Kafka 源码解析之 Producer 单 Partition 顺序性实现及配置说明(五)
今天把 Kafka Producer 最后一部分给讲述一下,Producer 大部分内容都已经在前面几篇文章介绍过了,这里简单做个收尾,但并不是对前面的总结,本文从两块来讲述:RecordAccumulator 类的实现、Kafka Producer 如何保证其顺序性以及 Kafka Producer 的配置说明,每个 Producer 线程都会有一个 RecordAccumulator 对象,它负责缓存要发送 RecordBatch、记录发送的状态并且进行相应的处理,这里会详细讲述 Kafka Producer 如何保证单 Partition 的有序性。最后,简单介绍一下 Producer 的参数配置说明,只有正确地理解 Producer 相关的配置参数,才能更好地使用 Producer,发挥其相应的作用。
RecordAccumulator
这里再看一下 RecordAccumulator 的数据结构,如下图所示,每个 topic-partition 都有一个对应的 deque,deque 中存储的是 RecordBatch,它是发送的基本单位,只有这个 topic-partition 的 RecordBatch 达到大小或时间要求才会触发发送操作(但并不是只有达到这两个条件之一才会被发送,这点要理解清楚)。
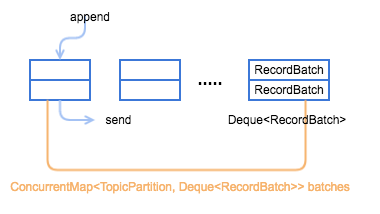
再看一下 RecordAccumulator 类的主要方法介绍,如下图所示。
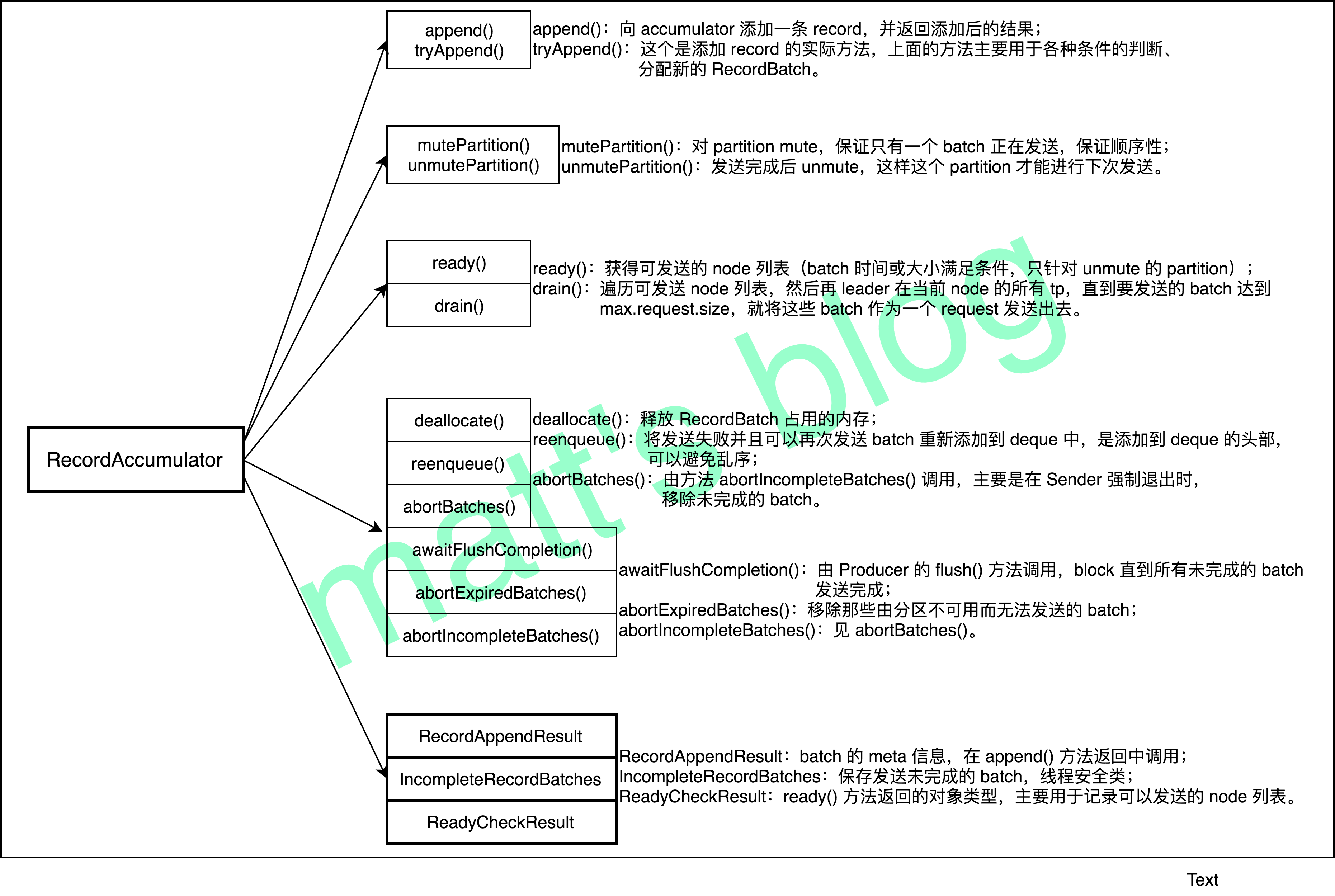
这张图基本上涵盖了 RecordAccumulator 的主要方法,下面会选择其中几个方法详细讲述,会围绕着 Kafka Producer 如何实现单 Partition 顺序性这个主题来讲述。
mutePartition() 与 unmutePartition()
先看下 mutePartition() 与 unmutePartition() 这两个方法,它们是保证有序性关键之一,其主要做用就是将指定的 topic-partition 从 muted 集合中加入或删除,后面会看到它们的作用。
1 | private final Set<TopicPartition> muted; |
这里先说一下这两个方法调用的条件,这样的话,下面在介绍其他方法时才会更容易理解:
mutePartition():如果要求保证顺序性,那么这个 tp 对应的 RecordBatch 如果要开始发送,就将这个 tp 加入到muted集合中;unmutePartition():如果 tp 对应的 RecordBatch 发送完成,tp 将会从muted集合中移除。
也就是说,muted 是用来记录这个 tp 是否有还有未完成的 RecordBatch。
ready()
ready() 是在 Sender 线程中调用的,其作用选择那些可以发送的 node,也就是说,如果这个 tp 对应的 batch 可以发送(达到时间或大小要求),就把 tp 对应的 leader 选出来。
1 | public ReadyCheckResult ready(Cluster cluster, long nowMs) { |
可以看到这一行 (!readyNodes.contains(leader) && !muted.contains(part)),如果 muted 集合包含这个 tp,那么在遍历时将不会处理它对应的 deque,也就是说,如果一个 tp 加入了 muted 集合中,即使它对应的 RecordBatch 可以发送了,也不会触发引起其对应的 leader 被选择出来。
drain()
drain() 是用来遍历可发送请求的 node,然后再遍历在这个 node 上所有 tp,如果 tp 对应的 deque 有数据,将会被选择出来直到超过一个请求的最大长度(max.request.size)为止,也就说说即使 RecordBatch 没有达到条件,但为了保证每个 request 尽快多地发送数据提高发送效率,这个 RecordBatch 依然会被提前选出来并进行发送。
1 | //note: 返回该 node 对应的可以发送的 RecordBatch 的 batches,并从 queue 中移除(最大的大小为maxSize,超过的话,下次再发送) |
在遍历 node 的所有 tp 时,可以看到是有条件的 —— !muted.contains(tp),如果这个 tp 被添加到 muted 集合中,那么它将不会被遍历,也就不会作为 request 一部分被发送出去,这也就保证了 tp 如果还有未完成的 RecordBatch,那么其对应 deque 中其他 RecordBatch 即使达到条件也不会被发送,就保证了 tp 在任何时刻只有一个 RecordBatch 在发送。
顺序性如何保证?
是否保证顺序性,还是在 Sender 线程中实现的,mutePartition() 与 unmutePartition() 也都是在 Sender 中调用的,这里看一下 KafkaProducer 是如何初始化一个 Sender 对象的。
1 | // from KafkaProducer |
对于上述过程可以这样进行解读
this.guaranteeMessageOrder = (config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION) == 1)
如果 KafkaProducer 的 max.in.flight.requests.per.connection 设置为1,那么就可以保证其顺序性,否则的话,就不保证顺序性,从下面这段代码也可以看出。
1 | //from Sender |
也就是说,如果要保证单 Partition 的顺序性,需要在 Producer 中配置 max.in.flight.requests.per.connection=1,而其实现机制则是在 RecordAccumulator 中实现的。
Producer Configs
这里是关于 Kafka Producer 一些配置的说明,内容来自官方文档Producer Configs以及自己的一些个人理解,这里以官方文档保持一致,按其重要性分为三个级别进行讲述(涉及到权限方面的参数,这里先不介绍)。
high importance
| 参数名 | 说明 | 默认值 |
|---|---|---|
| bootstrap.servers | Kafka Broker 的一个列表,不用包含所有的 Broker,它用于初始化连接时,通过这几个 broker 来获取集群的信息,比如:127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092 |
- |
| key.serializer | 对 key 进行序列化的 class,一般使用StringSerializer |
- |
| value.serializer | 对 value 进行序列化的 class,一般使用 StringDeserializer |
- |
| acks | 用于设置在什么情况一条才被认为已经发送成功了。acks=0:msg 只要被 producer 发送出去就认为已经发送完成了;acks=1:如果 leader 接收到消息并发送 ack (不会等会该 msg 是否同步到其他副本)就认为 msg 发送成功了; acks=all或者-1:leader 接收到 msg 并从所有 isr 接收到 ack 后再向 producer 发送 ack,这样才认为 msg 发送成功了,这是最高级别的可靠性保证。 | 1 |
| buffer.memory | producer 可以使用的最大内存,如果超过这个值,producer 将会 block max.block.ms 之后抛出异常。 |
33554432(32MB) |
| compression.type | Producer 数据的压缩格式,可以选择 none、gzip、snappy、lz4 | none |
| retries | msg 发送失败后重试的次数,允许重试,如果 max.in.flight.requests.per.connection 设置不为1,可能会导致乱序 |
0 |
medium importance
下面的这些参数虽然被描述为 medium,但实际上对 Producer 的吞吐量等影响也同样很大,在实践中跟 high 参数的重要性基本一样。
| 参数名 | 说明 | 默认值 |
|---|---|---|
| batch.size | producer 向 partition 发送数据时,是以 batch 形式的发送数据,当 batch 的大小超过 batch.size 或者时间达到 linger.ms 就会发送 batch,根据经验,设置为1MB 吞吐会更高,太小的话吞吐小,太大的话导致内存浪费进而影响吞吐量 |
16384(16KB) |
| linger.ms | 在一个 batch 达不到 batch.size 时,这个 batch 最多将会等待 linger.ms 时间,超过这个时间这个 batch 就会被发送,但也会带来相应的延迟,可以根据具体的场景进行设置 |
0 |
| client.id | client 的 id,主要用于追踪 request 的来源 | null |
| connections.max.idle.ms | 如果 connection 连续空闲时间超过了这个值,将会被关闭,主要使用 Selector 的 maybeCloseOldestConnection 方法 |
540000(9min) |
| max.block.ms | 控制 KafkaProducer.send() 和 KafkaProducer.partitionsFor() block 的最大时间,block 的原因是 buffer 满了或者 metadata 不可用导致。 |
60000 |
| max.request.size | 一个请求的最大长度 | 1048576(1MB) |
| partitioner.class | 获取 topic 分区的 class | org.apache.kafka.clients.producer.internals.DefaultPartitioner |
| receive.buffer.bytes | 在读取数据时 TCP receive buffer (SO_RCVBUF)的大小 | 32768(32KB) |
| request.timeout.ms | 如果 producer 超过这么长时间没有收到 response,将会再次发送请求 | 30000 |
| timeout.ms | 用于配置 leader 等待 isr 返回 ack 的最大时间,如果超过了这个时间,将会返回给 producer 一个错误。 | 30000 |
low importance
| 参数名 | 说明 | 默认值 |
|---|---|---|
| block.on.buffer.full | 当 Producer 使用 buffer 达到最大设置时,如果设置为 false,将会 block max.block.ms 后然后抛出 TimeoutException 异常,如果设置为 true,将会把 max.block.ms 设置为 Long.MAX_VALUE。 |
false |
| interceptor.classes | 使用拦截器,实现这个 ProducerInterceptor 接口,可以对 topic 进行简单的处理。 |
null |
| max.in.flight.requests.per.connection | 对一个 connection,同时发送最大请求数,不为1时,不能保证顺序性。 | 5 |
| metadata.fetch.timeout.ms | 获取 metadata 时的超时时间 | 60000 |
| metadata.max.age.ms | 强制 metadata 定时刷新的间隔 | 300000(5min) |
| metric.reporters | A list of classes to use as metrics reporters. Implementing the MetricReporter interface,JmxReporter 是默认被添加的。 | “” |
| metrics.num.samples | 统计 metrics 时采样的次数 | 2 |
| metrics.sample.window.ms | metrics 采样计算的时间窗口 | 30000 |
| reconnect.backoff.ms | 重新建立建立连接的间隔 | 50 |
| retry.backoff.ms | 发送重试的间隔 | 100 |
对于不同的场景,合理配置相应的 Kafka Producer 参数。
至此,Kafka Producer 部分的源码分析已经结束,从下周开始将开始对 Kafka Consumer 部分进行分析。
