//note: 加载所有的日志,而每个日志也会调用 loadSegments() 方法加载所有的分段,过程比较慢,所有每个日志都会创建一个单独的线程 //note: 日志管理器采用线程池提交任务,标识不用的任务可以同时运行 privatedefloadLogs(): Unit = { info("Loading logs.") val startMs = time.milliseconds val threadPools = mutable.ArrayBuffer.empty[ExecutorService] val jobs = mutable.Map.empty[File, Seq[Future[_]]]
for (dir <- this.logDirs) { //note: 处理每一个日志目录 val pool = Executors.newFixedThreadPool(ioThreads) //note: 默认为 1 threadPools.append(pool) //note: 每个对应的数据目录都有一个线程池
val cleanShutdownFile = newFile(dir, Log.CleanShutdownFile)
if (cleanShutdownFile.exists) { debug( "Found clean shutdown file. " + "Skipping recovery for all logs in data directory: " + dir.getAbsolutePath) } else { // log recovery itself is being performed by `Log` class during initialization brokerState.newState(RecoveringFromUncleanShutdown) }
var recoveryPoints = Map[TopicPartition, Long]() try { recoveryPoints = this.recoveryPointCheckpoints(dir).read //note: 读取检查点文件 } catch { case e: Exception => warn("Error occured while reading recovery-point-offset-checkpoint file of directory " + dir, e) warn("Resetting the recovery checkpoint to 0") }
val topicPartition = Log.parseTopicPartitionName(logDir) val config = topicConfigs.getOrElse(topicPartition.topic, defaultConfig) val logRecoveryPoint = recoveryPoints.getOrElse(topicPartition, 0L)
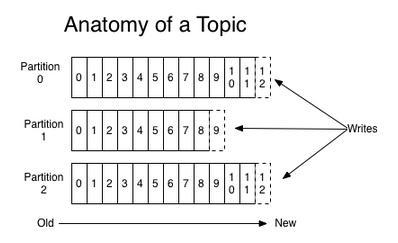
val current = newLog(logDir, config, logRecoveryPoint, scheduler, time)//note: 创建 Log 对象后,初始化时会加载所有的 segment if (logDir.getName.endsWith(Log.DeleteDirSuffix)) { //note: 该目录被标记为删除 this.logsToBeDeleted.add(current) } else { val previous = this.logs.put(topicPartition, current) //note: 创建日志后,加入日志管理的映射表 if (previous != null) { thrownewIllegalArgumentException( "Duplicate log directories found: %s, %s!".format( current.dir.getAbsolutePath, previous.dir.getAbsolutePath)) } } } }
try { for ((cleanShutdownFile, dirJobs) <- jobs) { dirJobs.foreach(_.get) cleanShutdownFile.delete() } } catch { case e: ExecutionException => { error("There was an error in one of the threads during logs loading: " + e.getCause) throw e.getCause } } finally { threadPools.foreach(_.shutdown()) }
info(s"Logs loading complete in ${time.milliseconds - startMs} ms.") } }
/** * Make a checkpoint for all logs in provided directory. */ //note: 对数据目录下的所有日志(即所有分区),将其检查点写入检查点文件 privatedefcheckpointLogsInDir(dir: File): Unit = { val recoveryPoints = this.logsByDir.get(dir.toString) if (recoveryPoints.isDefined) { this.recoveryPointCheckpoints(dir).write(recoveryPoints.get.mapValues(_.recoveryPoint)) } }
// 其他部分这里暂时忽略了 defappend(records: MemoryRecords, assignOffsets: Boolean = true): LogAppendInfo = { // now append to the log segment.append(firstOffset = appendInfo.firstOffset, largestOffset = appendInfo.lastOffset, largestTimestamp = appendInfo.maxTimestamp, shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp, records = validRecords)
// increment the log end offset updateLogEndOffset(appendInfo.lastOffset + 1)
trace("Appended message set to log %s with first offset: %d, next offset: %d, and messages: %s" .format(this.name, appendInfo.firstOffset, nextOffsetMetadata.messageOffset, validRecords))
if (unflushedMessages >= config.flushInterval) flush() }
/** * Delete any log segments that have either expired due to time based retention * or because the log size is > retentionSize */ defdeleteOldSegments(): Int = { if (!config.delete) return0 deleteRetenionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() }
//note: 清除保存时间满足条件的 segment privatedefdeleteRetenionMsBreachedSegments() : Int = { if (config.retentionMs < 0) return0 val startMs = time.milliseconds deleteOldSegments(startMs - _.largestTimestamp > config.retentionMs) }
//note: 清除相应的 segment 及相应的索引文件 //note: 其中 predicate 是一个高阶函数,只有返回值为 true 该 segment 才会被删除 privatedefdeleteOldSegments(predicate: LogSegment => Boolean): Int = { lock synchronized { val deletable = deletableSegments(predicate) val numToDelete = deletable.size if (numToDelete > 0) { // we must always have at least one segment, so if we are going to delete all the segments, create a new one first if (segments.size == numToDelete) roll() // remove the segments for lookups deletable.foreach(deleteSegment) //note: 删除 segment } numToDelete } }
/** * Perform an asynchronous delete on the given file if it exists (otherwise do nothing) * * @throws KafkaStorageException if the file can't be renamed and still exists */ privatedefasyncDeleteSegment(segment: LogSegment) { segment.changeFileSuffixes("", Log.DeletedFileSuffix) //note: 先将 segment 的数据文件和索引文件后缀添加 `.deleted` defdeleteSeg() { info("Deleting segment %d from log %s.".format(segment.baseOffset, name)) segment.delete() } scheduler.schedule("delete-file", deleteSeg, delay = config.fileDeleteDelayMs) //note: 异步调度进行删除 }