到缓存中。
下面来看下在 Partition 中是如何真正初始化一个 Partition 的 leader?其实现如下:
1 | //note: 将本地副本设置为 leader, 如果 leader 不变,向 ReplicaManager 返回 false |
简单总结一下上述的实现:
- 首先更新这个 Partition 的相应信息,包括:isr、AR、leader epoch、zkVersion 等,并为每个副本创建一个 Replica 对象(如果不存在该对象的情况下才会创建,只有本地副本才会初始化相应的日志对象);
- 如果这个 Partition 的 leader 本来就是本地副本,那么返回的结果设置为 false,证明这个 leader 并不是新的 leader;
- 对于 isr 中的所有 Replica,更新 LastCaughtUpTime 值,即最近一次赶得上 leader 的时间;
- 如果是新的 leader,那么为 leader 初始化相应的 HighWatermarkMetadata 对象,并将所有副本的副本同步信息更新为 UnknownLogReadResult;
- 检查一下是否需要更新 HW 值。
如果这个本地副本是新选举的 leader,那么它所做的事情就是初始化 Leader 应该记录的相关信息。
makeFollowers
ReplicaManager 的 makeFollowers() 方法,是将哪些 Partition 设置为 Follower,返回的结果是那些新的 follower 对应的 Partition 列表(之前是 leader,现在变成了 follower),其实现如下:
1 | private def makeFollowers(controllerId: Int, |
简单总结一下上述的逻辑过程:
- 首先遍历所有的 Partition,获到那些 leader 可用、并且 Partition 可以成功设置为 Follower 的 Partition 列表(partitionsToMakeFollower);
- 在上面遍历的过程中,会调用 Partition 的
makeFollower()方法将 Partition 设置为 Follower(在这里,如果该 Partition 的本地副本不存在,会初始化相应的日志对象,如果该 Partition 的 leader 已经存在,并且没有变化,那么就返回 false,只有 leader 变化的 Partition,才会返回 true,才会加入到 partitionsToMakeFollower 集合中,这是因为 leader 没有变化的 Partition 是不需要变更副本同步线程的); - 移除这些 Partition 的副本同步线程,这样在 MakeFollower 期间,这些 Partition 就不会进行副本同步了;
- Truncate the partition logs to the specified offsets and checkpoint the recovery point to this offset,因为前面已经移除了这个 Partition 的副本同步线程,所以这里在 checkpoint 后可以保证所有缓存的数据都可以刷新到磁盘;
- 完成那些延迟请求的处理(Produce 和 FetchConsumer 请求);
- 启动相应的副本同步线程。
到这里 LeaderAndIsr 请求的大部分处理已经完成,但是有一个比较特殊的 topic(__consumer_offset),如果这 Partition 的 leader 发生变化,是需要一些额外的处理。
__consumer_offset leader 切换处理
__consumer_offset 这个 Topic 如果发生了 leader 切换,GroupCoordinator 需要进行相应的处理,其处理过程如下:
1 | def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) { |
成为 leader
如果当前节点这个 __consumer_offset 有 Partition 成为 leader,GroupCoordinator 通过 handleGroupImmigration() 方法进行相应的处理。
1 | //note: 加载这个 Partition 对应的 group offset 信息 |
这个方法的做的事情是:
- 将正在处理的 Partition 添加到 loadingPartitions 集合中,这个集合内都是当前正在加载的 Partition(特指
__consumer_offsetTopic); - 通过
loadGroupsAndOffsets()加载这个 Partition 的数据,处理完成后,该 Partition 从 loadingPartitions 中清除,并添加到 ownedPartitions 集合中。
loadGroupsAndOffsets() 的实现如下:
1 | //note: 读取该 group offset Partition 数据 |
上面方法的实现虽然比较长,但是处理逻辑还是比较简单的,实现结果如下:
- 获取这个 Partition 的 HW 值(如果 leader 不在本地,那么返回-1);
- 初始化 loadedOffsets 和 removedOffsets、loadedGroups 和 removedGroups 集合,它们就是 group offset 信息以及 consumer member 信息;
- 从这个 Partition 第一条数据开始读取,直到读取到 HW 位置,加载相应的 commit offset、consumer member 信息,因为是顺序读取的,所以会新的值会覆盖前面的值;
- 通过
loadGroup()加载到 GroupCoordinator 的缓存中。
经过上面这些步骤,这个 Partition 的数据就被完整加载缓存中了。
变成 follower
如果 __consumer_offset 有 Partition 变成了 follower(之前是 leader,如果之前不是 leader,不会走到这一步的),GroupCoordinator 通过 handleGroupEmigration() 移除这个 Partition 相应的缓存信息。
1 | //note: 移除这个 Partition 对应的 group offset 信息 |
removeGroupsForPartition() 的实现如下:
1 | //note: 当一个 broker 变成一个 follower 时,清空这个 partition 的相关缓存信息 |
对于在这个 Partition 上的所有 Group,会按下面的步骤执行:
- 通过
onGroupUnloaded()方法先将这个 Group 的状态转换为 dead,如果 Group 处在 PreparingRebalance/Stable/AwaitingSync 状态,并且设置了相应的回调函数,那么就在回调函数中返回带有 NOT_COORDINATOR_FOR_GROUP 异常信息的响应,consumer 在收到这个异常信息会重新加入 group; - 从缓存中移除这个 Group 的信息。
这个遍历执行完成之后,这个 Topic Partition 就从 Leader 变成了 follower 状态。
