LLM 系列 (八):分布式训练:千卡集群如何训大模型
如果说预训练回答的是“大模型的能力如何形成”,后训练回答的是“这些能力如何被塑造成可用行为”,那么分布式训练回答的就是一个更底层的工程问题:如此庞大的模型,如何真的在成百上千张 GPU 上稳定训练完成?
大模型训练从来不是把一个 PyTorch 脚本复制到很多张卡上那么简单。真正的挑战在于:模型参数放不下,激活值放不下,优化器状态放不下;单卡算力不够,跨卡通信会拖慢训练;训练中还可能遇到 loss spike、节点故障、checkpoint 写入过慢、MoE 负载不均和长上下文显存爆炸。规模越大,问题越不再是单点优化,而是计算、显存、通信、存储、调度和容错的系统协同。
所以,分布式训练的本质不是“多用几张卡”,而是把一个单卡无法承载、单机无法高效完成的大模型,拆解成可以在大规模 GPU 集群上协同优化的计算图、参数状态和数据流。它解决的不是某一个算子怎么更快,而是如何让数百上千张 GPU 在数周甚至数月训练中,持续、稳定、有效地朝同一个目标更新参数。
为什么分布式训练
在小模型时代,训练慢一点通常还能接受:模型可以放进单卡显存,数据规模也不至于让训练周期失控。但到了百亿、千亿参数模型,问题会发生质变。模型参数本身放不下,训练过程中的梯度、优化器状态和激活值更放不下;即使勉强放下,单卡算力也无法在可接受时间内处理数万亿 token;而一旦扩展到多卡,又会引入通信、同步、故障恢复和系统稳定性问题。
所以,分布式训练不是“为了更快”,而是因为大模型训练在单卡上已经不可行。
以一个 70B 参数模型为例,BF16 权重本身就需要:70B × 2 bytes ≈ 140GB。
但训练时不只有权重,还包括梯度、优化器状态、master weights、激活值等。使用 Adam 类优化器时,常见训练状态可能达到:
1 | 每个参数约 12-16 bytes,不含激活 |
这还没有计算 batch size、sequence length 和 activation 带来的额外开销。也就是说,显存问题不是“省一点就够”,而是必须通过参数切分、优化器状态切分、激活重计算和多维并行才能解决。
除了显存,训练算力也会迅速失控。对 dense decoder-only Transformer,语言模型训练 FLOPs(FLOPs 是 Floating Point Operations 的缩写,中文一般叫 浮点运算次数)可以粗略估算为(这个公式主要用于量级判断,不包含长上下文 attention、MoE 路由、激活重算等额外开销):
1 | 训练 FLOPs ≈ 6 × 参数量 N × 训练 token 数 D |
如果模型参数量和训练 token 数同时扩大,计算量会以极高速度增长。单卡不仅慢,而且会让训练周期长到没有工程意义。
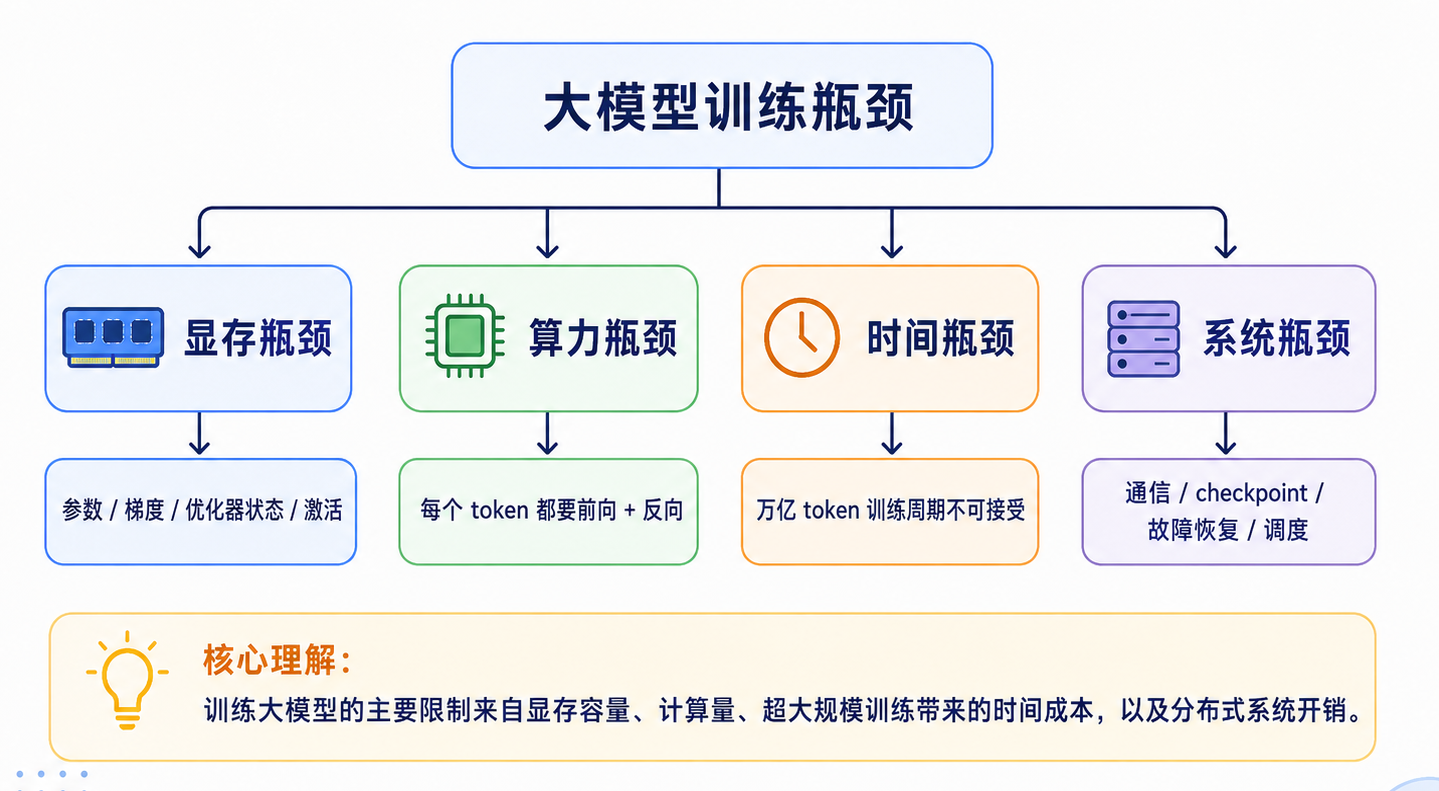
因此,大模型训练至少面临五类问题:
| 资源 | 大模型训练面临的瓶颈 |
|---|---|
| 显存 | 参数、梯度、Adam 状态、激活远超单卡容量 |
| 算力 | 训练 FLOPs 近似随 参数量 × token 数 增长 |
| 时间 | 单卡训练可能需要数年甚至更久 |
| 通信 | 多卡扩展后,梯度、参数、激活和 MoE token 需要跨设备同步,通信会成为新的系统瓶颈。 |
| 稳定性 | 千卡训练中任何一张卡、一个节点、一个 batch 异常都可能影响全局 |
所以,分布式训练要解决的不是一个简单问题,而是一组耦合问题:
- 如何放得下模型?
- 如何喂得满 GPU?
- 如何同步得足够快?
- 如何在故障后恢复?
- 如何让训练长期稳定下降?
这也是为什么大模型训练不是“写一个 PyTorch 脚本”的问题,而是计算图切分、显存管理、通信调度、容错恢复和训练稳定性共同组成的大规模系统工程
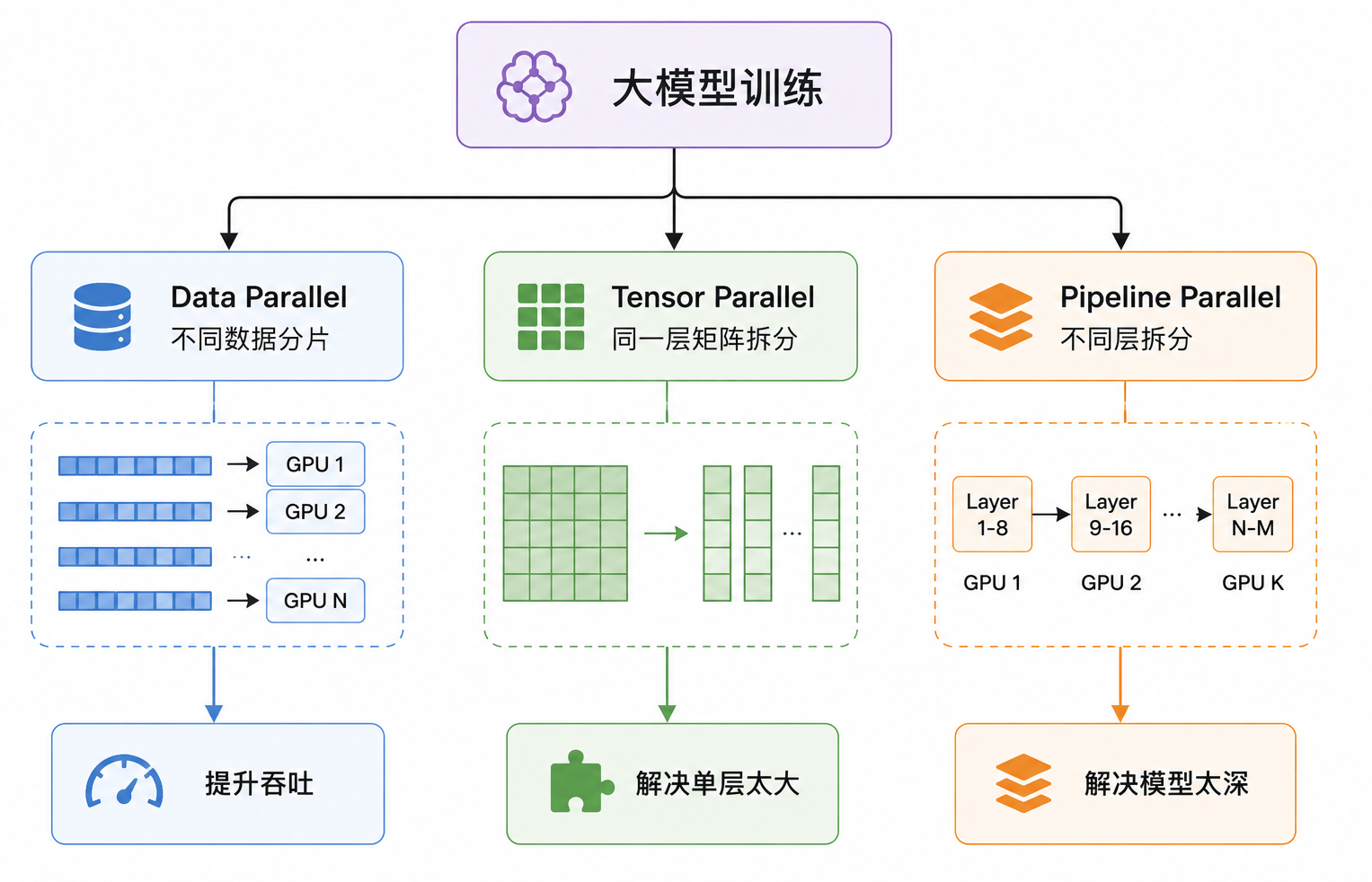
核心并行策略:大模型训练如何拆分
分布式训练的核心不是简单把同一份代码跑到多张卡上,而是把训练过程中的不同对象拆开:数据可以拆,模型参数可以拆,模型层可以拆,优化器状态可以拆,长序列可以拆,MoE 专家也可以拆。不同并行策略,本质上是在回答不同问题:
- 数据太多,如何让多张卡同时处理不同样本?
- 单层矩阵太大,如何拆到多张卡共同计算?
- 模型层数太深,如何把不同层放到不同设备?
- 参数、梯度、优化器状态太大,如何减少每张卡的冗余存储?
- 上下文太长,如何拆分序列维度?
- MoE 专家太多,如何把不同专家分布到不同 GPU?
所以,理解分布式训练,最重要的不是先记住一堆术语,而是看清楚:每一种并行策略到底在拆什么,又用什么通信代价换来了什么资源收益。
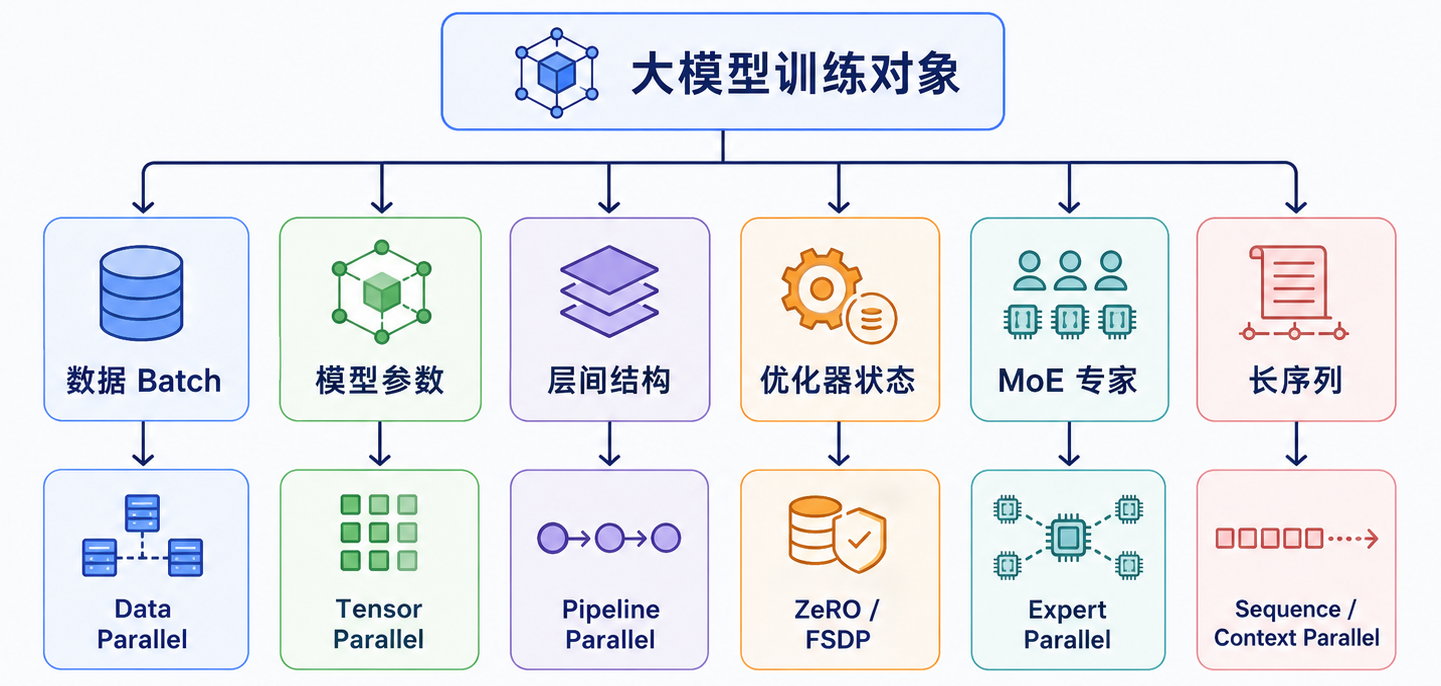
| 并行方式 | 拆什么 | 解决什么问题 | 主要代价 |
|---|---|---|---|
| 数据并行 DP | batch | 提升吞吐 | 梯度同步通信 |
| 张量并行 TP | 单层矩阵计算 | 单层太大、计算太重 | 层内通信频繁 |
| 流水线并行 PP | 模型层 | 模型太深、整模放不下 | pipeline bubble |
| ZeRO / FSDP | 参数、梯度、优化器状态 | 训练状态太占显存 | all-gather / reduce-scatter |
| 专家并行 EP | MoE experts | MoE 专家参数巨大 | all-to-all 路由通信 |
| 序列 / 上下文并行 SP/CP | sequence length | 长上下文激活和 attention 太大 | 序列维通信 |
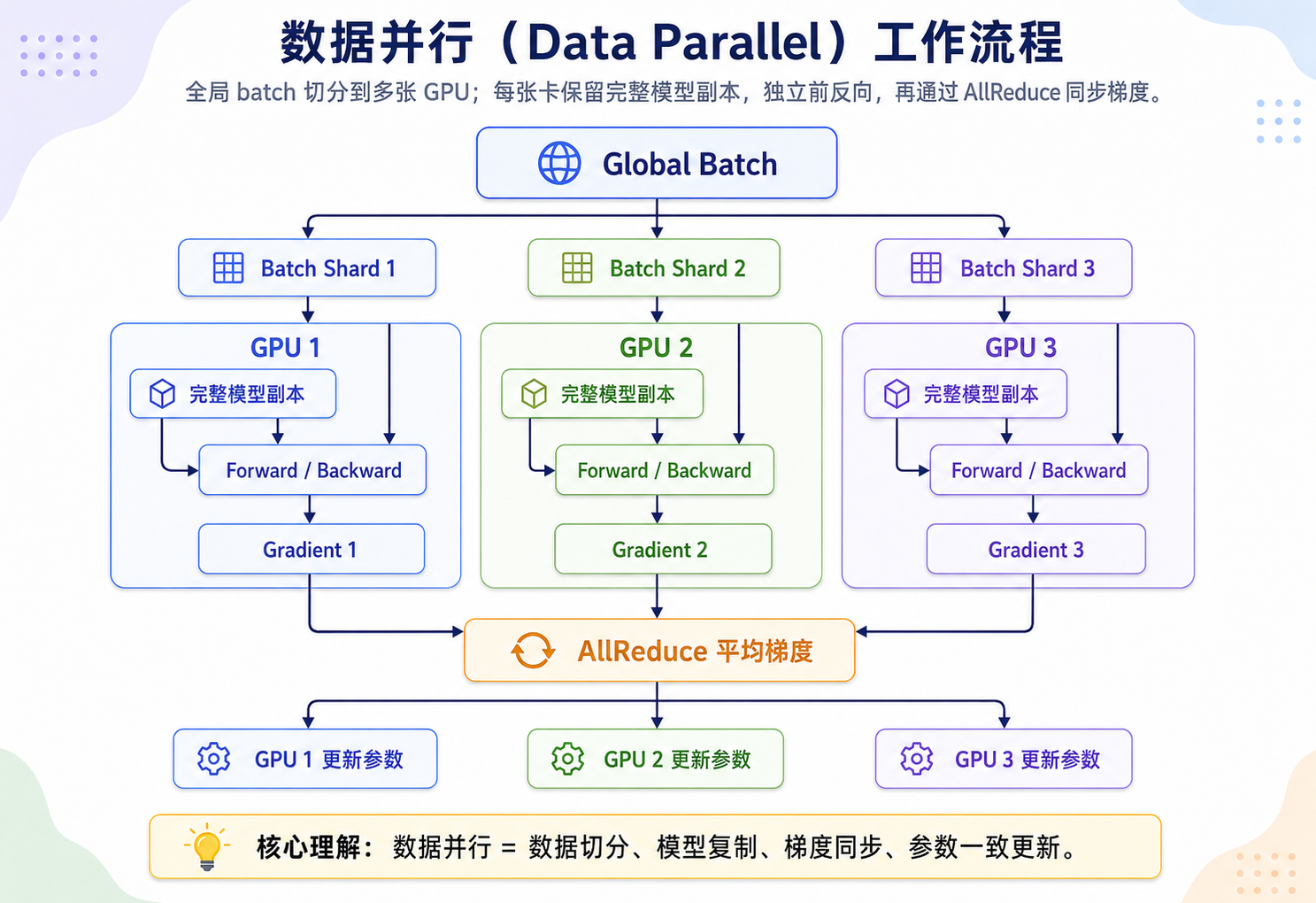
数据并行(Data Parallel)
数据并行最容易理解:模型不拆,数据拆。每张 GPU 拿到同一模型的完整副本,处理不同的数据分片;反向传播后,各卡通过 AllReduce 同步梯度,再执行相同的参数更新。这样可以提升吞吐,但不能解决“模型本身放不下”的问题。
张量并行(Tensor Parallel)
张量并行的核心是:模型层不再完整放在一张 GPU 上,而是把同一层里的大矩阵拆开。以线性层 Y = XW 为例,可以把权重矩阵 W 按列或按行切成多块,不同 GPU 分别计算部分输出,再通过 Concat / AllGather 或 AllReduce 得到完整结果。
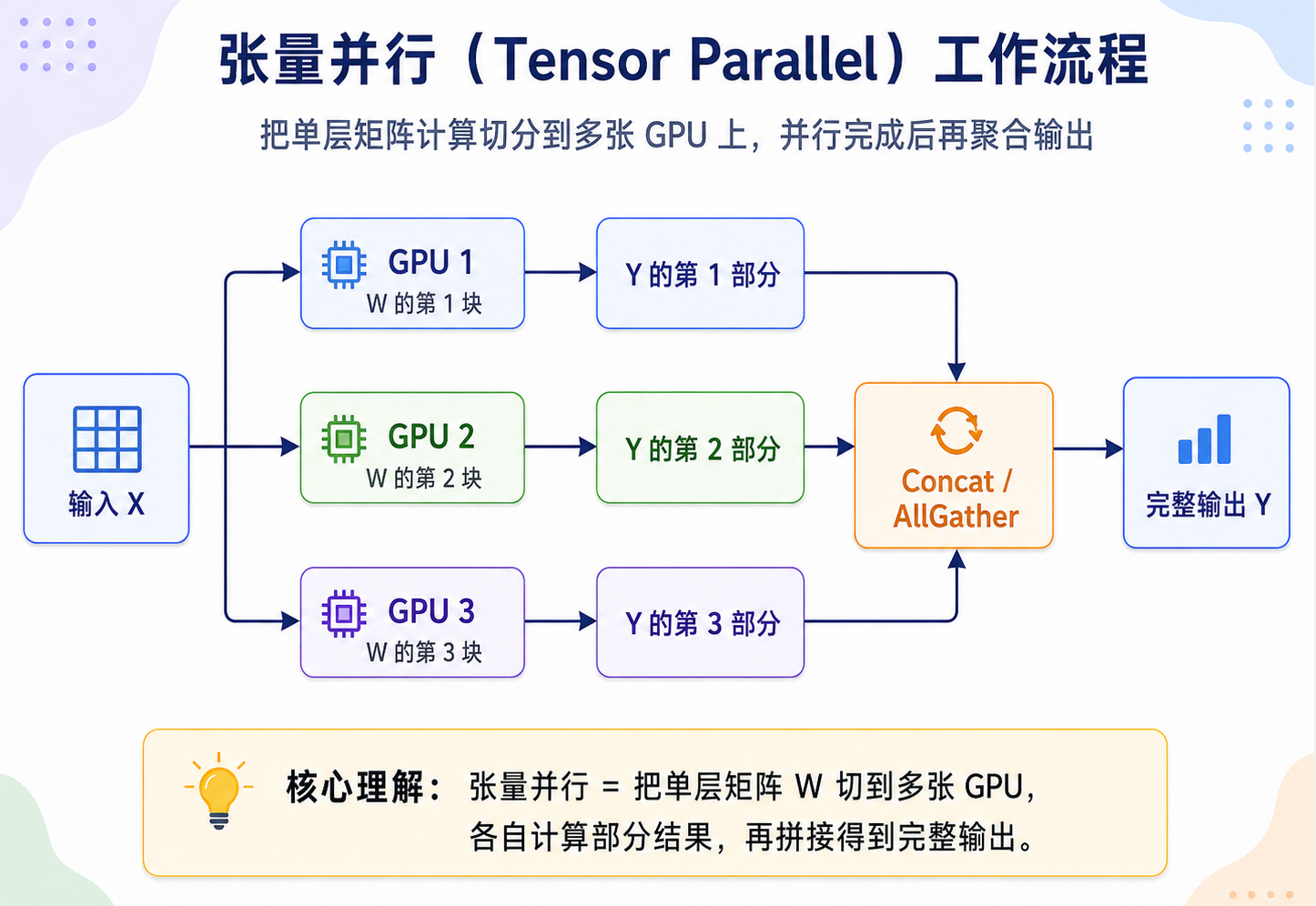
它解决的是“单层矩阵太大、单卡算不动”的问题,但代价是层内通信非常频繁,所以通常更适合放在 NVLink / NVSwitch 这种高速互联的节点内部。
流水线并行(Pipeline Parallel)
流水线并行拆的是“模型层”。它把不同 Transformer layers 放到不同 GPU 上,例如 GPU0 放 Layer 1-8,GPU1 放 Layer 9-16,依次组成一条计算流水线。
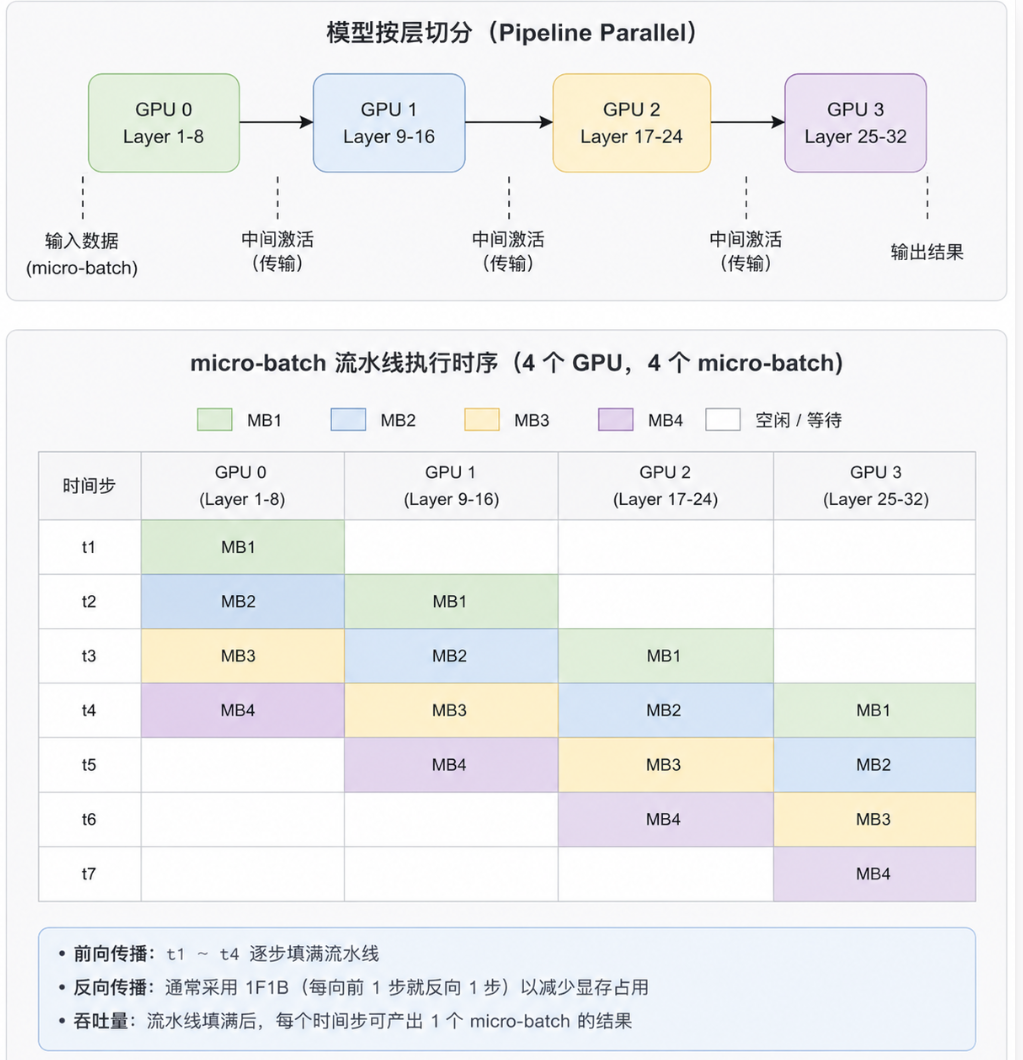
但如果一次只喂一个 batch,GPU 会大量空等:前面的 GPU 算完后面的 GPU 才开始,反向传播时又要反过来等待。为提高利用率,训练系统会把 batch 切成多个 micro-batch,让不同 GPU 在同一时刻处理不同 micro-batch 的不同层。
它解决的是“模型太深、整模放不下”的问题,代价是 pipeline bubble:流水线启动和收尾阶段总会有设备空闲,流水线越深,调度越复杂。
ZeRO / FSDP
ZeRO(Zero Redundancy Optimizer,零冗余优化器)和 FSDP(Fully Sharded Data Parallel,完全分片数据并行)拆的不是 batch,也不是某一层的矩阵,而是训练状态。
ZeRO 和 FSDP 的核心思路是:不要让每张卡都保存完整参数、梯度和优化器状态。
普通数据并行中,每张 GPU 都保存完整参数、完整梯度和完整优化器状态。这样实现简单,但显存冗余巨大。ZeRO / FSDP 的核心思想是:这些状态没有必要在每张卡上完整复制,可以按 shard 分摊到多张 GPU 上。
| 阶段 | 拆分对象 | 节省什么 |
|---|---|---|
| ZeRO-1 | optimizer states | 减少 Adam 状态冗余 |
| ZeRO-2 | optimizer states + gradients | 再减少梯度冗余 |
| ZeRO-3 | optimizer states + gradients + parameters | 参数也分片,显存节省最大 |

FSDP 和 ZeRO-3 思路接近:平时每张卡只保存参数 shard;计算某一层时,通过 AllGather 临时拿到当前层完整参数;反向传播后,通过 ReduceScatter 把梯度重新切分回各卡。
它解决的是“训练状态太占显存”的问题,代价是通信更复杂,尤其是频繁的参数聚合和梯度切分。
专家并行(Expert Parallel)
专家并行(Expert Parallel,EP)主要用于 MoE(Mixture of Experts,混合专家)模型。
MoE 的特点是:模型总参数很大,但每个 token 只激活其中少数几个专家。例如一个模型可能有几十个或上百个 expert,但每个 token 只路由到 Top-1 或 Top-2 expert。这样可以用较低的每 token 计算量,换取更大的总模型容量。
专家并行拆的就是这些 expert:不同 GPU 负责不同专家,token 经过 router 后,被发送到对应专家所在的 GPU 上计算,再把结果聚合回来。
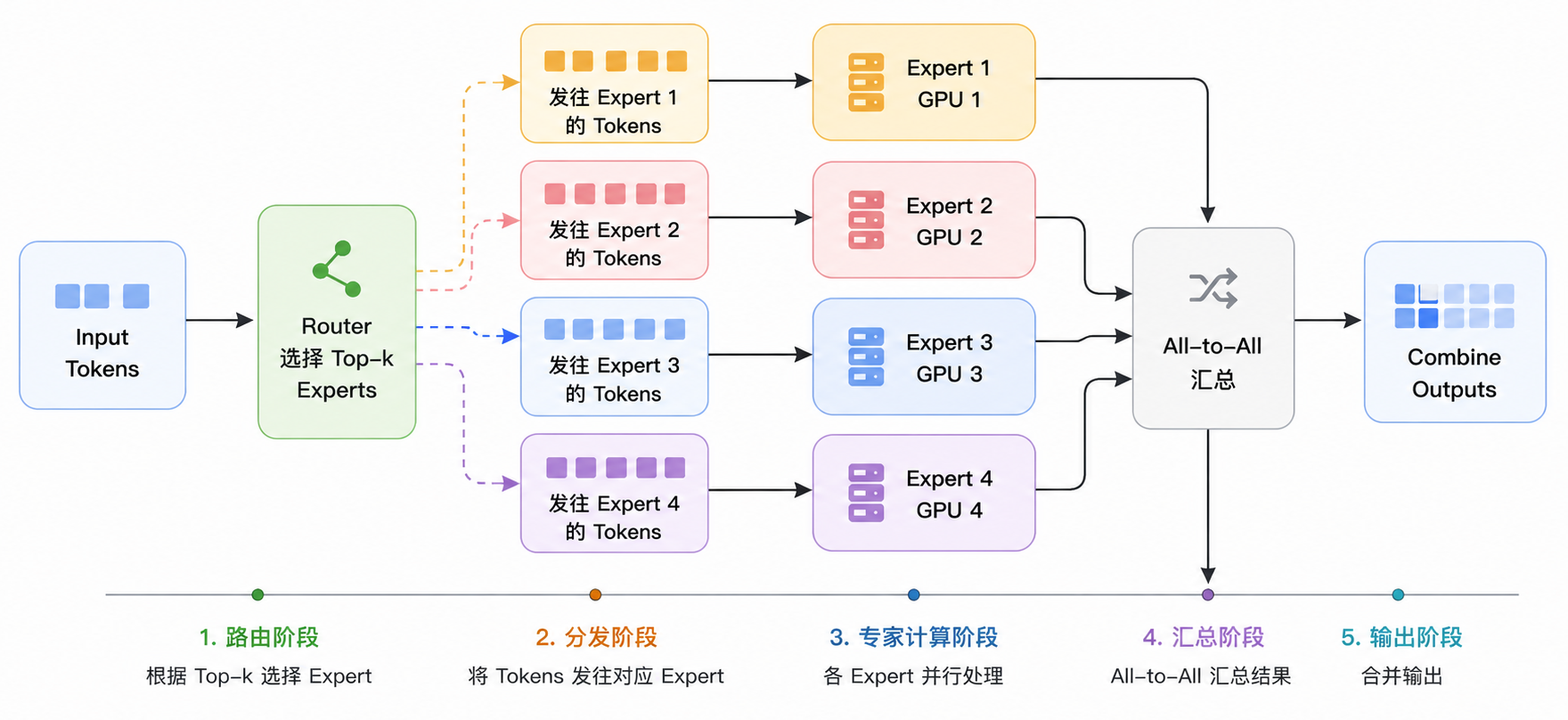
MoE 的难点不只是“专家很多”,而是 token 会在设备之间大规模移动。一个 batch 里的 token 可能被路由到不同专家,而这些专家分布在不同 GPU 或不同节点上,因此训练时会产生大量 all-to-all 通信。专家并行主要解决的是:
- 总参数太大: expert 参数分布在不同 GPU 上,不必每张卡保存所有专家;
- 每 token 计算可控:每个 token 只激活少数专家;
- 专家 specialization: 不同专家可以学习不同数据模式或能力方向。
但它也带来新的工程难点:
- all-to-all 通信: token 需要跨 GPU / 跨节点发送到目标专家;
- 负载不均: router 可能把大量 token 分到少数热门专家;
- expert capacity: 每个专家能处理的 token 数有限,溢出会影响训练;
- 路由稳定性:router 训练不稳定会导致专家退化或利用率低;
- 推理部署复杂:总参数大,专家调度和显存放置更难。
所以,MoE 的训练效率不只取决于模型结构,也取决于 router、负载均衡、专家放置、all-to-all 通信和集群拓扑。
序列 / 上下文并行(Sequence / Context Parallel)
序列并行和上下文并行拆的是 sequence length,主要用于长上下文训练。
普通训练中,一个样本的整段上下文通常会放在同一组 GPU 上完成 attention 计算。但当上下文长度从 4K、32K 扩展到 128K 甚至更长时,attention 和 activation 的显存压力会快速上升。尤其是长序列训练中,单卡不仅要保存更多 token 的 hidden states,还要处理更大的 attention 计算和中间激活。
序列 / 上下文并行的核心思想是:不只拆 batch 或模型参数,也把同一个长序列沿 sequence 维度切开,让多张 GPU 共同处理一段上下文。
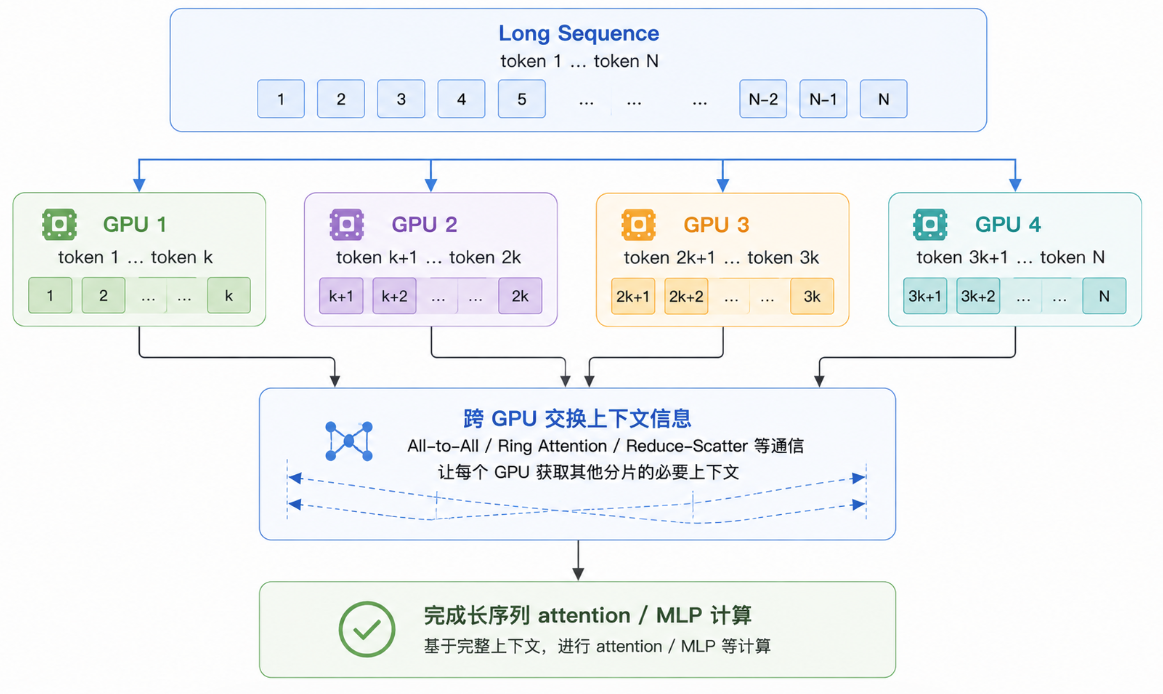
它的代价也很明显:attention 本来就依赖 token 之间的关系,把序列切开后,不同 GPU 之间必须交换上下文信息,否则模型只能看到局部片段。上下文越长,通信和调度越复杂。
训练系统如何协同工作?
前面讲的是“训练任务怎么拆”:数据并行拆 batch,张量并行拆矩阵,流水线并行拆层,ZeRO/FSDP 拆训练状态,专家并行拆 MoE expert。
但真实训练时,这些并行策略不是孤立运行的。一次训练 step 里,数据加载、前向计算、反向传播、梯度同步、参数更新、checkpoint 和故障监控会同时发生。分布式训练系统的任务,就是把这些环节组织成一条尽可能高效、稳定、可恢复的流水线。
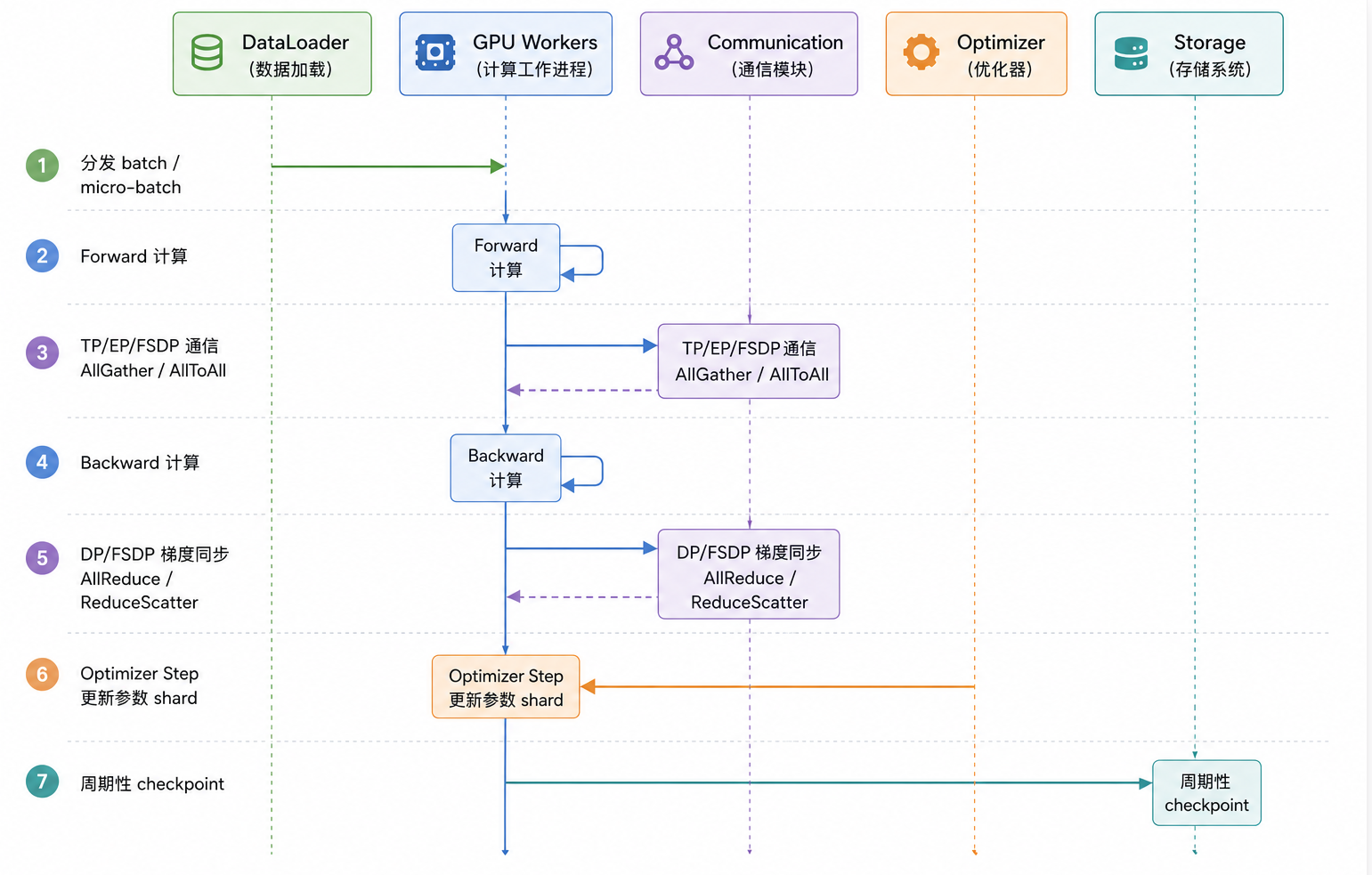
一次训练 step 里发生了什么?
一次大模型训练 step,表面上是一次 forward + backward,实际上包含数据、计算、通信、优化器、存储和调度多个环节的协同。核心流程如下:
- DataLoader:读取、清洗、打包并分发训练样本。关键是数据吞吐必须跟上 GPU,否则 GPU 会空等;
- Forward:执行前向计算,得到模型输出和 loss。这个阶段会产生大量激活值,是训练显存的重要来源;
- Backward:执行反向传播,计算各层梯度。为了节省显存,很多系统会结合 activation checkpointing,在反向时重算部分激活;
- Communication:在不同 GPU 之间同步梯度、参数、激活或 MoE token。常见通信包括
AllReduce、AllGather、ReduceScatter和AllToAll; - Optimizer Step:根据梯度更新参数。Adam 类优化器会维护额外状态,ZeRO / FSDP 则需要对参数、梯度和 optimizer state 做分片更新;
- Checkpoint:周期性保存模型参数、优化器状态、数据进度和随机数状态。模型越大,checkpoint 越大,写入和恢复都更复杂;
- Scheduler / Monitor:负责资源调度、健康检查、异常检测和任务重启。在千卡训练中,硬件故障、慢节点和网络异常都不是小概率事件。
可以把它理解成一句话:训练 step 不是单个算子,而是一条由数据流、计算流、通信流和状态流共同组成的分布式流水线。
为什么需要 3D Parallel / Hybrid Parallel?
单一并行策略通常只能解决一类问题:
| 单一策略 | 能解决 | 解决不了 |
|---|---|---|
| 数据并行 | 提升吞吐 | 模型和 optimizer state 放不下 |
| 张量并行 | 单层矩阵太大 | 层数太深、pipeline 调度 |
| 流水线并行 | 模型层太多 | 层内矩阵和训练状态仍可能太大 |
| ZeRO/FSDP | 训练状态太大 | 计算本身和 MoE 路由问题 |
| 专家并行 | MoE expert 太多 | dense 层、梯度同步、长上下文问题 |
所以工业训练通常不会只用一种并行方式,而是组合使用。这就是 Hybrid Parallel(混合并行)。其中最经典的组合是 3D Parallel(三维并行):Data Parallel × Tensor Parallel × Pipeline Parallel。
它之所以叫 3D,是因为它同时从三个维度拆训练:
- Data Parallel,拆 batch;
- Tensor Parallel,拆单层矩阵;
- Pipeline Parallel,拆模型层。
可以这样理解:
如果再加上 ZeRO/FSDP、Expert Parallel、Sequence Parallel,就变成更广义的 Hybrid Parallel:
1 | DP × TP × PP × ZeRO/FSDP × EP × SP/CP |
一个例子:
1 | Tensor Parallel = 8 |
这表示:
- 每个 pipeline stage 内,用 8 张 GPU 做 tensor parallel;
- 整个模型被切成 8 个 pipeline stage;
- 这样的模型副本有 32 组,用 data parallel 处理不同 batch shard;
- 如果再配 ZeRO/FSDP,可以继续切分 optimizer state;
- 如果是 MoE 模型,还可能叠加 expert parallel。
所以,3D parallel / hybrid parallel 不是新算法,而是一种系统组织方式:当模型、数据、训练状态和通信压力都太大时,用多种并行策略在不同维度上同时拆分训练任务。
工程难点与解决方案
分布式训练最难的地方,不是“能不能把模型拆开”,而是“拆开之后能不能稳定、高效地长期跑下去”。在千卡规模下,很多小问题都会被放大:一次跨节点通信变慢,会拖住整个 step;一个异常 batch 可能触发 loss spike;一张 GPU 或一块网卡故障,可能导致整组训练任务重启;一次 checkpoint 写入过慢,可能让大量 GPU 空等。规模越大,系统越接近“木桶效应”:最慢、最不稳定的环节决定整体训练效率。
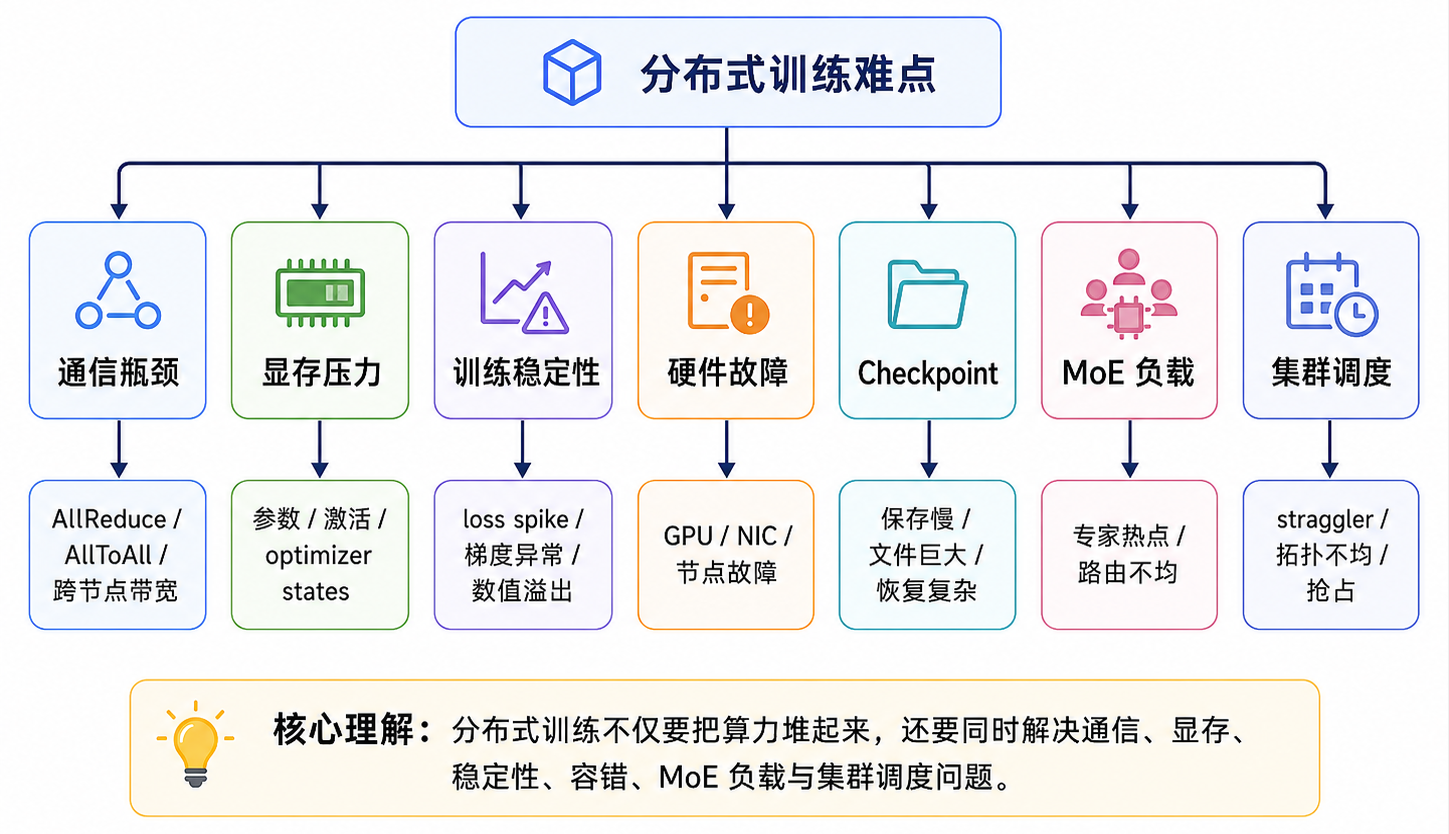
| 难点 | 本质问题 | 主流解决方案 |
|---|---|---|
| 通信瓶颈 | GPU 等通信,算力利用率下降 | 拓扑感知并行组、通信计算重叠、NCCL 调优 |
| 显存不足 | 参数、激活、optimizer states 占用巨大 | ZeRO/FSDP、activation checkpointing、混合精度 |
| Pipeline bubble | 流水线阶段空等 | micro-batch、1F1B、interleaved pipeline |
| Loss spike | 数值不稳或异常 batch 破坏训练 | warmup、gradient clipping、BF16/FP8 策略、异常 batch 检测 |
| Straggler | 慢节点拖慢全局 step | 健康检查、节点隔离、负载均衡、弹性训练 |
| Checkpoint 慢 | 模型和 optimizer state 文件巨大 | 分片 checkpoint、异步写入、增量保存 |
| MoE 负载不均 | token 路由集中到少数专家 | load balancing、capacity factor、aux-loss-free balancing |
| 长上下文训练 | attention 和 activation 随长度暴涨 | sequence parallel、context parallel、FlashAttention |
| 故障恢复 | 千卡训练中故障是常态 | 高频 checkpoint、自动重启、数据进度恢复 |
这里有一个重要判断:分布式训练不是追求单个 step 最快,而是追求长期稳定的有效吞吐。有效吞吐可以理解为:
1 | 有效吞吐 = 有效训练 token 数 / 总墙钟时间 |
所以,一个训练系统真正关心的不是“理论 peak FLOPs 有多高”,而是:
- GPU 有多少时间真的在算;
- 通信有没有被计算隐藏;
- checkpoint 会不会频繁阻塞;
- loss spike 后是否需要回滚;
- 节点故障后能不能快速恢复;
- MoE 负载是否均衡;
- 长时间训练中吞吐是否稳定。
如果一个系统单步很快,但频繁中断、回滚、空等、OOM 或 checkpoint 卡住,那么真实训练效率并不高。工业级分布式训练追求的是:在可接受成本下,持续、稳定地把最多有效 token 送进模型完成优化。
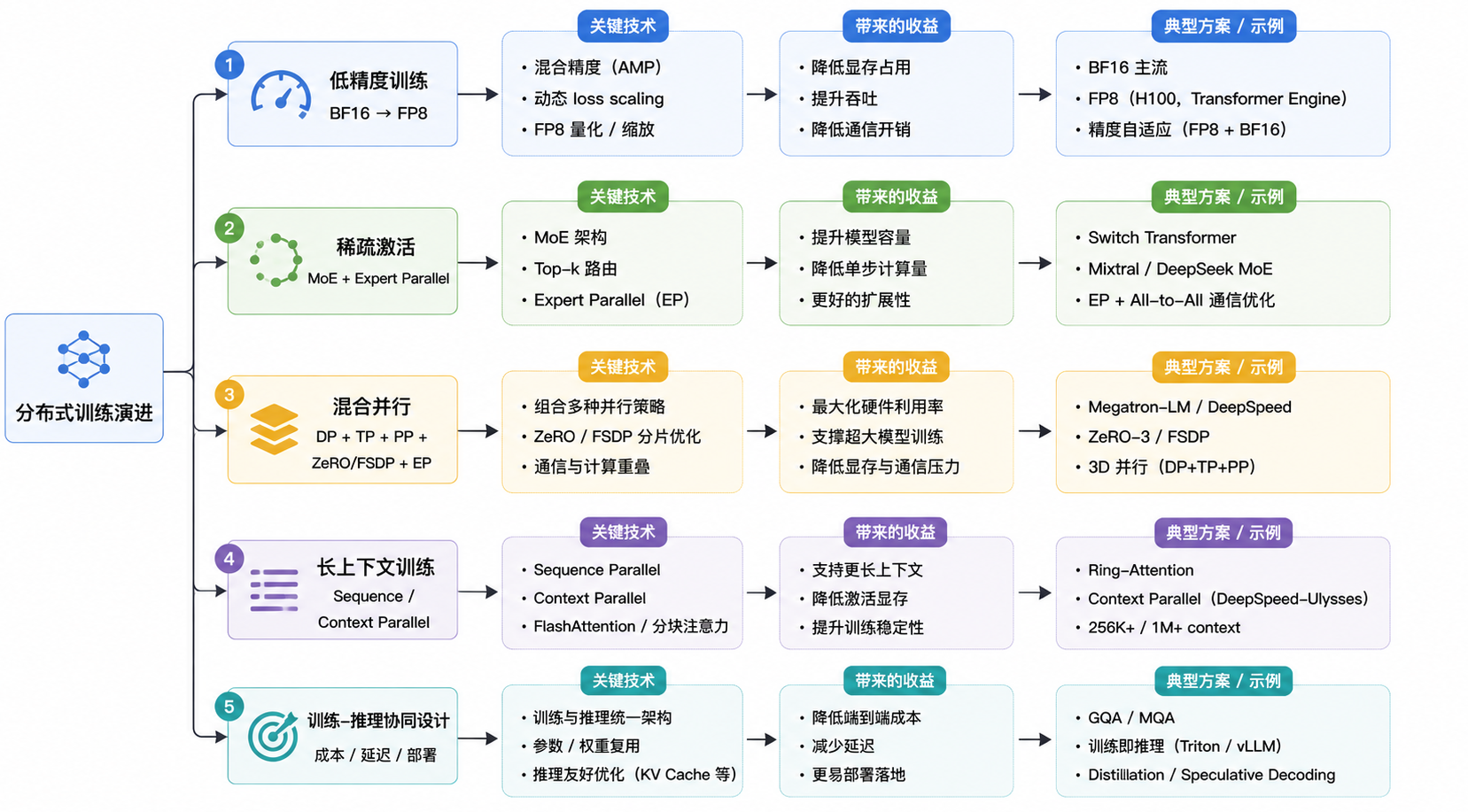
行业实践与未来趋势
分布式训练的发展,本质上是一条不断降低“大模型训练不可行性”的工程演进路线:先解决模型放不下,再解决训练太慢,再解决通信太重,最后走向低精度、MoE、长上下文和训练-推理协同优化。
| 系统 / 实践 | 核心贡献 | 解决的问题 |
|---|---|---|
| Megatron-LM | 组合 tensor parallel、pipeline parallel、data parallel | 证明多维并行可以把训练扩展到千卡级集群 |
| DeepSpeed ZeRO | 分片 optimizer states、gradients、parameters | 减少数据并行中的训练状态冗余 |
| PyTorch FSDP | 原生 fully sharded data parallel | 把大模型分片训练能力带入主流框架 |
| Megatron-DeepSpeed | Megatron 并行 + ZeRO 分片 | 工业训练通常需要混合并行,而不是单一策略 |
| DeepSeek-V3 | MoE、FP8、DualPipe、通信计算重叠、负载均衡 | 训练效率和稳定性成为模型竞争力 |
| Llama / Qwen | 大规模 dense / MoE 基模训练与公开技术报告 | 基模竞争越来越依赖完整训练系统栈 |
这里最典型的是 DeepSeek-V3。公开报告中,DeepSeek-V3 采用 671B total、37B activated 的 MoE 架构,并结合 FP8 mixed precision、DualPipe、MoE 负载均衡和通信计算重叠;同时报告强调训练过程中没有不可恢复 loss spike,也没有回滚。这说明前沿训练已经不只是“模型结构创新”,而是架构、并行策略、数值精度、通信调度、checkpoint 和稳定性控制一起优化。
未来趋势可以概括为五条:
所以,未来的大模型训练系统不会只比较“用了多少 GPU”,而会比较:
- 同样预算下,谁能训练更多有效 token;
- 同样模型规模下,谁能用更低成本稳定收敛;
- 同样能力目标下,谁能更好兼顾训练效率和推理效率。
最终,大模型分布式训练的本质不是简单“多卡并行”,而是把模型、数据、激活、梯度、优化器状态、通信和存储全部重新组织,让一个原本无法训练的模型,在千卡集群上以可控成本、可恢复方式,长期稳定地完成优化。
