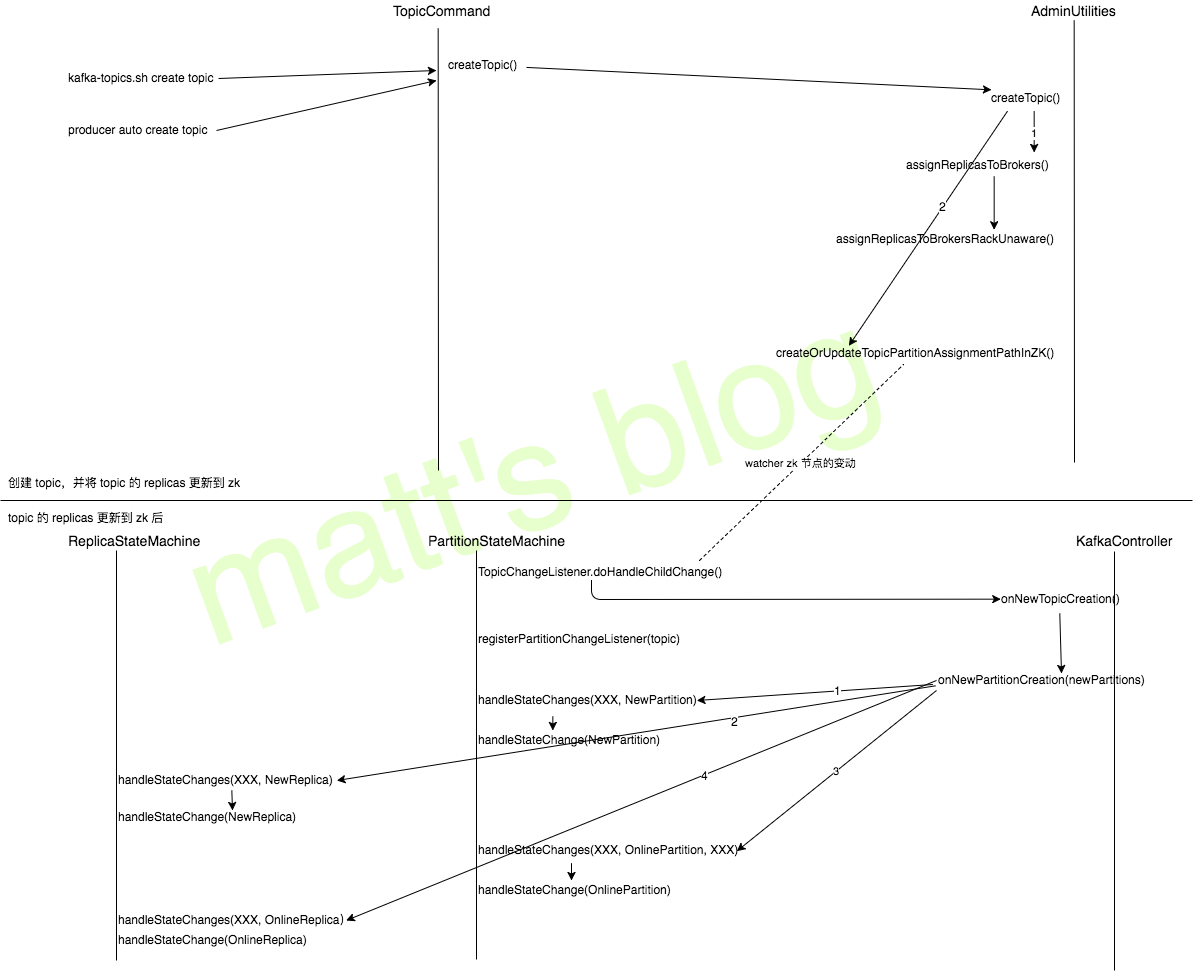
//note: 创建 topic defcreateTopic(zkUtils: ZkUtils, opts: TopicCommandOptions) { val topic = opts.options.valueOf(opts.topicOpt) val configs = parseTopicConfigsToBeAdded(opts) val ifNotExists = opts.options.has(opts.ifNotExistsOpt) if (Topic.hasCollisionChars(topic)) println("WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.") try { if (opts.options.has(opts.replicaAssignmentOpt)) {//note: 指定 replica 的分配,直接向 zk 更新即可 val assignment = parseReplicaAssignment(opts.options.valueOf(opts.replicaAssignmentOpt)) AdminUtils.createOrUpdateTopicPartitionAssignmentPathInZK(zkUtils, topic, assignment, configs, update = false) } else {//note: 未指定 replica 的分配,调用自动分配算法进行分配 CommandLineUtils.checkRequiredArgs(opts.parser, opts.options, opts.partitionsOpt, opts.replicationFactorOpt) val partitions = opts.options.valueOf(opts.partitionsOpt).intValue val replicas = opts.options.valueOf(opts.replicationFactorOpt).intValue val rackAwareMode = if (opts.options.has(opts.disableRackAware)) RackAwareMode.Disabled elseRackAwareMode.Enforced AdminUtils.createTopic(zkUtils, topic, partitions, replicas, configs, rackAwareMode) } println("Created topic \"%s\".".format(topic)) } catch { case e: TopicExistsException => if (!ifNotExists) throw e } }
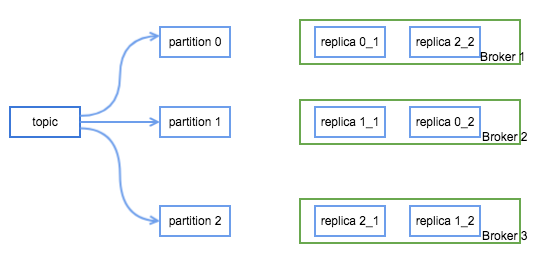
defparseReplicaAssignment(replicaAssignmentList: String): Map[Int, List[Int]] = { val partitionList = replicaAssignmentList.split(",") val ret = new mutable.HashMap[Int, List[Int]]() for (i <- 0 until partitionList.size) { val brokerList = partitionList(i).split(":").map(s => s.trim().toInt) val duplicateBrokers = CoreUtils.duplicates(brokerList) if (duplicateBrokers.nonEmpty)//note: 同一个 partition 对应的 replica 是不能相同的 thrownewAdminCommandFailedException("Partition replica lists may not contain duplicate entries: %s".format(duplicateBrokers.mkString(","))) ret.put(i, brokerList.toList) if (ret(i).size != ret(0).size)//note: 同一个 topic 的副本数必须相同 thrownewAdminOperationException("Partition " + i + " has different replication factor: " + brokerList) } ret.toMap }
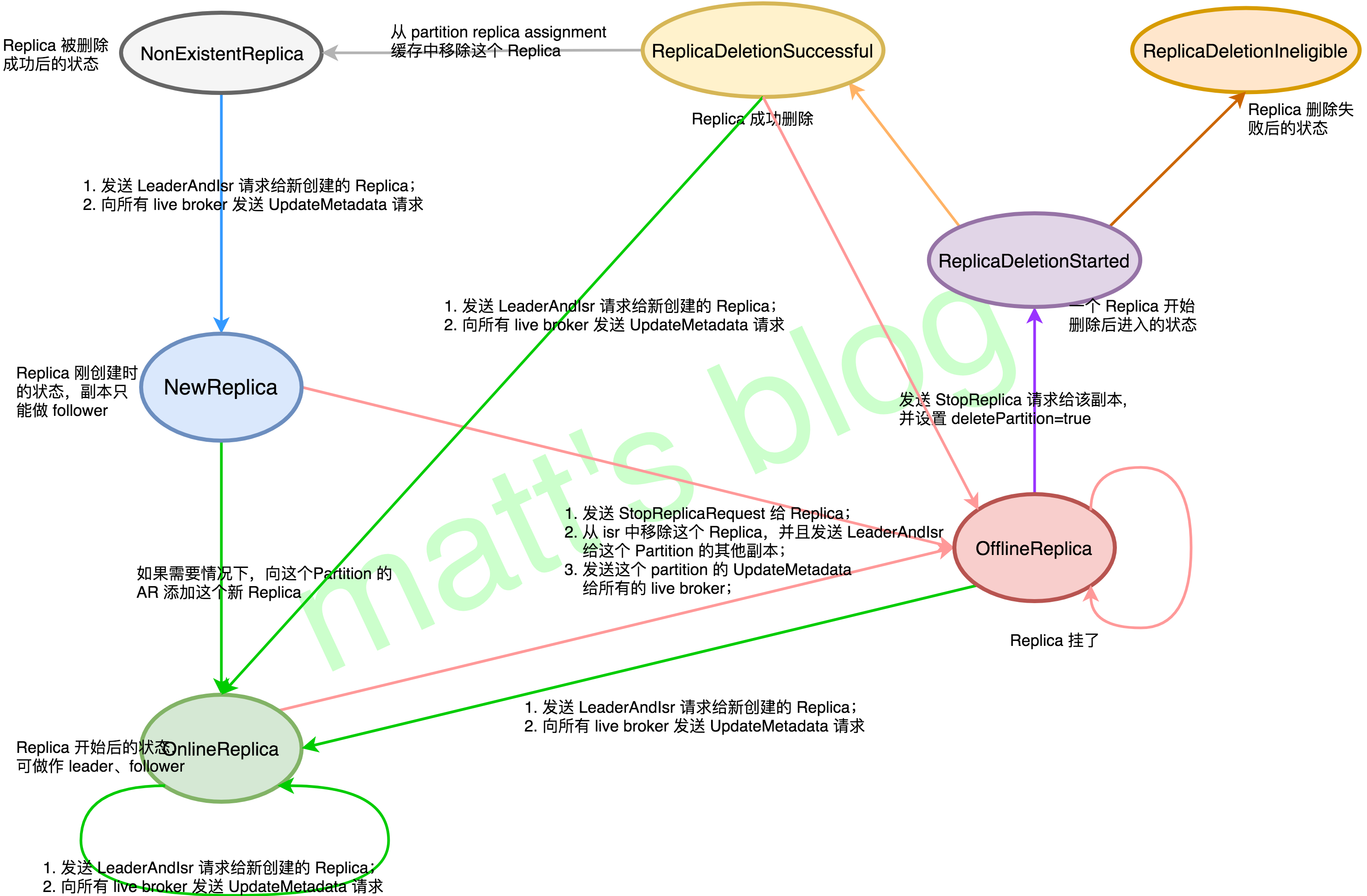
NewReplica:The controller can create new replicas during partition reassignment. In this state, a replica can only get become follower state change request.
OnlineReplica:Once a replica is started and part of the assigned replicas for its partition, it is in this state. In this state, it can get either become leader or become follower state change requests.
OfflineReplica:If a replica dies, it moves to this state. This happens when the broker hosting the replica is down.
ReplicaDeletionStarted:If replica deletion starts, it is moved to this state.
ReplicaDeletionSuccessful:If replica responds with no error code in response to a delete replica request, it is moved to this state.
ReplicaDeletionIneligible:If replica deletion fails, it is moved to this state.
NonExistentReplica:If a replica is deleted successfully, it is moved to this state.
caseNewReplica => assertValidPreviousStates(partitionAndReplica, List(NonExistentReplica), targetState) //note: 验证 // start replica as a follower to the current leader for its partition val leaderIsrAndControllerEpochOpt = ReplicationUtils.getLeaderIsrAndEpochForPartition(zkUtils, topic, partition) leaderIsrAndControllerEpochOpt match { caseSome(leaderIsrAndControllerEpoch) => if(leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId)//note: 这个状态的 Replica 不能作为 leader thrownewStateChangeFailedException("Replica %d for partition %s cannot be moved to NewReplica" .format(replicaId, topicAndPartition) + "state as it is being requested to become leader") //note: 向所有 replicaId 发送 LeaderAndIsr 请求,这个方法同时也会向所有的 broker 发送 updateMeta 请求 brokerRequestBatch.addLeaderAndIsrRequestForBrokers(List(replicaId), topic, partition, leaderIsrAndControllerEpoch, replicaAssignment) caseNone => // new leader request will be sent to this replica when one gets elected
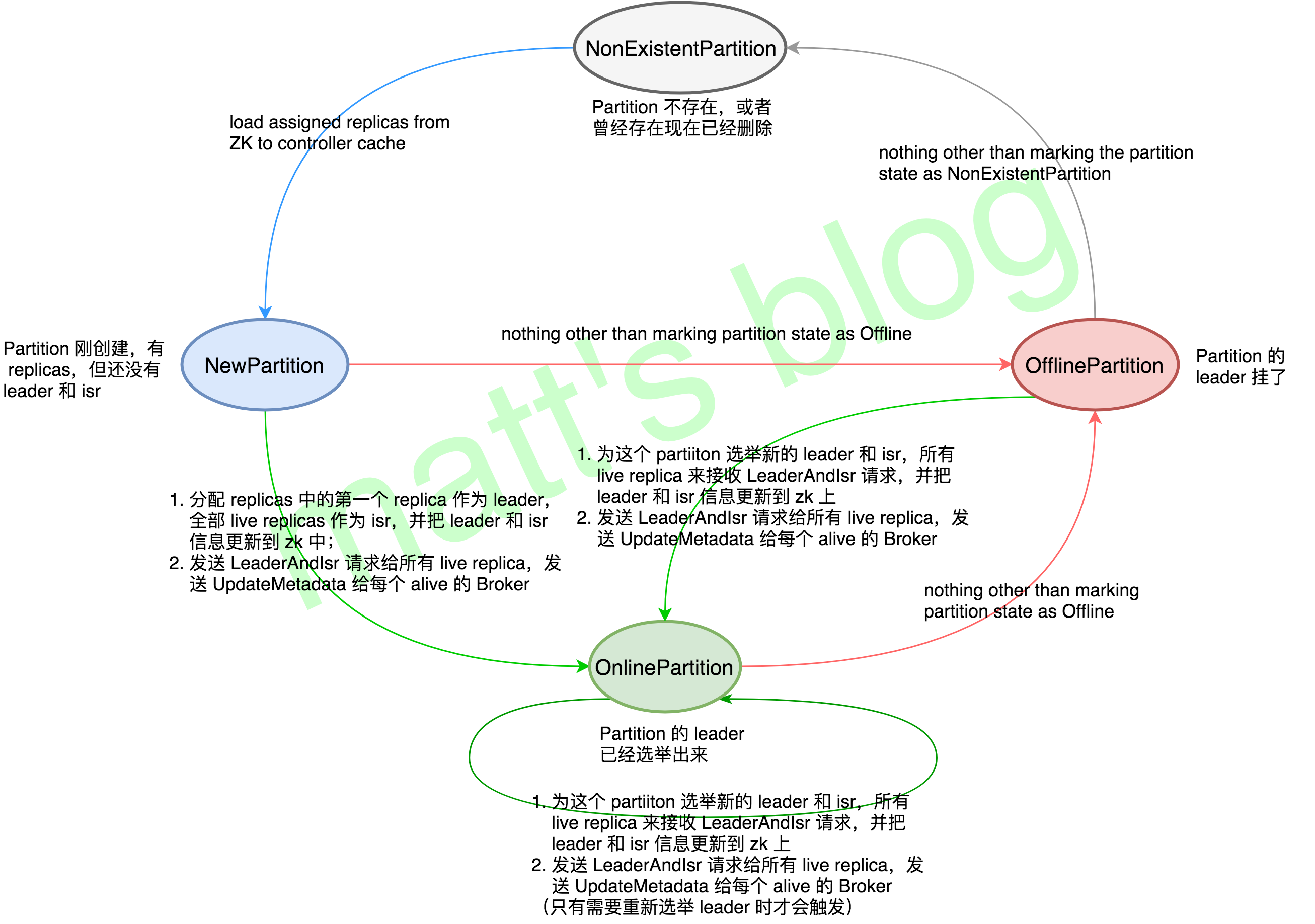
// post: partition has been assigned replicas caseOnlinePartition => assertValidPreviousStates(topicAndPartition, List(NewPartition, OnlinePartition, OfflinePartition), OnlinePartition) partitionState(topicAndPartition) match { caseNewPartition => // initialize leader and isr path for new partition initializeLeaderAndIsrForPartition(topicAndPartition) //note: 为新建的 partition 初始化 leader 和 isr caseOfflinePartition => electLeaderForPartition(topic, partition, leaderSelector) caseOnlinePartition => // invoked when the leader needs to be re-elected electLeaderForPartition(topic, partition, leaderSelector) case _ => // should never come here since illegal previous states are checked above }
//note: 当 partition 状态由 NewPartition 变为 OnlinePartition 时,将触发这一方法,用来初始化 partition 的 leader 和 isr privatedefinitializeLeaderAndIsrForPartition(topicAndPartition: TopicAndPartition) { val replicaAssignment = controllerContext.partitionReplicaAssignment(topicAndPartition) val liveAssignedReplicas = replicaAssignment.filter(r => controllerContext.liveBrokerIds.contains(r)) liveAssignedReplicas.size match { case0 => val failMsg = ("encountered error during state change of partition %s from New to Online, assigned replicas are [%s], " + "live brokers are [%s]. No assigned replica is alive.") .format(topicAndPartition, replicaAssignment.mkString(","), controllerContext.liveBrokerIds) stateChangeLogger.error("Controller %d epoch %d ".format(controllerId, controller.epoch) + failMsg) thrownewStateChangeFailedException(failMsg) case _ => debug("Live assigned replicas for partition %s are: [%s]".format(topicAndPartition, liveAssignedReplicas)) // make the first replica in the list of assigned replicas, the leader val leader = liveAssignedReplicas.head //note: replicas 中的第一个 replica 选做 leader val leaderIsrAndControllerEpoch = newLeaderIsrAndControllerEpoch(newLeaderAndIsr(leader, liveAssignedReplicas.toList), controller.epoch) debug("Initializing leader and isr for partition %s to %s".format(topicAndPartition, leaderIsrAndControllerEpoch)) try { zkUtils.createPersistentPath( getTopicPartitionLeaderAndIsrPath(topicAndPartition.topic, topicAndPartition.partition), zkUtils.leaderAndIsrZkData(leaderIsrAndControllerEpoch.leaderAndIsr, controller.epoch))//note: zk 上初始化节点信息 // NOTE: the above write can fail only if the current controller lost its zk session and the new controller // took over and initialized this partition. This can happen if the current controller went into a long // GC pause controllerContext.partitionLeadershipInfo.put(topicAndPartition, leaderIsrAndControllerEpoch) brokerRequestBatch.addLeaderAndIsrRequestForBrokers(liveAssignedReplicas, topicAndPartition.topic, topicAndPartition.partition, leaderIsrAndControllerEpoch, replicaAssignment)//note: 向 live 的 Replica 发送 LeaderAndIsr 请求 } catch { case _: ZkNodeExistsException => // read the controller epoch val leaderIsrAndEpoch = ReplicationUtils.getLeaderIsrAndEpochForPartition(zkUtils, topicAndPartition.topic, topicAndPartition.partition).get val failMsg = ("encountered error while changing partition %s's state from New to Online since LeaderAndIsr path already " + "exists with value %s and controller epoch %d") .format(topicAndPartition, leaderIsrAndEpoch.leaderAndIsr.toString(), leaderIsrAndEpoch.controllerEpoch) stateChangeLogger.error("Controller %d epoch %d ".format(controllerId, controller.epoch) + failMsg) thrownewStateChangeFailedException(failMsg) } }
caseOnlineReplica => assertValidPreviousStates(partitionAndReplica, List(NewReplica, OnlineReplica, OfflineReplica, ReplicaDeletionIneligible), targetState) replicaState(partitionAndReplica) match { caseNewReplica => // add this replica to the assigned replicas list for its partition //note: 向 the assigned replicas list 添加这个 replica(正常情况下这些 replicas 已经更新到 list 中了) val currentAssignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition) if(!currentAssignedReplicas.contains(replicaId)) controllerContext.partitionReplicaAssignment.put(topicAndPartition, currentAssignedReplicas :+ replicaId) stateChangeLogger.trace("Controller %d epoch %d changed state of replica %d for partition %s from %s to %s" .format(controllerId, controller.epoch, replicaId, topicAndPartition, currState, targetState))