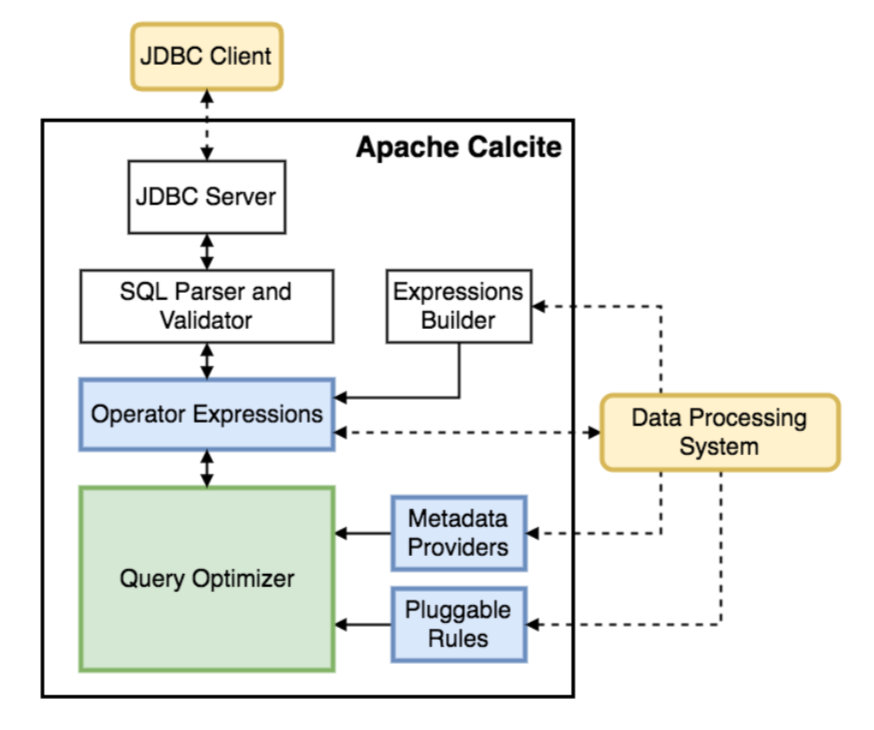
Apache Calcite is a foundational software framework that provides query processing, optimization, and query language support to many popular open-source data processing systems such as Apache Hive, Apache Storm, Apache Flink, Druid, and MapD. Calcite’s architecture consists of
a modular and extensible query optimizer with hundreds of built-in optimization rules,
a query processor capable of processing a variety of query languages,
an adapter architecture designed for extensibility,
and support for heterogeneous data models and stores (relational, semi-structured, streaming, and geospatial). This flexible, embeddable, and extensible architecture is what makes Calcite an attractive choice for adoption in bigdata frameworks. It is an active project that continues to introduce support for the new types of data sources, query languages, and approaches to query processing and optimization.
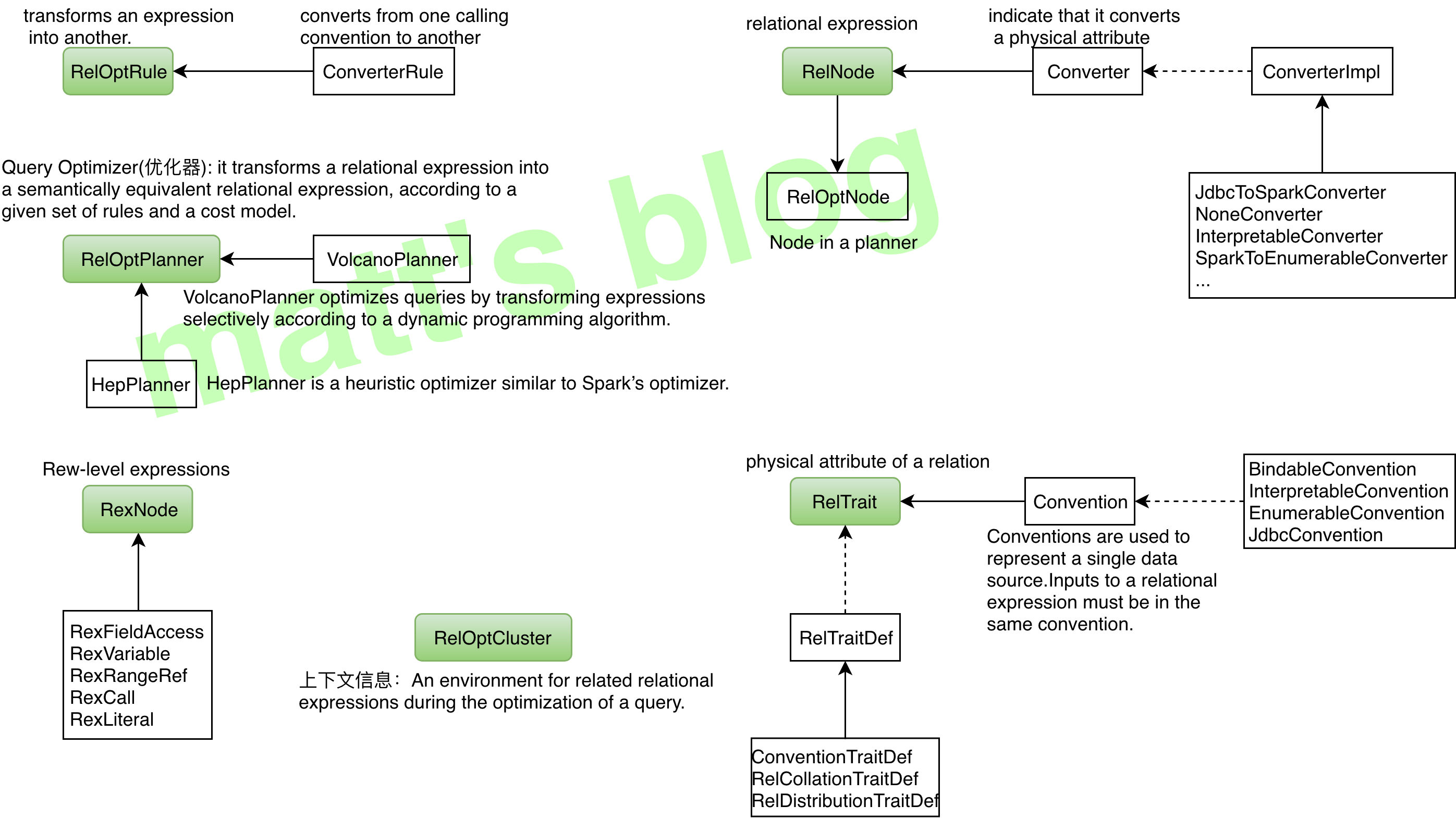
A relational expression implements the interface Converter to indicate that it converts a physical attribute, or RelTrait of a relational expression from one value to another.
An environment for related relational expressions during the optimization of a query.
palnner 运行时的环境,保存上下文信息;
RelOptPlanner
A RelOptPlanner is a query optimizer: it transforms a relational expression into a semantically equivalent relational expression, according to a given set of rules and a cost model.
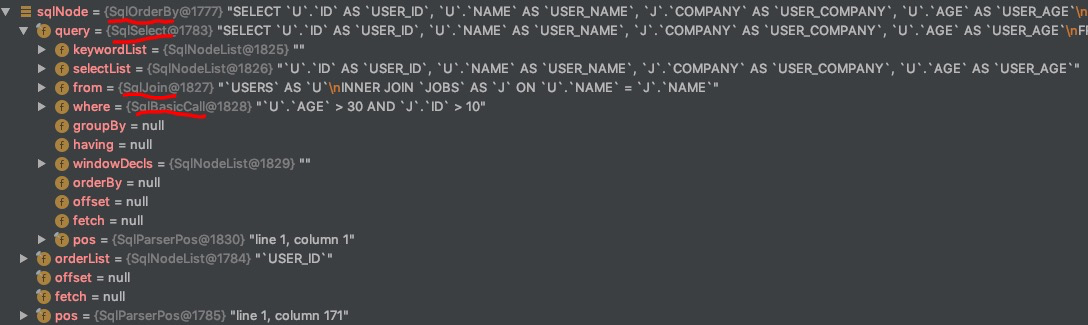
select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age fromusers u join jobs j on u.name=j.name where u.age > 30and j.id>10 orderby user_id
//note: 二、sql validate(会先通过Catalog读取获取相应的metadata和namespace) //note: get metadata and namespace SqlTypeFactoryImpl factory = new SqlTypeFactoryImpl(RelDataTypeSystem.DEFAULT); CalciteCatalogReader calciteCatalogReader = new CalciteCatalogReader( CalciteSchema.from(rootScheme), CalciteSchema.from(rootScheme).path(null), factory, new CalciteConnectionConfigImpl(new Properties()));
//org.apache.calcite.schema.impl.AbstractSchema /** * Returns a map of tables in this schema by name. * * <p>The implementations of {@link #getTableNames()} * and {@link #getTable(String)} depend on this map. * The default implementation of this method returns the empty map. * Override this method to change their behavior.</p> * * @return Map of tables in this schema by name */ protected Map<String, Table> getTableMap(){ return ImmutableMap.of(); }
org.apache.calcite.runtime.CalciteContextException: From line 1, column 156 to line 1, column 158: Column 'IDS' not found in table 'J' at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.calcite.runtime.Resources$ExInstWithCause.ex(Resources.java:463) at org.apache.calcite.sql.SqlUtil.newContextException(SqlUtil.java:787) at org.apache.calcite.sql.SqlUtil.newContextException(SqlUtil.java:772) at org.apache.calcite.sql.validate.SqlValidatorImpl.newValidationError(SqlValidatorImpl.java:4788) at org.apache.calcite.sql.validate.DelegatingScope.fullyQualify(DelegatingScope.java:439) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visit(SqlValidatorImpl.java:5683) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visit(SqlValidatorImpl.java:5665) at org.apache.calcite.sql.SqlIdentifier.accept(SqlIdentifier.java:334) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:134) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:101) at org.apache.calcite.sql.SqlOperator.acceptCall(SqlOperator.java:865) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visitScoped(SqlValidatorImpl.java:5701) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:50) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:33) at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:138) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:134) at org.apache.calcite.sql.util.SqlShuttle$CallCopyingArgHandler.visitChild(SqlShuttle.java:101) at org.apache.calcite.sql.SqlOperator.acceptCall(SqlOperator.java:865) at org.apache.calcite.sql.validate.SqlValidatorImpl$Expander.visitScoped(SqlValidatorImpl.java:5701) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:50) at org.apache.calcite.sql.validate.SqlScopedShuttle.visit(SqlScopedShuttle.java:33) at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:138) at org.apache.calcite.sql.validate.SqlValidatorImpl.expand(SqlValidatorImpl.java:5272) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateWhereClause(SqlValidatorImpl.java:3977) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelect(SqlValidatorImpl.java:3305) at org.apache.calcite.sql.validate.SelectNamespace.validateImpl(SelectNamespace.java:60) at org.apache.calcite.sql.validate.AbstractNamespace.validate(AbstractNamespace.java:84) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateNamespace(SqlValidatorImpl.java:977) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateQuery(SqlValidatorImpl.java:953) at org.apache.calcite.sql.SqlSelect.validate(SqlSelect.java:216) at org.apache.calcite.sql.validate.SqlValidatorImpl.validateScopedExpression(SqlValidatorImpl.java:928) at org.apache.calcite.sql.validate.SqlValidatorImpl.validate(SqlValidatorImpl.java:632) at com.matt.test.calcite.test.SqlTest3.sqlToRelNode(SqlTest3.java:200) at com.matt.test.calcite.test.SqlTest3.main(SqlTest3.java:117) Caused by: org.apache.calcite.sql.validate.SqlValidatorException: Column 'IDS' not found in table 'J' at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.calcite.runtime.Resources$ExInstWithCause.ex(Resources.java:463) at org.apache.calcite.runtime.Resources$ExInst.ex(Resources.java:572) ... 33 more java.lang.NullPointerException at org.apache.calcite.plan.hep.HepPlanner.addRelToGraph(HepPlanner.java:806) at org.apache.calcite.plan.hep.HepPlanner.setRoot(HepPlanner.java:152) at com.matt.test.calcite.test.SqlTest3.main(SqlTest3.java:124)
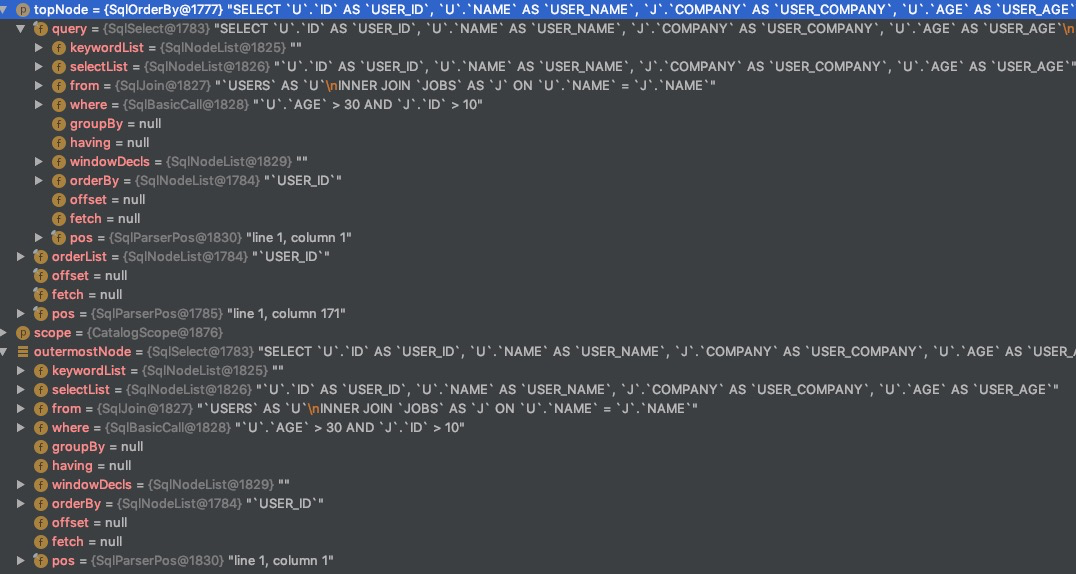
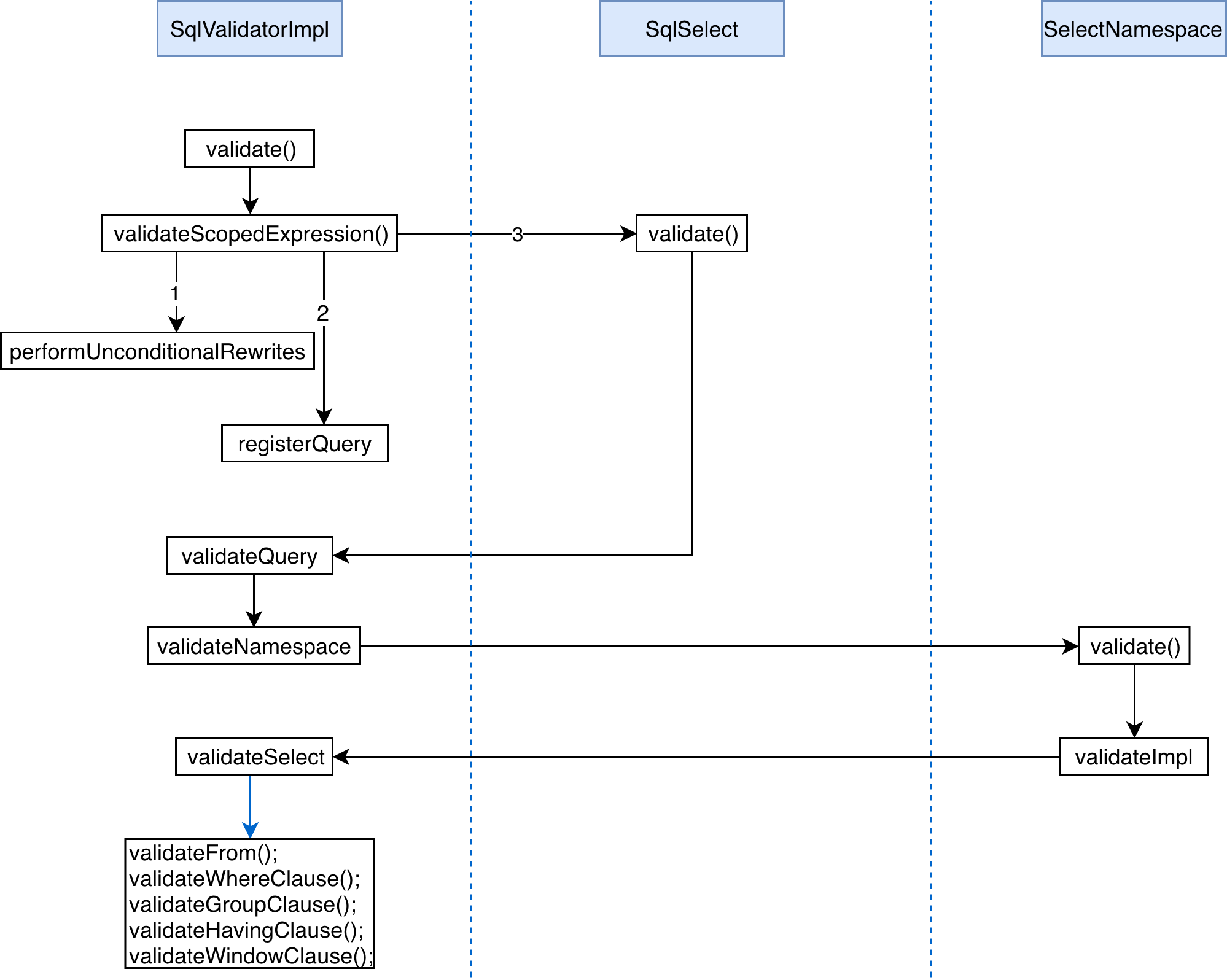
private SqlNode validateScopedExpression( SqlNode topNode, SqlValidatorScope scope){ //note: 1. rewrite expression,将其标准化,便于后面的逻辑计划优化 SqlNode outermostNode = performUnconditionalRewrites(topNode, false); cursorSet.add(outermostNode); top = outermostNode; TRACER.trace("After unconditional rewrite: {}", outermostNode); //note: 2. Registers a query in a parent scope. //note: register scopes and namespaces implied a relational expression if (outermostNode.isA(SqlKind.TOP_LEVEL)) { registerQuery(scope, null, outermostNode, outermostNode, null, false); } //note: 3. catalog 验证,调用 SqlNode 的 validate 方法, outermostNode.validate(this, scope); if (!outermostNode.isA(SqlKind.TOP_LEVEL)) { // force type derivation so that we can provide it to the // caller later without needing the scope deriveType(scope, outermostNode); } TRACER.trace("After validation: {}", outermostNode); return outermostNode; }
/** * Parse tree node that represents an {@code ORDER BY} on a query other than a * {@code SELECT} (e.g. {@code VALUES} or {@code UNION}). * * <p>It is a purely syntactic operator, and is eliminated by * {@link org.apache.calcite.sql.validate.SqlValidatorImpl#performUnconditionalRewrites} * and replaced with the ORDER_OPERAND of SqlSelect.</p> */ publicclassSqlOrderByextendsSqlCall{
/** * <h3>Scopes</h3> * * <p>In the query</p> * * <blockquote> * <pre> * SELECT expr1 * FROM t1, * t2, * (SELECT expr2 FROM t3) AS q3 * WHERE c1 IN (SELECT expr3 FROM t4) * ORDER BY expr4</pre> * </blockquote> * * <p>The scopes available at various points of the query are as follows:</p> * * <ul> * <li>expr1 can see t1, t2, q3</li> * <li>expr2 can see t3</li> * <li>expr3 can see t4, t1, t2</li> * <li>expr4 can see t1, t2, q3, plus (depending upon the dialect) any aliases * defined in the SELECT clause</li> * </ul> * * <h3>Namespaces</h3> * * <p>In the above query, there are 4 namespaces:</p> * * <ul> * <li>t1</li> * <li>t2</li> * <li>(SELECT expr2 FROM t3) AS q3</li> * <li>(SELECT expr3 FROM t4)</li> */
validateNamespace(ns, targetRowType);//note: 检查 switch (node.getKind()) { case EXTEND: // Until we have a dedicated namespace for EXTEND deriveType(scope, node); } if (node == top) { validateModality(node); } validateAccess( node, ns.getTable(), SqlAccessEnum.SELECT); }
/** * Validates a namespace. * * @param namespace Namespace * @param targetRowType Desired row type, must not be null, may be the data * type 'unknown'. */ protectedvoidvalidateNamespace(final SqlValidatorNamespace namespace, RelDataType targetRowType){ namespace.validate(targetRowType);//note: 验证 if (namespace.getNode() != null) { setValidatedNodeType(namespace.getNode(), namespace.getType()); } }
// create the rexBuilder final RexBuilder rexBuilder = new RexBuilder(factory); // init the planner // 这里也可以注册 VolcanoPlanner,这一步 planner 并没有使用 HepProgramBuilder builder = new HepProgramBuilder(); RelOptPlanner planner = new HepPlanner(builder.build());
//note: init cluster: An environment for related relational expressions during the optimization of a query. final RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder); //note: init SqlToRelConverter final SqlToRelConverter.Config config = SqlToRelConverter.configBuilder() .withConfig(frameworkConfig.getSqlToRelConverterConfig()) .withTrimUnusedFields(false) .withConvertTableAccess(false) .build(); //note: config // 创建 SqlToRelConverter 实例,cluster、calciteCatalogReader、validator 都传进去了,SqlToRelConverter 会缓存这些对象 final SqlToRelConverter sqlToRelConverter = new SqlToRelConverter(new DogView(), validator, calciteCatalogReader, cluster, StandardConvertletTable.INSTANCE, config); // convert to RelNode RelRoot root = sqlToRelConverter.convertQuery(validateSqlNode, false, true);
/** * Converts an unvalidated query's parse tree into a relational expression. * note:把一个 parser tree 转换为 relational expression * @param query Query to convert * @param needsValidation Whether to validate the query before converting; * <code>false</code> if the query has already been * validated. * @param top Whether the query is top-level, say if its result * will become a JDBC result set; <code>false</code> if * the query will be part of a view. */ public RelRoot convertQuery( SqlNode query, finalboolean needsValidation, finalboolean top){ if (needsValidation) { //note: 是否需要做相应的校验(如果校验过了,这里就不需要了) query = validator.validate(query); }
//note: 设置 MetadataProvider RelMetadataQuery.THREAD_PROVIDERS.set( JaninoRelMetadataProvider.of(cluster.getMetadataProvider())); //note: 得到 RelNode(relational expression) RelNode result = convertQueryRecursive(query, top, null).rel; if (top) { if (isStream(query)) {//note: 如果 stream 的话 result = new LogicalDelta(cluster, result.getTraitSet(), result); } } RelCollation collation = RelCollations.EMPTY; if (!query.isA(SqlKind.DML)) { //note: 如果是 DML 语句 if (isOrdered(query)) { //note: 如果需要做排序的话 collation = requiredCollation(result); } } //note: 对转换前后的 RelDataType 做验证 checkConvertedType(query, result);
if (SQL2REL_LOGGER.isDebugEnabled()) { SQL2REL_LOGGER.debug( RelOptUtil.dumpPlan("Plan after converting SqlNode to RelNode", result, SqlExplainFormat.TEXT, SqlExplainLevel.EXPPLAN_ATTRIBUTES)); }
/** * Implementation of {@link #convertSelect(SqlSelect, boolean)}; * derived class may override. */ protectedvoidconvertSelectImpl( final Blackboard bb, SqlSelect select){ //note: convertFrom convertFrom( bb, select.getFrom()); //note: convertWhere convertWhere( bb, select.getWhere());
final List<SqlNode> orderExprList = new ArrayList<>(); final List<RelFieldCollation> collationList = new ArrayList<>(); //note: 有 order by 操作时 gatherOrderExprs( bb, select, select.getOrderList(), orderExprList, collationList); final RelCollation collation = cluster.traitSet().canonize(RelCollations.of(collationList));
if (validator.isAggregate(select)) { //note: 当有聚合操作时,也就是含有 group by、having 或者 Select 和 order by 中含有聚合函数 convertAgg( bb, select, orderExprList); } else { //note: 对 select list 部分的处理 convertSelectList( bb, select, orderExprList); }
if (select.isDistinct()) { //note: select 后面含有 DISTINCT 关键字时(去重) distinctify(bb, true); } //note: Converts a query's ORDER BY clause, if any. convertOrder( select, bb, collation, orderExprList, select.getOffset(), select.getFetch()); bb.setRoot(bb.root, true); }
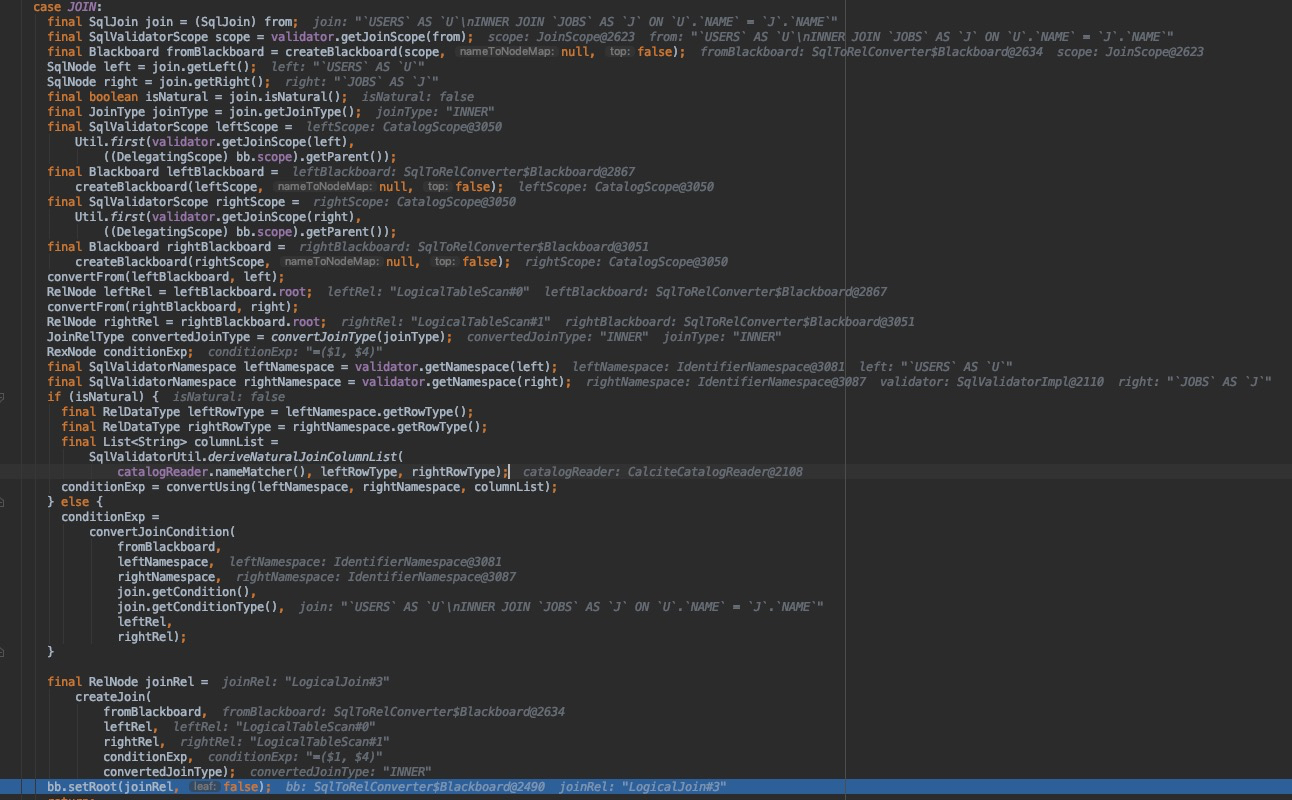
这里以示例中的 From 部分为例介绍 SqlNode 到 RelNode 的逻辑,按照示例 DEUBG 后的结果如下图所示,因为 form 部分是一个 join 操作,会进入 join 相关的处理中。